



第2章では、実際にヘッドレスChromeを自動化するうえで必要となる、最新のJavaScriptの構文やPuppeteerのAPIについて解説します。
進化し続けるJavaScript
PuppeteerのAPIを解説する前に、第1章の冒頭で掲載したサンプルコードを見返してみましょう。もしかすると、中にはまったく見慣れない構文が見つかったかもしれません。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'screenshot.png'});
await browser.close();
})();
JavaScriptの標準仕様であるECMAScriptは、2015年以降、毎年改訂されています。これは、JavaScriptが現在も進化し続けていることを意味しています。このサンプルコードを従来の構文に書き換えると、下記のようにとても複雑になってしまいます。
var puppeteer = require('puppeteer');
(function() {
return puppeteer.launch()
.then(function(browser) {
return browser.newPage()
.then(function(page) {
return page.goto('https://example.com')
.then(function() {
return page.screenshot({
path: 'screenshot.png'
});
});
})
.then(function() {
return browser.close();
});
});
})();
本特集に掲載されているコードでは、ECMAScriptのバージョン2017
そのほかにも、var宣言に代わって再代入不可能な変数に用いられるconst宣言や、関数を短く記述できるアロー関数といった、新しい構文が数多く使用されています。
本章では、このようなさまざまな構文の中でも、特に複雑になりがちな非同期処理を簡潔に記述できるasync/
イベントループを用いた非同期処理
JavaScriptはシングルスレッドで動作しますが、イベントループを用いた非同期処理に対応しています。そのため、ネットワークリクエストのようなI/
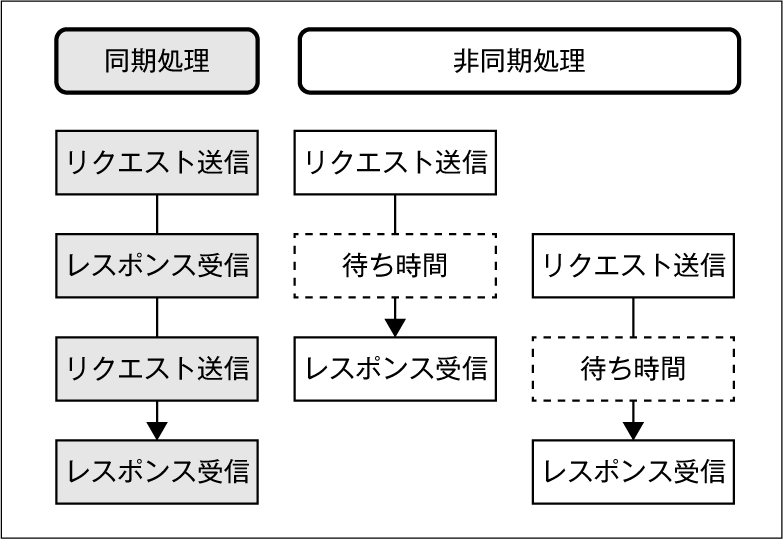
Puppeteerは、ほとんどのブラウザ操作をネットワークを介して行うため、非同期処理を便利に扱うためのasync/
Promiseと糖衣構文
async/
Promiseとコールバック地獄
Promiseは、コールバック地獄と呼ばれる問題を解決するために用意された、特別なオブジェクトです。コールバック地獄とは、たとえばsetTimeout()に代表されるような、非同期処理をコールバック関数として受け取る処理が連続した場合に、下記のようにコードの階層が何段にもネストされてしまい、可読性が大きく下がってしまう問題のことを指します。
setTimeout(() => {
// 1秒経過
setTimeout(() => {
// 2秒経過
setTimeout(() => {
// 3秒経過
