



9月8日から10日に三重県にて開催されたRubyKaigi 2022。最終日である3日目の最後のセッションとしての基調講演にAlan Wu氏が登壇しました。
Wu氏はRuby Committerの1人であり、現在ではShopifyにおいてYJITの開発に携わっています。
発表は

そもそもYJITとは
発表の内容に触れる前に、まずYJITについて簡単に紹介します。YJITは、Shopify社が中心となって開発をしたCRubyのJITコンパイラの一つです。2021年12月に公開されたRuby3.--yjitオプションを付与することで利用可能です。
もともと、Ruby2.
詳しくは、Shopifyの開発チームがブログ記事"YJIT: Building a New JIT Compiler for CRuby"やYJITのドキュメントが公開されているため、そちらをご覧ください。
逆に遅くなる? YJITの最初期のデザイン
さて、ここから基調講演の内容です。
まず講演の最初に、Wu氏はYJITの最初期のデザインについて紹介しました。
最初期は、機械語レベルでRubyのインタプリタが実行する順序、つまり上から下への処理の流れを模倣するという、非常にシンプルなものでした。
x=2+2に対するYJITの初期の振る舞い
Rubyのコードは、実行される際に字句解析が行われ、YARVのバイトコードに変換されます。たとえばx=2+2をYARVバイトコードxに代入します。

一方でYARVは、Rubyプロセスを起動時に、あらかじめISeqの命令列の定義を読み込み、メモリ上に保存しますopt_の処理はアドレス10を先頭に配置、putobjectの処理はアドレス30を先頭に配置のような具合です。
実際に実行してみると、上記写真の右側のような実行順序になります。Machine Codeは、実行時にRuby Codeの実行順序となるよう実行時に赤矢印の順序でアドレスをジャンプして、命令を参照しています。そのため挙動は少し複雑です。
そこで初期の設計では、このジャンプ処理などを減らしました。命令数も減り、高速化できるのではないかというのがミソというわけです。
実際にこのYJITの実装でベンチマークを実行したところ、optcarrotでは7.
遅くなった原因は「シンプルすぎた」こと
この結果を受け、なぜ遅くなったのかを調査したところ、興味深いことがわかりました。
そもそもoptcarrotとrailsbenchは、当然ながら、アプリケーションとして大きく異なります。前者はNES
実はそれだけではなく、この2つは実行中のCPUの挙動も大きく異なっていました。
YJITを無効にしたRubyの実行を対象に、トップダウン解析と呼ばれる手法を用いて、それぞれのベンチマークの特性について解析をしました。するとoptcarrotに比べてrailsbenchは、全体的に投機的実行の失敗やパイプラインストールが発生していました。そしてパイプラインストールの中でも特にフロントエンド依存な問題の発生割合が高いことも明らかになりました。
| retiring | bad speculation | frontend bound | backend bound | |
|---|---|---|---|---|
| optcarrot | 60. |
10. |
