



『家族アルバム みてね』
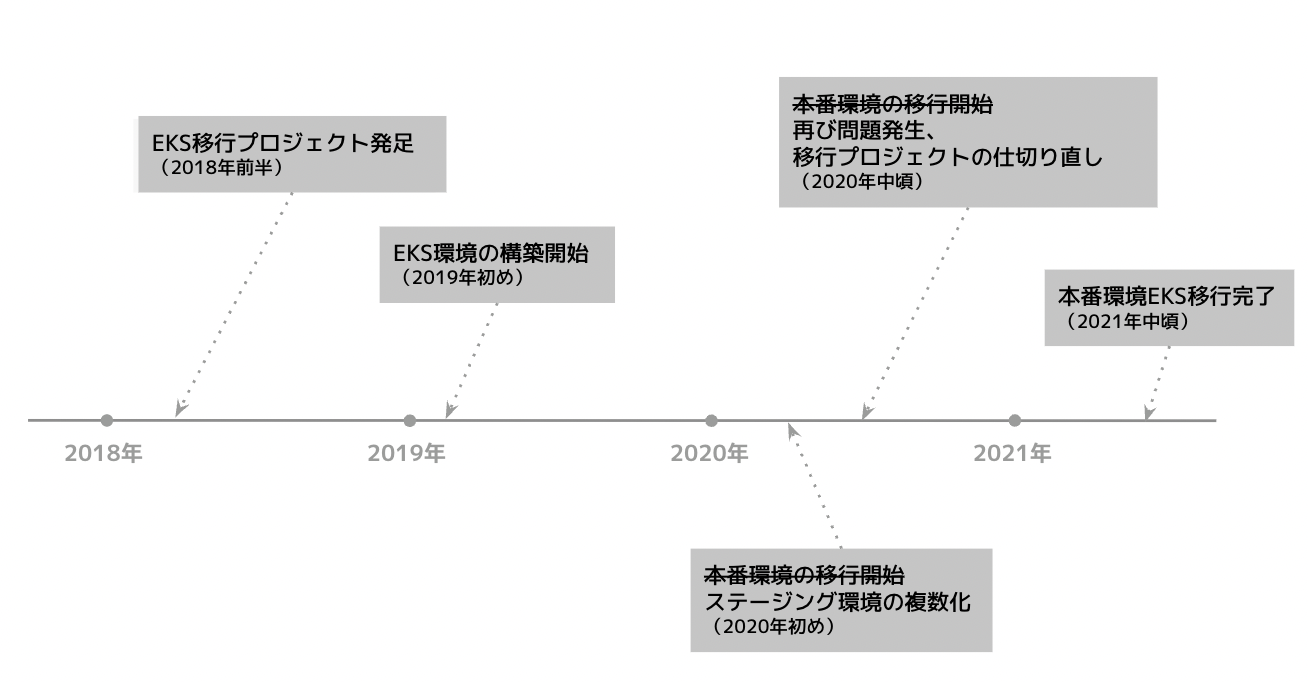
しかし、サービスや組織の拡大に伴い、AWS OpsWorksによる運用上の課題が生じてきました。そこで、2018年ごろにAWS OpsWorksからAmazon EKSに移行するという意思決定を行いました。
その後、たくさんの試行錯誤や紆余曲折、回り道を経て、2021年にAmazon EKSへの移行が完了しました。
この記事では、4年近くに渡ったEKS移行の取り組みを時系列を追って紹介していきます。
その過程には、後に取りやめることになった設計や意思決定も多く含まれています。
記事の最後でEKS移行プロジェクトを振り返り、そこから得た学びをまとめます。
AWS OpsWorksの課題とEKS移行プロジェクト
みてねでは、当初AWS OpsWorksを利用していましたが、次のような課題がありました。
- デプロイに時間がかかるため、高速なスケールアウトが困難
- Chefのバージョンアップが困難
- AWSマネジメントコンソールやSSHの利用を前提とした手動のオペレーションが多く、運用の自動化が困難
- スポットインスタンスの利用が困難
AWS OpsWorksに変わるオーケストレーションツール探し
これらの課題を解決するため、AWS OpsWorksに変わるオーケストレーションツールが求められていました。
さまざまな候補を検討し、AWSが提供するマネージドKubernetesであるAmazon EKSを採用することにしました。
この意思決定の理由については、弊社清水の 発表スライド にて詳しく説明しています。
その他、インフラに関する2つの課題
また、この時点でAWS OpsWorks以外にもインフラにおける課題が、大きく2つありました。
1つは、AWSリソースの構成管理の問題です。2018年時点で、AWSリソースの構成管理ツールとして miam や roadworker を部分的に導入していましたが、大部分のAWSリソースが管理対象外となっていました。
この状態では、通常運用におけるAWSリソースの変更を管理できないのはもちろん、Amazon EKS導入のためのさまざまなAWSリソースの作成・
そこで、Terraformなどのツールを導入し、Infrastrucutre as Code (以下、IaC) を実践していくことが必要と思われました。
もう1つの問題が、AWSアカウント構成の問題です。当時は、本番環境・
課題解決としてのEKS移行プロジェクト発足
これらの問題を一挙に解決するため、
コンテナイメージの作成と開発環境のコンテナ化
EKS移行プロジェクトが開始して一番初めに取り組んだのが、コンテナイメージの作成でした。
EKS上でみてねのサービスを稼働させるためには、コンテナイメージを作成しなければ始まりません。
まず、既存のChef CookbookをDockerfileに移植しました。併せて、Dockerイメージのビルドを自動化するパイプラインも構築しました。
GitHubに変更がプッシュされると、CodeBuildにてDockerイメージをビルドし、ECRリポジトリにプッシュする、という仕組みです。
これで、つねに最新のコンテナイメージが利用できる環境が整いました。
しかし、コンテナイメージがあっても、それを動かすための環境がまだありません。そこで、次に開発環境のコンテナ化に取り組みました。
それまでは、開発者はMySQLやFFmpegなど開発に必要なミドルウェアを各自でセットアップしていました。
これをDocker Composeで置き換え、開発者が docker-compose up を実行するだけで開発環境が立ち上がるようにしました。
これにより、開発効率が向上しただけではなく、作成したコンテナイメージがつねに利用可能な状態に保たれるようになりました。
Terraformの導入
コンテナイメージの作成と並行して最初期に取り組んだのが、AWSリソースの構成管理ツールの導入です。
