


こんにちは、CyberAgentの岩井佑樹
KubernetesとBatchワークロード
Kubernetesではこれまで標準機能として、ロードバランシングやローリングアップデートなどのServiceワークロードのための機能や、Container Storage Interface
この課題に取り組み、Kubernetesの標準機能としてBatchワークロードをよりサポートしていくためにWorking Group Batch
- 信頼性、拡張性、機能性に優れたJob APIの提供
- JobレベルでのQueing/
Scheduling/ Provisioning/ Autoscalingに関する機能強化 - NUMAやGPUなどの特別なハードウェア使用時の制約軽減
これらの活動目的に対してKubernetes v1.
1のJob APIの提供については、次のものがあります。
- Index値を持ったPodの作成を可能にするIndexed Job
- batch/
v1 Jobを一時停止可能にするSuspend Jobs - 終了済みのbatch/
v1 Jobを自動で削除可能にするTTL After Finished
2の機能強化については、次のようなものがあります。
- Podをグループ毎にスケジューリング可能にするco-scheduling scheduler plugin
- テナント間で動的な計算リソース融通を可能にするcapacity-scheduling scheduler plugin
3の制約軽減については、次のものが既にあります。
- NUMAなどのtopologyを考慮したPodのスケジューリングを可能にするtopology-aware scheduler plugin
このように複数のSpecial Interest Groups
Kueueの概要
KueueはKuberenetes-nativeなJob Queueingを実現するためのOSSであり、次の5つの目的を持っています。
- Queueing:JobはNodeが空くまで開始されるべきではない
- Execution order:ユーザはJobの実行順序に干渉する方法を持つべきである
- Fair sharing:利用可能な計算リソースを複数テナント間で公平に共有すべきである
- Flexible placement:ユーザはJobをスケジューリングする際に、場所・
VM/ GPU種別・ 時間の3つを柔軟に表現できるべきである - Budgeting:管理者は計算リソースの使用量を時間単位で管理できる必要がある
一方でKueueは基本的にJobの管理に焦点を置いているため、Batchワークロードで一般的に求められる、クラスタの自動スケーリングやJobプロセス
さらにKueueはBatchワークロード特有の次のような計算機環境でも、不自由なく動作可能であることにも焦点を当てています。
- 計算リソースが動的に変化し、スケールアップやスケールダウンする環境
