Linuxカーネルも人類が生み出したものである以上、既知であれ未知であれなんらかの不具合を抱えています。そしてそれは「都合の悪い時」に限って顕在するものです。今回は「やたらとカーネルがフリーズする」不幸な星のもとに生まれた人に向けて、カーネルがクラッシュしたときのデバッグ方法を紹介しましょう。
カーネルだってつらいときはあるんです
Linuxカーネルには「クラッシュダンプ」と呼ばれる仕組みが存在します。これはカーネルがどうしようもない自体に陥ったとき(=panicしたとき)、システムを再起動する前に障害収集用のシステムを起動し、現象発生直後のカーネルのメモリーをストレージに保存する機能です。これを使えば、panic時の原因を追求することが可能です[1]。
UbuntuをはじめとするLinuxディストリビューションにとって、Linuxカーネルはまさに「縁の下の力持ち」と言える存在です。
ハードウェア・ファームウェアに関わるあれやこれやを一手に引き受けることで、機種や世代による細々とした違いを吸収し、新しいハードウェアのサポートを行い、ハードウェア固有のよくわからない不具合を可能な限り隠蔽してくれます。Linuxディストリビューションが広く使われ、さまざまなアプリケーションが登場しているのも、ひとえにLinuxカーネルのおかげと言っても過言ではないでしょう。
言い方を変えると、「コンピューターに関するめんどくさいこと」の大半はカーネルに押し付けていることになります。普段から面倒事を押し付けられる人ならわかってもらえると思うのですが、これは結構なストレスです。もちろん調子のいいときならある程度なんとかできるものの、そういうことが続くと気持ちがつらくなってきますし、そのうち爆発してしまうこともあるでしょう。これはカーネルだって同じです。
- ひたすらスピンロックで待ち続けるお行儀の悪いサードパーティのドライバー
- 設定が悪いとひたすら割り込みし続けるデバイス
- 変なトランザクションを受けるとSoCごと停止するコントローラー
- ソフトリセットかけるとNMI panicを誘発するデバイス
- リードするとたまに仕様と全然違う値が返ってくるレジスタ
- 意味もなくメモリーを確保しながらCPU負荷を上げ続けるユーザープロセス
カーネルはできる限り「なんとかしよう」と「がんばる」わけではありますが、どうしようもないときはもう「どうしようもない」と言うしかないんです。しかも状況によっては「どうしようもない」と伝える術すら奪われているケースもしばしば存在します。しかしながら、どれもユーザーから見ると「なんかカーネルが固まった」としか見えないため、だいたい「カーネルが悪い」の一言で済まされます。よくある中間管理職の悲哀ですね。
本来はより上位に位置するシステム管理者が、カーネルの状況を把握し不調のサインを見つけたら随時ケアするのが理想です。ただ、よっぽど優秀な組織でない限りは、上位の管理者が下位の存在に対して、日常的にこまめな管理・配慮をすることはありません。よって結果的に「問題が起きてから対応する」という結果にならざるを得ないのです[2]。
前置きが長くなりましたが、今回はカーネルの「クラッシュダンプ」システムを利用して、「問題が起きたときに原因を追求する」方法を紹介します。
情報の引き継ぎは重要です
