システムの信頼性確保には二重化が基本
サーバは「止めないこと」が原則です。特に企業の基幹業務に関わる部分や、オンラインサービスを提供している場合、サーバの停止は業務の停止を意味するため、サーバの障害監視と障害発生時の対策は常に意識している必要があります。サーバにはHDD(ハードディスクドライブ)や冷却ファンなどの回転機構のあるパーツ、電源など熱を発生するパーツがあり、しばしば故障の原因となります。
もちろん、こうしたサーバを構成するパーツは故障を前提として作られていますが、実際に障害が発生したときにはサービスを止めずに復旧を行うことが重要になります。特に、障害発生から復旧までのプロセスにおいて、データが失われることは避けなければなりません。そこで、サーバでは二重化(冗長化)が行われています。二重化には、故障しやすいパーツを複数個搭載しておく手法や、サーバそのものを複数台するといった手法があり、多くの場合、後者が選択されています。
二重化はデータにおいても同様です。常に最新のデータをバックアップしておくことで、障害が発生してもデータを失うことなくサービスを継続することが可能になります。そこで、HDDの二重化にRAIDが多く採用されています。
RAIDでは対応できない問題
RAIDは、複数台のHDDを組み合わせて1台のHDDのように使用できる技術。HDDの構成やデータの記録方式によって、いくつかの種類があります。記録方式には、基本的にデータを分散して書き込む「ストライピング」と、データを複製して書き込む「ミラーリング」があり、データを失ってはならない場合はミラーリングによってデータを二重化し、一台のHDDに障害が発生しても、もう一台のHDDのデータでサービスを継続できるようにします。
さらに、RAID構成にHDDを追加することで常に最新のデータをバックアップし、RAIDそのものが障害により使えなくなってもデータを保護することが可能になります。特に、RAIDを構成するHDDの障害に気づかなかった場合に有効です。
RAIDはホスティングサービスにおいても以前から提供されており、それが信頼性確保の条件になっていました。しかし、RAIDはデータに限定された二重化であり、冷却ファンや電源、メモリといったHDD以外の障害には対応できません。特に現在のシステムでは、基幹サーバやWebサーバの背後にメールサーバ、データベースサーバなど複数のシステムが存在しており、これらに障害が発生する可能性もあります。すでにRAIDだけではサービスの継続性を担保できなくなっているのです。
注目されるHAクラスタ
HDDだけではない障害発生の要素に対して、サーバを丸ごと一台用意して障害に備えるようになりました。これによりサーバに障害が発生しても、もう一台のサーバに切り替えてサービスを継続できます。こうした耐障害性を高めてサービスの継続性を向上したシステムをHAクラスタと呼びます。HAは高可用性(ハイアベイラビリティ)の意味で、HA構成と呼ばれることもあります。
HAクラスタでは、メインのサーバとまったく同じ構成のサーバを予備機として用意しておく「コールドスタンバイ」と、同じ構成のサーバ2台以上でミラーリングを行い、一台に障害が発生したときに自動的に切り替える「ホットスタンバイ」があります。
サーバ間でのミラーリングは、DRBD(Distributed Replicated Block Device)というシステムによって実現されていますが、これによりサーバ単位だけでなくApacheやMySQLといったサービス単位で障害復旧を行うこともできます。さらに、物理サーバだけでなく仮想サーバにも適用できる可能性があります。
Pacemakerの特徴
サーバを二重化した場合、どの時点で切り替える(フェイルオーバ)かという問題があります。一般的には、定期的にサーバの死活監視を行ったり、リソースを監視して一定のしきい値を超えたときにメールなどでアラートを発信するといった方法が取られており、これらはソフトウェアによって行います。ソフトウェアは有償、無償のものが数多く提供されており、さまざまなものが使用されています。
