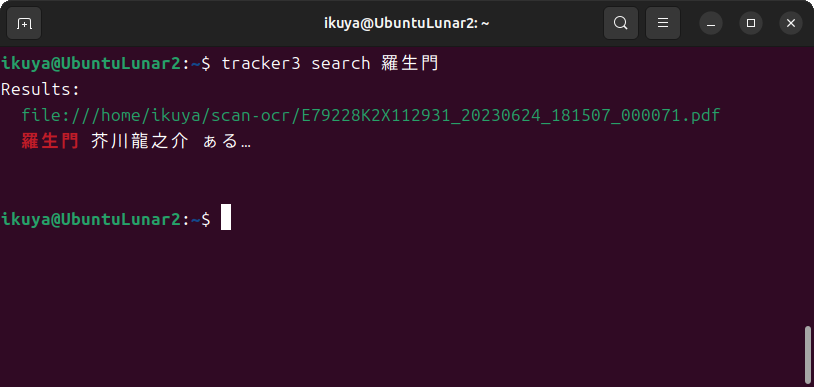
今回はブラザーのスキャナーでスキャンした結果を自動的にOCRを実行します。SambaやOCRmyPDF、Tesseract OCRなど、オープンソースソフトウェアだけで構成します。
紙の書類をなんとかしたい
ペーパーレスなんて言葉はもう聞き飽きてしまいましたが、実際にペーパーレスが達成されたかというとそういうわけでもないことはみなさんも日々感じていることでしょう。
なにかのサービスに契約したらユーザー名とパスワードは郵送されてくるなんてことはむしろ最近増えています。本人確認のためには致し方ないところではありますが。
昔のWi-Fiルーターはメーカーによって初期ユーザー名とパスワードが決まっていましたが、セキュリティ的には問題しかありません。そのため最近はWi-Fiルーターの箱にユーザー名とパスワードが書かれた紙
ではどうすればいいのでしょうか。今どきだとスマートフォンで撮影してクラウドストレージにアップロードすると自動的にOCRにかけてくれるようになっていますが、本連載としてはUbuntuでなんとかしたいところです。
なぜOCRが必要なのかというと、たくさんの書類からお目当てのものを探すのは大変です。なのでOCR結果をPDFに埋め込み、全文検索をかければ簡単に探せるようにしたいからです。
紙のいいところは探しやすいところですが、スキャンとOCRと全文検索を組み合わせてデジタル化しても紙に似た探しやすさに近づけたいところです。
とはいえ、今回は全文検索に関してはあまり詳しく紹介しません。
使用するスキャナー
紙をスキャンするにはスキャナーが必要です。スキャナーは何でもいいですが、今回はブラザーのADS-1700Wを購入しました。
価格が安いこと、使用しないときは小さく折り畳めることが主な購入理由ですが、
使用するUbuntu
今回使用するOCRmyPDFと、そのバックエンドのバージョンの都合で、使用するUbuntuのバージョンは23.
なお、それ以降のバージョンでも同様に動作するはずです。
共有フォルダーの設定
22.
ちょうどその間に開発が再開されており、皮肉にも22.
