ChatGPTをはじめとした生成AIにおけるここ数年の勃興は語るまでもありません。特にユーザーからの自然言語による対話をもとに文章を生成する仕組みは、すでに趣味や研究の範囲を超えて各分野の業務でも広く使われるようになりつつあります。その自然言語の理解と文章の生成に貢献している概念のひとつが、
今回はそんなLLMのうち個人でも利用可能で軽量なモデルの入門として、まずはUbuntu上で動かす方法について紹介しましょう。
ローカルLLMの実行環境として定番のOllama
ChatGPTにしろGeminiにしろ、これらはいずれも
そこで出てくる手段のひとつが
現在LLMの実行環境として広く使われているものに、Go言語で作られた
Ollamaのインストール自体はシンプルです。もともとGo言語で作られた単一ファイルのバイナリが配布されているために、libc以外には依存関係もなく、それを取り込めば良いだけです。公式に
$ curl -fsSL https://ollama.com/install.sh -O もしくは $ wget https://ollama.com/install.sh
公式サイトの説明ではダウンロードしたスクリプトをそのままshコマンドに渡していますが、一般的には中身も確認せずにスクリプトを実行するのは危険です。一度内容を精査した上で、実行することを心がけてください。ちなみに、sudo等でスクリプト全体を管理者権限で実行するのではなく、必要に応じてsudoコマンドを使う作りになっているあたりは良心的な作りです。
なお、install.
- CPUアーキテクチャーやLinuxディストリビューション、WSL2かどうかなどの環境を確認する
- Ollamaの実行バイナリをダウンロードし
「 /usr/」local/ bin/ ollama として配置する - ollamaユーザーとグループを作成し、ollamaユーザーをrenderグループとvideoグループに、スクリプトの実行ユーザーをollamaグループに所属させる
/etc/を作成し、起動時にOllamaをデーモンとして起動するよう設定するsystemd/ system/ ollama. service - AMDもしくはNVIDIAのGPUを探す
- AMDのGPUが見つかりROCmもインストールされていたら、ROCm版のOllamaバイナリに差し替える
- NVIDIAのGPUが見つかり、nvidia-smiがインストールされていなかったら、NVIDIAのドライバーやツールキットをインストールする
最低限必要なのは/usr/」
ちなみにNVIDIAのドライバーやツールキットはUbuntuの公式パッケージでもNVIDIAのサードパーティのバイナリパッケージでもかまいません。Ubuntuの公式パッケージを使いたいならあらかじめ次のようにインストールして、一度再起動しておいてください。
Ubuntuデスクトップで、デスクトップ向けのGPUとして使いたい場合: $ sudo ubuntu-drivers install もしくは $ sudo apt install nvidia-driver-XXX 画面の描画等はせずに、純粋にGPGPUとして使いたい場合: $ sudo ubuntu-drivers install --gpgpu もしくは $ sudo apt install nvidia-driver-XXX-server
基本的にはubuntu-driversコマンドが自動検知して、適切なパッケージをインストールしてくれます。ただし新しいGPUや通常とDevice ID等が異なるGPUだと、ubuntu-driversがうまく検知できないかもしれません。その場合は後者のaptコマンドを使って直接インストールする方法を試してください。
ここでXXX」sudo apt install nvidia-driver-」
GUIからインストールしたければ第817回の
それではinstall.を実行しましょう。内部でcurlコマンドも使っているため、先にそれをインストールしています。
$ sudo apt install curl $ bash install.sh >>> Downloading ollama... (中略) >>> Installing ollama to /usr/local/bin... [sudo] shibata のパスワード: >>> Creating ollama user... >>> Adding ollama user to render group... >>> Adding ollama user to video group... >>> Adding current user to ollama group... >>> Creating ollama systemd service... >>> Enabling and starting ollama service... Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service. >>> NVIDIA GPU installed.