console.log('実行完了');
}, 1000);
}, 1000);
}, 1000);
Promiseチェーン
そこで、setTimeout()をラップしてPromiseを返すsetTimeoutAsync()という関数を定義してみましょう。
function setTimeoutAsync(milliseconds) {
// Promiseオブジェクトを返す
return new Promise(resolve => {
// 一定時間経過後にresolve()を実行する
setTimeout(resolve, milliseconds);
});
}
Promiseは、then()というメソッドを呼び出して、コールバック関数を追加できます。このコールバック関数は、非同期処理が完了し、resolve()が実行されたときに初めて呼び出されます。
さらに、Promiseには、メソッドチェーンを使って何度でもthen()を呼び出せる、Promiseチェーンと呼ばれる機能があります。このPromiseチェーンを使って非同期処理を順番に呼び出すことで、下記のように非同期処理が連続しても、階層が深くなりにくいという大きなメリットがあります。
setTimeoutAsync(1000)
.then(() => {
// 1秒経過
return setTimeoutAsync(1000);
})
.then(() => {
// 2秒経過
return setTimeoutAsync(1000);
})
.then(() => {
// 3秒経過
console.log('実行完了');
});
Promiseの例外処理
Promiseのもう一つのメリットは、例外処理をまとめて記述できるという点です。たとえば、先ほど定義したsetTimeoutAsync()が、50%の確率で失敗するよう、下記のように仕様が変更されたとします。
function setTimeoutAsync(milliseconds) {
return new Promise((resolve, reject) => {
if (Math.random() < 0.5) {
// 50%の確率でreject()を実行する
reject(new Error('Failed!'));
return;
}
setTimeout(resolve, milliseconds);
});
}
Promiseは、catch()メソッドにコールバック関数を追加することで、Promiseチェーン内でreject()が実行された場合や、例外が発生した場合に、すべて1ヵ所で処理できます。この性質によって、毎回例外処理を書かなくても、下記のように漏れなく例外処理が行えるようになりました。
setTimeoutAsync(1000)
.then(() => {
// 1秒経過
return setTimeoutAsync(1000);
})
.then(() => {
// 2秒経過
return setTimeoutAsync(1000);
})
.then(() => {
// 3秒経過
console.log('成功');
})
.catch(error => {
// 例外処理をまとめて実行