ホームフォルダー以下に
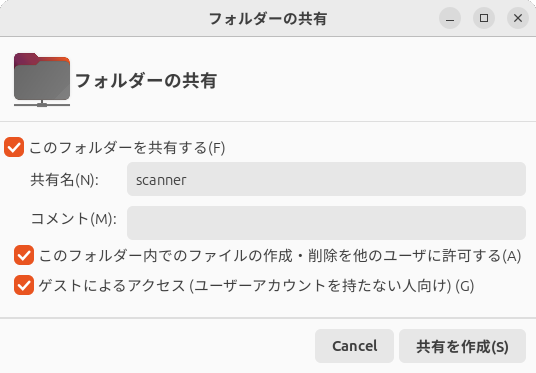
また、ホームフォルダーの所有者
次のコマンドを実行してください。
$ sudo pdbedit -a $USER
スキャナーの設定
スキャン結果のPDFを共有フォルダーに置くため、スキャナーの設定を変更します。ADS-1700Wでは、Webインターフェースにログイン後パスワードを入力して管理者になります。
「スキャン」
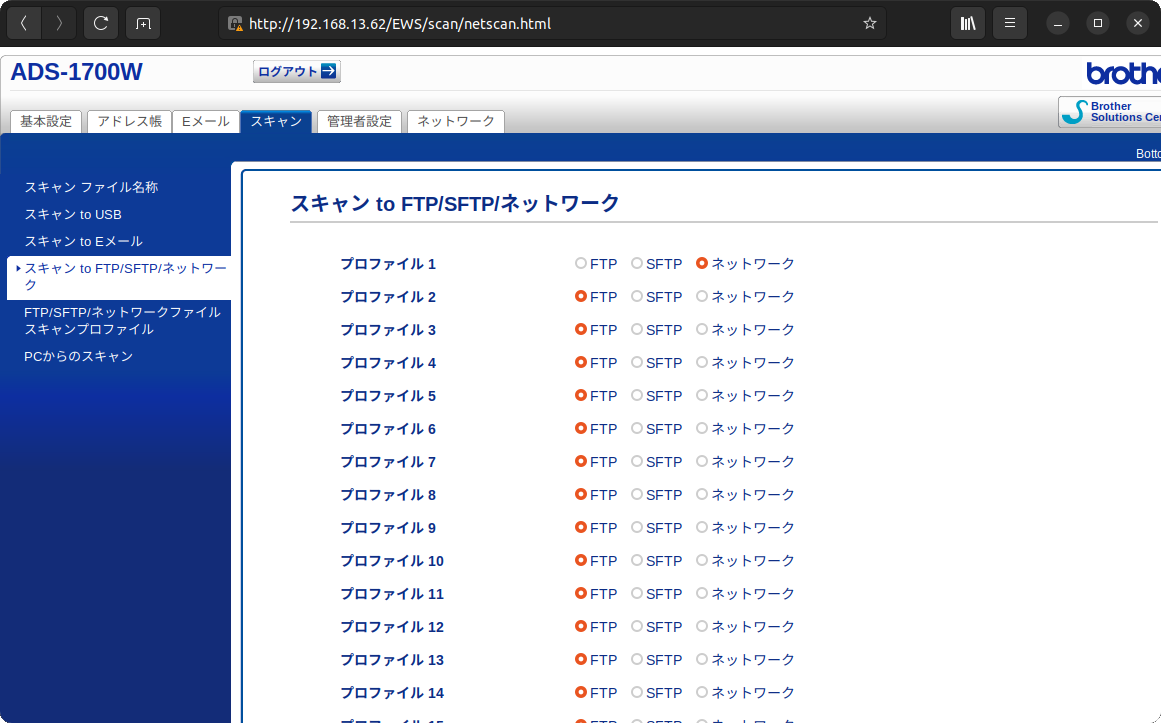
「FTP/
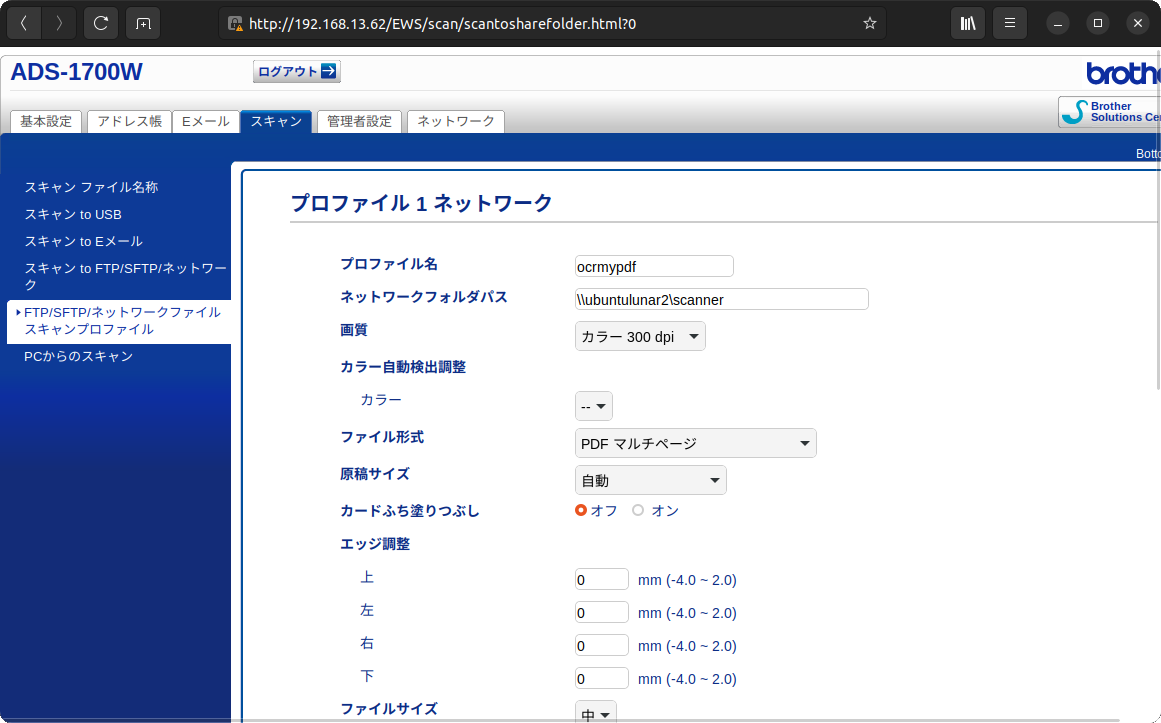
この段階でいったんスキャンを行い、正しく動作するか確認するといいでしょう。
サンプルドキュメント
今回使用するサンプルドキュメントは、程々の長さかつポピュラーで読みやすく、誰でも知っていて著作権上の問題がないという理由から
OCRmyPDFのインストール
OCRは、OCRmyPDFを使用します。OCRmyPDFは活発に開発されており、リリースも多いです。Ubuntu 23.
というわけでパッケージをインストールします。次のコマンドを実行してください。
$ sudo apt install ocrmypdf tesseract-ocr-jpn --no-install-recommends
ここからもわかるとおり、OCRmyPDFのバックエンドはTesseract OCRです。
OCR試行錯誤
まずはラフにOCRを実行してみましょう。次のコマンドを実行してください。
$ cd ~/scanner $ ocrmypdf -l jpn (スキャン済みPDF) (OCR実行後のPDF)
