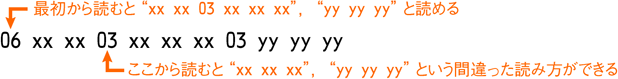さて、前回の大まかな地図を元に、第2回では実際に問い合わせ手法の詳細について見ていきます。最初に取り上げるのはシーケンシャルスキャンという、データベース検索の最も基本になるアクセス手法です。
シーケンシャルスキャンとは
シーケンシャルスキャンは、日本語に直訳すると「順次検索」という形になります。端的に言ってしまえば「すべてのデータを順に検索する」ということで、結果として通常はすべてのデータを読み込んで返します。その後、検索条件や取得件数などの必要に応じてフィルタリングが行われることもあります。この方法は、すべての件数を対象として検討するため、条件を選ばず使えます。そのほか、どんな複雑なSQLが来てもシーケンシャルスキャンなら取りこぼしがありません。たとえばなんの変哲もない
といったSQLを実行するに当たっては、シーケンシャルスキャンを使います。
図1 シーケンシャルスキャンの実行形

シーケンシャルスキャンのフロー
さて、これをふまえて、その内部ではなにがどのように行われているか、というところに踏み込んでいきましょう。これは、単純に考えていただければよいのですが、以下の通りになります。
- まず、ディスクからデータを読みます。
- (このとき、キャッシュにあればキャッシュから読みます)
- メモリに展開して、行にばらします。
- ばらした行に対して、フィルタをかけるなどの処理します。
図2 シーケンシャルスキャンの実行フロー

この一連の動作で、特に時間がかかるのはディスクからデータを読み取る部分です。たいていのディスク読み込み速度はメモリに比べると大変遅いのです。そのため、シーケンシャルスキャンの速度≒ディスク読み込み速度と考えます。
ディスクの読み込みが遅いのに対処するために、メモリ上にキャッシュ機構を持ち、同じデータが頻繁にディスクから読み出されることを防ぐなどの性能上の工夫を凝らします。ディスクキャッシュがどの程度効くか? というのはもちろんケースによりけりです。読み出すテーブルが小さいサイズであればキャッシュが効きやすいため、実行時間がより短くなるケースも出てくるでしょう。逆に、非常に大きなテーブルであった場合、あまり期待は出来ないでしょう。
シーケンシャルスキャンの裏側
ところで、筆者がよく受ける質問に以下のようなものがあります。
「今回のシステムは○○件のレコードを格納する予定なのですが、PostgreSQLで使えますか?」
実際にはこれに「CPUは~、メモリは~、ハードディスクは~」とか、「予算はいくら」とか、そういう前提条件が発生します。この質問だけではあまりにも漠然としていますから、シーケンシャルスキャンに関係のある「○○件の全件検索を行うのに、×秒以内でできますか?」という風に考えましょう。
この質問に対する答えとしては、件数が極端に多い場合には「出来ません」、極端に少なければ「大丈夫です」となります。そういう極端な場合のを除けば、実は「○○件」だけではうまく答えられません。シーケンシャルスキャンの実行時間、つまりディスクからの読み込み量には、件数以外の要素も絡みますから、簡単には答えられません。このギャップを理解しないと、データベースの性能というのはなかなか見えてきません。
ディスク上でのレコードの保存のされ方
というわけで、ディスクの読み込み量がどのように決まるかというところを見ていきましょう。つまるところ、ディスク上にレコードはどのように格納されているか? であると言っていいでしょう。これを考える上で問題になるのは、データベースでは、レコードは可変長であることが期待されるということです。これをそのまま可変長で扱おうとすると、以下のような問題に悩まされます。
途中のデータが欲しかった場合、どこから読めばいいか分かりづらい
今後説明するインデックス検索等では、ある特定のレコードを取り出すような処理も必要になります。そのときに特定の一つだけを取り出すための「とっかかり」が必要になります。その「とっかかり」は固定長でないと、プログラムの記述が大変面倒になります。実際に可変長を使って格納してあるケースで見てみましょう。
完全可変長のフォーマットの最もポピュラーなものは、そのブロックの長さを最初に記述し、その後にデータそのものを記述する、というものです。簡単な例を示します。
例:長さ1バイトを最初に表現し、そのあとに指定したデータを入れる
06 xx xx xx xx xx xx 03 yy yy yy
例のようにすれば、255バイト以内の長さのブロックを無駄なく格納できます。実に効率のよい形です。ところが、完全に可変長のデータの場合、一番最初から読んでいかないと区切りがはっきりしません。というのも、途中から適当に読んだところ、本当はデータの中身なのに「たまたま」一見妥当そうに見える部分があるかもしれないからです。
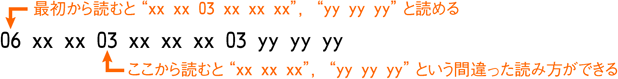
これに沿って読むとおかしなことになってしまいます。特殊な方法で文字列長とそれ以外を分けるなどの手法で解決できますが、それも物事を複雑にしてしまいます。結局このような間違った解釈を避ける妥当な方法は、「全部最初から読む」か「固定長のインデックスを前につける」になってしまいます。
更新したときに長さが変わったときに困る
これも簡単な例ですが、
- 3件のデータが入っている
- 真ん中のデータを消す
- 新しく4というデータを投入する
3-1) ちょうど削除したデータと同じ長さの場合
3-2) 削除したデータより短い場合
3-3) 削除したデータより長い場合
というのを見てください。3-1のように、ちょうど削除したのと同じ長さのデータが入っている場合には何ら問題がなさそうですが、短いデータや長いデータを格納するときは隙間が出来てしまいます。これで無駄なディスク容量を増やしてしまいますので、適当とはいえないでしょう。このようなケースにも対処しなければいけません。
このようなことを考えなければいけないため、完全な可変長というのは結構面倒なのです。そこで「基本は固定長、その中が可変長」という組み合わせが使われます。このうち、固定長の部分はブロック、可変長の部分がタプルと呼ばれます。関係を図に示します。
図3 ブロックとタプルの配置