ツールとしては、開発体制が安定していたこと、将来的にはAWS以外のリソースも管理していくことを考えて、Terraformを採用しました。
Terraformを導入するといっても、この時点ですでにかなりの数のAWSリソースを利用しており、そのすべてをインポートするのは大変でした。
そこで、miamやroadworkerで管理していたIAMリソース・
この時点では、すべてのAWSリソースを網羅的にインポートするよりも、Terraformの適用を自動化する仕組みを構築することが重要でした。
Terraformの適用が自動化されることで、EKS移行に必要なリソースの作成を安全かつ高速に進めることができます。
まずはCodeBuildを利用したシンプルな仕組みを構築しました。GitHubでPull Requestを作成すると terraform plan の実行結果がコメントに投稿され、その後メインブランチにマージされるとCodeBuild上で terraform apply が実行されるというものです。この仕組みを構築したことで、EKS関連のリソースの作成を効率よく進めることができるようになりました。
AWSアカウント構成の設計
次に取り組んだのが、EKS移行プロジェクトの目標の1つであるAWSアカウント分割の準備でした。
AWSアカウントの分割と一口に言っても、分割する単位にはさまざまな選択肢があります。
目的別に4つのアカウント構成に
みてねでは、本番環境
このうち、Productionアカウントは、すでに利用していたAWSアカウントをそのまま引き継ぐことになるので、残り3つのAWSアカウントを新規に作成しました。
AWSアカウントの作成・
ここから先の作業は、DevアカウントとStagingアカウントに、EKSを利用した環境を新しく構築していくことがメインとなりました。
新しい環境の構築は全てのTerraformを利用して行うため、環境構築が完了した時点ですべてのAWSリソースがコード化されTerraformの管理下に置かれている、という目論見でした。
開発環境のコンテナ化・
EKS環境の構築
いよいよ準備が整ったのでEKS環境の構築に取り掛かりました。
シングルテナント・マルチクラスタ構成を採用
初めにKubernetesクラスタを構築しなければなりません。
ここで、シングルテナント・
みてねのサーバサイドのアプリケーションは、一番メインとなるRailsアプリケーションと、DVDの作成や海外への商品発送などをそれぞれ専門で行う4つのサブシステムから成り立っています。
AWS OpsWorksを利用していたときは、これら5つのコンポーネントのそれぞれを個別のスタックで運用してきました。
今回、Amazon EKS上にこれら5つのコンポーネントをデプロイするにあたって、それぞれを別々のKubernetesクラスタで動かすか
それぞれのコンポーネントをできる限り疎結合に保ちたい、という理由で、シングルテナント・
また、それぞれのKubernetesクラスタに対して、VPCもそれぞれ独立したものを作成しています。
基本的な機能はすべてKubernetes上に
Kubernetesクラスタを作成できたら、次はみてねの基本的な機能を一通りKubernetes上で動かすことを目指しました。
この時点では、Kubernetesがみてねの要件に適合するかどうかを検証することを最優先とし、マニフェスト管理やデプロイパイプラインについて考えるのは後回しにしました。
Kustomizeなどのマニフェスト生成ツールは利用せず、シンプルにYAMLをどんどん書いていきました。
マニフェストの適用は、手動で kubectl apply を実行していました。
RDSやSQSなどのAWSリソースも、同時並行で作成していきました。
今まで手動で作成してきたAWSリソースの定義をTerraformファイルに書き起こし、新しく作成したDev/
2019年中ごろには、基本的な機能は一通りDev/
本番運用のハードル
