I/Oの「レスポンス」と「スループット」とは?
連載第1回でご紹介したように、大規模データ処理を行うデータベースで一番大きな課題となるのは、ディスクI/O(以降、単にI/Oと表記します)のボトルネックです。数百GBやTBクラスの巨大データウェアハウスの場合、SQLが実行される時間のほとんどがI/Oを待つ時間となっているケースが多々あります。
ここでは、I/Oボトルネックが発生するおもな原因を、「レスポンス」と「スループット」という概念から見ていきましょう。それぞれ、広義では以下の定義となります。
- I/Oレスポンス=I/O要求処理にかかる応答時間
- I/Oスループット=単位時間当たりのI/O処理量
Oracle Databaseに当てはめると、以下のように定義できます。
- I/Oレスポンス=1データブロックの読み出しや書き込みにかかる時間
- I/Oスループット=単位時間あたりの読み出しや書き込みの量
レスポンスにフォーカスすべき場合、スループットにフォーカスすべき場合
I/Oの性能を論じる際には、処理の特性からレスポンスとスループットを使い分けます。
レスポンスにフォーカスするケース
オンライントランザクション(OLTP)システムにおいては、注文や予約など、一度の処理に関係するデータ量が小さいのが特徴です(通常、数データブロック)。
このように、一度に扱うデータ量が小さいシステムの場合、1データブロックのI/O時間を表すレスポンスを向上させることが重要になります。
スループットにフォーカスするケース
売上分析など、一度に対象となるデータが大きい(数GBなど)場合は、1データブロックの処理時間よりも、単位時間あたりにどれだけ多くのデータを読み書きできるかが重要になります。
したがって、レスポンスではなく、スループットを議論するのが一般的です。
まとめると以下のとおりです。
- ミクロなI/O性能を論じる場合 ⇒レスポンスを考える
- マクロなI/O性能を論じる場合 ⇒スループットを考える
大規模データ処理の場合は、スループットをいかに高めるかが重要になります。
ディスクI/Oボトルネックのパターンを知る
ディスクI/Oがボトルネックになる場合、いくつかの代表的なパターンがあります。
そもそも、データベースが感じるI/O時間は、下記のように表されます。
- I/O時間 = ストレージがデータを取得する時間
- + ストレージからデータベースへデータを転送する時間
- + データベースサーバでI/O処理を行う時間
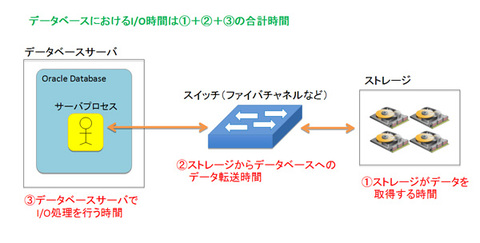
ここでは、「ストレージ」、「ストレージ ― データベース間のネットワーク」、「データベース」の3層に分けて、I/Oボトルネックとなる代表例を見ていきましょう。
ストレージがI/Oボトルネックとなる場合
ケース1 ストレージのI/O帯域幅やCPUの性能限界を超える
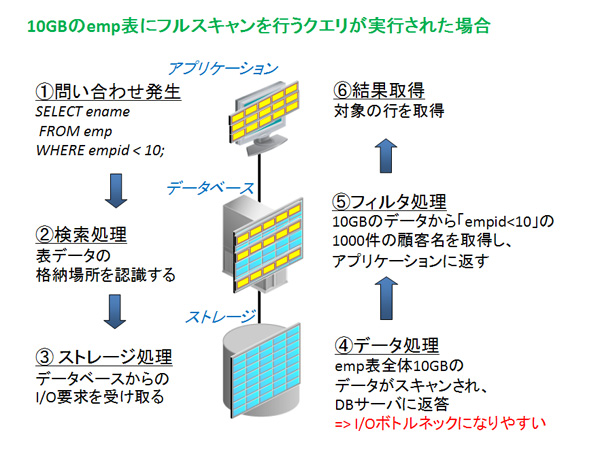
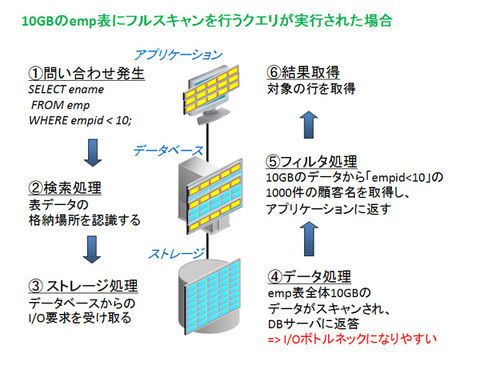
たとえば、フルスキャンを行うSQLがアクセスの対象とする表のサイズが10GBの場合を考えてみてください。この場合、SQLの中でどのような絞り込み条件が書かれていたとしても、Oracle Databaseは10GBすべてをストレージに要求します。
大規模なデータ処理が必要となるシステムの場合、大量のI/O要求を受けたストレージのI/OやCPUの性能限界により、スループットが出なくなることがあります。
ケース2 同一ディスクへのアクセス競合が発生する
同一のディスクにアクセスが集中すると、アクセス競合が発生し、スループットが落ちる場合があります。
ストレージ―データベース間のネットワークがI/Oボトルネックとなる場合
