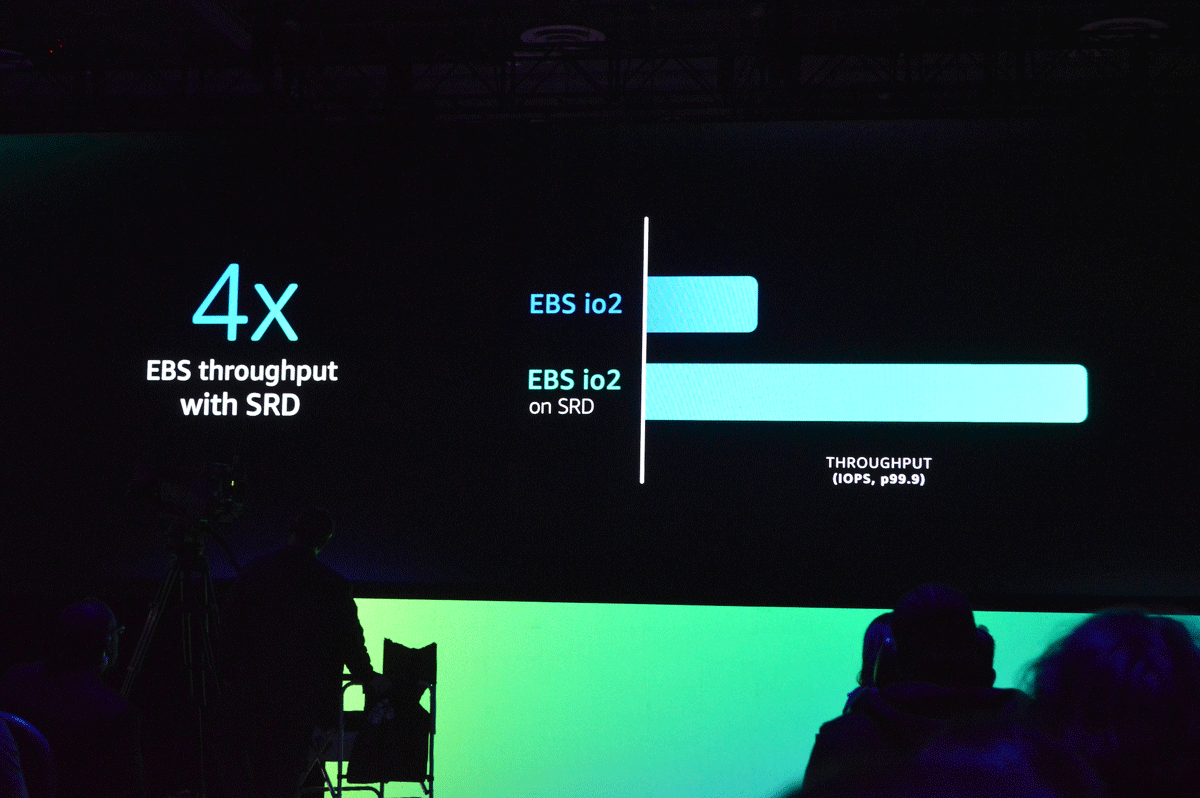11月28日(米国時間)から12月2日までの5日間、米ラスベガスで開催されたAWSのグローバル年次カンファレンス「AWS re:Invent 2022」には、全世界から5万人を超えるAWSユーザ/開発者が参加し、数多くの新サービスや最新事例が発表されました。筆者も3年ぶりに現地で取材する機会を得たのですが、パンデミック前のre:Inventが完全に帰ってきたと実感しています。
一方で、新型コロナウイルスの感染拡大は世界のオンライン化を加速し、その基盤となるクラウドインフラは明らかに3年前よりも重要な存在となっています。そのクラウドのトップベンダであるAWSは、インフラとしてどう進化しているのか ―本稿では11月28日に行われたAWS ユーティリティコンピューティング部門 シニアバイスプレジデント ピーター・デサンティス(Peter DeSantis)氏のキーノートの内容をもとに、AWSインフラの進化の方向性について概観したいと思います。
「AWS re:Invent 2022」キーノートに登壇したAWS ユーティリティコンピューティング部門 シニアバイスプレジデント ピーター・デサンティス氏
AWSにパフォーマンス向上をもたらすキーテクノロジーは何か?