さあ、あとは、ここまでに作成したTerraformファイルとKubernetesマニフェストをババーンッと適用したら、本番環境にKubernetesを導入できるはずです。
しかし、ここまでに作成したTerraformファイル/Kubernetesマニフェストをそのまま本番環境に適用するには、いくつかクリアすべき課題があることが見えてきました。
本番稼働前に見えた3つの課題
課題は大きく3つありました。
①Terraformファイル/Kubernetesマニフェストの管理
課題の1つ目は、Terraformファイル/Kubernetesマニフェストの管理が困難になってきていたことです。
ここまでに作成したTerraformファイル/Kubernetesマニフェストはかなりの分量になっていました。問題だったのは、QA専用のステージング環境・
この状態を解消するため、Terraformファイル/Kubernetesマニフェストの構成を考え直す必要がありました。
Terraformファイルに関しては、Workspaceという機能を利用することにしました。これは、単一のTerraformファイルを、パラメータだけ差し替えて、複数の環境に適用できるようにする機能です。これにより、各環境向けのパラメータの差分だけを管理すればよくなりました。
Kubernetesマニフェストに関しては、マニフェスト生成ツールを導入することにしました。当時は、KustomizeかHelmが主要な選択肢として挙がっていました。一度Kustomizeで書いてみましたが、各環境の差分の管理が困難だったので、Helm Chartとしてすべて書き直すことにしました。Helmを利用することで、Terraform Workspaceと同様に、単一のテンプレートを、パラメータだけ差し替えて、複数の環境に適用できるようになりました。
②デプロイパイプラインの不在
課題の2つ目は、デプロイパイプラインの不在です。
Terraformの自動デプロイの仕組みは既にありましたが、Workspaceの利用を想定したものではなかったので、Workspaceを前提とした新しい自動デプロイの仕組みを考える必要がありました。色々なツールを検討しましたが、要件に合うものが見つけられず、最終的に自動デプロイツールを自作することになりました。
Kubernetesマニフェストのデプロイに関しては、すでに広く利用されていたArgo CDを採用することにしました。
③Kubernetesクラスタのシングルテナント・マルチクラスタ構成の運用負荷
課題の3つ目は、Kubernetesクラスタのシングルテナント・
みてねでは、メインのRailsアプリケーションと4つのサブシステムから成り立っていると紹介しましたが、4つのサブシステムは実際にはかなり規模が小さく専任の開発チームがいるわけでもありません。
一方で、4つのサブシステムそれぞれに専用のKubernetesクラスタが割り当てられており、Kubernetesクラスタの管理が負担となっていました。特に、Kubernetesのアップグレードを5つのクラスタに対して行うというのは大きな手間となりそうでした。
シングルテナント・
そこで、マルチテナント・
他にもいろいろな課題がありましたが、それらを1つ1つ潰しながら、本番運用に向けた準備を整える期間が続きました。
2020年初めのころには、見えている課題は大体解決できていたように思います。
一方で、どこまで品質を高めたら本番運用に耐えられるのだろう、という手詰まり感と不安感もありました。
ステージング環境複数化という回り道
さあ、課題も一通り解決し、いよいよ本番環境の移行に取り掛かるぞ、というタイミングがやってきました。
しかし、ここでチームはある誘惑に駆られてしまいました。それが、ステージング環境の複数化です。
ここまでに
これは、開発中の段階で4つのサブシステムやすべてのAWSリソースを含めたトータルの動作確認を行うための環境です。
開発者の数が増えるに従って、この環境が開発者間で取り合いになることが増えてきていました。
