


今回はmdraidを使ったソフトウェアRAID環境における
そこで今回は少しでも再構築作業がスムーズに進むように、その予行演習を行いましょう。今回もLXDで構築した仮想RAID環境を利用します。LXDを用いてソフトウェアRAID環境を構築する方法は、次の回を参考にしてください。第748回ではRAID 1のみ、第749回ではそれ以外のRAIDレベルを紹介しています。
RAIDにおける再構築(リビルド)とは
RAIDは複数のストレージにデータを複製して書き込んだり、データのパリティを書き込むことで耐障害性をあげる仕組みです。つまりどれかのストレージが壊れたとしても、壊れていないストレージが一時的にデータを補完してくれます。
ポイントは
言い換えると再構築というのは、RAID構成においてどれか1台以上が壊れたときに、システム管理者が人生をかけて祈りをこめる時間です。壊れていないほうのストレージの視点に立つと、なんか仕事仲間がいきなり行方不明になった上に、その仕事仲間の分以上の負荷をいきなりかけてきて、こちらをぶっ壊しに来ているんじゃないかと感じる時間でもあります。立場によって印象が変わる良い例でもあります。
再構築を試すには、RAIDに参加するストレージが
- 故障扱いとするストレージを取り外す
- 故障扱いとするストレージを適当な値で上書きする
mdadmコマンドの「 --fail」オプションを使う
中途半端に読み書きできるとか、たまに特定のATAコマンドが失敗するとかそういう細やかなエラーをシミュレートするのは大変ですが、
ちなみに2番目の上書き方式についてはすぐにエラーを検知してくれるとは限りません。また、たとえばRAID 1の場合
今回利用するLXD環境だと、2番目の上書き方式や3番目のmdadmコマンドを使う方式はオンラインで実施できますが、1番目のストレージの取り外しは一度インスタンスをシャットダウンしないといけない点に注意が必要です。
RAID 1でエラーを起こす
まずは第748回で構築したRAID 1環境
第748回だとRAID 1は
$ lxc stop raid1 $ lxc config device remove raid1 root Error: Cannot update root disk device pool name to "default"
LXDの場合、インスタンス生成時にdefaultプロファイルから自動的にrootストレージが作成されます[2]。これを正しく消すにはいろいろ手順がやっかいです。これが
ちなみにUbuntu上で/dev/」/dev/」lxd_名前」lxd_」lxd_」
シリアル番号を確認する方法はいろいろありますが、Ubuntuに最初から入っているツール等を使うならlsblkコマンドを実行する、カーネルが作るファイルを直接見る、lshwコマンドの結果を読むあたりでしょうか。前者の2種類をそれぞれ紹介しましょう。
$ lsblk --nodeps -o name,serial /dev/sda NAME SERIAL sda lxd_root $ ls -l /dev/disk/by-id/ | grep "sda$" lrwxrwxrwx 1 root root 9 Feb 11 11:52 scsi-0QEMU_QEMU_HARDDISK_lxd_root -> ../../sda lrwxrwxrwx 1 root root 9 Feb 11 11:52 scsi-SQEMU_QEMU_HARDDISK_lxd_root -> ../../sda
これで/dev/はLXD的にはrootであり、/dev/はLXD的にはlxd_であることがわかります。そこで今回は、取り外しやすいlxd_を削除する前提で話を進めましょう。まず、インスタンスは終了しているものとします。
$ lxc storage volume detach raid raid1b raid1
これでraid1インスタンスからraid1bボリュームが見えなくなりました。試しにraid1インスタンスを起動しましょう。起動したら、次のようにステータスを確認してみてください。
$ cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid1 sda2[1]
40806400 blocks super 1.2 [2/1] [_U]
unused devices: <none>
activeにsda2」UU」_U」
$ sudo mdadm --detail /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Sat Feb 11 14:27:13 2023
Raid Level : raid1
Array Size : 40806400 (38.92 GiB 41.79 GB)
Used Dev Size : 40806400 (38.92 GiB 41.79 GB)
Raid Devices : 2
Total Devices : 1
Persistence : Superblock is persistent
Update Time : Sat Feb 11 14:39:43 2023
State : active, degraded
Active Devices : 1
Working Devices : 1
Failed Devices : 0
Spare Devices : 0
Consistency Policy : resync
Name : ubuntu-server:0
UUID : 17576c13:c379fb90:efd533d3:041cd124
Events : 372
Number Major Minor RaidDevice State
- 0 0 0 removed
1 8 2 1 active sync /dev/sda2
こちらもStatus : active, degraded」Total Devices」
ちなみに