- amd64やarm64などのCPUアーキテクチャや、SpotやOnDemandなどのNodeのライフサイクル、GPUなどのアクセラレータ種別が異なるNodeが混在しているheterogeneousな環境
これらの環境へ柔軟に対応するため、Kueueは後述するClusterQueueやResourceFravorを用いて複雑な組み合わせの計算リソースの定義を行う機能や、Cohortと呼ばれるグループ内での計算リソースの融通を行う機能を持っています。
Kueueの機能
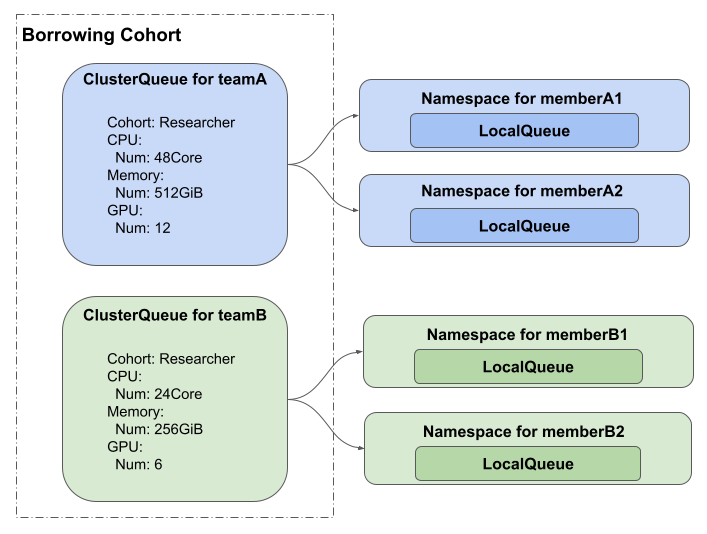
Kueueでは管理者が計算リソースの管理を行い、研究者やデータサイエンティストなどの利用者がQueueとJobを作成する設計となっています。
たとえば、Queueing基盤を利用する2つのチーム、teamAとteamBが存在し、それぞれのチームにmemberA1・
ResourceFlavor
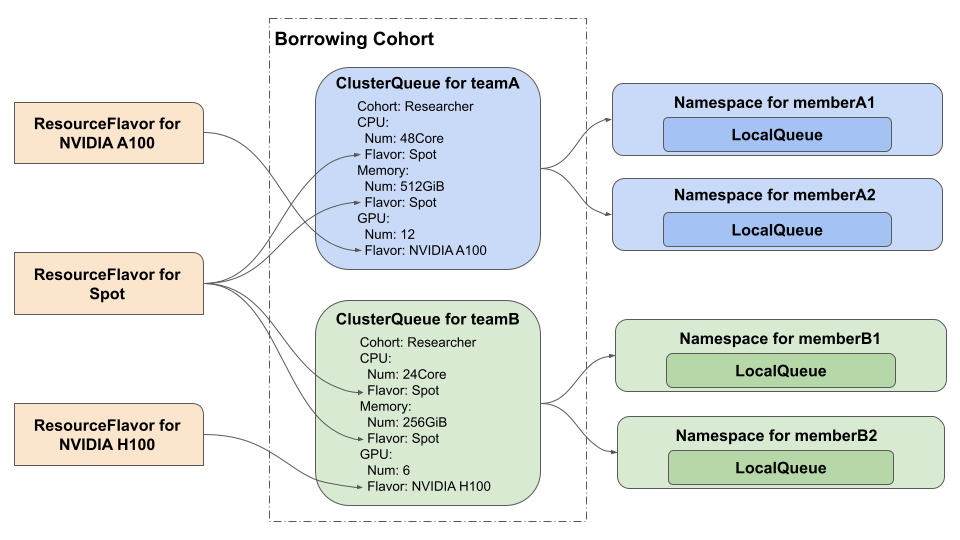
Kueueには、heterogeneousな環境向けの機能としてResourceFlavorがあります。ResourceFlavorは図2のように、ClusterQueueへ計算リソース種別ごとに指定でき、ResourceFlavor内で指定したラベルがWorkloadのnodeSelectorとして使用されます。
また、特定のWorkloadからのみ使用できるResourceFlavorを作成する機能として、ResourceFlavor Taintがあります。これはNodeTaintと同様に、ResourceFlavorにTaintをつけておくことで、該当するTolerationを持つWorkloadからのみ、ResourceFlavorを使用できるようにする機能です。
たとえば、SpotインスタンスのためのResourceFlavorであるSpot ResourceFlavorにおいて、ResourceFlavor Taintの機能を用いると、WorkloadがSpot ResourceFlavorのTolerationを所持していない限り、そのResourceFlavorが使用されることはなくなります。これにより、誤ったResourceFlavorを使用したWorkloadの実行を防ぐことができます。
Cohort
Kueueは、計算リソースを融通し合うことが可能なClusterQueueのグループであるCohortをClusterQueueに設定でき、同じResourceFlavorを持つ計算リソースに限り、計算リソースを融通し合うことができます。
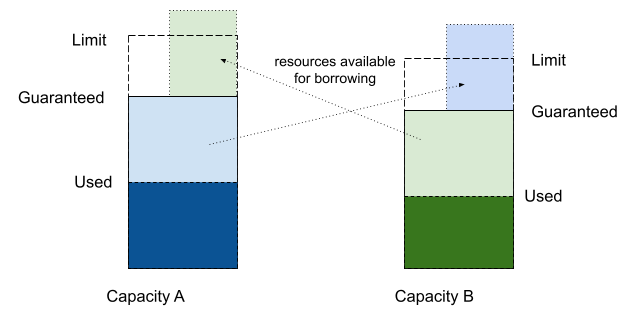
ClusterQueueには、最低限確保しておく計算リソース
