



データエンジニアリングとは何か
昨今、データドリブンな経営・
この記事ではデータエンジニアリングを実践するにあたって
なお、本記事は筆者の経験則に基づく解釈が多く含まれております。より客観的に学びたい方に向けて参考文献も記載しておりますので、併せてご参照頂けますと幸いです。
データ分析基盤の必要性
データ分析やデータ活用を行うシステム基盤のことを、データ分析基盤と言います。
通常分析に必要なデータは企業内に散在しており、分析するためには1箇所に集約する必要があります。
たとえば、広告の費用対効果を算出したい場合、広告費用に関するデータは広告管理画面から取得し、一方で広告経由で発生した売上データはSalesforceなどのCRMツールから取得します。それらを1箇所に集め、集計することによって費用対効果を算出します。
これを実現するためには、データウェアハウス
このデータ統合を行う仕組み
データエンジニアの役割
次に、データ分析基盤の構築や運用を行う役割である
前述したデータエンジニアリングを実際の業務として行う人のことを
データ分析基盤の構築と運用をメインの役割としておりますが、データ活用を行うための環境整備や、場合によってはデータ分析自体を行う場合もあります。
一方で
技術要素・技術スタック
では、データエンジニアリングの世界では日々どのような業務を行っていて、そこではどんな技術が活用されているのでしょうか。
ここでは、以下2つのフレームワークを使って解説していきたいと思います。
- DAMAホイール図
(DAMA DM Body of Knowledge 2より) - The Modern Data Stack
DAMAホイール図から見る、技術スタック
DAMAホイール図とは、データマネジメント協会という全世界に支部を持つ団体の出版しているDMBOK2という書籍で出てくる、