なお、今回はスキャン済みPDFのファイル名はE79228K2X112931_、OCR実行後のPDFはE79228K2X112931_としています。
OCR実行後のPDFを開き、Ctrl+aキーで全選択してCtrl+cキーでコピーし、テキストエディターを起動して貼り付けると、OCR結果を簡単に確認できます
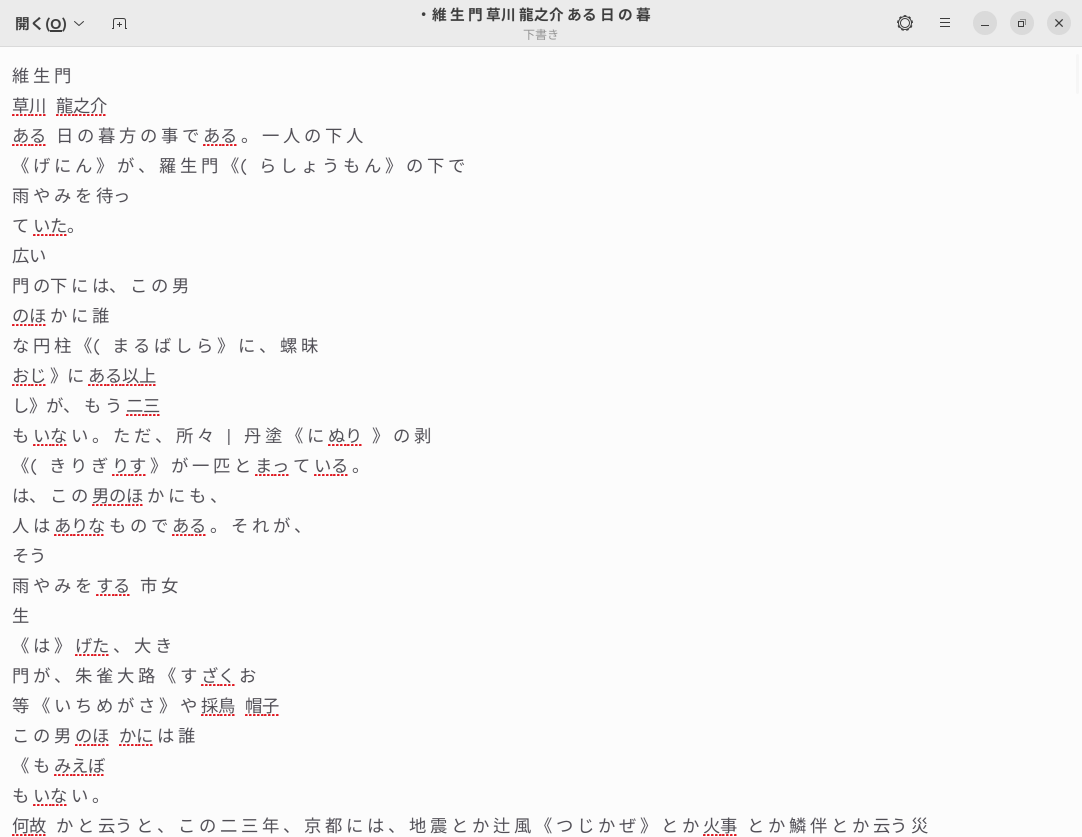
結果を見てみると、全然ダメで全く使い物になりません。OCRmyPDFのバックエンドであるTesseract OCRには多数のオプションがあるので、もう少しマシにならないか確認していきましょう。
OCR結果を見てみると、文字間にスペースが入っています。これだと全文検索が思うように実行できないので、なんとかしたいところです。
不具合報告を調査すると、
これはどうにかするのが難しそうなので、別のアプローチを取ってみましょう。
Tesseract OCRのmanをよく読むと、OCR Engine Mode
というわけで、0から3
$ ocrmypdf -l jpn --tesseract-oem 0 (スキャン済みPDF) (OCR実行後のPDF)
すると[tesseract] Error: Tesseract (legacy) engine requested, but components are not present in /usr/」
どういうことかとよく調べてみると、Tesseractの言語データはtessdata、tessdata_
このうち、Ubuntuのリポジトリにあるのはtessdata_です。これはtesseract-ocr-jpnパッケージのchangelog.からわかります。
これをtessdataに置き換えればよさそうです。次のコマンドを実行してください。