たとえば図2において、teamBのClusterQueueのCPUが枯渇した場合に、teamBのClusterQueueは同じResearcher CohortであるteamAのClusterQueueから次の3つの条件を満たす範囲でCPUを借りることができます。また、以下でCQ(A)はteamAのClusterQueueを、CQ(B)はteamBのClusterQueueを表します。
- CQ(B)のCPUの最低保証数とCQ(A)から借りるCPUの合計がCQ(B)のCPUの最大利用可能数を超えない
- CQ(B)がCQ(A)から借りることができるCPUはCQ(A)の最低保証数以下で、未使用のものに限る
- CQ(B)が借りる計算リソースは、CQ(A)とCQ(B)の両方が利用しているSpot Flavorに限る
なお前述したように、同じCohort内のClusterQueueは、同じFlavorの計算リソースのみを貸し借りできるため、teamBのClusterQueueでNVIDIA H100 GPUが枯渇した場合に、teamAのClusterQueueからNVIDIA A100 GPUを借りることはできません。
さらに注意点として、現在の実装ではKueueにWorkloadを中止させる機能は実装されていません。そのため一度計算リソースを他のClusterQueueに貸し与えた場合、貸した計算リソースをすぐに取り戻すことはできず、貸した計算リソースが割り当てられているWorkloadの終了を待つ必要があります。
Queueing Strategy
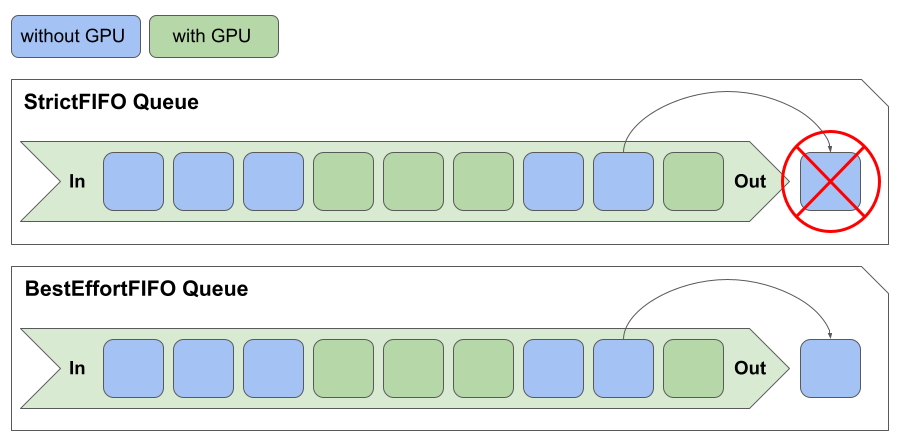
ClusterQueueにはQueueingの戦略を設定できます。現在は、StrictFIFOとBestEffortFIFOの二つの戦略が用意されており、デフォルトではBestEffortFIFOが使用されます。
StrictFIFOは、WorkloadをKubernetes標準機能であるPodPriorityの高いもの順で並び替えた後、さらに作成時間が早いもの順で並び替え、先頭から順番にスケジューリングする戦略です。
BestEffortFIFOは、StrictFIFOと同様の手順でWorkloadを並べ替えます。しかし、先頭のWorkloadがスケジューリング不能で、その後ろに積まれているWorkloadがスケジューリング可能な場合は、先頭のWorkloadを無視して、後ろのWorkloadをスケジューリングする戦略です。
たとえば、ClusterQueueのGPUがすべて使用中の際に、先頭のWorkloadがGPUを必要とするもので、その後ろにはCPUのみを使用するWorkloadが積まれている場合などで動作が変わってきます。図4のようにStrictFIFOの場合、GPUが使用可能になるまですべてのWorkloadのスケジューリングが止まります。しかしBestEffortFIFOの場合は、GPUを必要としないWorkloadはCPUが空いている限り、スケジューリングされていきます。
