



EuroPythonはヨーロッパ地域で開催されるPythonに関するカンファレンスです。EuroPython 2022レポートの第2回目は、カンファレンス2、3日目の様子を中心にお伝えします。
カンファレンス2日目はOrganisers' Lunch、日本から参加したwhitphxさんのトークや、Social Eventという名前のパーティーなどがありました。
Writing Faster Python 3
- タイトル:Writing Faster Python 3
- スピーカー:Sebastian Witowski
- ビデオ:https://
www. youtube. com/ watch?v=6P68IBou_ cg
スピーカーのSebastian氏は2019年にPyCon JPでも発表していたので、見かけたことがある人もいると思います。氏のWebサイト

最初にaという変数の中身が文字列かも知れませんし、数値、リストまたはDataFrameかも知れません。
Python高速化のアプローチ
そしてPythonを早くするためのアプローチとしていくつかの手法が紹介されました。当然ですが、より速いハードウェアで実行すればPythonの実行速度は速くなります。
別のアプローチとして、CPythonとは別のインタープリターとして、PyPy、Pyston、Pyjion、Cinder、GraalPythonが紹介されました。PyjionとCinderは筆者が初めて聞く名前でした。さまざまな高速化されたPython実装が開発されているようです。
NumPyにNumbaを組み合わせると、大量データ処理などをより速く実行してくれます。
また、Pythonのバージョンを更新すると高速化が見込めます。Python 3.
そして最後に
よりよいアルゴリズムやデータ構造
以下のような
total = 0
def compute_sum_of_powers():
global total
for x in range(1_000_000):
total = total + x*x
compute_sum_of_powers()
print(total)
次にグローバル変数をローカル変数に変えると63ミリ秒に短縮します。これは変数をグローバルから検索するために前のコードの方が遅くなっています。
def compute_sum_of_powers():
total = 0
for x in range(1_000_000):
total = total + x*x
return total
total = compute_sum_of_powers()
print(total)
次に全体を加算する部分をsum()関数で行い、リスト内包表記で2乗のリストを作成します。処理時間は59ミリ秒になりました。
def compute_sum_of_powers():
return sum([n * n for n in range(1_000_000)])
total = compute_sum_of_powers()
print(total)
リスト内包表記をジェネレーター式に変更します。ジェネレーター式はリストを一度に作成しないため使用するメモリは非常に少ないですが、処理速度は63ミリ秒とリスト内包表記より遅くなります。
def compute_sum_of_powers():
return sum(n * n for n in range(1_000_000))
total = compute_sum_of_powers()
print(total)
ここでさきほど紹介したnumbaを導入します。pip install numbaでインストールしてimportし、関数に@jitデコレーターを付けます。これだけで実行時間が34ミリ秒に短縮されます。
当然ですが、numbaのJITがうまく効く処理もあれば、そうでない処理もあるので注意が必要です。
from numba import jit # pip install numba
@jit
def compute_sum_of_powers():
total = 0
for x in range(1_000_000):
total = total + x*x
return total
total = compute_sum_of_powers()
print(total)
次に、このコードでは整数しか扱っていないのでNumPyを使用します。NumPyの関数やデータ型を使用すると57ミリ秒となりました。ただし、実行時間の大半はNumPyのimportにかかっており、計算処理自体は10ミリ秒とかなり高速です。
import numpy
def compute_sum_of_powers():
numbers = numpy.arange(1_000_000)
powers = numpy.power(numbers, 2)
return numpy.sum(powers)
total = compute_sum_of_powers()
print(total)
このようにして、72ミリ秒の処理を10ミリ秒にまで短縮することができました。
このあともコード例を示しながら、同じ目的でどう書く方が速いのかという説明がされました。紹介されたのは以下のような例です。
- 権限の事前チェックと
try/exceptではどちらが速いか - コレクションの中から要素を探す
- リストをフィルタリングする場合
filter()よりリスト内包表記が速い - リストに要素が存在するか調べる場合
setが速いが、setへの変換処理は時間がかかる - 空の辞書生成の
dict()と{}では{}の方が速い - リストから重複の削除は
set()がとても速いが順番が変わる
最後にここまでに挙げたコードをさまざまなバージョンのPythonで実行してみると、ほとんどのコードでPython 3.