$ wget https://github.com/tesseract-ocr/tessdata/archive/refs/tags/4.1.0.tar.gz $ tar xf 4.1.0.tar.gz $ sudo cp tessdata-4.1.0/jpn.traineddata /usr/share/tesseract-ocr/5/tessdata/jpn.traineddata $ rm -r 4.1.0.tar.gz tessdata-4.1.0/
あまりいいやりかたではありませんが、これでおおむね問題ないでしょう。Ubuntuを23.
Snapパッケージだと都合が悪いというのはこのあたりで、日本語データを置き換えることができません。
再び次のコマンドを実行して結果を確認してみましょう。
$ ocrmypdf -l jpn --tesseract-oem 0 (スキャン済みPDF) (OCR実行後のPDF)
精度が格段に向上しています

必須ではありませんが、OCRを実行する前にページの可読性を向上させるオプションもあります。古い紙をスキャンするような場合には、有効にしておくといいでしょう。
次のコマンドを実行し、unpaperパッケージをインストールします。
$ sudo apt install unpaper --no-install-recommends
オプションを追加してOCRを実行します。
$ ocrmypdf -l jpn --tesseract-oem 0 --clean (スキャン済みPDF) (OCR実行後のPDF)
自動実行
手動ではうまくいくようになったので、残すは自動実行できるようにするだけです。OCRmyPDFのドキュメントにBatch processingがあるので、ここで紹介されているwatcher.