ここ数年のre:Inventでは、カンファレンス初日の夜にデサンティス氏がオープニングキーノートのプレゼンターとして登壇し、AWSが提供するサービスの基盤となるインフラ関連のアップデートを発表するのが恒例となっています。現在、AWSインフラは以下の6つの分野にフォーカスして継続的に進化しています。
エラスティシティ(弾力性)
セキュリティ
パフォーマンス
コスト
パフォーマンス(可用性)
サステナビリティ
これらの中からデサンティス氏が今回のキーノートの中心テーマとして選んだのはパフォーマンスです。
AWSインフラがフォーカスする6つの分野。今回はパフォーマンスがテーマ
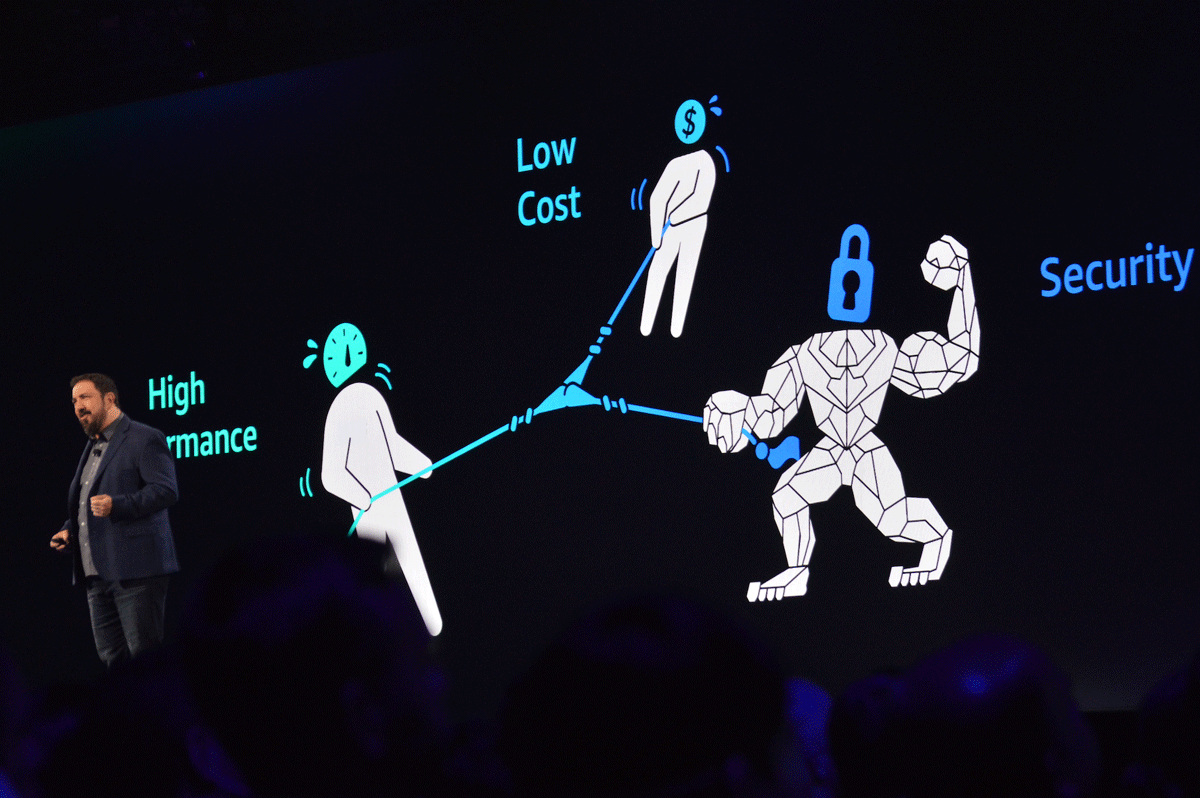
セキュリティやコストとトレードオフになりがちなパフォーマンスを、トレードオフさせることなくどう向上させていくのか ―デサンティス氏はAWSクラウドのパフォーマンス向上が具現化した分野として次の5つについて紹介を行いました。
Nitro
Graviton
SRD
マシンラーニング
AWS Lambda
以下、順に紹介していきます。
パフォーマンスをコストやセキュリティをトレードオフさせることなく向上させていくことがAWSインフラのミッション
AWS Nitro v5 ―第5世代のNitroチップ
2017年11月のre:Inventで発表された「AWS Nitro」は、2015年12月にAmazonが買収したイスラエルのチップメーカー Annapurna Labsの技術をベースに、AWS自身が継続的に開発するカスタムチップです。Nitroはクラウドコンピューティングのボトルネックともいえる仮想化にかかる負荷を「Nitro Card」という専用のコンポーネントにオフロードすることでハイパーバイザ(Nitro Hypervisor)を軽量化し、ネットワーキングやストレージアクセスのパフォーマンスを向上させる設計となっています。ハイパーバイザが軽量であるため、ユーザはリソースをハイパーバイザに多くのリソースを割く必要がなく、ベアメタルと同等のレベルでリソースの性能を引き出すことが可能になります。
セキュリティの向上やネットワーク/ストレージのパフォーマンス改善、ベアメタルのサポートなど、Nitroがインスタンスにもたらすメリットは数多くある
今回、デサンティス氏はNitroの第5世代となる「AWS Nitro v5」の一般提供開始(GA)を発表、パフォーマンスが大幅に改善したことを強調していました。前世代(第4世代)と比較したおもな特徴は以下になります。
前世代と比較して2倍のトランジスタ数、2倍の計算能力、DRAMアクセス速度50%増
PCI Experess帯域幅が2倍(100Gbps→200Gbps)
PPS(Packet-per-Second)性能が60%向上
レイテンシを30%短縮
帯域幅あたりの電力消費量を40%削減
前世代に比べてパフォーマンスが大幅にアップしたAWS Nitro v5がGAに
これを見るとわかるように、チップとしてのパフォーマンスが大幅に向上していることがわかります。AWSはこの進化したNitroのパフォーマンスをユーザに体感してもらうべく、Nitro v5の登場にあわせ、Nitro v5と「Graviton 3E」( 後述)を搭載したEC2インスタンス「Amazon EC2 C7gn」を発表しました。最大で64vCPUとメモリ128GBが利用可能で、Nitro v5が新たに獲得したネットワーク帯域幅とパケット処理能力による恩恵をそのまま受け取ることができます。
Nitro v5を搭載した新しいインスタンス「Amazon EC2 C7gn」が発表、最大64vCPUとメモリ128GBが利用可能、加えて最大200Gbpsのネットワーク帯域と50%高いパケット処理性能を発揮。発表と同時にプレビューの申込みが開始している