さらなるサンプルコードなどが、GitHubやBlogで公開されていることを紹介していました。詳細が気になる方は、ぜひ参照してみてください。
最後に
How we are making Python 3.11 faster
- タイトル:How we are making Python 3.
11 faster - スピーカー:Mark Shannon
- ビデオ:https://
www. youtube. com/ watch?v=xKk7IXm0XO0
スピーカーのMark Shannon氏は、Day 1のCPython Developer Panelにも登壇していたCPythonのコアデベロッパーです。Marc氏はPyCon US 2021で発表されたFaster CPythonの提唱者であり、現在はCPythonの高速化チームの技術リーダーとしてGuido氏らとともに開発を進めています。
ちなみに、Mark氏は10月に開催されるPyCon JP 2022のキーノートスピーカーでもあります。日本でCPythonの最前線の話が聞けそうで、非常に楽しみです。

このトークでは、どのようにしてPython 3.
最初に、CPythonはCで書かれたコンピュータープログラムであるため、高速化をするにはコンピューターがどのように動作しているかを理解する必要があると述べられました。筆者も理解が追いついていないですが、CPUはスーパースカラーというアーキテクチャーにより、複数の命令を同時に取り込んで並列で実行しているそうです。
また、メモリアクセスも重要で、CPUからメモリにアクセスする速度は物理的な制約があるため、CPUのキャッシュメモリを搭載して効率化しているとの説明がありました。
データ構造
ここでは、CPythonを高速化するためにデータ構造をどのように変更したかについて解説されました。
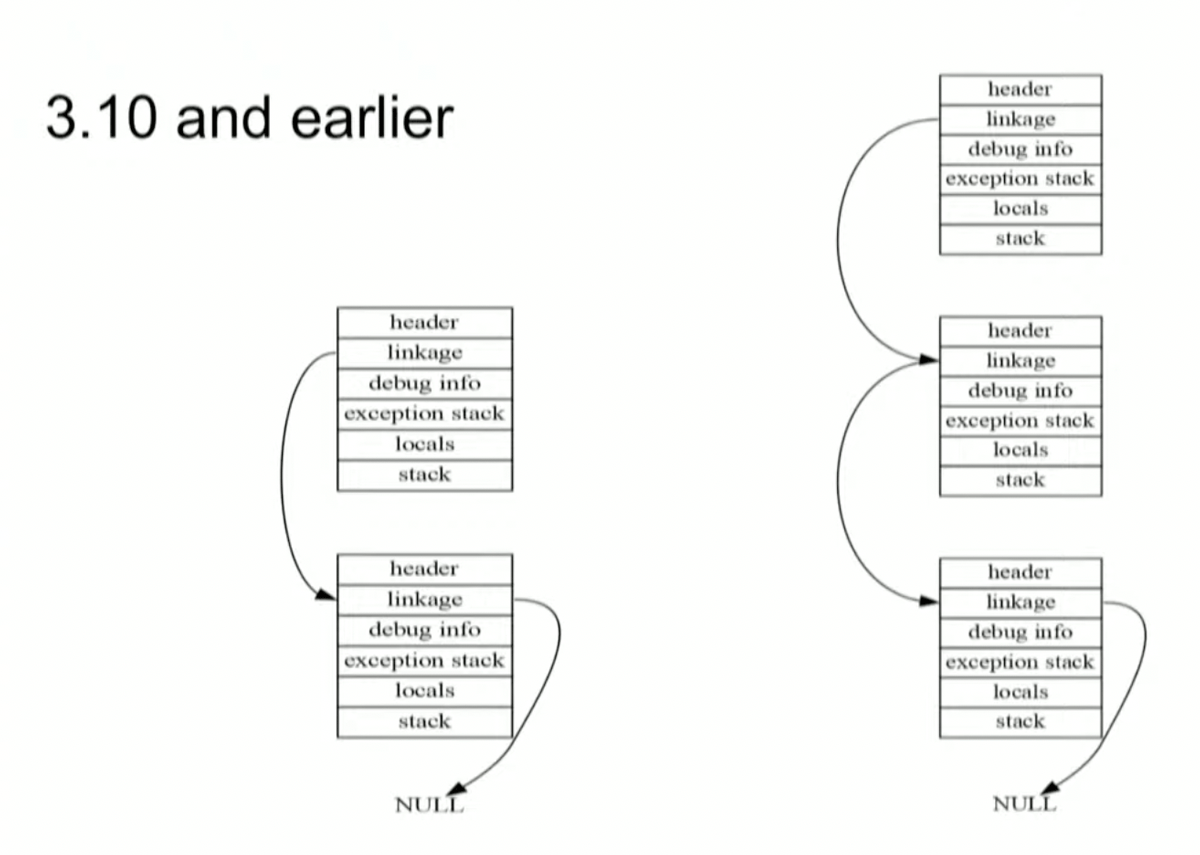
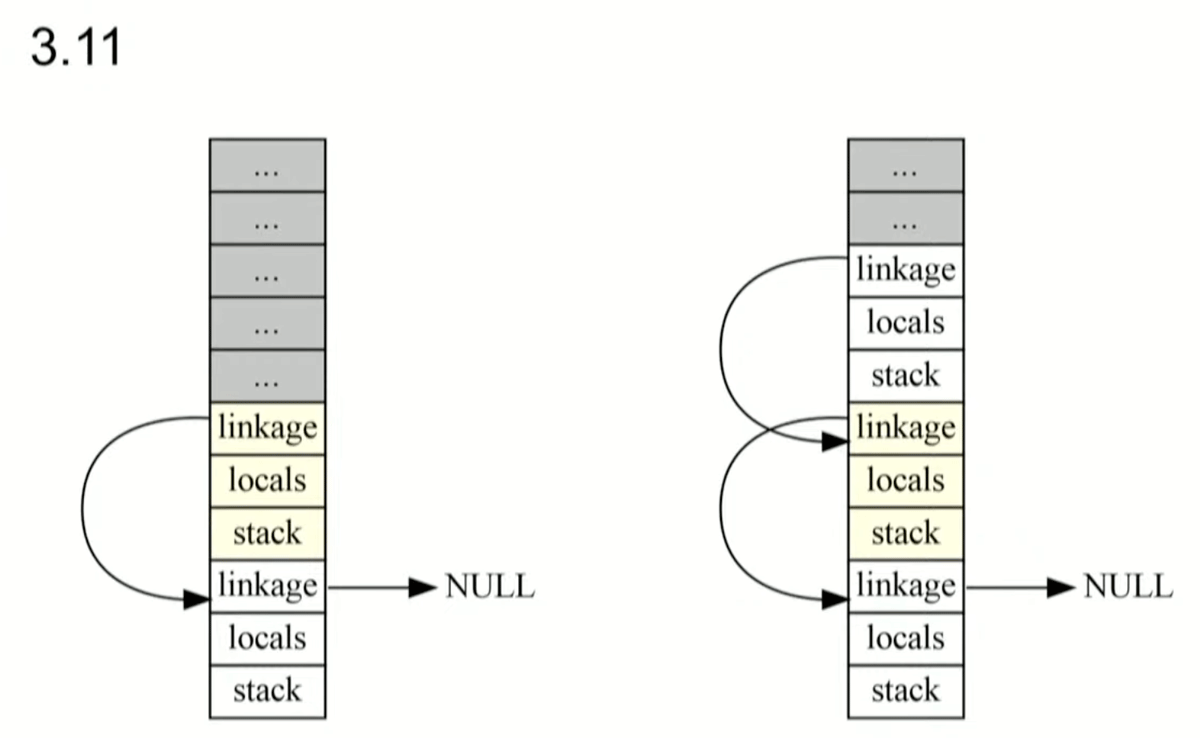
最初の例はリスト型です。リストをリンクリストで実装すると、毎回メモリを確保することと、データを探すためにリンクを辿らないといけないため効率がわるくなります。そこで、Python 3.