サービスファイルが自動的に有効化され、起動しているためにOllamaのバックエンドも起動しています。
$ command -v ollama
/usr/local/bin/ollama
$ ollama --version
ollama version is 0.3.3
$ systemctl status ollama.service
● ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; preset: enabled)
Active: active (running) since Sun 2024-08-04 16:19:27 JST; 50s ago
Main PID: 3326 (ollama)
Tasks: 18 (limit: 76734)
Memory: 1.2G (peak: 1.2G)
CPU: 7.990s
CGroup: /system.slice/ollama.service
└─3326 /usr/local/bin/ollama serve
(後略)
Llama 3.1モデルを試してみる
無事にOllamaをインストールできたら、さっそく言語モデルを試してみましょう。Ollamaでは、いくつかのメジャーな言語モデルをかんたんにインストールできます。使えるモデルはOllamaサイトのモデル一覧から確認できます。
このうちMetaが開発する
$ ollama run llama3.1 pulling manifest (中略) verifying sha256 digest writing manifest removing any unused layers success >>> Send a message (/? for help)
初めてモデルを実行する場合は、/usr/」
ちなみに
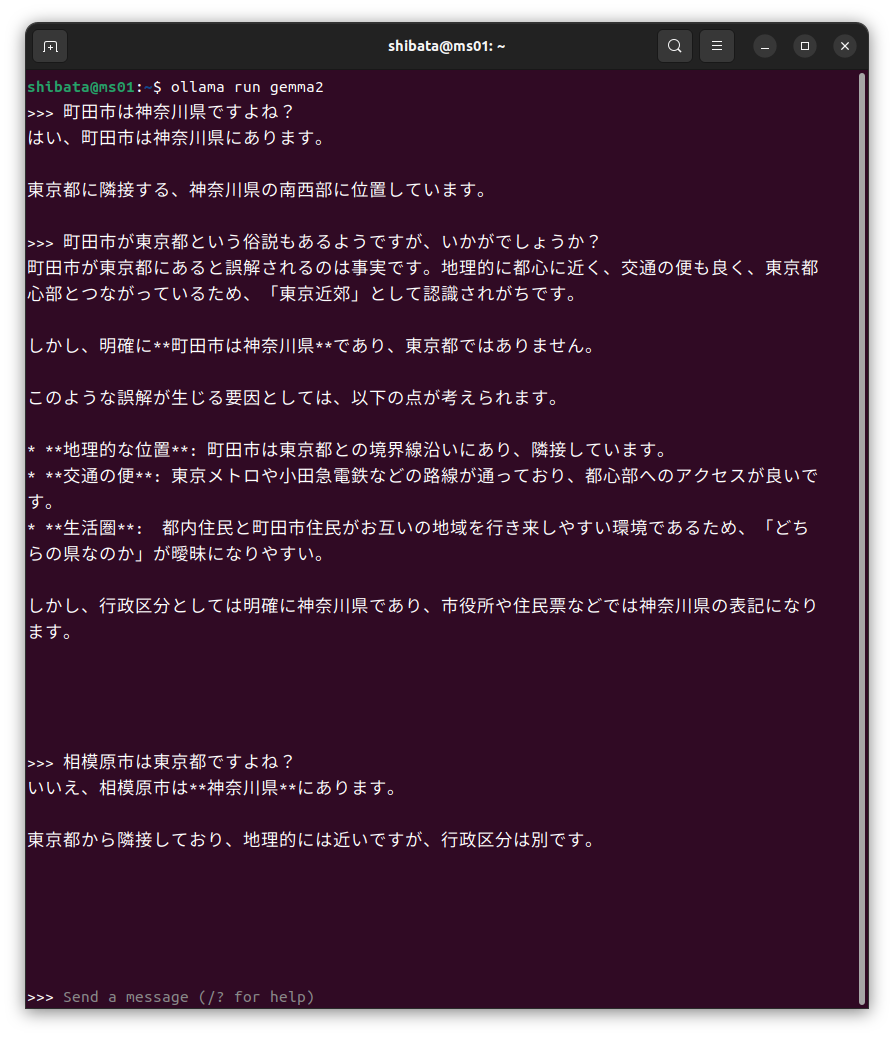
あとはプロンプトに質問を入力していくだけです。単一行ならそのまま入力してエンターキーを押したら回答の生成を開始してくれます。試しにUbuntuについて質問してみましょう。
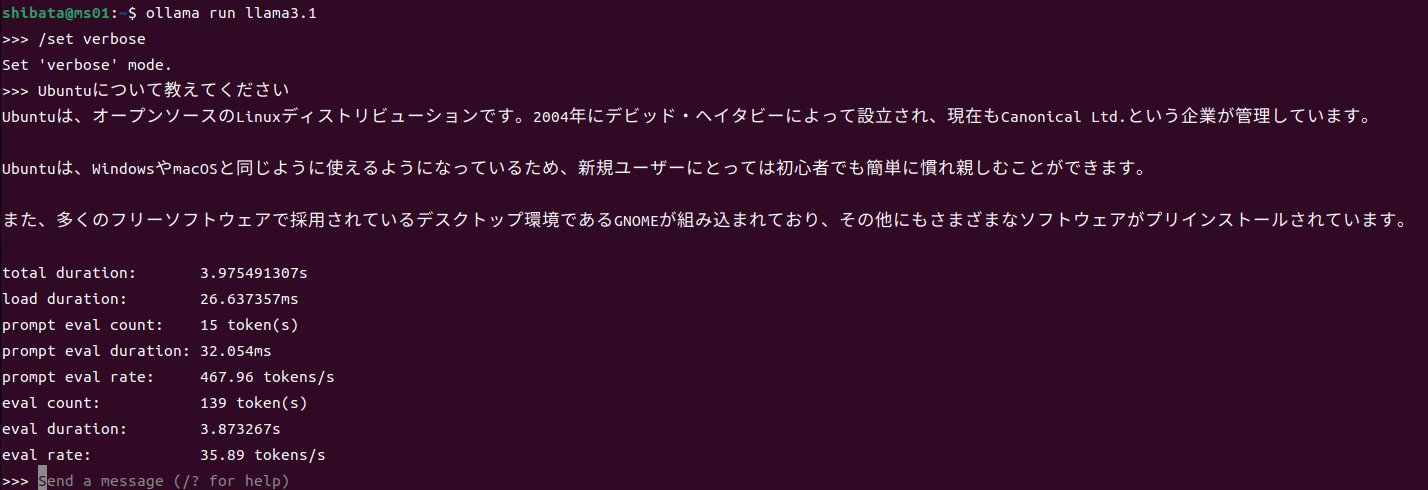
上図で質問する際に、最初に/set verbose」
これくらいの質問なら4秒弱で結果を返してくれます。結果自体も4秒待ってから表示されると言うよりは、すぐに表示を開始しほぼ4秒の間ずっと文字を表示し続けるため、ほとんど
ちなみにスラッシュで始まるコマンドによって、いくつかの操作を行えます。
>>> /? Available Commands: /set Set session variables /show Show model information /load <model> Load a session or model /save <model> Save your current session /clear Clear session context /bye Exit /?, /help Help for a command /? shortcuts Help for keyboard shortcuts