データマネジメントとは、エンジニアリングの技術ノウハウを用いて、データ分析基盤周辺のデータを正しく管理することです。
図1がDAMAホイール図で提唱されている、データマネジメントに必要な10+1の領域となります。
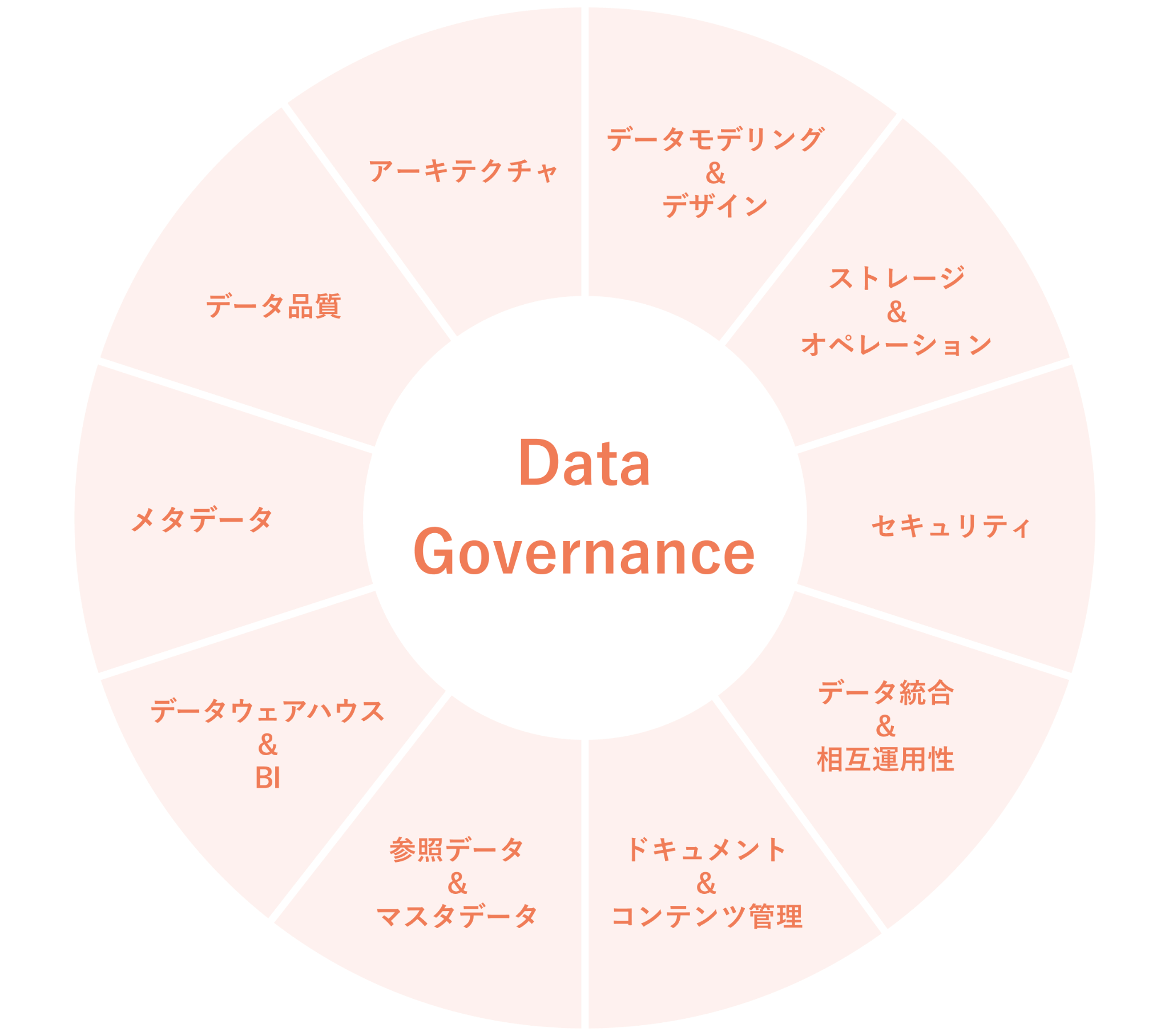
それぞれの領域では以下のような目的を達成するべきものとしています。
- データアーキテクチャ:データ分析基盤全体の設計図を作成する
- データストレージとオペレーション:データを保管するシステムの構築・
運用保守をする - データ統合と相互運用性:分析データを1箇所に統合し、組織内で運用しやすい形で保持する
- データモデリングとデザイン:データをビジネス活用しやすい形に設計・
変換する - データウェアハウジングとビジネスインテリジェンス:DWHシステムの選定・
構築と、BIツールなどを用いてデータをビジネス活用する - マスタデータ管理:組織横断で利用されるデータをマスタデータとして定義し、運用保守する
- ドキュメントとコンテンツ管理:PDFやワード・
エクセルファイルなど、非構造データを管理する - データセキュリティ:データの取扱いに関するルールを策定し、組織内で監査する
- データ品質:蓄積したデータについての品質要件を定義し、要件を満たすようにデータの品質を担保する
- メタデータ管理:各データに対して説明を付与し、検索性や運用性を向上する
- データガバナンス:10領域について組織内での実運用を行い、ビジネスに活用していく
Peter Aiken's framework
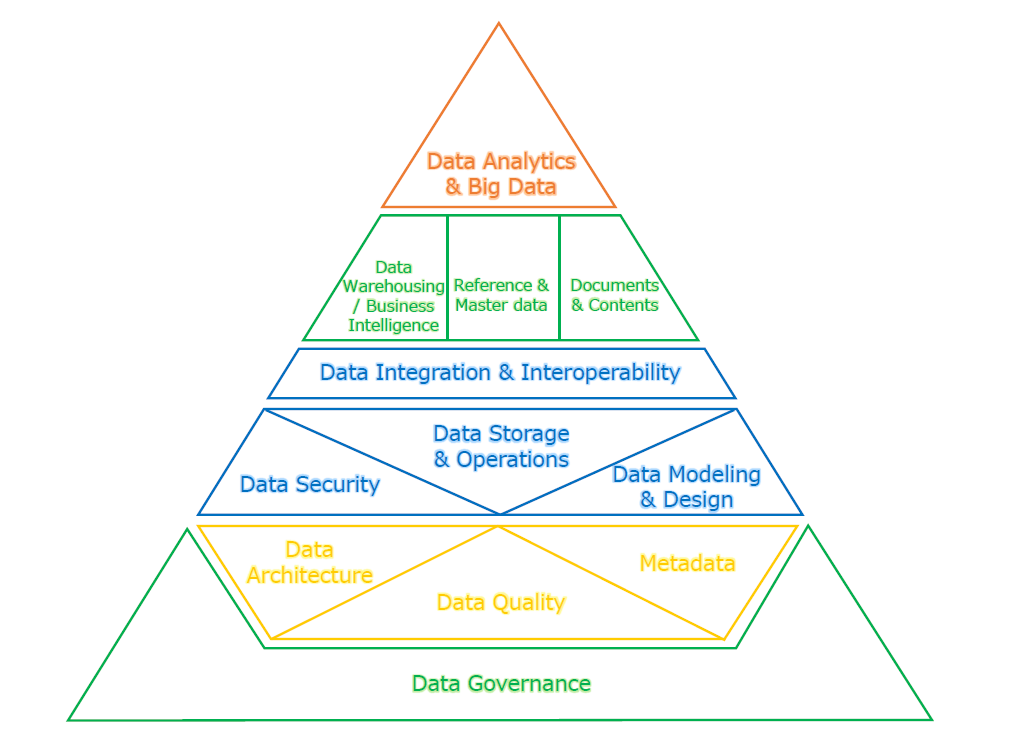
図の下から、色分けされた層順に以下のような分類となっており、より実運用に近い依存関係や関連性がわかるかと思います。
- データガバナンスの実行:他の各領域を、組織内で実運用する
- データ品質・