また、例外発生時に使用するframe objectをあとから生成する
もう1つは以下のような一般的なPythonのオブジェクトについてです。
class C:
def __init__(self, a, b):
self.a = a
self.b = b
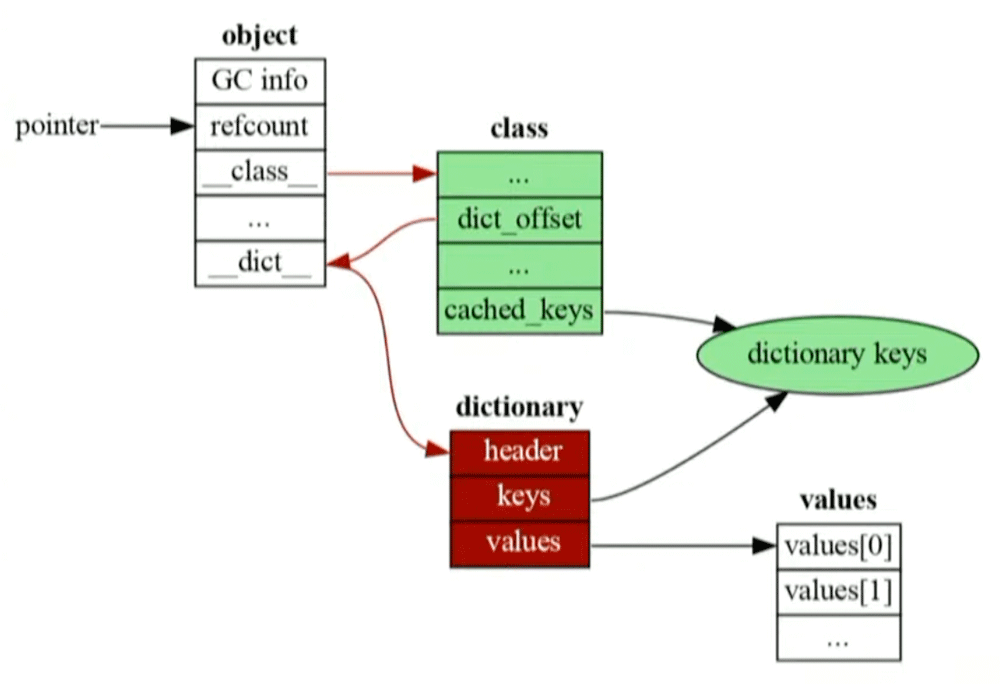
Pythonのオブジェクトは__を持っており、この中にオブジェクトの属性を持っています。しかし通常のコードでは__には直接アクセスしません。
Python 3.class→__→dictionary→valuesとアクセスする必要があり効率が悪いです。
Python 3.__を先頭に移動しました。こうすることでclassのdict_を参照する必要がなくなりました。
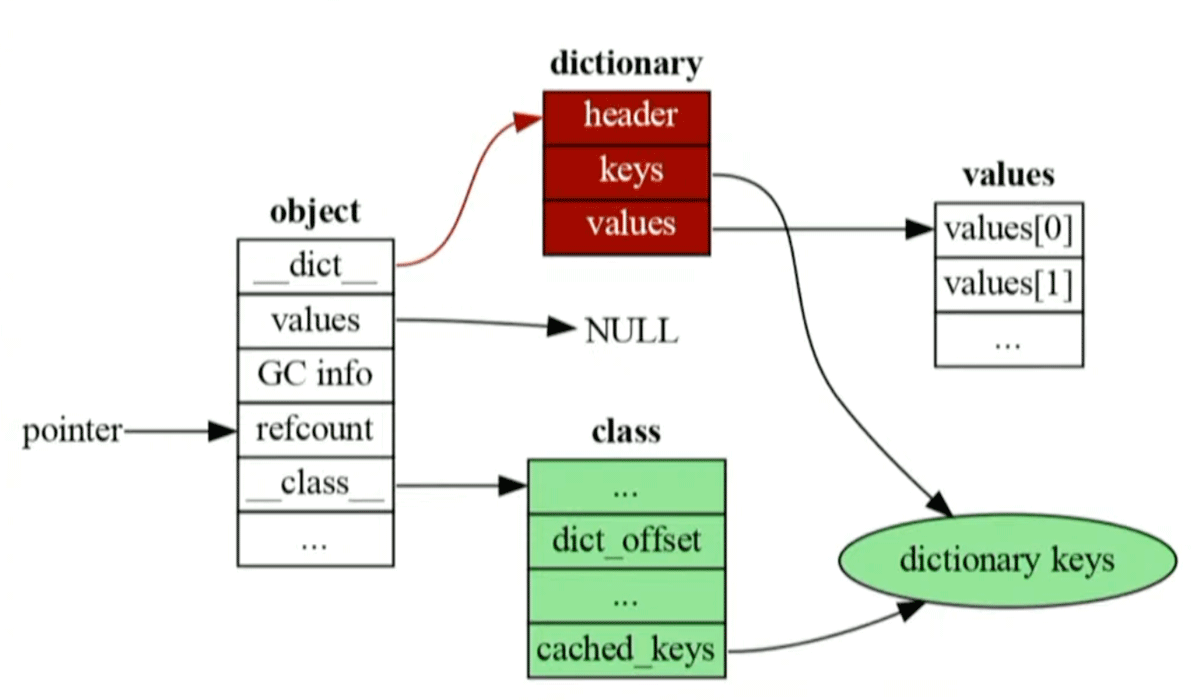
そして、Python 3.valuesにアクセスできるため、作成したばかりのオブジェクトでは__は存在しないように改良されたそうです。このようにPython 3.