意外と盲点になりやすいですが、データベースがI/O要求を出した場合、ストレージとデータベースサーバ間のネットワークの転送時間もI/O処理時間として見えます。したがって、大規模データ処理を行うデータベースにおいては、I/O量に対してネットワーク帯域が不足していると、ネットワークがボトルネックになります。
データベースがI/Oボトルネックとなる場合
ケース1 SQL、もしくはSQLの実行計画が不適切で、不要なI/Oを実施している
CPUやI/O帯域、ネットワークなどのハードウェアリソースに余裕があっても、以下のようにSQL文、もしくはSQLの実行計画が不適切な場合、不要なI/Oを実施し、実行時間が長時間化してしまうことがあります。
- 実行計画に直積が選択された場合
- 同一データに複数回アクセスしてしまうSQLがある場合
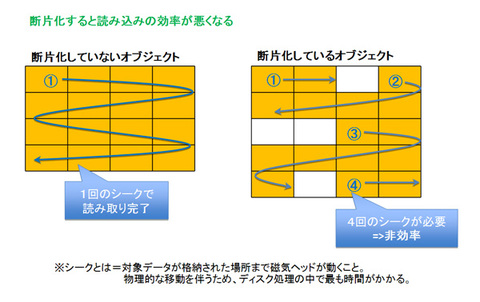
ケース2 索引、エクステント、ブロックが断片化している
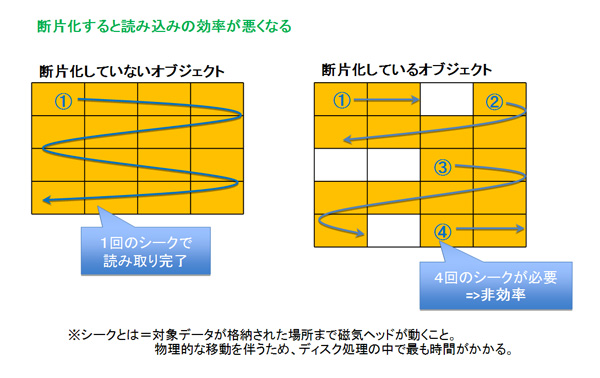
Oracle Databaseにおいては、さまざまなサイズで領域が割り当てられたり、更新処理が断続的に発生したりすると、実データサイズ以上に割り当てられているサイズが肥大化する「断片化」という現象が発生する可能性があります(索引やエクステントで発生)。
大規模データ処理を行うデータベースにおいては、断片化により、ディスクに対する範囲読み込み(シーケンシャルリード)を行うフルスキャンの効率が悪くなり、I/O時間が延伸することになります。これはおもに、ディスク読込の中で最も時間のかかるシーク処理の回数が増えるためです。
I/Oボトルネックを分析するには
Oracle Databaseにて、I/Oボトルネックになっているかどうかを判断するにはさまざまな方法がありますが、代表的なものは以下のとおりです。
AWRでOracle Databaseの性能を分析する
AWR(Automatic Workload Repository)からは、Databaseの性能分析に必要なほとんどの情報を見ることができます。
I/Oボトルネックになっているかを見極める一番かんたんな方法は、AWRレポートの「Top 5 Timed Foreground Events」のセクションにて、I/O関連の待機イベントによる待機時間の割合(「% DB time」列から確認)が大きくないかを確認することです。
おもに以下の待機イベントによる待機時間の割合が大きい場合には、I/Oボトルネックであると考えることができます。
- db file sequential read
- db file scattered read
- direct path read
- log file sync
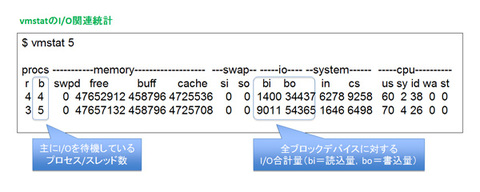
vmstat/iostatでOS観点からI/O性能を分析する
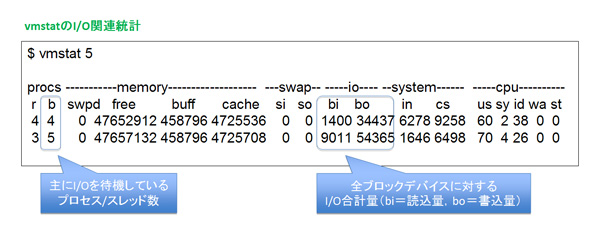
UNIX系OSの場合、vmstatやiostatを使用することで、I/Oの状況を分析することができます。
vmstatの場合、I/O待ちをしているプロセス数を表す「b」列にCPUスレッド数以上の値が出ていると、I/Oがボトルネックになっている可能性があります。
iostatの場合、I/O使用率を表す「%util」列値が100に近い値となっているディスクでは、I/Oが詰まっている可能性があります。
では、どうすればこれらのI/Oボトルネックを解消することができるのでしょうか。
次回は、Oracle ExadataがいかにしてI/Oボトルネックを解消しているのか、その高速化技術に迫ります。お楽しみに!