問題が起きたときにやるべきことは、現象発生時の状況の把握です。たとえばどんな操作したときに発生したのかとか、どんなエラーログが残っているのか、再現性はあるのかとか、そのような情報が必要になります。しかしながらカーネルにおいて回復不能なトラブルが発生した場合、再起動する以外に手は存在しません。つまりなんとかして、再起動後に「問題発生時の情報を引き継ぐ」必要があるのです。
Ubuntuには「Apport」と呼ばれる障害情報収集システムが存在します。これはユーザープロセスがコアダンプしたとき、その中身やプロセスの情報をまとめて、必要に応じてUbuntuのチケットトラッキングシステムであるLaunchpadに報告する仕組みです。Ubuntu 12.04 LTSあたりから、常に有効化されるようになったので、「なんかプロセスが落ちた」ときに「残念ながら内部エラーが発生しました」というダイアログを見たことがある人も多いでしょう。
「ユーザープロセスが死ぬ」状態であればカーネルがケアすることは可能です。しかしながら「カーネル内部に問題がある」ときは、カーネル側ではどうしようもないことが多々あります。さらに「問題が起きたことを通知する」方法も限られます。運が良ければコンソールに何か出力することが可能ですが、最近のLinuxシステムだとカーネルメッセージをディスプレイに表示していることは稀です。そこで出てくるのが「クラッシュダンプ」システムです。
Linuxカーネルにはkexecと呼ばれる仕組みが存在します。これはメモリー上にカーネル本体とinitramfsをあらかじめ展開しておき、このカーネルとinitramfsに処理を移す仕組みです。仕組みと見た目上はカーネルの再起動になるのですが、ハードウェアの初期化やUEFI/BIOS、ブートローダーの処理を飛ばせるので「高速な再起動」になります。また、極端な言い方をすると「メモリー上の特定の場所にジャンプする」だけで実現できるので、ストレージが動かないような状況でも実行できます[3]。
クラッシュダンプシステムでは、カーネル起動時にあらかじめ障害情報収集用のカーネル(クラッシュカーネル)とinitramfs用のメモリー領域をあらかじめ確保しておき、panic時にはそのカーネルを起動するようになっています。これによりpanic時のカーネルメモリーの中身がほぼそのままの状態でクラッシュカーネルが起動します。クラッシュカーネル側は、それを任意のストレージに保存することで、「問題発生時の現場」を保存できるわけです。
Ubuntuにおいて「クラッシュダンプシステム」として必要なパッケージ・設定は「linux-crashdump」パッケージにまとまっています。そこでまずはこれをインストールしましょう。
$ sudo apt install linux-crashdump
このインストールの際に、2件ほど質問が表示されます。
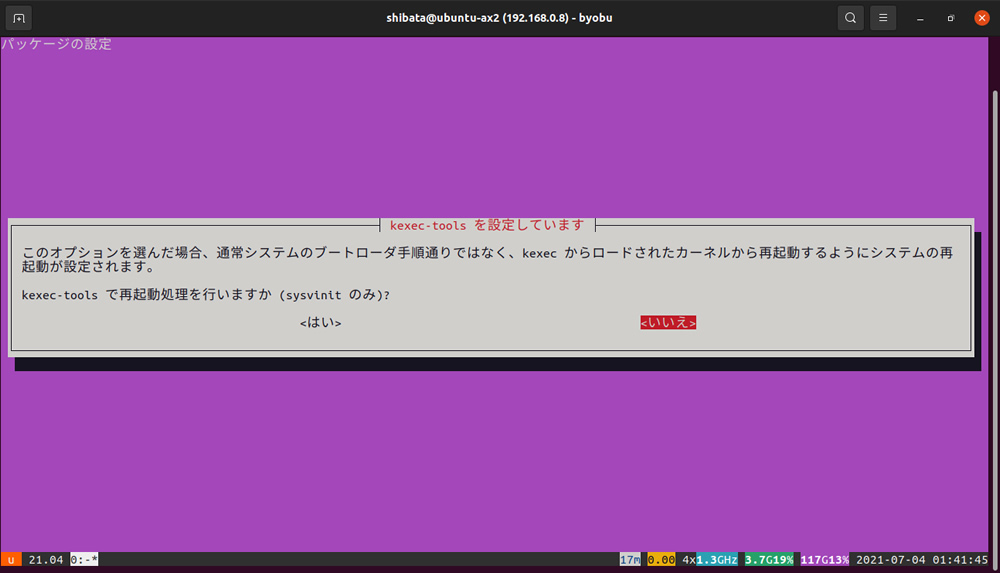
図1 kexec-toolsで再起動処理を行うかどうか
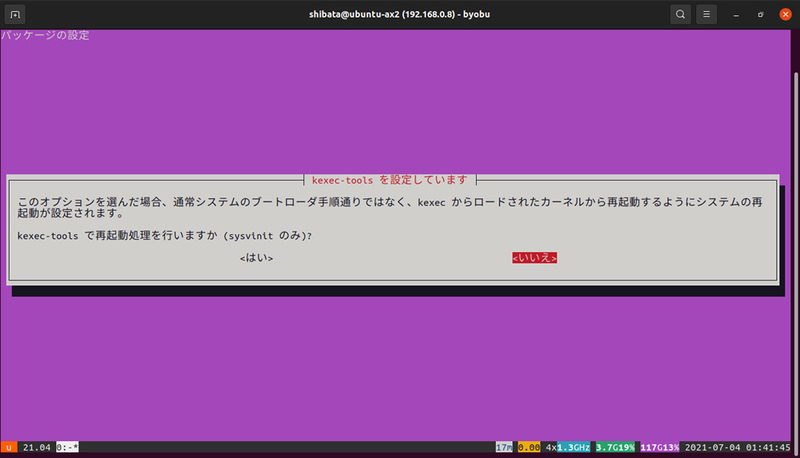