console.error('失敗', error);
});
async/await関数の導入
Promiseを導入したことで、たしかにコードのネストを減らすことに成功しました。しかし、相変わらずコールバック関数の呼び出しが何度も行われています。さらに、通常のtry catchと、Promiseのcatch()メソッドを使った、2種類の例外処理を使い分ける必要が生じてしまいました。
そこで、Promiseを同期処理と同じように扱うことができるasync/awaitを付けると、非同期処理の完了まで次の処理を待ち続けます。さらに、通常のtry catchを使って、例外処理を行うことができるようになりました。
ただし、このような呼び出しを行う関数の前には、必ずasyncを付ける必要があります。グローバルスコープ内でawaitを使いたい場合は、一度asyncを付けた関数で囲まなければなりません。
// asyncを付けた関数で囲む
(async () => {
try {
// Promiseの前にawaitを付ける
await setTimeoutAsync(1000);
// 1秒経過
await setTimeoutAsync(1000);
// 2秒経過
await setTimeoutAsync(1000);
// 3秒経過
console.log('成功');
} catch (error) {
// try catchを使って例外処理を実行する
console.error('失敗', error);
}
})();
このとき、console.のような同期処理の前には、awaitを付ける必要がないことに注意しましょう。このように、async/
なお、今後のサンプルコードにおいて、グローバルスコープ内でawaitが使われている場合は、暗黙的にasync関数で囲まれているものとします。
Puppeteerのコンポーネント
Puppeteerを使ったブラウザ操作の自動化は、基本的に下記の手順に従うことになります。
- ❶ Puppeteerライブラリを読み込む
- ❷ Browserインスタンスを立ち上げる
- ❸ Pageインスタンスを開く
- ❹ Pageインスタンスを通じて、さまざまな処理を行う
- ❺ Browserインスタンスを閉じて終了する
公式ドキュメントに示されているコンポーネントは図2のとおりです。もちろん例外はありますが、これらのコンポーネントのうち、Puppeteer、Browser、およびPageの3つさえ押さえれば、ほぼすべてのブラウザ操作を自動化できます。そこで、これら3つの主要なコンポーネントの役割と使い方について、解説を進めたいと思います。
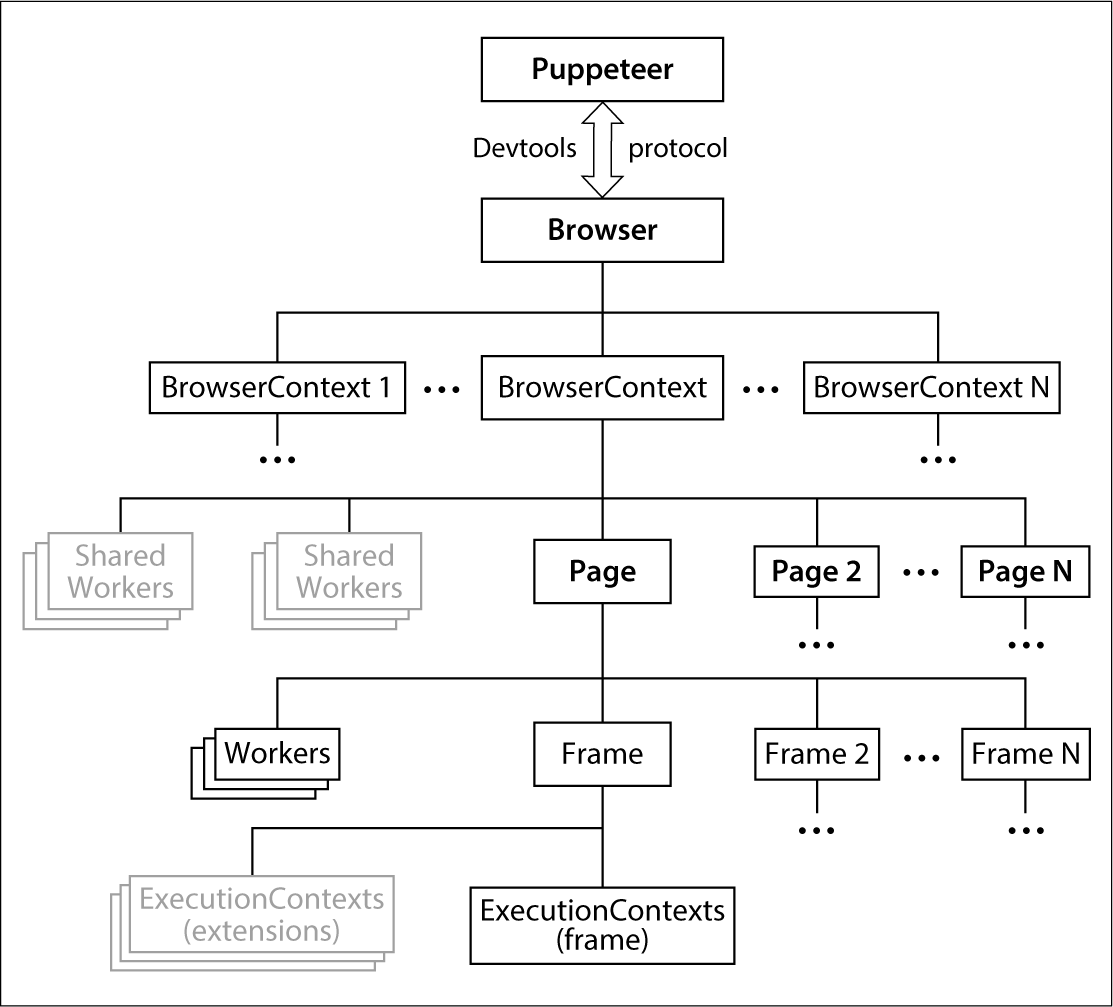
Puppeteer──ブラウザの起動
Puppeteerライブラリは下記のコードで読み込まれ、ブラウザを起動します。
// ライブラリを読み込む
const puppeteer = require('puppeteer');
(async () => {
// ブラウザを立ち上げる
const browser = await puppeteer.launch();
// 以下、ブラウザ操作を自動化する
// ...