$ sudo mdadm --fail /dev/md0 /dev/sdb2
こちらはmdadm --detail」faulty spare」
RAID 1のdegraded状態からの回復
さて、ここからRAID 1の回復を試みましょう。ここら先については状況次第で手順が変わります。なるべく一般的な方法で説明していきましょう。
もしmdadm --fail」
$ sudo mdadm --remove /dev/md0 /dev/sdb2
次にストレージの交換です。マシンにもよっては電源が入ったまま入れ替えることも可能ではありますが、個人で使うPCならとりあえず電源を切ってからストレージの入れ替えになるでしょう。今回の環境はLXDなので、次のように新しいカスタムストレージボリューム
$ lxc storage volume create raid raid1c --type=block size=40GiB Storage volume raid1c created $ lxc storage volume attach raid raid1c raid1
ここでマシンを起動することになるわけですが、できれば生き残っているストレージを優しく扱いところです。方法はいくつかあります。
- UbuntuサーバーのインストールISOファイルを使って、Live環境から回復させる
- Ubuntuの
「recovery mode」 で、他のプロセスを動かさずに回復させる - 気にせず普通に起動して、普通に回復させる
ストレージに頻繁に読み書きするタスクが動く状況なら、できれば1番目か2番目の方法をとりたいところです。
ちなみに1番目については、RAIDアレイが自動的に

余計なことをせずにデータを退避したい場合は読み込み専用にしておくと安心ではありますが、もしLive環境で回復したければまず次の方法で書き込み可能にしておいてください。
# mdadm --readwrite /dev/md127
2番目の
1番目・
パーティションレイアウトの複製
今回はESPを同じストレージに保存した都合上、ストレージ全体がRAIDアレイに追加されているわけではなく、一部のパーティションのみが追加されている状態です。よって新しいストレージも前回と同じパーティションレイアウトにしないといけません。特にRAID 1の場合はRAIDアレイに参加している既存のストレージのうち最も小さいサイズに揃ってしまう都合上、パーティションのサイズにも気をつける必要があります。
パーティション分割せずにストレージ全部をまとめてRAIDアレイに参加させて良い場合は、この方法はスキップしてもOKです。ただしその場合、この先のmdadmコマンドに渡すデバイスファイル名が変わる/dev/が/dev/になる)
パーティションレイアウトは、RAIDアレイに参加する他のストレージと同じにして良いなら、sfdiskを使うのが楽です。まずは次のように設定をスクリプトに変更します。
$ sudo sfdisk -d /dev/sda > /run/user/$UID/sda.part $ cat /run/user/$UID/sda.part label: gpt label-id: 5A20BB4C-7401-480A-9D83-CAC8DAF8D8BC device: /dev/sda unit: sectors first-lba: 34 last-lba: 83886046 sector-size: 512 /dev/sda1 : start= 2048, size= 2201600, type=C12A7328-F81F-11D2-BA4B-00A0C93EC93B, uuid=4EE3366D-7B56-4F79-8DDF-56A65097E3C6 /dev/sda2 : start= 2203648, size= 81680384, type=0FC63DAF-8483-4772-8E79-3D69D8477DE4, uuid=57A881D9-556B-451C-932E-8AA3BBD5A044
このまま取り込むとlabel-idやuuid等が/dev/と/dev/で同じになってしまいますので、消してしまいます。
$ grep -v "^label-id" /run/user/$UID/sda.part | sed -e 's/, *uuid=[0-9A-F-]*//' > /run/user/$UID/sda.part.new
これを/dev/に反映しましょう。
$ sudo sfdisk /dev/sdb < /run/user/$UID/sda.part.new $ sudo parted /dev/sdb print Model: QEMU QEMU HARDDISK (scsi) Disk /dev/sdb: 42.9GB Sector size (logical/physical): 512B/512B Partition Table: gpt Disk Flags: Number Start End Size File system Name Flags 1 1049kB 1128MB 1127MB boot, esp 2 1128MB 42.9GB 41.8GB
これで追加するストレージの準備ができました。
パーティションをRAIDアレイに参加させ再構築を開始する
パーティションの準備ができたので、RAIDアレイに参加させます。
$ sudo mdadm --add /dev/md0 /dev/sdb2 mdadm: added /dev/sdb2
重要なのは、
もちろん今回はテスト環境なので失敗したところで大したことはないのですが、テスト環境から慎重に作業できないような人が、本番環境のトラブル時に慎重になれるはずがありません。
無事に追加されたら、今回のケースだと自動的に再構築が始まります。
$ cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md0 : active raid1 sdb2[2] sda2[1]