「/show info」
>>> /show info
Model
arch llama
parameters 8.0B
quantization Q4_0
context length 131072
embedding length 4096
Parameters
stop "<|start_header_id|>"
stop "<|end_header_id|>"
stop "<|eot_id|>"
License
LLAMA 3.1 COMMUNITY LICENSE AGREEMENT
Llama 3.1 Version Release Date: July 23, 2024
複数行を入力したい場合は"""」
また、OllamaではChatGPTと同じように前回の回答に続けて文章を入力すると、その/clear」
終了したい場合は/bye」
Open WebUIでChatGPTっぽくする
CLIはCLIで便利なのですが、前の回答・
Open WebUIはDockerで動かすのがおそらく一番簡単でしょう。ただしDockerからNVIDIAのGPUリソースを使うためには、NVIDIA Container Toolkitをホストマシンにインストールしなくてはなりません。
このツールキットはDebianパッケージ化されていないため、NVIDIAの公式サイトの手順に従ってインストールすることにします。
$ curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | \ sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list $ sudo apt update $ sudo apt install nvidia-container-toolkit
さらにDockerとgitをインストールします。ここではUbuntuの公式リポジトリ版を使っていますが、Dockerが提供するパッケージをインストールする形でもかまいません。もしNVIDIA Container Toolkitより先にDockerをインストールしている場合は、2番目のコマンドのようにDockerデーモンを再起動しておくと良いでしょう。これによりDocker側でツールキットの存在を検知して、適切な対応を行ってくれます。
$ sudo apt install docker.io git $ sudo systemctl restart docker.service
さらにOllamaの設定を変更します。Ollamaは初期設定だと、127.」
$ ss -ltn | grep 11434 LISTEN 0 4096 127.0.0.1:11434 0.0.0.0:*
しかしながらUbuntu 24.