その解決策として
これに少し手を加えれば、
そこで、本番環境の移行を一旦ストップし、ステージング環境の複数化に取り組むことになりました。
簡単とは言っても、
Terraformの自動デプロイツールとArgo CDをなかば無理やり組み合わせることで、これを実現することができました。
結局、ステージング環境の複数化に半年ほどを費やし、完了した頃には2020年中頃になっていました。
EKS移行プロジェクトの仕切り直し
さあ、今度こそ本当に本番環境の移行に取り掛かるタイミングです。そして、再び問題にぶつかりました。
ここまでに作成してきたTerraformファイル/Kubernetesマニフェストをそのまま適用すると、既存の本番環境とは完全に独立した新しい本番環境が生まれることになります。
既存→新本番環境への切り替え方法という壁
ここにきて、既存の本番環境から新しい本番環境への切り替え方法を考えていなかったことに気が付きました。
ロードバランサもジョブキューも4つのサブシステムも、既存の本番環境と新しい本番環境で完全に独立しています。つまり、新しい本番環境にトラフィックを流すということは、リクエストを受けるAPIサーバも、そこからトリガされる非同期ジョブやサブシステムへのリクエストも、すべてがトラブルなく処理されなければならないことを意味します。かなりハイリスクなリリースになりそうです。
新しい本番環境が正常に動作することをどうやって検証するのか、という問題もありました。QAを実施したとしても、スケールアウト性能などの非機能要件については検証が困難です。とくにオートスケーリングのチューニングは、本番環境と同等のトラフィックやアクセスパターンの下で実施しないと難しい部分があります。
そのあたりを頑張ってチューニングしている間に、既存の本番環境には次々に新しい機能が実装されていくことでしょう。
新しい本番環境はその変更を追いかけ続けなくてはなりません。これでは、いつまで経っても新環境の検証は終わりそうにありません。
2年かけた新構成をリセットする決断
本番環境の移行を目前にして、既存の環境とは独立した新しい環境を作成する、というここまでの方針が大きく覆されることになりました。
Terraformファイル/Kubernetesマニフェスト、AWSアカウント分割の設計や新規に作成した諸々のAWSリソース、ステージング環境複数化の機能、などなど2年近くかけて構築してきた成果物の多くを一度リセットすることになったのです。
対象範囲を狭めながらの本番環境のEKS移行
本番環境の移行手順を考え直すにあたって、EKSへの移行対象をできる限り小さく絞り、リリースのリスクを抑えることが重要であるという認識がありました。
最初の移行は社内向け管理ツール
最初の移行対象として、比較的重要度が低くエラー時のリカバリが容易なコンポーネントという観点で、4つのサブシステムのうちの1つに含まれる社内向けの管理ツールを選びました。
この管理ツールをKubernetes上にデプロイし、OpsWorksで稼働中のインスタンスを停止する、というのが最初の目標になりました。
このアプローチでは、既存のOpsWorksのシステムを少しずつ少しずつEKSに置き換えていくことになります。したがって、AWSアカウントの分割やTerraformの全面的な導入は、自動的にスコープから外れました。
既存のAWSリソースにはほとんど手を加えず、Kubernetes上で1つのPodを稼働させるために必要な最小限のAWSリソースのみを新規に作成することになりました。
最初のリリースはとくに問題なく成功しました。
小さなリリースでしたが、本番環境でEKSが稼働しているというのは、何かとても大きな成果であるように感じられました。たとえ小さなコンポーネントでも、一度OpsWorksからEKSへの移行を経験してしまうと、次のステップの心理的・
すでに用意していた全Kubernetesマニフェストでスムーズに移行が進む