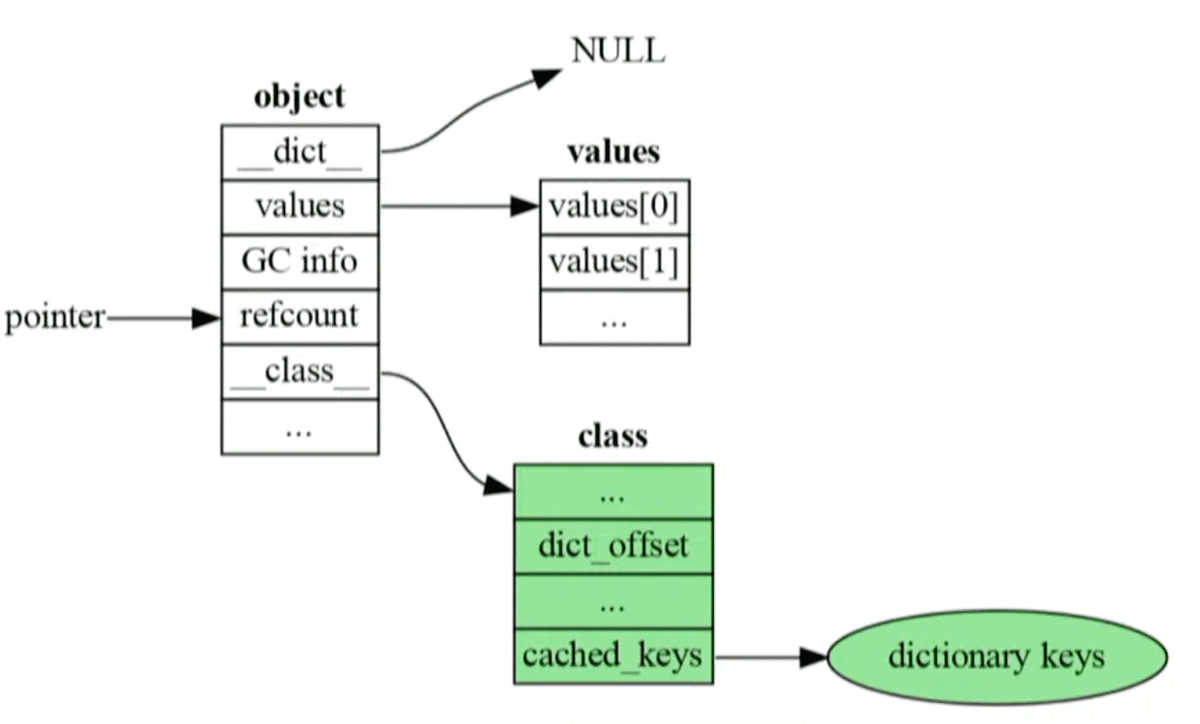
アルゴリズム
アルゴリズムの高速化として、PEP 659で提案されPython 3.
- General:ウォームアップカウンターを持つ。カウンターが0になるとSpecialized
(最適化される) になる - Specialized:ミスカウンターを持つ。カウンターが0になると最適化が外れる
SpecializedBINARY_がBINARY_になったりします。
たとえば、+演算子BINARY_)BINARY_)
Specializing Adaptive Interpreterについては、以下の資料も参考にしてください。
- PEP 659 – Specializing Adaptive Interpreter
- What's New In Python 3.
11のPEP 659: Specializing Adaptive Interpreter - Python 3.
11の新機能(その2) 特殊化適応的インタープリタ: Python3. 11の新機能 - python. jp
最後に、3.