利便性の向上:データの品質や利便性を担保する - データの統合・
蓄積:データを組織内で利用しやすい形で管理する - データの提供:データを処理・
利用するための手段を提供する - データ分析の実行:実際にデータ分析を行い、ビジネスに活用する
こちらのDAMAホイールで紹介されている各種領域について詳しく知りたい方は、以下の書籍をおすすめします。
ゆずたそ著
The Modern Data Stackから見る、近年の必要技術スタック
The Modern Data Stackとは、現代におけるデータ処理・
DAMAのホイール図と比べると、より具体的な要素技術にフォーカスしており、なおかつ最新の技術進化への追従性が高いことが特徴的です。
The Modern Data Stackの要素技術を習得することは、データエンジニアになるための必修科目と言っても過言ではないでしょう。
具体的には以下のような領域が存在しています。
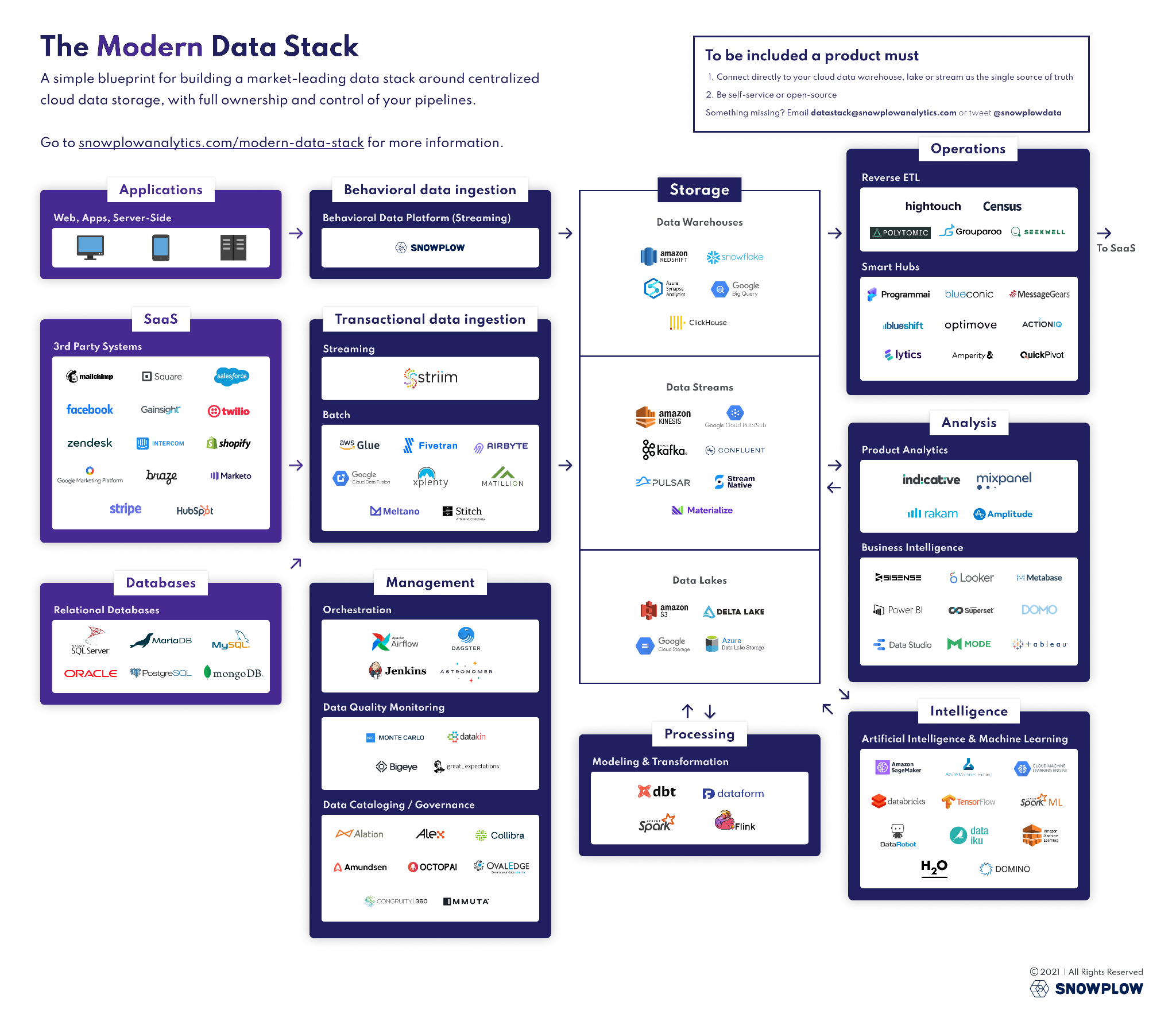
図3はThe Modern Data Stackの一部領域・
ここですべててのカテゴリについて説明することは控えますが、とくに押さえるべき技術要素を一部ピックアップしてご紹介します。
データの統合・蓄積
- Data Warehouses:分析に最適化された形でデータを蓄積するためのサービス群
- ETL Tools / Change Data Capture / Data Streaming:データを統合するためのサービス群
データ処理
- Modeling & Transformation:蓄積されたデータを変換するためのサービス群
データの管理
- Workflow Orchestration:データ統合やデータモデリングを動かすためのジョブ管理サービス群
- Data Cataloging / Data Discovery:メタデータを蓄積し、データの検索性や理解を促すためのサービス群