40806400 blocks super 1.2 [2/1] [_U]
[>....................] recovery = 1.9% (801792/40806400) finish=2.4min speed=267264K/sec
unused devices: <none>
$ sudo mdadm --detail /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Sat Feb 11 14:27:13 2023
Raid Level : raid1
Array Size : 40806400 (38.92 GiB 41.79 GB)
Used Dev Size : 40806400 (38.92 GiB 41.79 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Sat Feb 11 16:59:14 2023
State : clean, degraded, recovering
Active Devices : 1
Working Devices : 2
Failed Devices : 0
Spare Devices : 1
Consistency Policy : resync
Rebuild Status : 4% complete
Name : ubuntu-server:0
UUID : 17576c13:c379fb90:efd533d3:041cd124
Events : 743
Number Major Minor RaidDevice State
2 8 18 0 spare rebuilding /dev/sdb2
1 8 2 1 active sync /dev/sda2
今回はサイズが小さくシンプルな構成なので、数分で終わりそうですがサイズが大きかったり、パリティ計算が必要だったりするとそれなりの時間がかかります。その間はできる限りそっとしておきましょう。必死にがんばっている時に、ちょくちょく
/proc/のfinish=」
回復後のESPの同期
システム用のストレージをRAIDとして組む時、ESP
しかしながら、今回の手順で再構築した場合、ESPの領域は空のままになってしまいます。そこで、次の手順を用いて手動で同期しておきましょう。
/dev/sdb1をFATでフォーマットしておく
$ sudo mkfs.vfat /dev/sdb1
mkfs.fat 4.2 (2021-01-31)
念の為、/etc/default/grubをバックアップ
$ sudp cp /etc/default/grub{,.bak}
ESPを同期する
$ sudo dpkg-reconfigure grub-efi-$(dpkg --print-architecture)
Installing grub to /var/lib/grub/esp.
Installing for x86_64-efi platform.
Installation finished. No error reported.
Installing grub to /boot/efi.
Installing for x86_64-efi platform.
Installation finished. No error reported.
Sourcing file `/etc/default/grub'
Sourcing file `/etc/default/grub.d/init-select.cfg'
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-5.15.0-60-generic
Found initrd image: /boot/initrd.img-5.15.0-60-generic
Warning: os-prober will not be executed to detect other bootable partitions.
Systems on them will not be added to the GRUB boot configuration.
Check GRUB_DISABLE_OS_PROBER documentation entry.
Adding boot menu entry for UEFI Firmware Settings ...
done
Processing triggers for shim-signed (1.51+15.4-0ubuntu9) ...
最後のコマンドは画面にさまざまな設定が表示されます。最初のコマンドラインの設定はUbuntuデスクトップならquiet splash」/etc/を/etc/に戻してsudo update-grub」
一番重要なのが最後に表示される
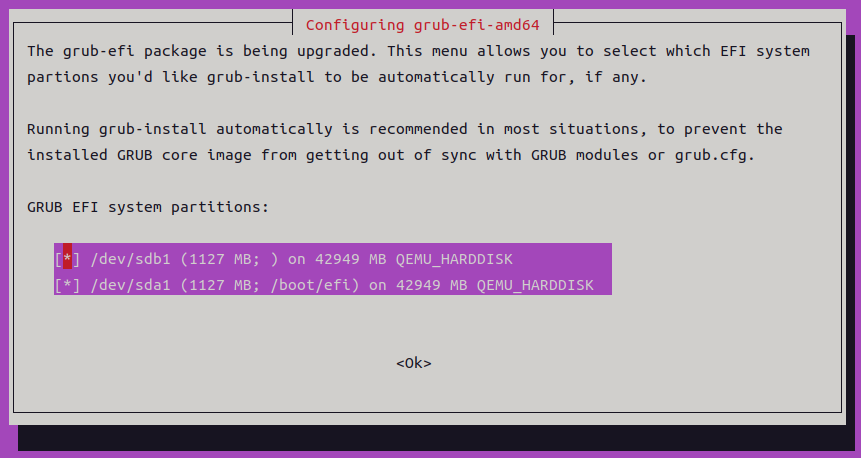
ここまで設定しておけば、GRUBパッケージ等の更新があった場合も、dpkgが自動的にすべてのESPのGRUBを更新してくれます。
RAIDのスーパーブロックについて
Linux MD/
スーパーブロックの位置や内容はLinux MD/cat /proc/」mdadm --detail /dev/」
$ cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4] [linear] [multipath] [raid0] [raid1] [raid10]
md0 : active raid5 sdc2[1] sdb2[0] sda2[3]
81612800 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/3] [UUU]
^^^ ここがバージョン
$ sudo mdadm --detail /dev/md0
/dev/md0:
Version : 1.2
^^^ ここがバージョン
1.