14. |
15. |
| railsbench | 25. |
18. |
32. |
23. |
CPUの世界では、内部の機構をフロントエンド
また、RubyのプログラムとYJITが生成したコードの行き来
加えて初期のYJITでは、この汚染されたパスもコード生成に利用していたため、さらに問題を悪化させていました。
これらが原因となり、初期のYJITではrailsbenchのパフォーマンスが劣化してしまいました。
分岐を減らして高速化:Lazy Basic Block Versioning(LBBV)の導入
高速化するためには、YJITがより最適化されたマシンコードを出力する必要があります。
それを実現するためにLazy Basic Block Versioning
LBBVとは、Maxime Chevaller-Bolsvert氏によって発表されたJITコンパイラの型チェックに関する手法です。arXivに論文が公開されているので、興味がある方はそちらをご覧ください。
本発表では、LBBVにおける"Lazy"とはどういうことかを説明しました。
次の図はcall_が呼び出された際のcall_メソッドの動作例です。call_の定義の時点objは型が不明です。また、obj.は基底クラスであるObjectに定義されているitselfメソッドなのか、オーバーライドされたitselfメソッドなのかもこの時点では不明です。そのため、YJITはメソッド内の処理であるobj.をstub化して型の評価を行いません
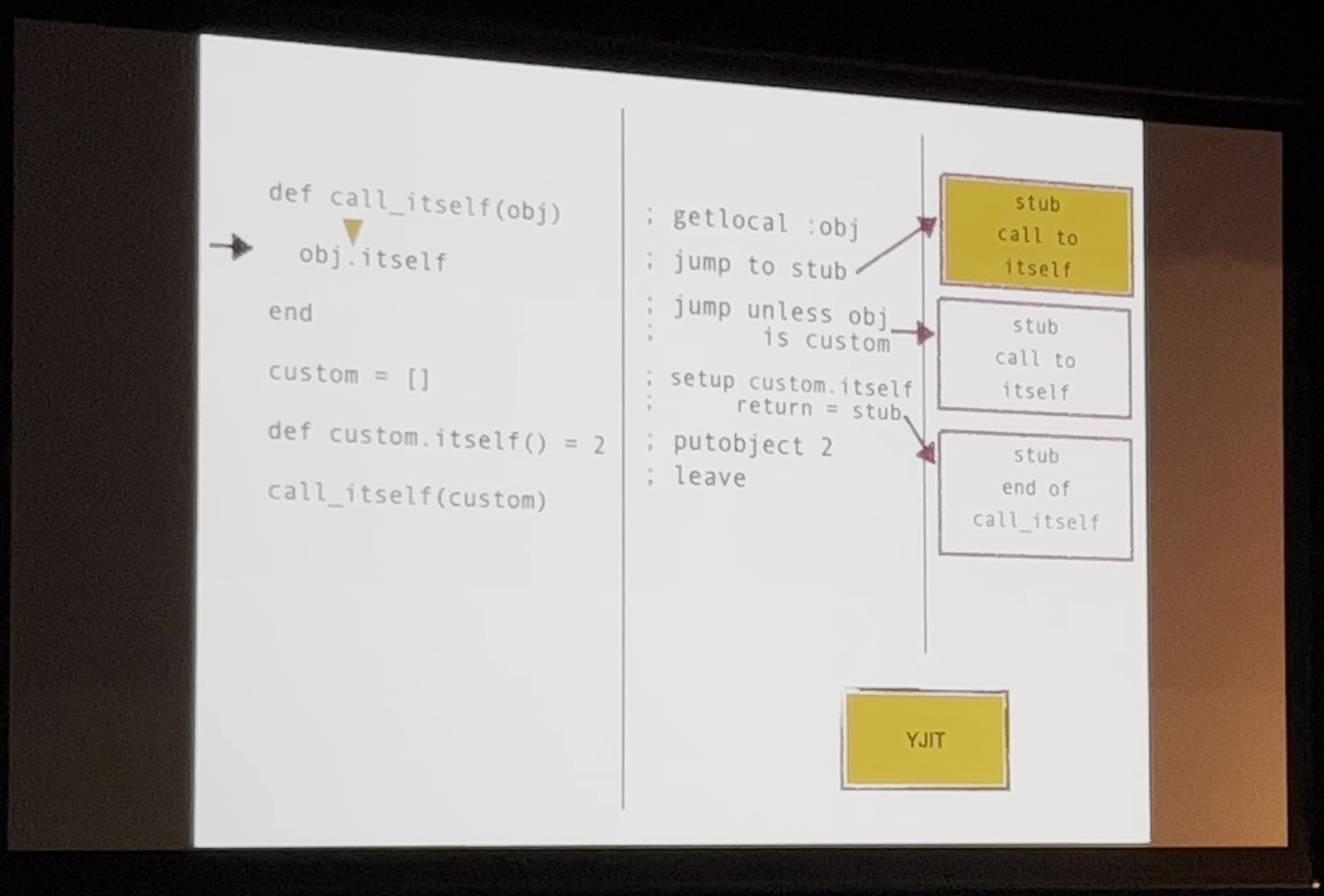
call_が定義された後、4行目から実際の処理が行われ、customであったりdef custom.など、型やitselfメソッドの挙動が決定されます。そして、6行目のcall_が実際にコールされるタイミングにおいて、初めてstub化されたobj.を評価します。このとき、引数がcustomの場合にのみ、実際に処理が行われるようYJITは命令を生成しsetup custom.の処理)、それ以外がobjとして渡されたときの処理はstub化します
では、custom以外の引数が渡されたとき、YJITはどのような挙動をするでしょうか。例として、[3]
custom以外の引数が渡された場合のYJITの挙動
[3]は、当然customとは異なるため、生成済みの処理は利用できません。そのためYJITは、初めてcustumが渡されたときと同様に、[3].itselfのコードを出力します。[3]のitselfメソッドは、特にオーバーライドもされていないため、Array#itselfすなわちKernel#itselfのコードが出力されます。また、Array以外の型の処理についても同様にstub化します。
ところで、この挙動はcall_の引数が変わるたびにYJITによるコンパイルが行われるため、一見効率が悪そうに見えます。
しかしWikipediaのインラインキャッシュにあるごく簡単な調査によると、1つのプログラム内において90%程度はMonomorphic、つまり型が変化しないと言及されています。実際の調査でも、ShopifyにおけるCRubyコードにおいては約92%がMonomorphicであることがわかりました。
