



2022年8月、2年半ぶりに渡米した際にAIアクセラレータを開発する企業を2つ訪問しました。1つは前回記事のCerebras Systems、そしてもう1つがEsperanto Technologiesです

Esperanto社はRISC-Vを牽引してきた企業の1つです。そのFounderであるDave Ditzel氏は、1980年にDavid PattersonがRISCのアイデアを提示した有名な論文[1]の共著者であり、長くプロセッサ業界の第一線を走り続けているエンジニアです。筆者がDaveに初めて取材したのは2004年でしたが、それ以来[2]、何年かおきにDaveと会い、そのときどきの彼の仕事を聞き続けています。
今回のEsperanto訪問では、ざっと現在のEsperantoの状況を聞くとともに、将来の半導体技術への展望などを話すことができました。
なお今回の訪問は同社のシニア・
最近の状況
まず、VP of Corporate & IP MarketingのCraig Cochran氏から、ざっと現在のEsperantoの状況を伺いました。私が最後に訪問した3年前から、より広いオフィスに移っていました

すでに彼らは最初のシリコンを完成させています。世界最大のRISC-Vチップ、ET-SoC-1

彼らのエンジンの強みはMinionによる並列演算能力と、その電力バジェットの設定手法にあります。10ワットから60ワットの間で、特定のアプリケーションの電力要件に合わせて電圧と周波数をソフトウェアによって調整することができるのです。
-
Craig: AI処理のアクセラレーションを行っている他の多くの企業は、電力予算全体を使用する大きなチップでシステムを構築するアプローチを取っています。シストリックアレイ
(訳注:GoogleのTPUなど) は、CNNに最適です。ResNet 50のような高密度のネットワークでは、かなり良いスコアを出しています。しかし、疎なメモリタスクはうまく処理できません。たとえば推薦システムや自然言語処理向けのTransformerモデルなどです。限られた並列度と標準的な電圧で動作させることで、効率が悪くなるのです。私たちのアプローチは、並列チップをたくさん、それも低電圧で走らせる、というものです。 私たちのチップの電力とパフォーマンスの間の良いトレードオフ、我々はスイートスポットと呼んでいますが、それは20ワット前後です。たとえばチップあたり20ワットで動かすと、6チップを120ワットの電力バジェットに収めることができ、120ワットで動かす他の1チップのシステムと比べると4倍以上にパフォーマンスが良くなります。
今回の渡米で訪問したもう1つのAIアクセラレータ企業、Cerebrasもこのスパースな行列演算をうまく扱えるよう、全体をデータフローマシンで構成しています。GoogleがTPUを公表した2016年当時から、疎行列の処理はそれぞれに工夫されています。Esperantoはこれをメモリの配置と効率
取材ではそのために1,000以上のMinionを

プレプロダクション・サーバ
ET-SoC-1 チップはいま最初の顧客による評価中で、そのためのサーバを開発しているとのことです。
- Craig: 現在、私たちは最初の顧客と一緒に、顧客が購入できるシステムを開発しています
(写真5)。このシステムはハイエンドのXeonプロセッサーを2基搭載しており、当社のカードを4、8あるいは16枚収納することができます。これは高密度なソリューションで、1つのラックに最大20台まで積み重ねることができます。
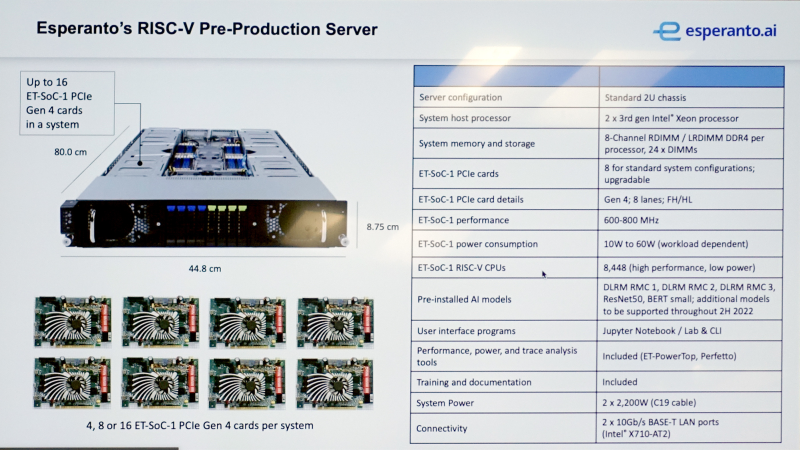
ET-SoC-1を積んだカードはPCIe gen4接続です。2Uのサイズに最大16枚搭載というのはなかなかすごい数字です。全部60Wで動作させるようなことはまずないのでしょうが、掛ける負荷や処理速度の要求に応じてコストパフォーマンスが最適となるシャシーとカード数のバランス、そして各カードの消費電力
HPCを含めて大規模クラスタシステムではコスト効率の最適化は至上命題ですから、この自由度の高さは重要です。
- Craig: また私たちは、AIモデルをあらかじめインストールした状態で提供しています。DLR
(Deep Learning Runtime) は推薦モデルです。また、自然言語処理のTransformerモデルであるBERTもあります。ResNet50もあります。もちろん、自分で作ったモデルをインポートすることもできます。ユーザインターフェースとしてJupyter Notebookをサポートしています。オープンソースの標準的なもので、実験などに適していますね。
エッジへの展開
-
Craig: 私たちはクラウドからエッジにフォーカスしており、まずはデータセンターからスタートしました。つまり私たちの最初の製品はデータセンター向けですが、今後はフォグと呼ばれる、クラウドとエッジの間にあるものへと拡大していく予定です。フォグ
(霧) は、サンフランシスコの企業にとってパーフェクトなものですからね。 (笑い) そこではIoTデバイスのようなものではなく、ネットワークのエッジに向けた取り組みを行っています。
そうしたサンプルをいくつか紹介します。私たちがターゲットにしているのはスマートSSDです。例としてサムスンを挙げます。私たちはAI機能をSSDに導入することで、ストレージに近いところでコンピューティングが行えると考えています。