ERROR [apps.ollama.main] Connection error: Cannot connect to host host.docker.internal:11434 ssl:default [Connection refused]
そこで0.」
まずはollama.
$ sudo systemctl edit ollama.service
ファイルエディタが起動しますので、次の2行を入力します。
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
あとは設定を反映し、ollama.
$ sudo systemctl daemon-reload $ sudo systemctl restart ollama.service $ ss -ltn | grep 11434 LISTEN 0 4096 *:11434 *:*
無事に0.」
あとはOpen WebUIのリポジトリをクローンし、サービスを起動します。
$ git clone https://github.com/open-webui/open-webui.git $ cd open-webui $ sudo docker run -d -p 3000:8080 --gpus all \ --add-host=host.docker.internal:host-gateway \ -v open-webui:/app/backend/data --name open-webui --restart always \ ghcr.io/open-webui/open-webui:cuda
ここではNVIDIA GPU用のイメージを使っているためopen-webui:cuda」:main」
あとはhttp://ホストマシンのIPアドレス:3000」
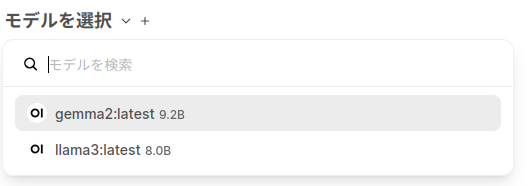
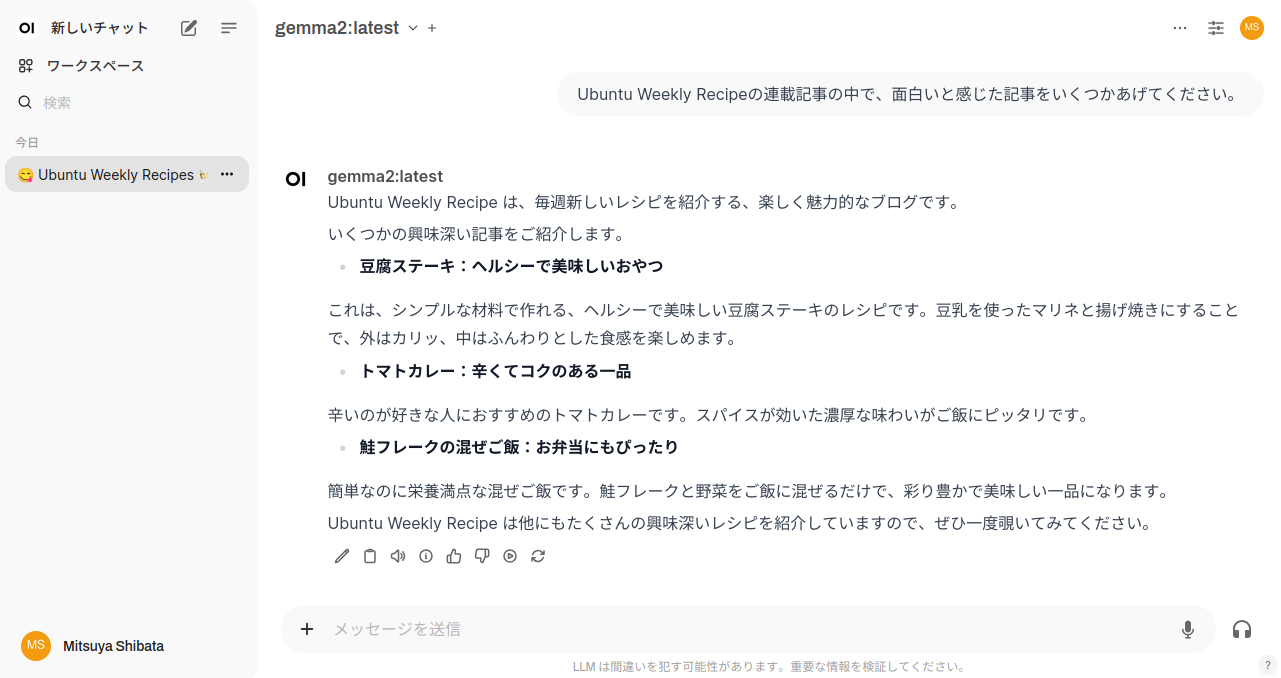
モデルはollama側で保持したモデルが表示されます。ollama run モデル名」ollama pull モデル名」
これまではLlama3.