Linux-HAが提供している「Pacemaker」もそのひとつ。OSS(オープンソース・ソフトウェア)のため無償で利用でき、カスタマイズも可能なため多くのユーザに利用されています。さまざまな構成のHAクラスタに対応しており、サービスレベルでの監視とフェイルオーバが可能であることも人気です。
ただし実用上の問題も多くあります。たとえばSSHでログインすることで復旧できるような設定ミスなども検知してしまうことや、Apacheをフェイルオーバしたい場合、Apacheは通常PHP等をホストしており、PHPは通常MySQLと組み合わせて利用されているため、Apacheをフェイルオーバするのであれば必然的にMySQLも併せてフェイルオーバする必要が生じる場合が多くなります。また、リソース単位の監視やフェイルオーバをしたい場合には、サービス間の依存関係や複雑性をクラスタ自体が管理しなくてはならなくなります。
コンテナ型のLXCによるメリット
一方、仮想環境上でリソース単位の監視やフェイルオーバを実現したい場合、仮想化技術そのものを工夫して効率化を図るという方法もあります。そのひとつが「LXC」です。LXCもオープンソースの仮想か環境で、もともとはIBMの技術者が開発したものです。LXCは、リソース単位で管理を行う「コンテナ」と呼ばれるシステムが特徴のひとつ。プロセス権限でOSリソースを制御できるため独立した動作が可能で、オーバーヘッドがほとんどないことも特徴です。
最近のカーネルもコンテナに対応しているので、OSのバージョン管理やカーネルに手を加えることなく独立したリソース管理行うことができます。特にVPSと相性のいいシステムといえるでしょう。
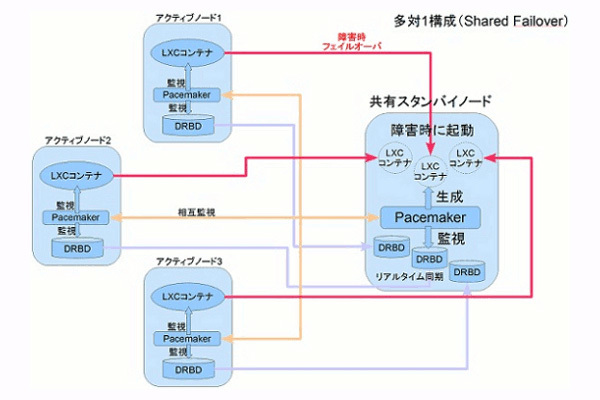
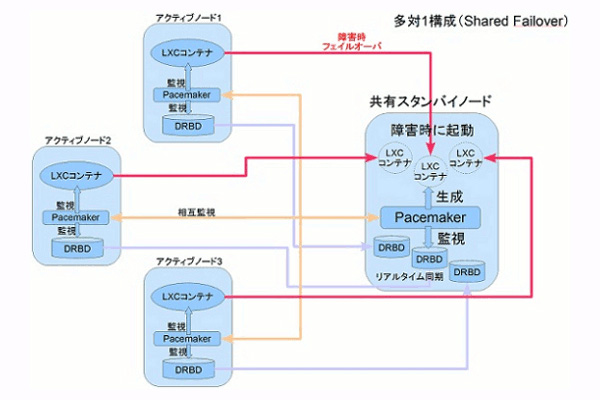
インスタンス単位でフェイルオーバ
LXCとPacemakerにより、「コンテナ」単位での監視が実現できます。さらにDRBDを組み合わせることで、VPSインスタンスを監視しインスタンス単位でフェイルオーバすることが可能になります。具体的には、動作中の仮想サーバがダウンするとPacemakerが検知して待機側に同じ仮想サーバが生成され、ダウン直前のアクティブ側と同じ状態で待機サーバ側が動作します。これはコンテナ単位、つまりApacheやMySQLといったサービス単位、インスタンス単位でのフェイルオーバが可能になるのです。
Joe'sウェブホスティングでは、専用サーバおよびVPSにこの技術を応用することを検討してきた結果、2011年8月22日より専用サーバおよびVPSのオプションとして、HAクラスタサービスを開始しました。
インスタンス単位でフェイルオーバする方式によって、サービス間の関係の複雑さを意識しなくて済み、sysvinitやsystemdに委譲することができ、またSSHでログインすることで復旧できるような問題はトリガ対象イベントから除外できるので、ハードウェアやネットワーク障害などの本当にフェイルオーバが必要な事態に対応することができます。KVM等でもほぼ再利用できる設計としていることも特徴です。
さらに、ユーザ自身が手動リソースリロケーション等可能なブラウザベースの管理インターフェイスを提供しており、ハードウェアメンテナンスやカーネル更新時、手動でノードを切り替える等、柔軟な運用が可能VPSとしています。
Joe'sの専売特許であるコンテナ型のLXCを用いているので、完全仮想化などと比較して待機側のマシンの動作を軽くでき、リソースを低オーバヘッドVPSインスタンスとしてまとめられるので、非常に効率的。HAクラスタ利用の月額費用は、サーバ利用の月額費用の50%と安価なこともメリットといえます。