-
筆者
(以降Yasu) インテリジェントSSDやコンポーザブル・: データセンターのことは見ていましたが、しかしSamsungがあなた方のSoCを使っていることは知りませんでした。 -
Craig: 彼らはすでにFPGAを組み込んだSamsung Smart SSDを提供しています。
(はい。それは知っていました) 我々は2021年11月に開催されたSamsung Tech Dayで、我々のチップのうちの少数のコアで処理できることを実証しました。つまり (チップに内蔵されたSRAMを使うことで) DRAMさえも不要になる可能性があります。 また、私たちは分散型エッジネットワークへの移行にも力を入れています。あるコネクテッドカーの企業と話しています。彼らは何百万台もの車を5Gモデムでデータセンターに接続し、あらゆる種類のセンサーデータを収集し、データセンターに集めるのですが、彼らはデータのすべてではなく、推論した結果だけをストアしようとしています。そこで車内で推論を行うために我々のSoCを車に搭載することを検討しているわけです。
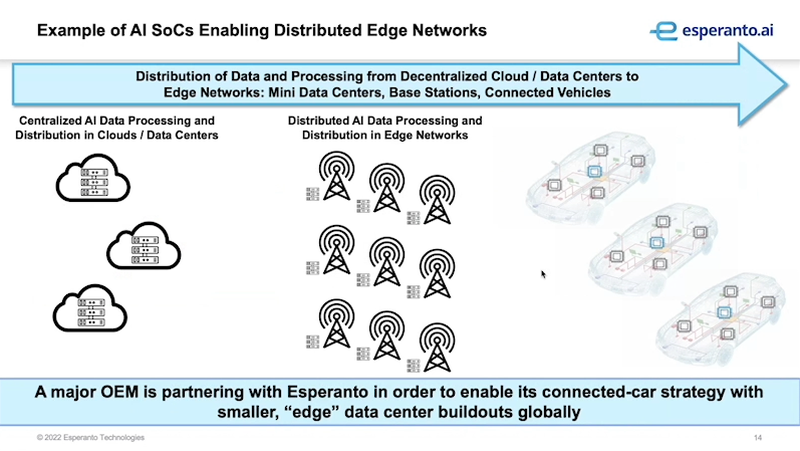
これまでEsperantoはデータセンターでの大規模AIアクセラレータとしての応用に集中していました。そのためのSoCができた今、エッジ領域への展開を進めているわけです。なお、先述のプレプロダクションサーバはXeonを外部ホストプロセッサとして使っていますが、エッジ利用向けに外部プロセッサを必要とせずMaxionをホストとするSelf Hosted Modeを開発中とのことです。
何がハードだったか
Daveに少しこれまでの道のりを聞いてみたくなりました。
-
Yasu: 初めてEsperantoを訪問してから4年ほど経ちました。あのときはまだ、いくつか部屋があるだけの小さなオフィスでした。いま、最初のチップET-SoC-1が出て、それを搭載したシステムもできつつあります。今日に至るまで、何が最もハードなところだったでしょうか?
-
Dave: そうですね。すべてのピースがお互いに対話できるようにすることでしょうか。つまり課題は個々のCPUのことではなく、どうやって相互接続するか、でした。最初、この1000個のCPUをすべて正しく接続するにはとても時間がかかるかもしれない、という心配がありました。そこでSynopsysのZeBuを使い、大規模なFPGAシステムの上でのRTLシミュレーションを行いました。内部的に何千のFPGAが使われたのか知りませんが、1000個のCPUはすべてシミュレートされました。
(おお) そしてその上で私たちのソフトウェアを走らせたんです。動作は遅くて、1ギガヘルツどころか100キロヘルツくらいでした。それでも、あるCPUがダイ上の
(ローカル配置の) SRAMメモリと通信できなかったり、SRAMメモリからDRAMへ通信できなかった場合に、問題を発見するには十分です。 ただ、すべての接続を調べて検証し、検証やデバッグを行い、すべての可能な組み合わせをテストすること、またそのためのテストを書くには長い時間が掛かりました。
(なるほど) これにとても多く時間を費やしました。1,000個全部のCPUをベリファイする、これが最も大変なパートでしたね。 -
Yasu: 馬鹿っぽい質問でごめんなさい。RTLレベルのシミュレーションができていたのなら、そのシステムは論理的な定義情報から100%正しい配線を合成できるんじゃないですか?
どうして配線ミスのようなことが起きるのでしょう。 -
Dave: それはオリジナルの仕様に何かしら抜けがあったからですね。
(シミュレータ上に) FPGAを用意したところで、そこには抜けたインターコネクトの情報がそのままコピーされますからね。またそのワイヤーが接続されていたとしても、その接続相手を間違えているかもしれません。でも、普通はそんな単純な配線の問題ではありません。信号処理のプロトコル、制御アルゴリズムに何かあるんです。
ここでDaveが出してくれたのは以下のようなケースです。つまりある命令をロードするときにキャッシュフォールトが起きたとして、同時にフローティング演算でゼロ除算が出てしまった、といった場合です。
ところが誰が割り込みを掛けたか保持するレジスタは1つしか用意していなかった、といった
-
Yasu: ところでテストでそうした問題が出た場合、何がその原因だったのか、どうやって特定するのですか?
(できるのですか?) Dave: もうそれはテストをたくさん書くんですよ。
(それしかできない、という意味) Yasu: うーん、
(対象物があまりに多くて) とてもたくさんのテストケースが要りそうですね。 Dave: たくさん作ります。それからテストカバレッジも問題です。もし
「ここのゲートは一度も状態が変化しなかった」 といった場合、 「うーん、これちゃんとテストできてる?」 と考えることになります。するとこのゲートをFalseにするための特別なテストケースを作らなければね。 まあ手間は掛かりましたが、しかしFPGA
(によるシミュレータ) システムは非常に役に立ちました。最初のシリコンはちゃんと動作し、出荷されています。検証には予想以上に時間がかかりましたが、一度のテープアウトで済みましたからね。 Yasu: それは素晴らしいですね。
Daveは、コンセプトのレベルでは簡単なのだ、と言います。

