みなさん、令和ですよ、令和。令月で気淑く風和らぐ令和ですよ。しかも十連休の真ん中あたりに令和になるなんて、令和さんまじやばい。さすが時和すだけのことはある。もういっそのこと毎日が令和だったらいいのに。ということで今回はUbuntuと令和のお話です。
なぜ令和?
念のため、まずは本連載 の趣旨を確認しておきましょう。
Ubuntuの強力なデスクトップ機能を活用するための、いろいろなレシピをお届けします。
最近はデスクトップに限らずサーバーや各種デバイス・サービスの紹介もしているものの、基本的にUbuntuに関連した記事となります。Ubuntuは内部的にはUNIX時間を採用しており、その単位は秒です。いろいろなコマンドやツールは月日の表示に対応しているものの、おそらくほとんどは西暦が標準でしょう。つまりUbuntuを使う上で日本の元号に触れることはほぼありません。
ではなぜ今回、Ubuntuと令和の話をするかと言うと理由は単純で、この記事が公開される日が改元の日でもある5月1日だからです。それだけです。そもそも大型連休の中日にUbuntuの記事を読むような人は、よっぽどUbuntu大好き人間 か、休日出勤という名の連休を楽しんでいる奇特な人 か、休日にも関わらず本記事の編集・査読と公開設定をしてくれる本連載の編集氏だけのはず。であれば大抵の悪ふざけは許してもらえると期待して、今回はいつもと趣向を考えた、あまり活用できないレシピをお届けすることにしたのです。
さて、Ubuntuは2004年10月にリリースされたので、平成16年生まれです。よって日本の元号が変わるのは今回がはじめての経験となります[1] 。改元どころか2000年問題も経験していない未成年です。実際、Ubuntuと同じく、改元は人生で初めてだという読者諸氏も多いことでしょう。きっと多いことでしょう。
[1] 実際のところLinuxカーネルの登場が平成3年(1991年)なので、昭和生まれのLinuxディストリビューションは存在しないはずです。ただしUnix系のソフトウェアはたまに時空を超えるので、昭和44年(1969年)末から昭和45年(1970年)あたりに生まれたことになっているものも存在するかもしれません。
しかもUbuntuは4月19日に19.04がリリースされたばかり です。つまり次の元号が発表された4月1日ごろにはすでにリリース向けのフリーズが迫っている状態であり、改元に伴う変更を取り込むには時間がない状態でした[2] 。第556回の末尾 でも少し言及はされていますが、結果的に19.04でもほぼ何も入っていない状態であり、正式な対応が行われた各種パッケージを取り込むのは、19.10以降になると思われます[3] 。
Ubuntuを令和対応にする
さて、19.04のリリースに令和対応が行われていないとしても、個別のソフトウェアの設定だけで対応可能な場合も多々あります。ここからは、ソフトウェアごとの対応方法を確認していきましょう。
日本語入力
元号を最も使う可能性があるケースは、日本語入力において元号そのものを入力することでしょう。UbuntuだとESMに入ったprecise以外はかな漢字変換システムとしてMozcを採用しています。よってMozcが対応する必要があります 。
Mozcに関して言えば、令和対応をUbuntuの公式リポジトリで提供予定です。少なくとも16.04、18.04、18.10、19.04がアップデートされる見込みです。さらにDebianや開発版の19.10では修正が既に取り込まれています。
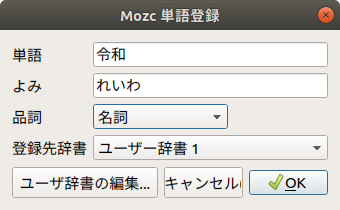
もし急ぎで対応したいなら、個人辞書に設定しておきましょう。画面右上の言語パネルから「ツール」の「単語登録」を選択します。品詞は「名詞」であとはそのままで良いでしょう。
図1 単語登録で令和を追加ちなみに19.04だとmozc-utils-guiが最初からインストールされていないために、「 ツール」が表示されないかもしれません。その場合は、システム設定の「地域と言語」から「インストールされている言語の管理」を選択し、表示される指示に従ってください。もしくは「sudo apt instal mozc-utils-gui」を直接実行する方法でもかまいません。
他にも今後は太上天皇の略称ではないほうの「上皇」や皇太子ではない「皇嗣」なんて単語を入力する機会が増えることになりますが、こちらはいずれも登録済みのようです。