筆者にとっては難しい内容でしたが、図なども交えてていねいにCPythonの高速化について説明してくれたトークでした。細かい地道な努力の積み重ねでCPythonが徐々に高速化していくのだなと感じました。

Organisers' Lunch
カンファレンス2日目のランチはOrganisers' Lunchがあったので参加してきました。このイベントは、各国でPython関連のイベントやコミュニティを運営しているメンバーで、一緒にランチをとりながら交流しましょう、という企画のようです。筆者はPyCon JP Associationの副代表理事を務めていることもあり、イクバルさんにも声をかけて、Organisers' Lunchに参加しました。
ランチ会場に行ってみると、発表会場前のホワイエ的なところに丸テーブルがいくつかセッティングされていました。

筆者はイクバルさんと同じテーブルに座りました。同じテーブルには、たびたびこのレポートにも出てくるMarc氏、現在のEuroPython SocietyのChairであるRaquel氏などがいました。
筆者の右隣に座った3名はKiwi.
左隣に座っているGajendra Deshpande氏

Kiwi.
ライトニングトーク
2日目も最後にライトニングトークがありました。いくつか紹介します。

- EuroPython Society <3: 昨日のライトニングトークにも登場したVB氏による
「EuroPythonのボランティアになってね」 というトーク - Hugging Face Gradio Hackathonの紹介
- Django-reversion:Djangoのモデルインスタンスのバージョン管理をする拡張の紹介
- EuroSciPy 2022というカンファレンスの紹介
- Reverse-Engineering Keynote: MacのKeynoteファイルをリバースエンジニアリングするトーク。keynote-parserというライブラリを紹介
- latest.
cat :ソフトウェアの最新バージョンを取得するコマンドの紹介
Day 3 ―ライトニングトークにサインアップ
ここからはカンファレンス3日目の様子をお伝えします。
前日はSocial Eventでビールをけっこう飲みましたが、朝早く起きることができました。この日はカンファレンス後にそのまま移動だったので、ホテルで荷物をまとめて会場に来ました。
9時からオープニングですが、朝8時前には会場に到着しました。筆者が早起きして会場に来た理由は、ライトニングトークにサインアップするためです。EuroPythonのライトニングトークは朝にボードが貼り出され、早いもの勝ちで埋まっていきます。無事、4番目に自分の発表タイトルを書き込むことができました。

Keynote 3:Multithreaded Python without the GIL
- タイトル:Multithreaded Python without the GIL
- スピーカー:Sam Gross
- ビデオ:https://
www. youtube. com/ watch?v=9OOJcTp8dqE
カンファレンス最後のキーノートです。キーノートスピーカーを紹介するためにLarry Hastings氏が壇上に上りました。
Larry氏はPython 3.

このトークではSam氏が過去数年取り組んでいるプロジェクト、PythonのマルチスレッドプログラムをGILなしで実行させること、について語られます。
まず前提として、プログラムをマルチスレッド化すると、マルチプロセッサやマルチコアコンピューターで並列の動作して効率的です。シングルプロセッサでもスレッドによって並行処理ができます。このプロジェクトのゴールは、Pythonでマルチスレッドのコードをマルチコアコンピューターで効率的に動作させることですが、その障害の1つがGILです。GILによって、一度に1つのスレッドのみがPythonコードを実行することが保証されます。
1991年にPython 0.
