


2020年が始まりました。
テキストファイルにメッセージを埋め込める「stegsnow」
半角スペースはASCIIコードで
結果として
さて、
コンピューターの世界でも、
今回紹介する
インストールは単にリポジトリからパッケージをインストールするだけです。
$ sudo apt install stegsnow
stegsnowでデータを埋め込む
まずはあらかじめ埋め込み対象のプレーンテキストを用意しておきます。これは任意の行長で改行されたテキストが想定されています。埋め込んだデータをやり取りすることから、
stegsnow自身は、-l」
元データから埋め込みデータへのエンコードはタブ文字で区切られた最大7個の半角スペースによって実現しています。つまりタブ文字とタブ文字の間の半角スペースの数で、
さらに前述したとおり、
今回は例として、
「ではみなさんは、そういうふうに川だと言われたり、乳の流れたあとだと言
われたりしていた、このぼんやりと白いものがほんとうは何かご承知ですか」
先生は、黒板につるした大きな黒い星座の図の、上から下へ白くけぶった銀河
帯のようなところを指しながら、みんなに問いをかけました。
カムパネルラが手をあげました。それから四、五人手をあげました。ジョバ
ンニも手をあげようとして、急いでそのままやめました。たしかにあれがみん
な星だと、いつか雑誌で読んだのでしたが、このごろはジョバンニはまるで毎
日教室でもねむく、本を読むひまも読む本もないので、なんだかどんなことも
よくわからないという気持ちがするのでした。
ところが先生は早くもそれを見つけたのでした。
「ジョバンニさん。あなたはわかっているのでしょう」
ジョバンニは勢いよく立ちあがりましたが、立ってみるともうはっきりとそ
れを答えることができないのでした。ザネリが前の席からふりかえって、ジョ
バンニを見てくすっとわらいました。ジョバンニはもうどぎまぎしてまっ赤に
なってしまいました。先生がまた言いました。
「大きな望遠鏡で銀河をよっく調べると銀河はだいたい何でしょう」
やっぱり星だとジョバンニは思いましたが、こんどもすぐに答えることがで
きませんでした。
先生はしばらく困ったようすでしたが、眼をカムパネルラの方へ向けて、
「ではカムパネルラさん」と名指しました。
するとあんなに元気に手をあげたカムパネルラが、やはりもじもじ立ち上が
ったままやはり答えができませんでした。このテキストに
$ stegsnow -m "けれども本当の幸いは一体なんだろう" body.txt output.txt Message exceeded available space by approximately 29.52%. An extra 4 lines were added.
「-m」
最後のメッセージではデータが入り切らなかったので、
実際に生成されたテキストファイルを開いてみると次のように表示されます。
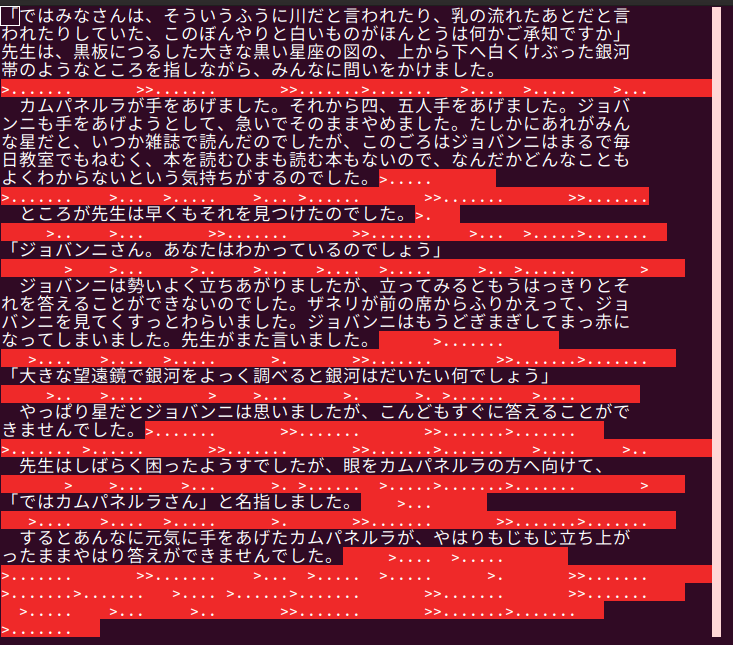
タブは>...」
上記を見る限り、
たとえば-S」
$ stegsnow -S body.txt File has storage capacity of between 317 and 335 bits. Approximately 40 bytes.
