varnish2.1.4が発表されたようで、一部ユーザの間ではリリースノートから新しい機能について解読、評価したりと盛り上がっているようです。
キャッシュシステムは、比較的トラフィックが大きなシステムで検討されるものかもしれませんが、varnishをはじめ、squidなどでも比較的簡単に実装できるため、「今はそんなにトラフィックがないので」というシステムでも積極的に評価し、トラフィックの少ないうちであればなおさら適用する事をお進めします(httpサーバ等との同居でも十分に効果が得られる事もあります)。
筆者の経験上、クリスマス、年末年始、あるいは、昨今のSNSのように、爆発的なトラフィックは突然やってきます。
今回も、今までキャッシュシステムに無関係だったり、新しくインフラ関連の仕事に就いた人で概念が理解できる事を目標に、キャッシュの仕組みはvarnishを使う前提で、特定のコンテンツだけをvarnishに向けたりと、いくつかのシチュエーションを考えてみようかと思います。
多段キャッシュ構成の基本
前回は、varishを親子階層に定義する所まで説明したかと思います(図1)。
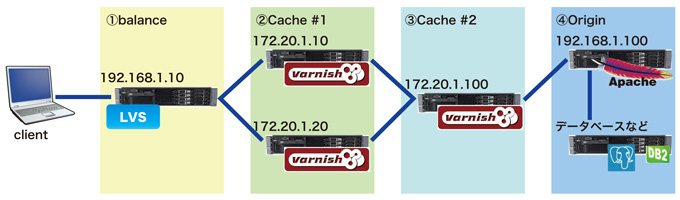
図1 前回の構成
これを親子関係がわかりやすい図(シーケンスイメージ)で記載すると、図2のようになります。
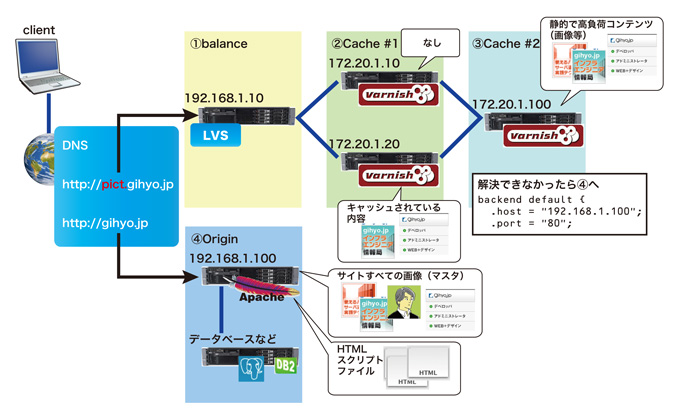
図2 構成図(多段)イメージ
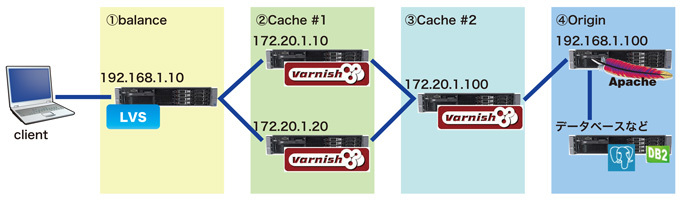
①balance
HTTPなどのリクエストを受け付け、適切なサーバへ割り当てます。大規模、高負荷システムの場合、この機器自体がL7の分散機器であったり、分散方法もLVS等ではなく、(2)Cacheサーバのヘルスをウォッチし、適切なロード分散を行うミドルウェアなど、トラフィックの規模に応じて検討します。
②Cache #1
多段キャッシュ構成では「子」に位置します。
varnishの場合「子」が独立してしまうなど、ミドルウェアによって違いが出てくる部分でもありますので、システムに適したミドルウェアや運用を検討する部分でもあります。
③Cache #2
多段キャッシュ構成では「親」と位置付けられます。この「親」サーバでリクエストが解決できない場合、実際のAPサーバへ問い合わせを行います。
②でも記載しましたが、varnishの場合は図2で言えば水平(横)にの動きに対しては大変パフォーマンスが良いのですが、垂直(縦)の動きに対してはかなりクセがあるというか、varnish以外の方法も含めて検討が必要です。これらに関しては後述します。
④Origin
実際のAP(アプリケーション)サーバになります。たとえば静止画像のみをvarnishでキャッシュするとした場合、htmlやスクリプト系のファイルはAPサーバに存在しますので、最初のhtmlファイルのリクエストは直接このサーバにアクセスし、html中に記載されている静止画像等のパス(URL)がLVS(varnish側)へリクエストされれば良いことになります。これらの構成を「コンテンツキャッシュ」「外に散らす」などと言われることがあります。