- Data Quality Monitoring:低品質なデータの検知や、データ品質を担保するためのサービス群
分析・活用
- Reverse ETL:蓄積したデータを実ビジネスで利用している別サービスに連携するためのサービス群
- Business Intelligence:データの可視化や簡易的な処理を行うためのサービス群
- Product Analytics:提供製品の分析に特化したサービス群
Modern Data Stackでは、これらの技術要素を実現するための実サービスやOSSを紹介していたり、各企業で利用しているデータ関連の技術スタックをまとめていたりします。
ロードマップ
さて、ここまででデータエンジニアリングの定義と、必要となる技術要素について解説してきました。
ここでは、それらの技術要素をどのような順序で学ぶべきか、ロードマップを用いてご紹介します。
データエンジニアリング・ロードマップ
データエンジニアリングを実際に行うにあたり、筆者が適していると思う学習の順序・
Startから順に学んでいくことで、データ基盤の成長過程に適した技術を学べるようにしています。
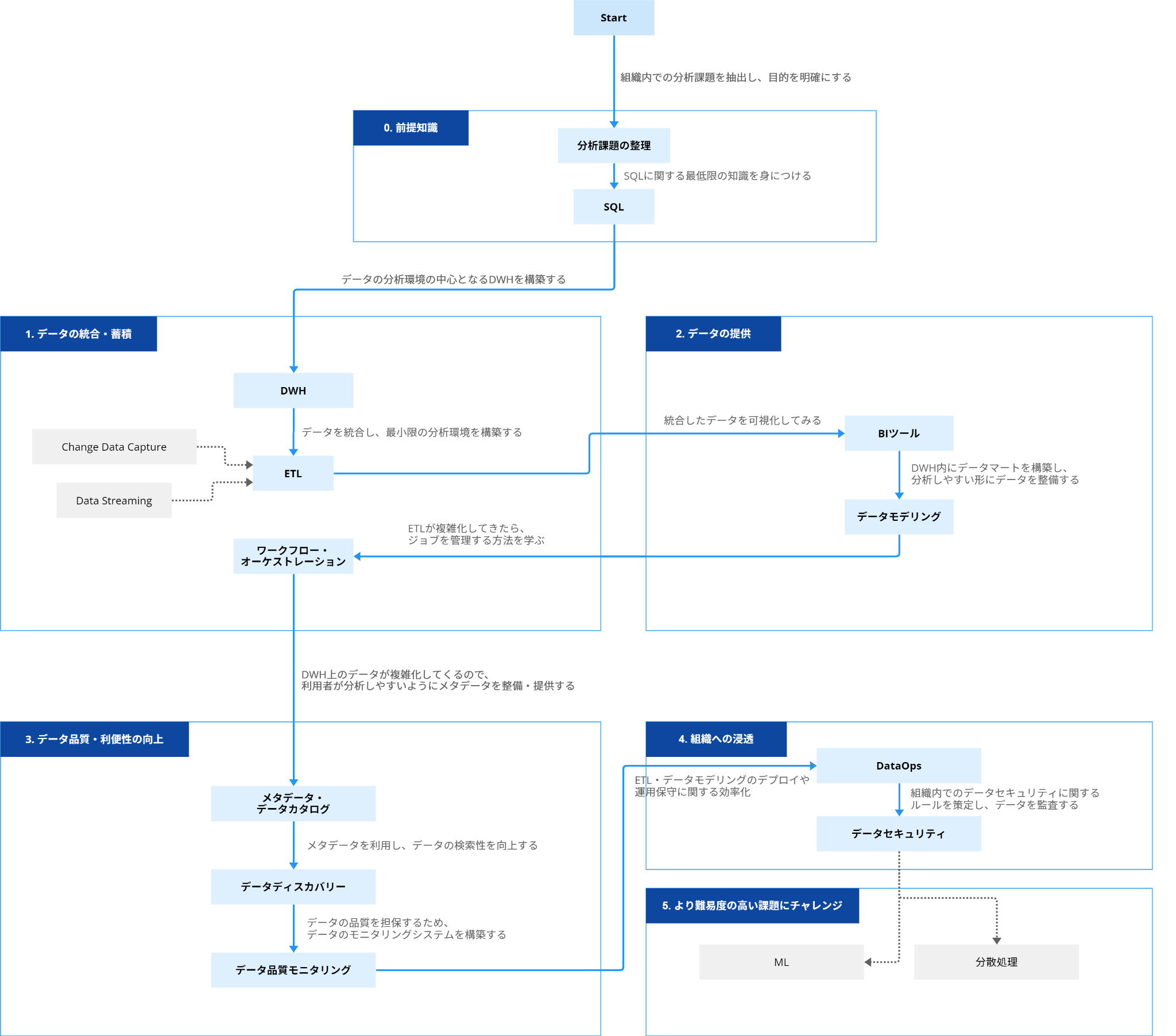
Startからいきなり
「何ができるか、どんな技術を使うか」
「何の目的でデータ分析基盤を作るのか、誰のどんな課題を解決するためにやるのか」
以後は前述の部分で説明したカテゴリと要素技術が並んでいます。
なお、説明の都合上、独断によって前述とは異なるカテゴリに分類されている要素がある点にご留意ください。
データエンジニアのキャリア
ここまで学んできたデータエンジニアとしてキャリアを歩みはじめる場合、どのようなキャリアパスが存在するのかをご紹介していきます。
キャリアのはじまり
一般的には、ソフトウェアエンジニアやインフラエンジニアといったキャリアからのコンバートが多いかと思います。