この配置は、たとえば特定のタプル(=レコードと考えて差し支えありません)を取得する場合にも、
- データ全体の何番目のブロックか?
- その中の何番目のタプルか?
という2段階を経て検索が出来、非常に効率的です。そして、全件読み込みの性能を語る場合、問題になるのはこの「読み込むべきブロックがどの程度の量になるか?」というのが焦点になります。PostgreSQLではブロックのサイズは標準で8KBなので、それを例に取ってみますと、
- タプルサイズが60バイトの場合、136個が1ブロックに格納可能=1360000行で10000ブロック
- タプルサイズが120バイトの場合、68個が1ブロックに格納可能=680000行で10000ブロック
- タプルサイズが4150バイトの場合、1個が1ブロックに格納可能=10000行で10000ブロック
となります。やや暴論ですが、各タプル内での処理を無視すれば、上記のテーブルに対するシーケンシャルスキャンは全部同じ性能ということになります。これでは「~行を投入する」というだけでなく、タプルサイズがどれなのか? ということが分からないと全く性能面の話が出来ない! ということがおわかりいただけるのではないでしょうか。
また、このうち一番下のケースでは格納効率が悪い点も見逃せません。というのも、10000ブロック=80MBのディスクを消費しているのに、投入できるのは4150×10000=40MB強と、わずか半分なのです。これはやはりブロックータプル型の欠点であるといえます。しかしながらタプルサイズが小さい場合は効率もとてもよいのです。この構造は大半のRDBMSが採用しているそうです。カラム数が少ないテーブルととても相性がよいのです。
まとめ
さて、最も基本的なシーケンシャルスキャンをもとに、データ検索と格納の最も基礎的な部分を解説しました。中でも最もわかりやすい部分だと思いますが、RDBMSは件数ももちろんですが、データの物理的な量に性能が左右されるシステムだということが理解していただけたかと思います。
- シーケンシャルスキャンは、データを逐次読み込んで実行する、スキャンの最も基本的な流れです。
- あらゆる点に対応が出来るのがメリットです。
- 読み込むディスク量に比例して時間がかかります。件数だけではなく、件数×サイズが問題になります。
- データの格納は、大きくは固定長で、その中で可変長で小さく区切られています。
- レコードサイズ(タプルサイズ)の大きなテーブルは、格納時に不利です。