つまり、最初のメソッド呼び出しで生成されたコードがそのまま再利用可能な確率が非常に高いということです。この挙動は、インラインキャッシュとの相性が非常によく、投機的実行にうまく効き、結果としてもともと言われていたフロントエンド依存なストールに対して非常に効果的でした。
以上のことを踏まえて、YJITは命令生成を次の戦略で行うよう実装しました。
- できるだけ生成済みのコードを実行する
- 動的な命令の場合はstubを差し込んで型推論を行う
- 上記2つができないとき、インタプリタの実行にフォールバックする
この状態で、改めてrailsbenchを実行しました。結果を比較したのが次の表です。
perf stat railsbenchの結果| 命令数 | 1サイクルあたりの命令実行数 | |
|---|---|---|
| Interpreter | 104360039152 | 1. |
| YJIT | 87535747021 | 1. |
生成された命令数はインタプリタ比約15%減となり、サイクルあたりの命令実行数も向上しました。
YJITのさらなる高速化にむけて:Deoptimizationの最適化
Wu氏は、将来YJITでの採用を考えている最適化についても発表しました。
前項で挙げたYJITの命令生成の戦略において
一般にこのことをDeoptimizationというのですが、現時点では以下の2つが行われています。
- (YARVにおける)
コントロールフレームのスタックポインタの書き換え - コントロールフレームのプログラムカウンタの書き換え
YJITは、現時点ではYARV命令列に沿ってコード生成をしています。しかし、このやり方だと同じレジスタに対するstore命令とload命令が連続するなど、効率的でない処理が発生してしまいます。今後は、この重複した命令を減らすなどの最適化を取り込むために、Deoptimizationに2つの仕組みを追加したいと考えています。
- レジスタ上にのみ残ったスタックのメモリへの書き戻し
- YJITの実行情報から必要なスタックフレームの書き戻し
この2つによって、最適化により命令を削除した場合でも適切にインタプリタに必要な情報を戻せるようにしていくようです。
YJITの挑戦と今後
発表の最後に、Wu氏は現在取り組んでいるYJITの技術的な挑戦と今後を語りました。
YJITは、前述したように、特にDeoptimizationの部分について大きな挑戦を行っています。今後は、実行時はもちろん、起動時間の短縮など、プロセス実行から終了まで全体で見たときのパフォーマンス向上を引き続き目指していくとのことでした。
なお、RubyKaigiの会期中には、arm64に対応したYJITがバンドルされた、Ruby3.
まとめ
このセッションはRubyKaigiらしい、Rubyユーザーはまず意識することのない非常に低レベルな処理部分の話でした。Twitterの実況や中継のコメント欄も、最初のほうこそ有識者の実況が流れていましたが、途中からは
RubyKaigiは、他の言語系カンファレンスに比べて言語そのものの処理系の話が比較的多く話されるカンファレンスです。そのため、このセッションのような難易度の高いセッションも多く、会期中は"C言語会議"とか"CPU会議"と評した感想もちらほら見られます。しかし、ユーザとして普段意識せず当たり前に使っている