2月3日および4日、OpenStack専門カンファレンス「OpenStack Days Tokyo 2015」が開催されました。OpenStackへの注目の高まりを受けて規模を拡大してきた本イベント。今年は10月に本家の国際カンファレンス「OpenStack Summit」の東京開催を控え、その前哨戦という意味でも大いに盛り上がりました。ここでは、4日に行われたミラクル・リナックスのセッション「使ってわかった!現場担当者が語るOpenStack運用管理の課題」の様子を中心にレポートします。
会場受付を待つ来場者
のべ3000名以上が来場!
第3回目となる今回の「OpenStack Days」は、会場をグランドプリンスホテル高輪に移して2日間の日程で開催されました。入場者数はのべ3000名を超え、OpenStackへの注目の高まりを肌で感じるカンファレンスとなりました。1日目のキーノートセッションには、OpenStackファウンデーションのCOOであるMark Collier氏が登壇、「 OpenStack Mission Update」として講演を行いました。
OpenStackファウンデーション COO Mark Collier氏
OpenStackは、オープンソースのネットワークOSとして最も活発に活動しており、多くのメジャーなベンダが参加しているとCollier氏は強調しました。2010年のラウンチから5年でデベロッパーの数が100倍に、サミットの参加者は5000名に拡大したといいます。すでに大手企業での導入事例も豊富にあり、参加する開発者も増加していますが、多くの取り組みがあるとして参加を呼びかけました。
また、10月26日から30日にかけて開催される国際カンファレンス「OpenStack Summit Tokyo」も紹介し、日本で初めてのカンファレンスに大きな期待を寄せており、非常に楽しみにしていると述べました。なお、OpenStack Summit Tokyoも今回と同じグランドプリンスホテル高輪で開催される予定です。
今年日本で開催されるもうひとつのOpenStackイベント「OpenStack Summit Tokyo」が告知された
OpenStack環境の運用上の課題とは
OpenStackのゴールのひとつに、数千台から数万台規模での物理サーバの管理を自動化があります。最近では1万台という事例も聞こえてくるようになりましたが、同時に問題点も指摘されています。その問題に取り組んでいるのがミラクル・リナックスです。2日目には、ミラクル・リナックスのエンジニアである佐藤剛春氏によるセッション「使ってわかった!現場担当者が語るOpenStack運用管理の課題」が行われました。
ミラクル・リナックス 佐藤剛春氏
セッションには、佐藤氏と並んで日本仮想化技術の玉置伸行氏も登壇しました。日本仮想化技術は仮想化技術に特化した技術者集団であり、日本におけるOpenStack導入支援・コンサルティングの先行企業でもあります。OpenStackにおいては、ベアメタルサーバを管理するためのベアメタルプロビジョニング技術を開発し、オープンソース化し、OpenStackのGrizzly版にマージした実績があります。大規模なクラウド環境の構築や運用の経験やノウハウがあります。日本仮想化技術とミラクル・リナックスが両社の強みを生かし、協力してOpenStack環境の運用上の課題の解決にあたっていると玉置氏は説明しました。
日本仮想化技術 玉置伸行氏
佐藤氏はOpenStack環境の運用上の課題として、「 管理対象のサーバ数が莫大であること」「 スケールアウトすることを前提にシステムが作られていること」「 運用の効率化が求められていること」「 障害検知の方法が多様であること」の4点を挙げました。そして、これらの課題に対して「Zabbix(※ )を活用した監視システム」と「Hatoholによる統合監視システム」で解決するとしました。