ダイ間接続
次は少し先のことを聞いてみました。
-
Yasu: ではこの先のこととして、もっとも注目していることはなんですか?
Dave: 新しい実装スタイル、つまりチップレットをベースにしたものへの変化ですね。我々はそこに行こうとしています。
(なるほど、そうなんですね。) 最近、UCIeについて[5]大きな発表がありました。つまり個々のダイを接続してチップにするためのバスができたので、それでどのようにパーティションするか、それで何をするか、といったことが今の私たちの思考の大部分を占めています。 また、Minionについて改善予定があります。というのも、RISC-Vのコミュニティがベクトルユニットの標準仕様を完成させたのです[6]。Esperantoも次の世代ではそれを使う予定ですが、それは私たちの最初の、つまり独自のベクトルユニットと互換性を持つものになります。昔は我々が使えるようなベクタの使用が定まってなかったので、自分たちで設計するしかなかったんです。
Yasu: はい。以前そのことを話しておられましたね[7]。
Dave: また、何世代にもわたってプロセスがシュリンクしていく中で、何が起きるでしょう。チップレットは実際に大きなチップを作ることができますから、今日4,000個のCPUからスタートするようなものです。すると5ナノメートルは8,000個。3ナノは16,000、2ナノで32,000、2030年後に1.
5ナノメートルになるなら、1つのパッケージに64,000個のCPUが搭載されることになります。 Yasu: とても大きなパッケージで、ですね。
Dave: 大きなパッケージになる可能性は非常に高いと思いますし、本当にそれで未来は変わっていくでしょう。
Yasu: ところで日本は前工程
(の競争) では負けてしまいましたが、後工程ではまだとても強いですね。 Dave: そうなんです。いま2030年までの未来を展望する別の論文を書いているのですが、そこで私からメッセージがあります。
「Hey! 我々Esperantoや他の企業は、そこに多くのダイを置こうとしているよ! だから本当に大きなパッケージを作る用意をしといてね!」 と。 Yasu: ほんとそうですよね。
Dave: これからはそうなります。ラック1本に対して何個のチップ
(パッケージ) を載せられるかを考えると、おそらく1ラックに300から1,000個は積めるでしょう。1000個というと現在のスパコンのCPUの数より遙かに多い、6400万個のRISC-Vコアを小さな会社の1ラックに載せられるのです。人びとは数年後にそのステージに到達するでしょう。