今回のファイルだとたかだが40バイト程度であり、
最大行長を指定する-l」
$ stegsnow -l 120 -m "けれども本当の幸いは一体なんだろう" body.txt output.txt Message used approximately 63.75% of available space.
今度は行の追加が必要なかったようですね。
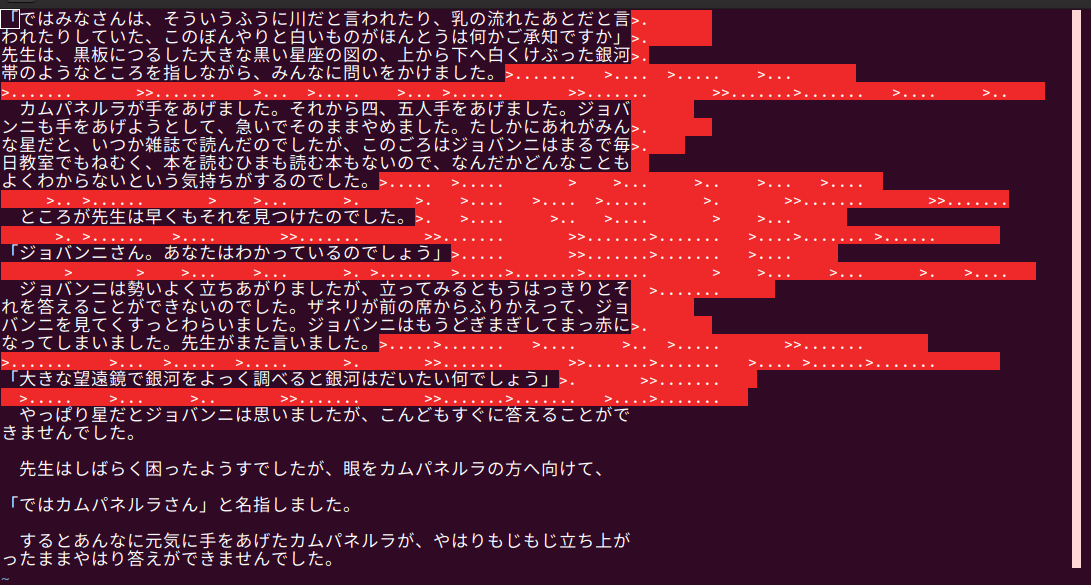
今回は右の縦のラインは120文字の部分です。右端の位置がまちまちですが、
さて次は出力されたファイルから、
$ stegsnow output.txt けれども本当の幸いは一体なんだろう
日本語のデータもきちんと取り出せましたね。ちなみに上記のような-m」-m メッセージ」-f ファイル名」
さらにファイル名を指定すると、
$ stegsnow output.txt message.txt $ cat message.txt けれども本当の幸いは一体なんだろう
データを圧縮して埋め込む
さて、
stegsnowは-C」
$ stegsnow -C -m "けれども本当の幸いは一体なんだろう" body.txt output.txt Compressed by 4521260802379791872.00% Message exceeded available space by approximately 240.00%. An extra 26 lines were added.
圧縮率がおかしいことになっていますね。さらに圧縮前に比べると追加される空行も増えています。実はstegsnowは英文に最適化された静的なハフマンテーブルを利用して圧縮します。このため、-f」
ちなみに英文を埋め込んだ場合だとどうなるのでしょう。
未圧縮の場合: $ stegsnow -m "Night on the Galactic Railroad" body.txt output.txt Message used approximately 84.21% of available space. 圧縮した場合: $ stegsnow -C -m "Night on the Galactic Railroad" body.txt output.txt Compressed by 40.00% Message used approximately 48.00% of available space.
圧縮が効いた結果、
圧縮データが含まれたテキストファイルをデコードする場合も-C」
$ stegsnow -C output.txt Night on the Galactic Railroad
データを暗号化して埋め込む
stegsnowはICE暗号化アルゴリズムを利用したデータの暗号化にも対応しています。-p」
$ stegsnow -l 120 -m "けれども本当の幸いは一体なんだろう" -p "パスワード" body.txt output.txt Message used approximately 63.75% of available space.
まずはパスワード無しでデコードしてみましょう。
$ stegsnow output.txt
.~6AZnJY7
y"ҪxZC4O&1k^6うまくデコードできず意味不明の文字列になってしまいましたね。
次はパスワードを付けてデコードします。
$ stegsnow -p "パスワード" output.txt けれども本当の幸いは一体なんだろう
今度は無事にデコードできました。
決して強度のある暗号化アルゴリズムではないので、