Kueueのアーキテクチャ
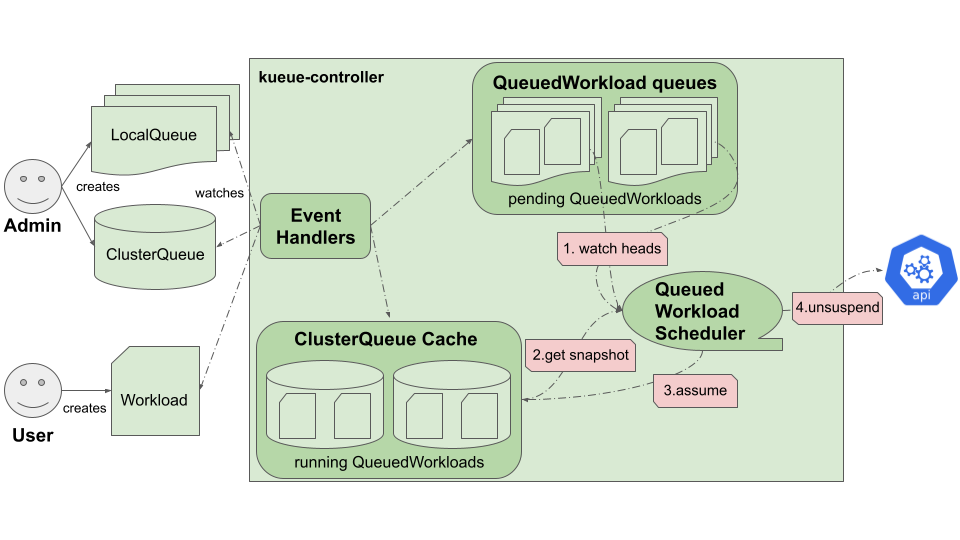
Kueueの実態はkueue-controllerです。kueue-controllerは主にClusterQueue・
kueue-controllerのコアロジックは図5のようになっています。ユーザがLocalQueueを指定したbatch/
その後、Workloadに含まれるすべてのJobが必要とする計算リソース量が、LocalQueueにひもづくClusterQueue内で確保できると、ClusterlQueueにWorkloadが割り当てられます。そしてkueue-controllerが、Suspend Jobsの機能を用いてbatch/
Kueueの今後
Kueueは開発がはじまったばかりのOSSであり、これから実装が予定されている機能が多くあります。その中でも筆者が注目している4つの機能について紹介します。なお、紹介する機能はまだ仕様が完全に決まっておらず、今後仕様の変更や実装自体が取りやめになることもあります。
1つ目がkubeflow/
2つ目はWorkload Preemptionです。
3つ目はBudgetsです。ある時点におけるClusterQueueが確保できる計算リソース量はmaxフィールドで現在も設定可能になっていますが、一ヶ月間などの一定期間内でのClusterQueueが使用できる計算リソース量を制限する方法がありません。そこでBudgetを導入することで、特定のClusterQueueによる計算リソース占有の防止や、パブリッククラウドの利用料金の抑制などが期待されています。
最後はFlavorAssignmentStrategyです。現在のKueueは、ClusterQueue内に同一計算リソース種別で、Flavorが異なるものが設定されている場合に配列の上から順番に計算リソースをWorkloadへ割り当てる、InOrder戦略のみがサポートされています。この戦略で問題となるのがCohortの扱いです。たとえば、0番目に設定されているOnDemand FlavorのCPUは不足しているが、1番目に設定されているSpot FlavorのCPUは十分にある場合でも、Cohort内の他ClusterQueueからOnDemand FlavorのCPUを借りてきます。そのため、ClusterQueue内のCPUを先にすべて消費してから他ClusterQueueからCPUを借りるといった動作をすることができません。この問題を解決するためにMinimizeBorrowing戦略が実装される予定になっており、最も計算リソースの貸し借りが発生しない方法でWorkloadに計算リソースを割り当てることが可能になります。
まとめ
本記事ではKubernetesにおけるBatchワークロードの取り扱いとKueueついての紹介を行いました。
「Kueueの今後」