かな漢字変換というカテゴリで言うと、anthyやskkdicなども辞書の更新が必要です。いずれもMozcのように個人辞書の登録で対応できるはずです。
ちなみにMozcや他のかな漢字変換には「ことし」や「2019ねん」と入力すると「平成31年」「 令和元年」と変換してくれる仕組みも存在します。これも個人辞書で回避可能ではあるので、必要なら登録しておきましょう。将来的なMozcパッケージのアップデートでは、このタイプの変換も令和に対応する見込みです。
フォント
「令」も「和」も常用漢字なので、一般的な日本語フォントであれば表示可能です。これに関して何か特別な対応を行う必要はありません。
フォントで影響してくるのは「合字」です。「 ㍻」や「㍼」の令和版で「㋿(U+32FF) 」となります。令和対応版のMozcなら「れいわ」で合字の令和も変換候補に出てきますが、そうでないなら「U+32FF」と入力してタブキーで変換すると出てくるはずです。
U+32FFは5月7日にリリース予定のUnicode 12.1 において、「 U+32FF SQUARE ERA NAME REIWA」として定義されます。この定義に合わせて各種フォントや文字を扱うソフトウェアが対応することになるのですが、最近のUbuntuで標準的に使われているNoto Sansフォントについては、4月10日にU+32FF対応版がリリースされています 。Noto Serifのほうは、源ノ角明朝 も含めてリリースされていないようです。
V2.001のSourceHanSans.ttc をダウンロードしてインストールしてみましょう。CJKすべて含むサイズの大きなファイルなので注意してください。
$ mkdir -p ~/.local/share/fonts
$ cp ~/ダウンロード/SourceHanSans.ttc ~/.local/share/fonts/
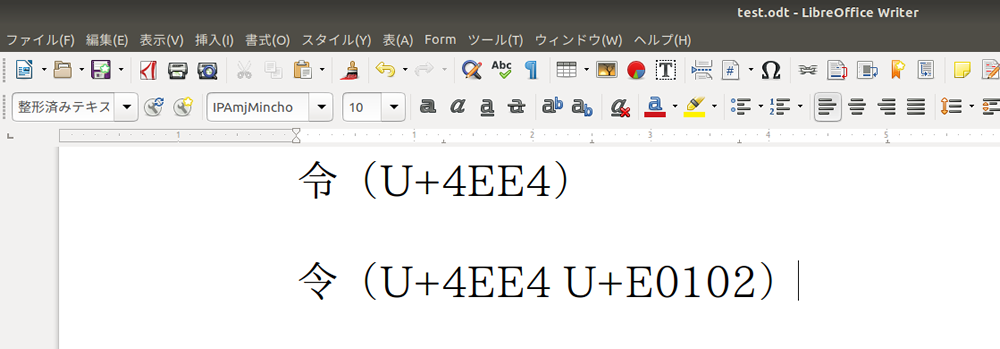
$ fc-cache -f -v これで「㋿(合字の令和) 」を表示できるようになりました。
図2 geditで合字の令和を表示した例「令」の字は下半分が「マ」になる異体字も存在します。通常の「令」が「U+4EE4」で、「 令󠄂(マのほう) 」が「U+4EE4 U+E0102 」です。残念ながらNotoフォントは令の異体字に対応していません。もし「マの令」を使いたいなら、別のフォントをインストールしましょう。たとえばIPAmj明朝フォント(fonts-ipamj-mincho)は「マの令」に対応しています。
図3 LibreOfficeでマの令を表示した例LibreOffice
LibreOfficeについては、6.2.3で令和に対応しています 。今のところ、Ubuntuの各リリースごとのLibreOfficeのバージョンは次のようになっています。
Ubuntu 16.04 LTS: 5.1.6 rc2
Ubuntu 18.04 LTS: 6.0.7
Ubuntu 18.10: 6.1.2
Ubuntu 19.04: 6.2.2
Ubuntu 19.10(開発版): 6.2.2
つまり公式リポジトリにおいては、2019年4月28日時点では令和対応版は入っていません。19.04についてはうまくいけば今後のリリースで対応されるかもしれません。
どうしても令和対応版のLibreOfficeが今すぐ必要なのであれば、一つの選択肢として「snap版のLibreOffice 」を使うという手があります。
$ sudo snap install libreoffice パッケージサイズは543MBと大きいのでストレージ容量やネットワークに注意してください。
snap版のLibreOfficeはDash上だと「LibreOffice 6...」と表示されます。パッケージ版のアイコンと同じなので混乱するかもしれませんが、うまくエスパーして選択してください。もしくはAlt+F2で表示されるダイアログから「libreoffice.calc」と実行するという手もあります。
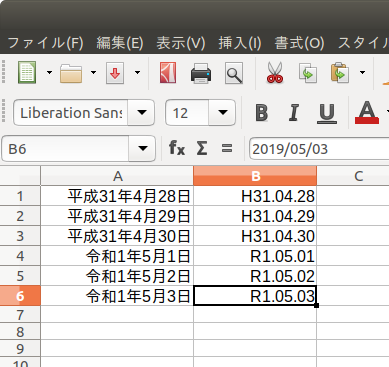
セルに「2019/04/28」と入力し、セルの書式設定から「日付」の「平成11年12月31日」や「H11.12.31」を選択します。その後、そのセルの右下をShift+クリックで下方向にドラッグすれば、日付がインクリメントされ、5月1日の時点で令和になるはずです。