})();
ブラウザの起動時、さまざまなオプションを受け取ることができます。その中でも、特に便利なのがheadless、slowMoおよびdevtoolsの3つです。
ヘッドレスモードの解除
Puppeteerはデフォルトで、ブラウザをヘッドレスモードで起動します。しかし、起動時のheadlessオプションにfalseを渡すことで、ヘッドレスモードを解除し、ヘッド
const browser = await puppeteer.launch({
// ヘッドレスモードの解除
headless: false
});
通常のヘッドレスモードでは、視覚的に何が起きているかがわかりにくいという問題があります。しかし、ヘッド
スローモーション再生
しかし、ヘッドレスモードを解除しただけでは、ほとんどのブラウザ操作が一瞬で過ぎ去ってしまいます。そこで、slowMoオプションにミリ秒単位の値を渡すことで、すべてのブラウザ操作の実行が、指定した時間分だけ遅くなります。このオプションを調整することで、あたかもブラウザがスローモーションで再生されているようになり、視覚的な動作確認が行いやすくなります。
const browser = await puppeteer.launch({
headless: false,
// スローモーション再生
slowMo: 1000
});
デバッグモードの開始
さらに、ブラウザをスローモーションで再生するだけでなく、デバッグモードを開始できます。Puppeteerの起動オプションにdevtoolsフラグを渡すと、自動的にデベロッパーツールが開いた状態になります。この状態でデバッガを仕込むことにより、通常のブラウザと同じようにJavaScriptの実行を一時停止したり、ステップ実行が行えるようになります。
const browser = await puppeteer.launch({
// デベロッパーツールを開く
devtools: true
});
ただし、devtoolsオプションを渡してデベロッパーツールを開くと、headlessオプションの値にかかわらずブラウザが必ずヘッド
Browser ──複数タブの管理
Browserインスタンスは、Puppeteerがブラウザを起動することで生成されます。基本的な操作は、ブラウザのタブを開くか、またはブラウザを閉じるかのどちらかです。通常は下記のコードになります。
// ブラウザのタブを開く
const page = await browser.newPage();
// 以下、さまざまな処理を行う
// ...
// ブラウザを閉じる
await browser.close();
シークレットモード
Browserは、内部的にBrowserContext
なお、Puppeteerを使うとブラウザを立ち上げるたびにコンテキストが作りなおされるため、Cookieやキャッシュは毎回クリアされた状態になります。
// シークレットモードを開始する
const context = await browser
.createIncognitoBrowserContext();
// ブラウザのタブを開く
const page = await context.newPage();
Page ──タブ内での行動を操作
Puppeteerは、Pageインスタンスを通じて主要なブラウザ操作を自動化します。ほとんどの場合は、まずpage.メソッドを使ってURLにアクセスすることから始まります。
// URLにアクセスする
await page.goto('https://example.com');
// 以下、さまざまな処理を行う
// ...
その後行うことができる操作は多岐に渡ります。そこで以下では、よく使われるコードのパターンを紹介することで、Puppeteerを使ってできるブラウザ操作に慣れ親しんでもらいたいと思います。
DOMを指定する
URLにアクセスしたあと、ほとんどのブラウザ操作は、DOM
たとえば、下記のようなHTML構造のフォームがあると仮定します。
<html>
<!-- 中略 -->
<body>
<form>
<input type="text" id="search">
<select name="language">
<option value="Japanese">日本語</option>
<option value="English">英語</option>
</select>