OpenStack環境の特徴は、まず仮想ホストとして多数の物理マシンがあることです。多数あるということは、故障ポイントも多いということになります。また仮想ゲストとして非常に多数のインスタンスが立ち上がります。これは物理マシンの数倍から数十倍にもなります。そして、物理マシンの故障や増強、利用者の増減によって、物理マシンもインスタンスも増減します。このように変化の激しいOpenStack環境では、さまざまな事象に対して運用の効率化が求められるとしました。
運用を効率化するためには、監視アプローチの変更が必要であると佐藤氏はいいます。具体的には、アプリケーションの冗長化を前提として、障害発生ホストを即座に切り離すといった「サービス継続を優先」 、特に行動の契機となる障害を検知する「監視は障害検知に重点を置く」「 障害検知後の自動化も考慮する」を挙げました。もちろん、構築費用や運用費用も重要な要素になります。
課題を解決する監視システム
続いて佐藤氏は、監視システムについて説明しました。まずはZabbixによる監視システムです。ZabbixはOSSの監視ソフトであり、ミラクル・リナックスによるMIRACLE ZBXも提供されており、通常版は無償です。ここで、玉置氏から発表がありました。Zabbix、MIRACLE ZBXのどちらでも使用可能なOpenStack構成ノード用テンプレートをミラクル・リナックスと日本仮想化技術が共同開発し、無償提供しています 。controller、network、computeノード用で、プロセス、ポートの監視、RabbitMQのキュー監視が可能になっています。
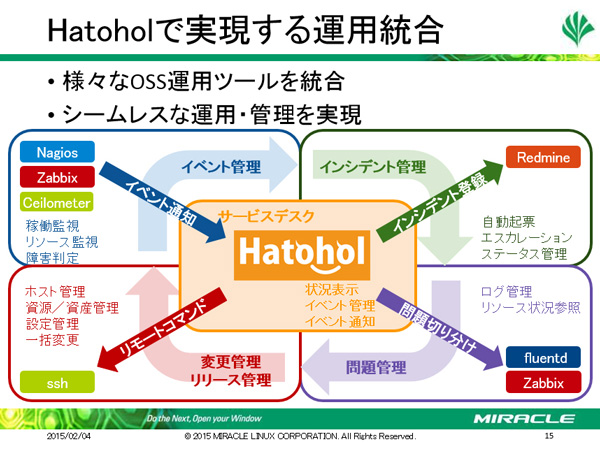
大規模OpenStack環境では、スケールアウトが必須となります。なおZabbix、MIRACLE ZBXでは実データ、障害検知履歴がサーバ上のデータベースに格納されます。そこで佐藤氏は、Hatoholによる統合監視システムを紹介しました。HatoholもOSSの監視ソフトで、ミラクル・リナックスが支援している開発コミュニティ「Project Hatohol」で開発されています。Hatoholはスケールアウトした監視サーバを統合することが可能で、検知した障害の一括監視・管理と権限分掌の両立を実現します。対象はMIRACLE ZBX、Zabbix、Nagiosのほか、プラグインを作成することで他の監視ソフトを追加することも可能です。また、Redmineのインシデント自動登録も可能になっています。
Hatoholを活用することで、スケールアウトに対応できます。システム拡充とともに増加する監視サーバを統合でき、複数の拠点を跨いだ統合も可能になっています。また、Hatoholのオーケストレーション活用によって、Ceilometerでリソース利用状況を把握したり、インスタンスの増減など状況に応じてアクションを実行することができます。ここで注意したいことは、MIRACLE ZBX、Zabbixでは監視対象の減少があまり想定されていないことです。監視対象の減少を障害発生だと誤検知してしまうので、インスタンスを減らす際には、Zabbix APIを使用して監視対象ホストを削除または無効化し、インスタンスを明示的に終了するというステップを踏む必要があります。
これからのインフラ監視
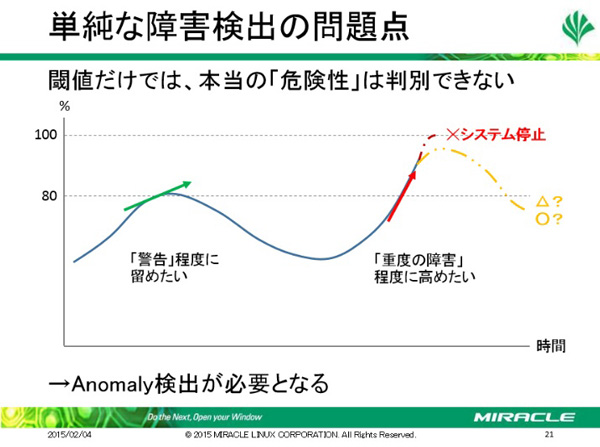
佐藤氏はさらに、インフラ監視の今後について述べました。OpenStack環境の課題として、障害検知の方法においては。プロセス・ポートの状態が正常であっても、正常に動作しているとは限らないことや、アプリケーション冗長状態の確認も必要になること、単純なしきい値判定では、運用状態を把握できないことを挙げました。障害だけでなく運用状態の監視も必要になるため、効率性が重視されます。そのためには、監視手法の拡充が必要であるとしました。