管理ツールの次は、定期実行されるバッチジョブ、その次は非同期ジョブワーカ、その次はさらに別のサブシステム、というように、EKSへの移行がどんどんと進み始めました。
一度すべてのKubernetesマニフェストの作成が完了していた、というのも移行作業をスムーズに進めることができた大きな要因でした。
段階的にEKSに移行していく過程で、Kubernetesの本番運用に関する知見がどんどん蓄積されていきました。
オートスケーリングのチューニングや、Podに割り当てるリソース量の調整、インスタンスタイプの選定やスポットインスタンスの活用などなど、本番環境で運用しなければ得られない知見を段階的に獲得することができました。
Kubernetesで稼働中のコンポーネントがまだ少ない段階で、Kubernetesのアップグレードを経験できたのもとても良かったです。
結果として、チーム内のKubernetesの知見の共有が進む
また、チーム内の全メンバーにKubernetesの知見を共有できたのもこの時期でした。
もともとEKS移行プロジェクトには固定のメンバーがずっとアサインされていました。Kubernetesの知見を一部のメンバーに集約しプロジェクトの進捗を最大化すること、EKS移行以外のタスクも並行して進めること、などが狙いでした。
しかし、Kubernetesの本番運用を開始するにあたっては、すべてのメンバーにこれまでの知見を共有することが重要です。
OpsWorksからEKSへの移行作業をチームの全員で手分けして経験することで、スムーズに知見を共有することができました。
2021年中旬にEKS移行プロジェクトが完了
そして、2021年前半には、すべてのコンポーネントをEKSに移行し、遂にOpsWorksのインスタンスをすべて停止することができました。
この後さらに、一度スコープから外していた、AWSアカウントの分割やTerraformの全面的な導入に取り組みました。
本番環境で利用しているAWSリソースをすべてTerraformの管理下に取り込み、そうして作成したTerraformファイルを、ステージング環境用に作成したAWSアカウントに適用することで、AWSアカウントの分割とTerraformの全面的な導入を同時に達成することができました。
EKSへの移行が完了していたため、この作業はとてもシンプルなものでした。
そうして、2021年中ごろには
振り返って~「小さくリリースすること」「高速にトライアンドエラーできる仕組み」の重要性
こうして振り返ると、なかなかに苦難の道のりでした。
Terraformファイル/Kubernetesマニフェストの全面的な書き直しは3回ほど行いました。EKSクラスタを含む諸々のAWSリソースを何度も作り直しました。ステージング環境複数化の機能に至っては、本番環境移行に向けて仕切り直すため、ほとんど利用される間もなく削除されることになりました。
私たちは、このEKS移行プロジェクトをどのように進めるべきだったのでしょうか。
今振り返って思うのは、
小さくリリースするというのは、アジャイルにおける最も基本的な考え方だと思いますが、Kubernetesという未知の技術を前にしてなかなかその判断ができませんでした。
しかし、どんなに小さなコンポーネントであっても、本番環境で運用することで得られる知見と自信は、ステージング環境のそれとはまったく違うものでした。未知の技術に対してこそ、どれだけ小さくリリースできるかが重要であるということを痛感しました。
一方で、プロジェクトの比較的早い段階で、Terraformの自動デプロイツールやArgo CDを導入し、
すべての作業がコード化されていたことも、とても重要でした。
何度かインフラの全面的な作り直しを行いましたが、決して過去の作業が無駄になることはありませんでした。
過去のTerraformファイル/Kubernetesマニフェストが履歴に残っていたことで、作り直しの作業は1回目よりもずっと簡単に行うことができました。
今回のEKS移行プロジェクトを通じて
この記事を読んでくださった方にも何かヒントになるものがあれば幸いです。