<input type="submit" class="button">
</form>
</body>
</html>
ブラウザ上では、図4のように表示されます。
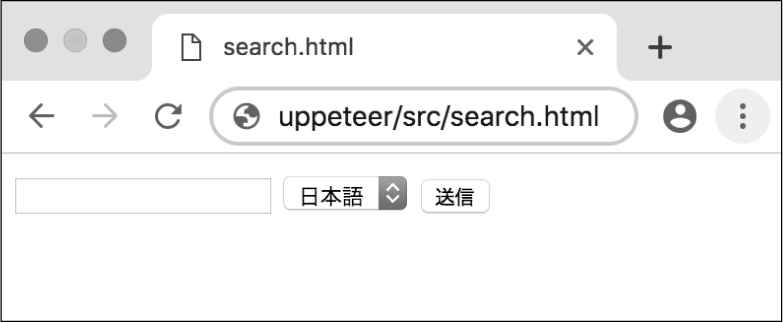
PuppeteerでDOMを指定する方法は、代表的には下記の2つがあります。
CSSセレクタによる指定
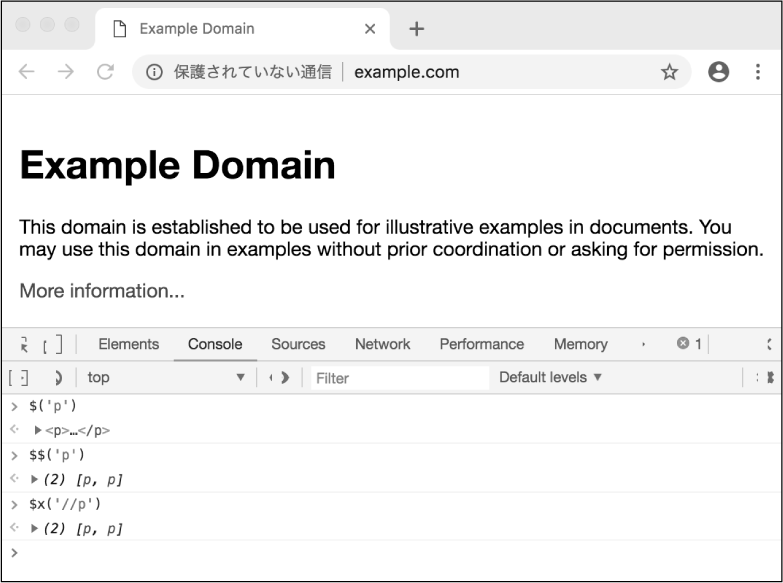
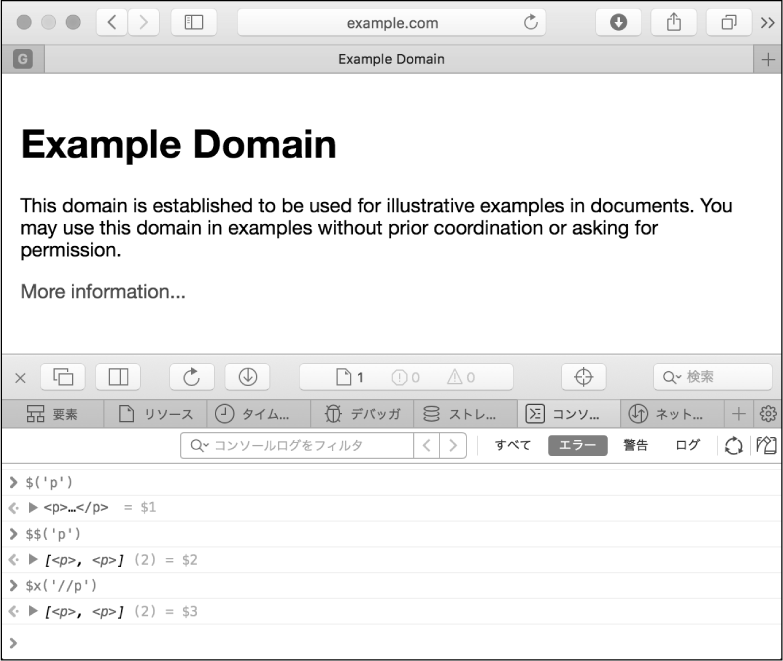
CSSセレクタとは、その名のとおりCSSを適用するためのセレクタです。jQueryセレクタで馴染みがあるかもしれませんが、jQueryには独自の拡張が存在するため、同じセレクタがそのまま適用できない場合もあります。PuppeteerでCSSセレクタを使って特定の要素を指定するためには、page.$()メソッドを使います。
// id属性を使って指定
const search = await page.$('#search');
// class属性を使って指定
const button = await page.$('.button');
// name属性を使って指定
const select = await page.$('[name=language]');
また、CSSセレクタにマッチするすべての要素を指定するためには、page.$$()メソッドを使います。
// 要素名を使って指定
const options = await page.$$('option');
XPathによる指定
一方でXPathとは、XML形式の文書から特定の部分を指定するための言語で、HTMLにも対応しています。XPathを使ってセレクトボックスの選択肢を指定する方法は、下記のとおりになります。
// 要素名を使って指定
const options = await page.$x('//option');
// value属性を使って指定
const path1 = '//option[@value="Japanese"]';
const japanese = (await page.$x(path1))[0];
// 要素内の文字列を使って指定
const path2 = '//option[text()="英語"]';
const english = (await page.$x(path2))[0];
一般的には、CSSセレクタは簡潔に記述でき、XPathは複雑な条件指定ができるという強みがあるようです。たとえば、CSSセレクタでは要素内のテキストを使った指定はサポートされていませんが、XPathではサポートされているという違いがあります。
なお、page.$()が単一の要素だけを取得するのに対し、page.$$()およびpage.$x()は複数の要素を配列として取得する点に注意してください。XPathを使った指定方法では、単一の要素だけを取得するメソッドが用意されていない点にも、注意が必要です。
関数名の由来
ところで余談ですが、どうしてpage.$$()やpage.$x()といった可読性の低い関数名が使われているのでしょうか。実は、これらの関数は、Chrome
デベロッパーツールと関数名に一貫性を持たせているのは、Chromeデベロッパーツールの開発チームならではと言えるかもしれません。
DOMを操作する
先ほど指定したDOMは、ElementHandleと呼ばれるクラスのインスタンスになっています。このインスタンスを通じて、文字の入力やクリックなどの動作を受け付けます。
// 文字の入力
const search = await page.$('#search');
await search.type('puppeteer');
// ボタンのクリック
const button = await page.$('.button');
await button.click();
ボタンのクリックには、左クリックのほかに、右クリック、ダブルクリックといったさまざまなクリック方法がサポートされています。ほかにも、要素のホバーやタップといったさまざまな操作ができます。
// ボタンの右クリック
await button.click({button: 'right'});
// ボタンのダブルクリック
await button.click({clickCount: 2});