図4 LibreOffice Calcで日付の連番表示snap版ではなくパッケージ版のLibreOfficeが必要であれば、こちらのブログ記事 を参照してください。
OpenJDK
OpenJDKにも元号に対応したAPIがあります。よって日本の元号に依存したソフトウェアを使っている場合、OpenJDK(のJRE)を更新する必要があります。
Ubuntuの場合、各リリースのOpenJDKパッケージのバージョンは次のような状態です。
Ubuntu 16.04 LTS: 8u191-b12 / OpenJDK 11は非対応
Ubuntu 18.04 LTS: 8u191-b12 / 11.0.2+9
Ubuntu 18.10: 8u191-b12 / 11.0.2+9
Ubuntu 19.04: 8u212-b01[4] / 11.0.3+7
Ubuntu 19.10(開発版): 8u212-b03 / 11.0.3+7
つまりOpenJDK 8だと19.10以降、OpenJDK 11だと19.04以降で対応していることになります。
ただこれまでの慣習的にOpenJDKのセキュリティアップデートは、ほぼ新バージョンへのアップグレードと等価なので、おそらくOpenJDK 8/11いずれも、近いうちに令和対応版に更新されるものと思われます。
glibc
実はglibcにも元号に関する情報が含まれています。たとえば次のような方法で、元号を表示する際に使われます。
$ LC_ALL=ja_JP.UTF-8 date +%Ex -d 20190501
平成31年05月01日 これはglibcのlocalesパッケージが提供する、「 /usr/share/i18n/locales/ja_JP 」で設定されています。2019年5月1日以降を令和にしたいのであれば、このファイルを編集する必要があるのです。
上記修正はすでにglibcの本体には適用されています 。また、19.04のglibcにもs390向け修正にひっぱられる形で glibc本体の修正が取り込まれています。
もし古いリリースで同様の対応を行いたい場合は、localesファイルを修正することになるでしょう。しかしながら「/usr/share/i18n/locales/ja_JP 」を直接編集してしまうと、glibcのアップデート時に上書きされてしまいます。ここでは「/usr/local/share/i18n/locales/ja_JP 」を作成し、そこに令和対応を記述することにします。
$ sudo mkdir -p /usr/local/share/i18n/locales
$ sudo cp /usr/share/i18n/locales/ja_JP /usr/local/share/i18n/locales/
$ sudo vi /usr/local/share/i18n/locales/ja_JP
$ diff -u /usr/share/i18n/locales/ja_JP /usr/local/share/i18n/locales/ja_JP
--- /usr/share/i18n/locales/ja_JP 2018-04-17 05:14:20.000000000 +0900
+++ /usr/local/share/i18n/locales/ja_JP 2019-04-28 21:18:59.414194981 +0900
@@ -14946,7 +14946,9 @@
t_fmt_ampm "%p%I<U6642>%M<U5206>%S<U79D2>"
-era "+:2:1990//01//01:+*:<U5E73><U6210>:%EC%Ey<U5E74>";/
+era "+:2:2020//01//01:+*:<U4EE4><U548C>:%EC%Ey<U5E74>";/
+ "+:1:2019//05//01:2019//12//31:<U4EE4><U548C>:%EC<U5143><U5E74>";/
+ "+:2:1990//01//01:2019//04//30:<U5E73><U6210>:%EC%Ey<U5E74>";/
"+:1:1989//01//08:1989//12//31:<U5E73><U6210>:%EC<U5143><U5E74>";/