拡充については、まず追加の監視設定が必要で、これにはAPIレスポンスやDBレスポンス、Queue depth(AMQP)が含まれます。そして、インスタンスの起動・終了、ネットワークの作成・削除、テナントの作成・削除について、controllerノードに対する要求と結果を比較します。これにはOpenStack Rally, tempest-libが活用できます。さらに充実させるための方法として、佐藤氏はプローブ用インスタンスの監視、プローブ用インスタンスをライブマイグレーションさせつつ監視することを挙げました。
このほか、Fault Injectionを使用してアプリケーション冗長性の確認をしたり、運用中のシステムに対し、常に障害を引き起こさせる方法も紹介しました。Netflixが開発、OSSとして公開しているChaos Monkeyも有効です。ただし、しきい値だけでは本当の危険性は判別できないと佐藤氏は指摘します。そこで、自動学習によるAnomaly検出が必要となります。Anomaly検出を行うには、過去のリソース監視データを統計的・数学的に処理する必要があります。この処理にはApache StormやMonitoring as a Serviceと呼ばれるOpenStack Monascaを活用することができます。
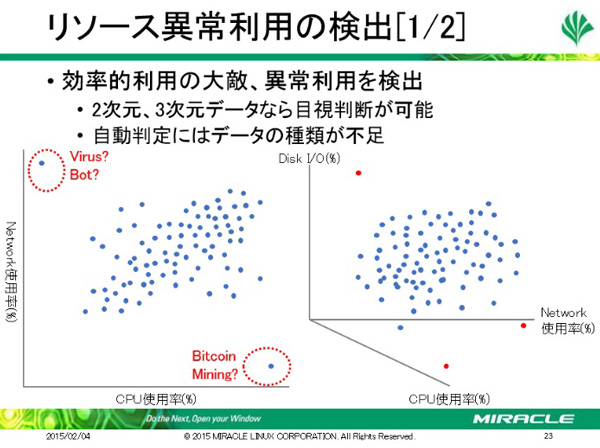
リソース異常利用を検出する場合には、二次元、三次元のデータを使うことで目視判断が可能になります。たとえばネットワーク使用率とCPU使用率を軸とした二次元のデータであれば、CPU使用率は低いのにネットワーク使用率が異常に高ければウイルスやボットの可能性がある。あるいは逆の位置にデータがあれば、ビットコインのマイニングなどが行われている可能性があると判断できます。ただし、自動判定にはデータの種類が不足していると佐藤氏は指摘します。
たとえば送受信ポート番号による重み付けを追加すれば五次元のデータに、さらに時間軸を考慮すれば六次元のデータにすることができます。ただし、そうなると人間が目で判断することは不可能です。そこで、たとえばベクトルデータとして処理する、過去のデータや利用履歴から初期判断基準を生成する、運用しながら自動学習、異常検出にフィードバックするという方法があります。
佐藤氏は最後に、4月10日に秋葉原UDXのGALLERY NEXT 4Fで行われる無料セミナー「Hatohol 15.03で行うOpenStack運用管理」の告知と、OpenStackを監視する構成を半自動で実現する手順書「MIRACLE ZBX + Hatohol環境構築手順書」をアピールし、セッションを締めくくりました。
31社がブースを出展
OpenStack Days Tokyo 2015では、セッション以外にも展示ブースの出展やハンズオンコーナーなども行われ、活況を呈していました。ブースの出展は31社におよび、より実践的な出展内容が目立ちました。OpenStackが実用フェーズへ確実に移行していることを実感します。実際にブースを訪れる方達も、前回多くを占めたテレコムやキャリア系から、エンジニアや一般企業のお客様が非常に増えたといいます。来場者の質問も、「 OpenStackとは何か」を知ろうとするものから「実際の導入や運用はどうするのか」といった、より具体的なものになっているそうです。
今回のイベントにより、OpenStackへの興味がまた一段と上がったように感じました。そして10月には、いよいよ国際カンファレンス「OpenStack Summit Tokyo」が同じ会場で開催されます。世界的にも注目されているイベントであり、会期中には欧米を中心とする海外からの来場者もいらっしゃるでしょう。ぜひサミットにも足を運んでいただき、OpenStackに取り組むグローバルな“ 熱さ” を実感していただきたいと思います。