最初は「kexec-tools」の設定で、「kexec-toolsで再起動処理を行いますか?」というものです。これは通常の再起動処理を行う際、UEFI/BIOSからの再起動(PCだとACPIリブート)を実施せず、kexecでロードしたメモリー上のカーネルを起動するかどうかを確認しています。再起動時間は短くなるものの、ハードウェアの初期化等はスキップされます。一般的なPCにおいて「再起動したい」ときは、だいたい「クリーンな状態から起動し直したい」ケースが多いので、ここは「いいえ」を選んでおくと良いでしょう。サーバー等でカーネル更新によるダウンタイムを短くしたいときには有効な設定です。なお、インストール後も「/etc/default/kexec」の「LOAD_KEXEC」を「true」にして再起動すれば、設定を「はい」にしたときと同じ状態にできます。
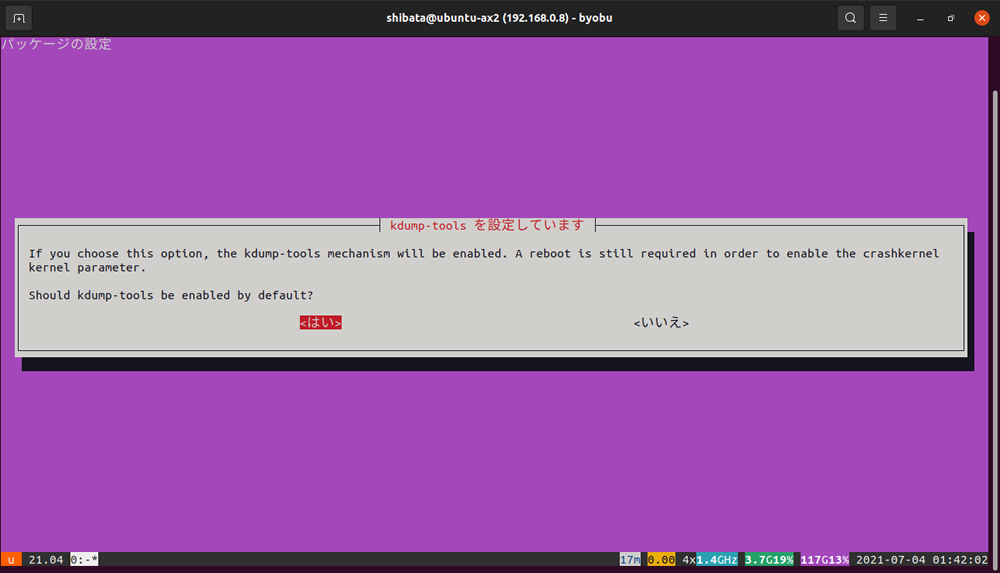
図2 クラッシュダンプシステムを有効化するかどうか
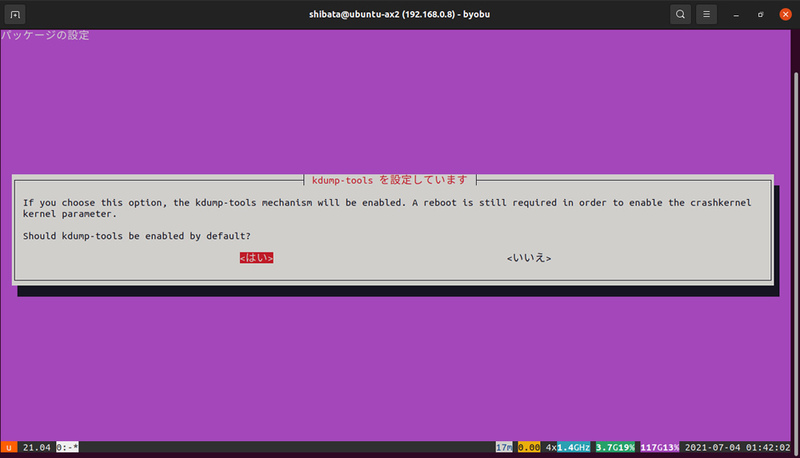
次が「kdump-tools」の設定で、クラッシュ発生時にクラッシュダンプシステムを起動するかどうかを問い合わせています。今回はこちらを利用するため「はい」を選んでおいてください。メッセージにもあるように、有効化するためには一度再起動が必要になります。この設定も「/etc/default/kdump-tools」の「USE_KDUMP」を0か1にすることで設定の変更が可能です。
ちなみに上記において、おおよそ追加でインストールされるファイルは次のとおりです。
- kexec-tools
- kdump-tools
- makedumpfile
- crash
前述したようにkexec-toolsがkexec用にカーネル・initramfsをメモリー上に展開するツールです。kdump-toolsは、このkexec-toolsを利用してクラッシュダンプシステムを起動するために必要な設定・サービスを提供しています。具体的にはブートローダーから、クラッシュシステム用のカーネルパラメーターを設定したり、起動処理の途中でクラッシュシステムをメモリー上にロードしたりする作業です。
makedumpfileは、クラッシュシステム上でクラッシュ前のカーネルメモリー(/proc/vmcore)を保存するためのコマンドを提供しています。/proc/vmcoreはとても大きなファイルなので、障害情報として有用なものだけに限定して取り出したほうが良いことが多々あります。そのあたりの処理を担ってくれるのがmakedumpfileです。最後のcrashは、障害情報の内容を確認するためのデバッガーです。もし障害情報の精査を他のマシンで行うなら、インストールしなくてもかまいません。
linux-crashdumpをインストールしたあとは、一度再起動しておく必要があります。次回起動時から、クラッシュダンプシステム用のカーネルメモリーが確保され、そこにシステムがロードされるからです。
実際に再起動したあとは次のコマンドを実行してみましょう。
$ cat /proc/cmdline
BOOT_IMAGE=/boot/vmlinuz-5.11.0-22-generic root=UUID=afa22713-4378-4e8d-b662-496ef2b318d0 ro quiet splash crashkernel=512M-:192M vt.handoff=7
ここで「crashkernel=512M-:192M」がクラッシュシステム用に確保される領域です。
- メモリーサイズが512MiB以下ならクラッシュシステムはロードしない