ムーアの法則
せっかくDaveというビジョナリーと話しているのです。もう少し先の未来のことに話を進めてみました。
-
Yasu: 今、オングストロームレベルのプロセスが出てきているわけです。しかし、その次はどうなるのでしょうか?
それはシリコンの終わりなのでしょうか? Dave: ノー。皆が
「これがムーアの法則の終わりだ」 と言っています。もう10年、彼らはムーアの法則の終わりを予言していますが、しかし終わっていません。 Yasu: 同意します。だから聞きたいのですが、何がムーアの法則を終わらせるのでしょうか。
Dave: 最大の困難は、チップの実装コストになると思います。Transmetaを作ったときは、1つのCPUを作るのにチーム
(と呼べる程度の人数) が必要でした。Esperntoでは、もう少し小さなチームで1つのCPUを作ることができます。 ただ、そのCPU
(コアのこと) を1,000個も組み立てなければならず、設計が非常に複雑になりました。最近では私たちのようなチップを作るには、平均2億5,000万ドル近くかかると言われています。この数字は世代を重ねるごとに増えています。 そこでもう1つの法則、
「Daveの設計コストの法則」 が必要かもしれません。1サイクルごとに2倍になるのです。 (ははは) つまり技術が進歩するにつれて、ある機能に特化したまったく新しいチップを作るだけの経済的な余裕を持つことが、人びとにとって非常に難しくなるのです。
(なるほど) その点、チップレットは少しは助けになるでしょうが、プロジェクト規模が大きなものは非常に難しくなるでしょうね。2030年、つまり1. 5ナノメートルで、その状況になると思います。皆1. 5ナノメートルまで到達するのは間違いないと言っていますから、あと3世代。とても早く到達します。1ナノメートルの前にムーアの法則の終わりが来るとは思えません。 (困難でも) 彼らは進むべき道を見つけるでしょうから。 Craig: 確かに。誰もがFin-FETで終わりだと思っていましたが、でも解決してしまいました。
Dave: ムーアの法則は少し遅くなっただけで、死んではいません。それより設計の複雑さとそのコストが、本当に大きな問題になってくるのだと思います。またそのコストを支払うためには、製品は非常に普遍的な、たとえば携帯電話などにも搭載できるようなものでなければなりません。
「プレイステーション」 のようなデバイスでは、将来的に十分な生産量が見込めなくなるかもしれません。新しくやりたいことを思いついても、それを実際に設計できる経済的な力のある人 (組織) がいないのです。これが課題ですね。 笠原: スタートアップ企業がこの課題に取り組むことは非常に難しいことだと思います。
Dave: とても高額になるからね。これが、今後10年間の課題だと思います。ムーアの法則が止まるのではありません。だからといってチップを非常に小さくすると、ファブのビジネスが壊れてしまいます。ウェハーを1枚作ったら100万のチップが採れて、もう終了、では困ります。このビジネスと設計におけるジレンマは、物理的なマテリアルの問題などよりずっと根本的なところにあると思います。
Yasu: 何かブレイクスルーが必要ですね。
Dave: まあ高レベル設計などを人々は口にしますが、完全なソリューションにはならないですね。
Yasu: うーん。いまソフトウェア側で何が起こったか考えています。つまりオープンソースのソフトウェア開発は、スケーラビリティという点で有益でした。ソフトウェアはどれも年々複雑になっていますが、オープンな開発はそれに対応できています。こうした新しいアプローチの開発がシリコン産業で起きるかもしれません。
Dave: ソフトウェアはとても速く進化します。ハードウェアはムーアの法則に従うのでとても予測しやすいのですが、たとえば10年前に
「(10年後の) 機械学習のプログラミングで最も優れた方法は何になるか」 と聞かれたら、誰もわからなかったでしょう。昨日ミーティングで私とCraigはロードマップについて話したのですが、ここ数年、そして今も我々はうまくやっているけれど、しかし四年より先のことは誰にもわからない、と言いました。 Yasu: ははは。そうですね。
Dave: 今はあまりにも多くのことが変化しますよね。今日人気のあるものが、明日には人気がなくなってしまう。そうでなければ私たちは第5世代のNapsterやFriendsterを使っているはずです。
(一同笑い)
ここで時間切れとなり、Daveは次のミーティングに向かいました。
「何がムーアの法則を止めるのか」
Daveが言ったように、今後どのように進むのか誰にも分かりません。しかし