これはデータエンジニアリングやデータマネジメントといった領域が専門性が高く、エンジニアリングのベストプラクティスを結集して解決すべき難易度の高い課題に溢れていることが影響しているかと思われます。
また、多くの場合データ分析基盤はクラウド上に構築するため、AWSやGCPといったクラウドに関する基礎知識も必要とされるでしょう。
初級データエンジニア
ロードマップにおける
多くの場合、他のエンジニア職種からコンバートして、書籍やネット上の情報を頼りに独学で学ぶことが多いかと思います。
社内外でメンターや顧問を探し、最短ルートで学びながら
中級データエンジニア
「0. 前提知識」
ここまで来るとかなり多くの課題に直面するため、人員を増やしてチームを組織する必要も出てきます。
データ分析の品質・
上級データエンジニア
ジェネラリストとスペシャリストの2つのキャリアパスがあると考えます。
ジェネラリストは上述するすべての要素技術を一通り学び、チームを指揮しながら組織においてインパクトの大きいデータ分析課題を解決する能力が求められます。
スペシャリストは要素技術の一部に関して、最新の技術を駆使しながらより難易度の高い課題を解決する能力が求められます。例えば膨大な量のデータを、一定時間内に高速に処理するETLに関する能力などです。
まとめ
今回の記事では、データエンジニアリングの定義と、それを学ぶためのロードマップやキャリアパスについてご紹介しました。
データエンジニアリングはかなり多くの技術領域があり、なおかつそれぞれの領域の専門性が非常に高いため、かなり難易度の高い分野だと思います。
それゆえに市場価値も高く、ソフトウェアエンジニアやインフラエンジニアからの次のステップとしてもおもしろいと思います。
あなたの学んできたエンジニアリングの知見をすべて活かしながら、チャレンジしてみるのはいかがでしょうか。