- メモリーサイズが512MiB以上なら、512MiB以降の領域に192MiB予約する
予約した領域は通常のカーネルから利用されることはありません。クラッシュシステムのカーネルとinitramfsがロードされ、クラッシュシステムが起動したときにこの領域が利用されます。
無事にクラッシュシステムの準備が整ったので、次のコマンドを実行して、意図的にpanicさせてみましょう。念のため、アプリケーションは一通り終了させておいてください。
$ echo "c" | sudo tee /proc/sysrq-trigger
おそらく画面が固まり、キーボードやマウスの操作はできなくなるはずです。しばらく待つとスプラッシュスクリーンが表示され、そのうちPC自体が再起動するでしょう。通常のログイン画面が表示されたら、障害情報は収集済みの状態になります。クラッシュダンプシステムは、自動的に障害情報を収集・保存したあとは、再起動するようになっています。つまりPC自体が再起動し、普通に起動したときのようにPCのロゴが表示される時点で、障害情報の収集は完了済みです。
収集された障害情報はApportと同じように、「/var/crash」以下に保存されています。
$ ls -R /var/crash/
/var/crash/:
202107040335 _usr_bin_seahorse.1000.crash kdump_lock kexec_cmd linux-image-5.11.0-22-generic-202107040335.crash
/var/crash/202107040335:
dmesg.202107040335 dump.202107040335
ここで日付ディレクトリになっているのが、実際に収集したものです。dmesgがpanicが発生したときのカーネルログの内容で、dumpがvmcoreを保存したものです。またLaunchpadに報告できるように、Apportフォーマットのcrashファイルも生成されています。
とりあえずdmesgの中身を見てみましょう。これだけでどこで問題が起きたかはわかるはずですし、運が良ければ原因までたどり着けます。
(前略)
[ 6262.530024] sysrq: Trigger a crash
[ 6262.530033] Kernel panic - not syncing: sysrq triggered crash
[ 6262.530045] CPU: 3 PID: 111191 Comm: tee Kdump: loaded Tainted: G S C E 5.11.0-22-generic #23-Ubuntu
[ 6262.530049] Hardware name: Panasonic Corporation CF-AX2QEBJR/CFAX2-1L, BIOS V1.11L14 10/16/2012
[ 6262.530051] Call Trace:
[ 6262.530056] show_stack+0x52/0x58
[ 6262.530063] dump_stack+0x70/0x8b
[ 6262.530067] panic+0x101/0x2e3
[ 6262.530072] sysrq_handle_crash+0x1a/0x20
[ 6262.530077] __handle_sysrq.cold+0x48/0x120