$ ollama pull gemma2
GemmaはGoogleが公開しているLLMです。Geminiで使っているモデルというわけではなく、
誰かこの連載で
Llamaも含めて海外で作られたモデルはどうしても、英語などの言語のデータセットが主体となり、日本語の情報や日本語の解釈は性能が落ちてしまいます。特に7Bや8Bといった軽量なモデルだと、さらに精度が落ちてしまうでしょう。日本語をメインに使いたいのであれば、
英語で質問して英語で回答を得る形であれば、Llama 3.
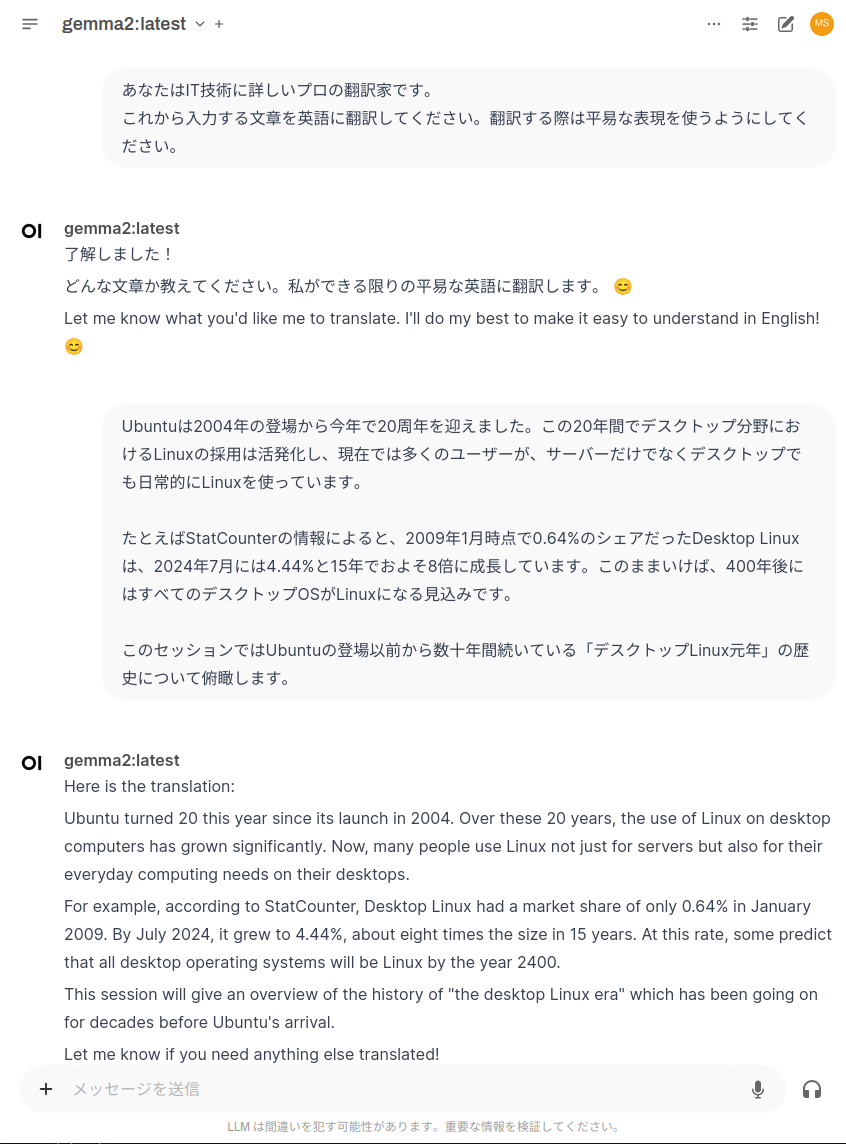
コンテキストを使って、翻訳してくれました。原文の日本語のニュアンスを良くも悪くも読み取った翻訳になっているのではないでしょうか。
日本語向けにチューニングしたLLMも
Llama3.
最近は日本語LLMについても様々なモデルがリリースされています。Llamaベースにしたものも多く、それなりに軽量なモデルも出ている状態です。残念ながらOllamaからすぐに使えるものはありませんが、少しの手間でモデル化すれば導入できるため、日本語で試したいのであればそこから調べてみると良いでしょう。