// ボタン上でホバー
await button.hover();
// ボタンのタップ
await button.tap();
ショートカットメソッド
さらに、Pageインスタンスには、ElementHandleを経由せずに直接DOMを操作できるショートカットが数多く用意されています。
// 文字の入力
await page.type('#search', 'puppeteer');
// セレクトボックスの選択
await page.select('select', 'Japanese');
// ボタンのクリック
await page.click('.button');
// ボタンの右クリック
await page.click('.button', {button: 'right'});
// ボタンのダブルクリック
await page.click('.button', {clickCount: 2});
// ボタン上でホバー
await page.hover('.button');
// ボタンのタップ
await page.tap('.button');
ただし、これらのメソッドでは、DOMの指定方法として執筆時現在はXPathがサポートされておらず、CSSセレクタのみ使用できます。
しかし、比較的新しいメソッドでは、XPathもCSSセレクタも同様にサポートされているため、このような格差は今後なくなっていくものと考えられます。
画面遷移の完了まで待機する
フォームを送信したりリンクをクリックしたあと、画面は瞬間的には切り替わりません。特にSPAでは必ずしもURLが切り替わらないため、画面遷移が完了したことを何らかの手段で検知しなければなりません。
PuppteerではSPAか否かにかかわらず、画面遷移が完了したことを検知するための便利な関数がいくつも用意されています。
// CSSセレクタがマッチするまで待機する
await page.waitFor('div.container');
// XPathがマッチするまで待機する
await page.waitFor('//div[@class="container"]');
// 指定した時間だけ待機する
await page.waitFor(1000);
// ブラウザ上で関数を実行し、trueが返るまで待機する
await page.waitFor(() => window.innerWidth < 100);
// 画面遷移まで待機する
await page.waitForNavigation();
page.は、デフォルトではloadイベントの発行を画面遷移の完了とみなします。そのほかにも、waitUntilオプションを渡すことで、さまざまな条件の組み合わせを指定できます。
await page.waitForNavigation({
// 指定したすべてのイベントが発生するまで待機する
waitUntil: [
// loadイベントが発行されるまで
'load',
// DOMContentLoaded
// イベントが発行されるまで
'domcontentloaded',
// 500ミリ秒の間、ネットワークの
// 接続数がなくなるまで
'networkidle0'
// 500ミリ秒の間、ネットワークの
// 接続数が2以下になるまで
'networkidle2'
]
});
競合状態による失敗
初学者が陥りがちな過ちは、これらの待機メソッドに対して盲目的にawaitを付けてしまうことです。たとえば、下記のコードは、page.でリンクをクリックし、page.で画面遷移の完了を待つだけの単純なコードに見えます。
// リンクをクリックする
await page.click('.button');
// 画面遷移まで待機する
await page.waitForNavigation();
一見問題なく動作しそうなコードですが、実際に走らせてみると、高い確率で実行が停止してしまいます。その原因は、page.とpage.の競合状態
並列処理の実行
この問題を回避するためには、2つの非同期処理を並列で実行し、両方が完了するまで待機する必要があります。このように、2つ以上の非同期処理を、直列ではなく並列で実行したい場合には、下記のようにPromise.を活用する必要があります。
// 複数の非同期処理を並列で実行する
await Promise.all([
// 画面遷移まで待機する