"+:2:1927//01//01:1989//01//07:<U662D><U548C>:%EC%Ey<U5E74>";/
"+:1:1926//12//25:1926//12//31:<U662D><U548C>:%EC<U5143><U5E74>";/ これでファイルの変更は完了です。追加された行は上から順番に「令和2年以降を表示する期間」「 令和元年を表示する期間」「 平成2年以降を表示する期間」となります。
さらに実際にlocalesファイルからロケールデータを生成しましょう。
$ sudo locale-gen ja_JP.UTF-8
Generating locales (this might take a while)...
ja_JP.UTF-8... done
Generation complete. 実際にdateコマンドを実行すると期待通りの動作になっていることがわかります。
$ LC_ALL=ja_JP.UTF-8 date +%Ex -d 20190501
令和元年05月01日
$ LC_ALL=ja_JP.UTF-8 date +%Ex -d 20190430
平成31年04月30日
$ LC_ALL=ja_JP.UTF-8 date +%Ex -d 20200501
令和2年05月01日 その他のパッケージ
今回は代表的なパッケージを紹介しましたが、他にも関連しそうなパッケージはいくつも存在します。
たとえば5月上旬にはU+32FFに対応したUnicode 12.1がリリースされる予定です。このUnicodeの情報はUbuntuだとunicode-dataパッケージで提供されています[5] 。unicodeコマンドは、このunicode-dataを元に、文字の各種属性を教えてくれるツールです。
[5] Unicodeの各文字の属性を元に挙動を変える必要があるソフトウェアは多々あります。有名なのがEast Asian Width の中で定義されている「東アジア圏だと全角だけどそれ以外の地域だと半角になる文字」です。ソフトウェア側できちんとハンドリングしないと、文字幅がずれてしまうことになります。よってlessコマンドのように、Unicodeが提供するデータをソフトウェアが保持していることが多々あるのです。
$ unicode ㍻
U+337B SQUARE ERA NAME HEISEI
UTF-8: e3 8d bb UTF-16BE: 337b Decimal: ㍻ Octal: \031573
㍻
Category: So (Symbol, Other)
Unicode block: 3300..33FF; CJK Compatibility
Bidi: L (Left-to-Right)
Decomposition: <square> 5E73 6210
$ unicode ㋿
U+32FF - No such unicode character name in database
UTF-8: e3 8b bf UTF-16BE: 32ff Decimal: ㋿ Octal: \031377
㋿ (㋿)
Uppercase: 32FF
Category: Cn (Other, Not Assigned)
Unicode block: 3200..32FF; Enclosed CJK Letters and Months unicode-dataはまだ古いままなので、「 平成」は期待通りの結果ですが、「 令和」のほうは「No such unicode character」と言われてしまってますね。
同じくUnicode由来のソフトウェアとして、ICU(International Components for Unicode) が存在します。ICUは64.2でUnicode 12.1に対応したようです。しかしながらUbuntuは最新の19.04でも63.1のままです。
ICUのライブラリであるlibicuXXは、Node.jsやLibreOfficeなど、かなり多くのパッケージから依存されています。よってリリース後のアップグレードは難しいのですが、必要になる理由を丁寧に説明できれば、取り込んでもらえる可能性はあります。
U+32FF用のグリフについてはCMapが更新されているため、poppler-dataもAdobe-Japan1-7 へ追随する必要があるかもしれません。