注意点としては、入力用フォルダーと出力用フォルダーを明確に分けないといけないところです。今回は入力用を~/scanner、出力用を~/scan-ocrとします。
次のコマンドを実行して、準備してください。
$ mkdir ~/.local/bin ~/scan-ocr $ wget https://raw.githubusercontent.com/ocrmypdf/OCRmyPDF/master/misc/watcher.py -O ~/.local/bin/watcher.py
watcher.
$ OCR_INPUT_DIRECTORY=~/scanner/ OCR_OUTPUT_DIRECTORY=~/scan-ocr/ OCR_POLL_NEW_FILE_SECONDS=5 OCR_ON_SUCCESS_DELETE=1 OCR_JSON_SETTINGS='{"language": "jpn", "tesseract-oem": "0", "clean": null}' python3 ~/.local/bin/watcher.py
詳細は前出のBatch processingのページを確認してほしいのですが、OCRmyPDFのオプションをJSONにしないといけません。OCR_はファイルが作成されてからOCRを実行するまでの秒数です。今回の5秒は少ないページ数ではいいかもしれないものの、もっと長いページでは足りないかもしれません。適宜変更してください。
あとはこれをsystemdのユーザーセッションで自動実行するようにすればいいでしょう。次のコマンドを実行してください。
$ systemctl edit --user --full --force watcher.service
エディターが開くので、次の内容としてください。
[Unit]
Description=Watch a directory for new PDFs and OCR them
[Service]
Environment=OCR_INPUT_DIRECTORY=%h/scanner/
Environment=OCR_OUTPUT_DIRECTORY=%h/scan-ocr/
Environment=OCR_POLL_NEW_FILE_SECONDS=5
Environment=OCR_ON_SUCCESS_DELETE=1
Environment=OCR_JSON_SETTINGS='{"language": "jpn", "tesseract-oem": "0", "clean": null}'
WorkingDirectory=%h/scanner
ExecStart=/usr/bin/python3 %h/.local/bin/watcher.py
[Install]
WantedBy=default.target
あとは有効にするだけです。次のコマンドを実行してください。
$ systemctl enable --now --user watcher.service
この段階ではscan-ocrフォルダーは共有されていないので、必要であれば共有してください。
全文検索
全文検索に関しては、詳しくは紹介しません。Ubuntuということでデフォルトの全文検索エンジンであるTrackerを使用する場合は、scan-ocr)
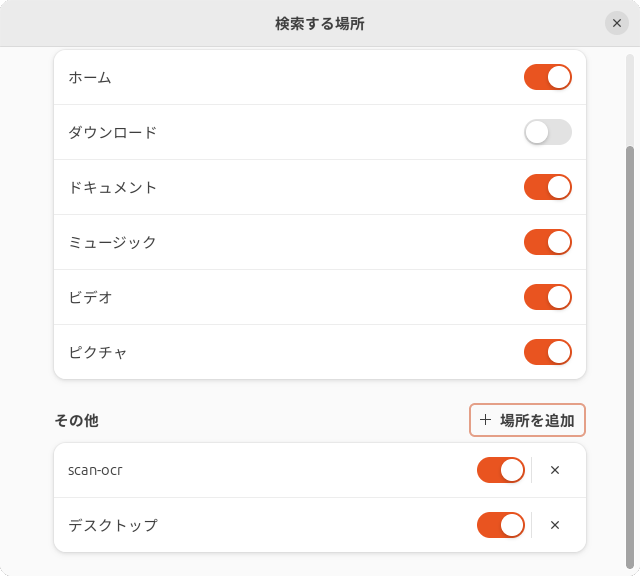
あとは端末から検索します