$ sudo parted /dev/sda unit KiB print Model: QEMU QEMU HARDDISK (scsi) Disk /dev/sda: 41943040kiB Sector size (logical/physical): 512B/512B Partition Table: gpt Disk Flags: Number Start End Size File system Name Flags 1 1024kiB 1101824kiB 1100800kiB fat32 boot, esp 2 1101824kiB 41942016kiB 40840192kiB
Ubuntuサーバーのインストーラーの設定をそのまま使えば、ESPは上記のように1024KiBから1GiB程度確保されており、RAID用のパーティションは先頭から1101824KiBの位置にあるようです。つまり/dev/なら先頭から4KiBの位置に、/dev/ならプラス4KiBして1101828KiBにスーパーブロックが存在することになります。
$ sudo dd if=/dev/sda2 status=none bs=4KiB count=1 skip=1 | hd 00000000 fc 4e 2b a9 01 00 00 00 00 00 00 00 00 00 00 00 |.N+.............| 00000010 65 e6 f3 27 8b 22 8a 65 00 0d e3 d1 5a e1 da 1c |e..'.".e....Z...| 00000020 75 62 75 6e 74 75 2d 73 65 72 76 65 72 3a 30 00 |ubuntu-server:0.|
最初のfc 4e 2b a9
特定のストレージないしパーティションのスーパーブロックは次のコマンドで削除します。古いストレージを再構築で追加することは早々ないとは思いますが、もしそういう事態になったときは忘れないようにしておきましょう。
/dev/sda2のスーパーブロックの削除 $ sudo mdadm --zero-superblock /dev/sda2
mdadmの監視と通知
mdadmパッケージにはRAIDのステータスを監視し、通知を送る仕組みが最初から組み込まれています。
- mdmonitor.
service: 「 mdadm --monitor --scan」を起動し、RAIDの状態が変わった場合は /etc/のメールアドレスに通知を送るmdadm/ mdadm. conf - mdmonitor-oneshot.
timer:毎日 「 mdadm --monitor --scan --oneshot」を実施し、その度に通知を送る
メールの送信はsendmailコマンドがインストールされている必要がありますmdadm.にPROGRAM行を追加することで任意のコマンドを実行可能です。今ならメールを送るよりも、任意のコマンドを使ってSlack等のチャットシステムに通知するほうがうれしいかもしれません。
PROGRAMの使い方についてはmdadm.
定期的なスクラビング
RAIDはデータブロックにアクセスして初めて問題を認識します。つまりサイレントに何か問題が発生し、そのまま誰もアクセスしなかったら、誰も気がつけない状態となります。一番やっかいなのが
Linux MD//sys/」check」/proc/」check」
さて、Ubuntuの場合はこのスクラビングもmdcheck_が実施しています。実際の処理は/usr/」/sys/の値)
このスクリプトはsystemdのtimer機能により、systemctl edit mdcheck_」OnCalendar」RandomizedDelaySec」
$ systemctl cat mdcheck_start.timer
# /lib/systemd/system/mdcheck_start.timer
# This file is part of mdadm.
#
# mdadm is free software; you can redistribute it and/or modify it
# under the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
[Unit]
Description=MD array scrubbing
[Timer]
OnCalendar=Sun *-*-1..7 1:00:00
RandomizedDelaySec=24h
Persistent=true
[Install]
WantedBy=mdmonitor.service
Also=mdcheck_continue.timer
$ systemd-analyze calendar 'Sun *-*-1..7 1:00:00'
Original form: Sun *-*-1..7 1:00:00
Normalized form: Sun *-*-01..07 01:00:00
Next elapse: Sun 2023-03-05 01:00:00 UTC
From now: 3 weeks 0 days left
ちなみにシステムのシャットダウン時にスクラビングが動いている場合は、blk-availability.によって実行された/sbin/の中で、スクラビングが完了するまで待つことになります。つまり、スクラビングに時間がかかる環境だと、月始めの日曜日にシャットダウンしようとすると、シャットダウンまでに数時間かかることも起こりえます。
気になるようなら、blk-availability.のdrop-inファイルを作って、ExecStopの-r wait」idle」sync_」
最後に重要なことを。第748回からここまで3回にわたってRAIDの記事を読んだ方なら自明かもしれませんが