AWSジャパン 技術統括本部 技術推進本部 本部長 小林正人氏によれば、C7gnは「ネットワーク仮想アプライアンス、データ分析、密結合なクラスタコンピューティングなど、ネットワークの要求がきびしいワークロードに適している」とのことで、まさに次世代のネットワーク最適化インスタンスといえるでしょう。現時点でのC7gnは11月28日からプレビューの申し込み受け付けを開始したところなので、一般提供までにはまだ少し時間がかかるようですが、第1世代から継続的な進化を続けているNitroが、そのイノベーションのペースを落とすことなくパフォーマンス改善を図っていることを示した発表だといえます。
Graviton3E ―HPCワークロードに最高のコストパフォーマンスを提供するARMベースのプロセッサ
Nitroと並んでAWSがカスタム開発するもうひとつのチップ「AWS Graviton」は、EC2インスタンス上で実行されるクラウドワークロードに” 最高のコストパフォーマンス” を提供するべく、64ビットARMをベースに設計されています。2018年11月のre:Inventで第1世代がローンチされ、2019年12月に「Graviton2」が、そして2021年11月には第3世代となる「Graviton3」とこれを搭載した「Amazon EC2 C7g」インスタンスがプレビューとして発表されました。Graviton3およびC7gインスタンスは2022年5月にすでに一般提供が開始されており、アプリケーションサーバ、マイクロサービス、ゲーム、動画エンコーディング、HPC(ハイパフォーマンスコンピューティング)などさまざまな分野で適用されています。
このように、Nitroと同様に継続的な進化を続けているGravitonですが、今回のre:Invent 2022でデサンティス氏が発表したのはGraviton3の派生型となる「Graviton3E」プロセッサです。これはHPCワークロードで必要となる浮動小数点演算とベクトル演算のパフォーマンスに最適化されたチップで、気象予報や遺伝子工学、金融工学、生産工学といった分野で大幅なパフォーマンス向上が実現するとされています。
Graviton3とGraviton3Eのパフォーマンス比較。線形代数処理のベンチマークであるHPLで35%、分子動力学シミュレーションのGROMACSで12%、金融オプションの価格決定ワークロードで30%の性能向上が実現する
Graviton3Eのアナウンスと同時に、デサンティス氏はGraviton3Eを搭載したHPC向けインスタンス「Amazon EC2 HPC7g」も発表しました。このインスタンスに関する追加情報は2023年の早い時期に提供される予定ですが、すでにいくつかのユーザ企業がアーリーアダプタとしてHPC7gを導入しており、Graviton3Eがもたらす高い演算処理能やコストパフォーマンスをHPCコンピューティングで実感しているとコメントしています。AWSはHPCに最適化されたインスタンスとして「HPC6a」を2022年1月に提供済みですが、今回のre:InventではHPC7gのアナウンスとともにデータ&メモリインテンシブな「HPC6id」インスタンスもGAとなりました。
Graviton3Eを搭載した新インスタンス「HPC7g」は同じVPC内のインスタンス間のトラフィックに最適化された、独立した200GbpsのEFAネットワーク帯域を備え、最大64vCPUと128GBのメモリを利用可能。HPCや分散コンピューティングでもっとも高いコストパフォーマンスが期待できる。現時点ではアナウンスのみで、2023年はじめに追加情報が提供予定
クラウド上で"スケールするコストパフォーマンスの高いHPC"を実現することは、AWSが10年以上前から力を入れてきた分野であり、とくにインフラ部門のトップであるデサンティス氏にとっては非常に思い入れの強いテーマでもあります。単なるHPC向けインスタンスから、より個々のワークロードに最適化された” purpose-built” なHPCインフラへと進化させているAWSの姿勢がうかがえます。
SRD ―AWSクラウドに最適化された低レイテンシと高スループットを実現するネットワークプロトコル