Pythonのリリースから30年が経ち、マルチコアのプロセッサーはどこにでもあるようになりました。しかし、Pythonで並行処理にはGILによって制限があります。制限を回避するために、たとえばscikit-learnなどでは内部でOpenMPを使用しています。他にはマルチプロセスで実行する方法もありますが、プロセス間の通信が問題となります。
GILを取り除くには以下のような対応が必要です。
- オブジェクトの参照カウンター
- リスト、辞書などのコレクションをスレッドセーフにする
- メモリアロケーター
- ガーベッジコレクター
- シングルスレッドでのパフォーマンスを維持しながら、効率的にマルチスレッドでスケールする
GILの削除には過去3回チャレンジしたことがあるそうです。"free threading" patchの一部は現在のPythonにも取り込まれているそうです。また、GilectomyがもっともSam氏のプロジェクトに影響を与えているそうです。
- 1996:"free threading" patch (Greg Stein)
- 2007:python-safethread (Adam Olsen)
- 2016:Gilectomy (Larry Hastings)
参照カウントの改善
参照カウントをスレッドセーフにするもっとも簡単な実装方法として、アトミック操作にしてみます。pyperformanceでベンチマークしてみると、平均60%遅くなるそうです。そこで2018年に発表されたBiased reference countingというアルゴリズムを採用したところ、10%遅くなる程度となったそうです。
次にImmortal objectsTrue、False、None、0、1といったオブジェクトは常に存在するオブジェクトにして、参照カウントの対象外とする物です。この状態でフィボナッチ関数をマルチスレッドで実行してみたところ、8CPUでのスループットはシングルスレッドの25%となったそうです
この原因は関数の参照カウント処理の問題であり、この問題を解決するためにDeferred reference counting
Biased reference counting、Immortal objects、Deferred reference countingの3つを使い分けることで、マルチスレッドでの参照カウントのパフォーマンスが改善しました。
コレクションのスレッドセーフ対応
次に、辞書、リスト、セットなどのコレクションに並行でアクセスするために、Lightweight locks
value = dict["key"]
value = object.attr
item = list[idx]
メモリーアロケーターとガーベッジコレクター
Pythonのpymallocはスレッドセーフではありません。代わりにスレッドセーフなmimalocを使います。
また、ガーベッジコレクターはグローバルな二重のリンクリストでオブジェクトを追跡するため、スレッドセーフではありません。mimallocを使用することでこの問題も解決します。
まとめ
このプロジェクトの成果物はhttps://pyenv install nogil-3.で簡単にインストールできます。また、この内容を元にPythonからGILを取り除くPEP
とても難しい内容でしたが、数年後にGILを取り除いたPythonが普通に使えるようになり、Pythonのマルチスレッドプログラムがマルチコアで効率的に動くことに期待したいと思います。
筆者のライトニングトーク:Spread the community after COVID-19 in Japan
- ビデオ: https://
www. youtube. com/ watch?v=o8AHM8mx61U&t=692s - スライド: Spread the community after COVID-19 in Japan 🇯🇵
ライトニングトークのサインアップに成功したので、発表資料の準備に時間を使い、トークはほとんど聞きませんでした。ライトニングトークは
トークの中では、コロナ禍となりPython Boot Campのようなリアルイベントができなくなったこと、その代わりにPython Charity TalksやPyCon JP TVといったリモートでの活動にチャレンジしていることを紹介しました。
このPyCon JP TVのところで

撮影した画像をトーク終了後に確認してみると、たくさんの人が手を上げたり笑ったりしてくれていて、とてもいい写真が撮れたなと思いました。トークの後にこの画像をツイートしました。ぜひ拡大画像で確認してみてください。
Thanks for listening to my LT "Spread the community after COVID-19 in Japan ". See you at PyCon Japan or somewhere!! #europython2022 https://
— Takanori Suzuki (@takanory) July 15, 2022t. pic.co/ tj0oSdKGwq twitter. com/ vWJhj5YRXD
持ち時間5分の中にネタを入れまくったトークでしたが、なんとか時間ギリギリで終了しました。伝えたいことは伝わり、ウケてほしいところはウケていたような気がするので、自分としては
クロージング
カンファレンスの最後クロージングです。Day 1のオープニングと同様にRaquel氏の進行で進みます。会場は、2年振りのオンサイトカンファレンスが無事終了できた喜びに満ちていました。参加者数は現地参加1194名、オンライン143名とのことです。また、参加者の男女比、国別比較なども報告されました。他にはトークのプロポーザルの数や、遠方支援者の数などについても述べられました。最後にEuroPython 2022を支えたオンサイトとオンラインのボランティアが紹介され、2023年のスタッフとして参加することを呼びかけていました。2023年の開催場所は未定のようです。

クロージングの一番最後にpipx run saghettiを実行してみて」
まとめ
久しぶりの現地開催での海外カンファレンス
筆者がPyCon JP Associationとして行っているYouTubeライブ、PyCon JP TVでもEuroPython 2022について紹介しました。よりたくさんの写真とともに現地の様子を伝えているので、もしよかったらそちらもご覧になってください。
また、オフィシャルの写真はFlickrの以下のURLで共有されています。筆者が、会場内のソファに寝っ転がりながら、ライトニングトークの資料作成をしている写真もあります。ぜひ、探してみてください。
カンファンレンス自体はこのあとの土日に開発スプリントが開催されていましたが、筆者はDay 3のライトニングトークを終えると飛行機でデンマークのビルンへと移動しました。ビルンではLEGO HouseとLEGOLANDを堪能したのですが、それはまた別のお話し。