アニメ風に解説すると以下の通りになります。
- まず「client」から「http://gihyo.jp/」にアクセスしたとしましょう。
- gihyo.jpでは、「index.html」などのテキスト形式のhtmlを返します。
- 再び「client」では、レスポンスで得た「index.html」ファイルを(ブラウザが)解読します。
- 複雑な処理は割愛して、サイトを表示するための画像ファイルは以下のように記載されているとしましょう。(コンテンツキャッシュの例)
<img src="http://pict.gihyo.jp/xxx/logo.gif" alt="xxx" width="xxx" height="xxx" />
<img src="http://pict.gihyo.jp/xxx/title.gif" alt="xxx" width="xxx" height="xxx" />
<img src="http://pict.gihyo.jp/xxx/prof.gif" alt="xxx" width="xxx" height="xxx" />
5.「client(ブラウザ)」は取得したHTMLファイルに指定された「http://pict.gihyo.jp」配下にあるgifファイルを探しにいきます。http://pict.gihyo.jp はDNS(など)によって図2の①側のシステムへ振り分けられ、目的のファイルが解決されるまで、varnishなどのプロダクトの定義に従ったルートの通り進み、画像があればそのまま返信され、無ければ「backend」定義に従って次のマシンへ問い合わせます。④の「親」でも無かった場合は、HTMLがあったOriginサーバへ問い合わせ、解決します(ここで無ければユーザ「client」へは404となり、システムとしては何らかの障害となるでしょう)。
図3 多段キャッシュにおけるデータの流れ
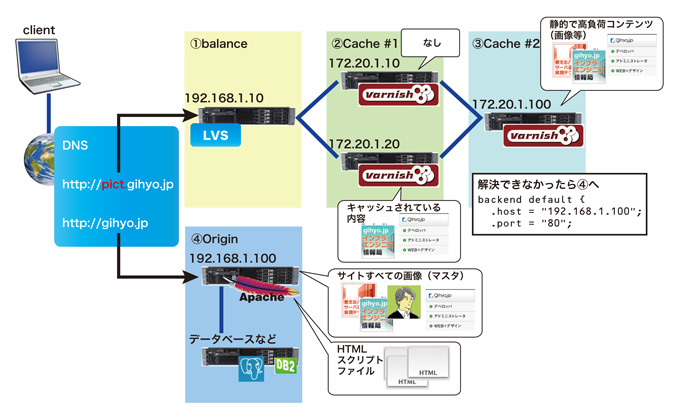
このような構成を構築することにより、実際に課金をするようなシステムやデータベースへの格納、その他重要な処理を行うサーバは④側へ分離することができますので、静的コンテンツを表示するためにセッションや(ネットワークも分けることができれば)帯域の消費が削減されます。
静的画像の他に、容量の大きいFLASHや音楽(楽曲)や動画系のコンテンツ等もランキングとダウンロードの割合に応じてあらかじめキャッシュ系(②~③)へ配置しておくことにより、④側の負荷を下げることができます。特に大きな容量のファイルをダウンロードする場合、④に対して、数秒~1分という単位でセッションを占有する場合もありますので、ピーク時のアクセスからシステムダウンしないような設計を検討すると良いでしょう。
本番で利用するために
インフラエンジニアとして本番環境にて利用する場合、障害などによるリスクに対する備えを検討する必要があります。varnishに関しては前述した通り、clientからoriginに向けたシーケンスに対しての処理の性能は光るものがあります。多段構成における親子関係は階層が深くなったとしてもその性能は秀逸です。