[ 6262.530082] write_sysrq_trigger+0x28/0x40
[ 6262.530086] proc_reg_write+0x5a/0x90
[ 6262.530091] ? _cond_resched+0x1a/0x50
[ 6262.530095] vfs_write+0xc6/0x270
[ 6262.530098] ksys_write+0x67/0xe0
[ 6262.530101] __x64_sys_write+0x1a/0x20
[ 6262.530104] do_syscall_64+0x38/0x90
[ 6262.530107] entry_SYSCALL_64_after_hwframe+0x44/0xa9
[ 6262.530111] RIP: 0033:0x7f3a4110cc27
[ 6262.530114] Code: 0d 00 f7 d8 64 89 02 48 c7 c0 ff ff ff ff eb b7 0f 1f 00 f3 0f 1e fa 64 8b 04 25 18 00 00 00 85 c0 75 10 b8 01 00 00 00 0f 05 <48> 3d 00 f0 ff ff 77 51 c3 48 83 ec 28 48 89 54 24 18 48 89 74 24
[ 6262.530118] RSP: 002b:00007ffeb514fbd8 EFLAGS: 00000246 ORIG_RAX: 0000000000000001
[ 6262.530122] RAX: ffffffffffffffda RBX: 0000000000000002 RCX: 00007f3a4110cc27
[ 6262.530124] RDX: 0000000000000002 RSI: 00007ffeb514fcc0 RDI: 0000000000000003
[ 6262.530126] RBP: 00007ffeb514fcc0 R08: 0000000000000002 R09: 0000000000000001
[ 6262.530127] R10: 00000000000001b6 R11: 0000000000000246 R12: 0000000000000002
[ 6262.530129] R13: 00005622844eb4e0 R14: 0000000000000002 R15: 00007f3a411e68a0
今回はteeコマンドで、sysrq-triggerを利用してpanicをさせました。上記だと「Comm: tee」でpanic時のユーザープロセスがteeであることもわかりますし、バックトレースのwrite_sysrq_triggerで、sysrq-triggerに何かを書いたことがわかります。
この収集自体は「/usr/sbin/kdump-config」が担っています。つまりこのシェルスクリプトの中身を見れば、おおよそ何をやっているかがわかるはずです。また、このスクリプトは通常起動時の、クラッシュカーネルのロードやKernel Oops時のpanic実行(sysctlのkernel.panic_on_oops設定)も担当しています。
次回はこの取得したクラッシュダンプを、crashコマンドとデバッグシンボル付きパッケージを用いてより詳細に解析してみます。