page.waitForNavigation(),
// リンクをクリックする
page.click('.button'),
]);
Promise.メソッドは、リストとして受け取ったすべてのPromiseを実行する便利な関数です。すべてのPromiseでresolve()が呼び出されて正常に完了するか、または1つでもreject()が呼び出されて失敗すると、非同期処理は終了します。
上記の修正によって、リンクのクリックと同時に画面遷移の完了まで待機するコードになったため、意図したとおりに動作するようになりました。
ブラウザ上でJavaScriptを実行する
画面遷移が完了したら、Node.page.メソッドを使って、リンク先のURL一覧を受け取るコードです。
// ブラウザ上でJavaScriptを実行する
const hrefs = await page.evaluate(() => {
// すべてのアンカーリンクを取得する
const elements = document.querySelectorAll('a');
const anchors = Array.from(elements);
// リンク先のURL一覧を受け取る
return anchors.map(anchor => anchor.href);
});
コードは比較的単純ですが、いくつか注意すべき点があります。
実行時の注意点
まず1つ目の注意点は、page.のコールバック関数が、Node.document.のようなブラウザ上にしか存在しない関数を呼び出すことができます。
一方で、下記のようなNode.
// queryはNode.js上にしか存在しない
const query = 'a';
const hrefs = await page.evaluate(() => {
// queryがブラウザ上に存在しないため例外が発生
const list = document.querySelectorAll(query);
const anchors = Array.from(list);
return anchors.map(anchor => anchor.href);
});
このように、Node.page.の第2引数以降に渡す必要があります。
// 第2引数で渡された値を受け取ることができる
const hrefs = await page.evaluate(query => {
const list = document.querySelectorAll(query);
const anchors = Array.from(list);
return anchors.map(anchor => anchor.href);
}, 'a'); // 第2引数に値を渡す
もう一つの注意点は、ブラウザ上のJavaScriptの実行結果が、シリアライズ可能
上記の例では、実行結果である文字列の配列がシリアライズ可能であるため、意図したとおりに動作させることができます。
スクリーンショットを撮影する
画面に表示されている内容は、JavaScriptを実行して受け取るだけでなく、スクリーンショットとして撮影することもできます。スクリーンショットは、テストやスクレイピングが失敗したときに撮影することで、デバッグに役立てられるでしょう。
ページ全体のスクリーンショットは、page.メソッドを使って撮影し、保存できます。
// スクリーンショットを撮影する
await page.screenshot({
// 画像を保存する絶対パスまたは相対パス
path: 'screenshot.png',
// ページ全体を撮影する
fullPage: true
});
特定の要素だけを撮影
さらに、指定したDOMのスクリーンショットだけを、element.メソッドを使って保存することもできます。この機能を活用することで、画像どうしの差分を利用したテストも実現しやすくなるでしょう。
下記は、表示された画面の中から、1つ目のdiv要素だけを抜き出して、スクリーンショットとして保存するコードです。
// 1つ目のdiv要素を指定する
const element = await page.$('div');
// 指定したdiv要素のスクリーンショットを撮影する
await element.screenshot({path: 'div.png'});
まとめ
第2章では、非同期処理を便利に扱うためのasync/