しかし、途中のサーバに障害が発生した場合とたんにいろいろな場所に負荷をかける事になります。それを回避するために、vclなどでさまざまな定義を入れておくことができますが、マシン自体をサービスアウトし、対応した後にサービスインさせる場合等はキャッシュが空の状態で参加させることになります。
その状態では全てのリクエストに対して上位サーバへ問い合わせることになりますので、「親」サーバに障害が発生した場合、全てoriginに対して負荷をかけることになります。originから見れば、clientから全てのリクエストを受けるのと変わりはなくなってしまいます。
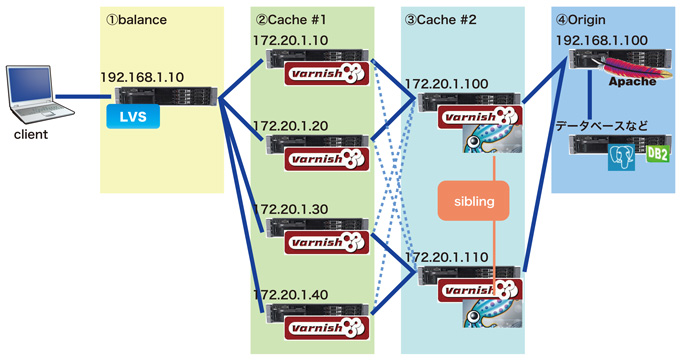
図4 障害時のキャッシュのはたらき
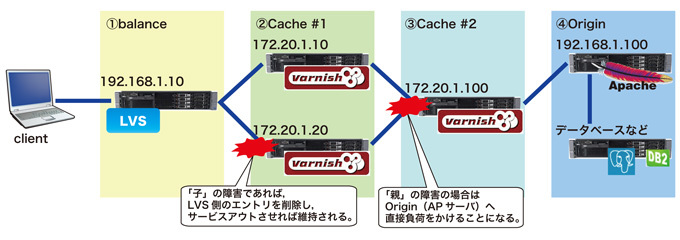
また、障害からの回復方法にも気を使う必要があります。基本的に、今まで溜め込んだキャッシュがなくなってしまう可能性が多い事から、アクセスが「親」または「origin」へ集中してしまう可能性があります。そのため、キャッシュを意識的に溜め込む必要があります。たとえば、利用者を絞って徐々に拡大していく方法もありますが、ミドルウェアで解決する方法もあります。
代表的な例では「親」「子」の考え方の延長でもある「兄弟」関係を構築する方法でsquidなどではおなじみのsibling構成です。現時点ではvarnish単体で実現させるには敷居が高い(というかわからない)ため、それに変わる運用を検討するか、障害からの回復時に「origin」への負荷を最小限に食い止める目的であれば「親」サーバにsquid等を同居させて「親」のsquid同士をsiblingさせておけば、サービスイン後はキャッシュが空の状態のvarnishがリクエストを受け取っても、同一筐体内のsquidへ問い合わせ、解決できる可能性が大きくなり、「origin」への負荷はそのままとなります。
図5 障害復帰を考慮した構成
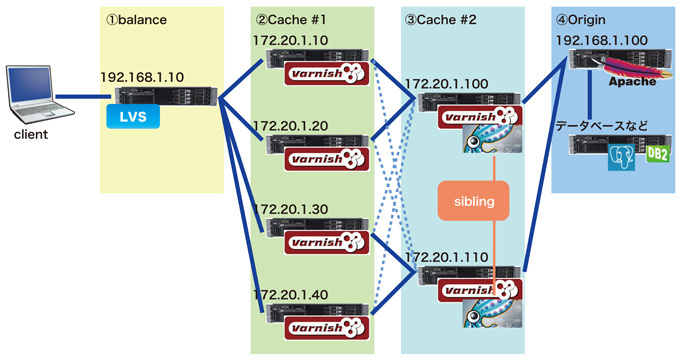
しかし、上記のような構成とした場合、今度は通常運用時の負荷を考慮する必要があります。たと例えば、キャッシュをクリアしたい等といった要請がアプリケーション部門から来る可能性があります。その際は、全てのvarnishとsquidに対してpurge処理を行う必要がありますので、そのシステムにあった様々なシチュエーションを考慮して設計できればと思います。
おわりに
いかがでしたでしょうか? 筆者も以前はApacheのキャッシュ機能で十分だと思っていたこともありましたが、リバースプロキシ・キャッシュや、それらを実現させるプロダクトのことを少しでも触り理解する機会があったなら、システムを設計する幅が広がるかと思います。
すでに大規模サービスで利用されている方々にはかなり物足りないかと思いますが、あまり触れる機会の無かった方々や、検討しなければと思っていた方々へのヒントとなれば幸いです。