AWSのインフラを世界でもっともよく知る立場にあるデサンティス氏のキーノートは例年、「 AWSの中はこんなことになっていたのか!」と驚かされる発表がいくつかあります。その意味でいえば、今回デサンティス氏が明らかにしたAWS独自の通信プロトコル「SRD(Scalable Reliable Datagram) 」は多くのユーザ/開発者にとって非常に新鮮な響きをもつテクノロジだったのではないでしょうか。
デサンティス氏が明らかにしたAWSのデータセンター内で動いているネットワークプロトコル「SRD」。AWSクラウドを前提に、低レイテンシと高スループットを実現するように設計されている
SRDをひとことで説明すれば「AWSクラウドの環境に最適化することで安定性と低レイテンシを実現するネットワークプロトコル」( 小林氏)となります。もう少し具体的に言うと、AWSのモダンでマルチテナントなデータセンターネットワークのメリットを最大限に活かせるように設計されたプロトコルで、大量のネットワークパスを並列にカバーしながら、フローの衝突や一貫性のないレイテンシを防ぎ、低レイテンシと高スループットを同時に実現することが可能となっています。「 AWSのデータセンターのトポロジはトラディショナルなデータセンターのそれとはまったく異なる。マルチパスをカバーし、マイクロ秒でのリトライが可能で、かつ、( AWSのカスタムチップである)Nitro上で動作する、それがSRDだ」( デサンティス氏)
トラディショナルなネットワークのトポロジ
マルチパスをカバーするAWSデータセンター内のトポロジ
実はSRDというキーワードがre:Inventのキーノートで登場したのは今回がおそらく最初ですが、SRD自体はすでにAWSのサービスで実装されており、それが2018年のre:Inventでデサンティス氏が発表したネットワークインタフェース「EFA(Elastic Fabric Adapter) 」です。AWSは2016年に特定のEC2インスタンスにアタッチすることで、インスタンスのネットワーキング機能を大幅に拡張する「ENA(Elastic Network Adapter) 」をリリースしましたが、EFAはこれにSRDを実装することでカーネルバイパス機能とRDMAを追加、さらにNitroに直接ネットワーキング機能をオフロード可能にしており、並列分散処理におけるノード間の通信を大幅に向上します。ちなみにEFAはHPCや機械学習アプリケーションのワークロードを高速にスケールさせることをターゲットにしています。先にも書きましたが、昨今のAWSインフラはHPC/マシンラーニング界隈から寄せられるスケールやリアルタイムへの強いニーズによって進化が後押しされている傾向にあるといえます。
2018年に発表されたネットワークインタフェース「EFA」ではすでにSRDが実装されていた
このようにAWSの内部で深く静かに進化してきたSRDですが、今回のre:Inventでの初登場にともない、デサンティス氏はSRDに関連する2つのアナウンスを行っています。ひとつは「2023年の早い段階で、すべてのAmazon EBS io2ボリュームをSRDベースにする」というもの、もうひとつはHPCなどに用途を限定せず、一般的なワークロードでSRDのメリットを体感できるインタフェース「ENA Express」の一般提供開始です。インスタンスにネットワーク接続されるストレージと、インスタンスにアタッチしてネットワーク機能を拡張するインタフェース、それぞれにSRDというAWSならではの強力なプロトコルがサポートされることで、より幅広いワークロードで低レイテンシ&高スループットの実現が期待できそうです。
AWSはSRDを適用するリソースを拡大していくことを表明しており、そのひとつがEC2インスタンスにアタッチされるEBS io2ボリュームを2023年内にすべてSRDベースにするというもの。これにより書き込み時のレイテンシが最大90%改善され、スル-プットが4倍向上するといわれている
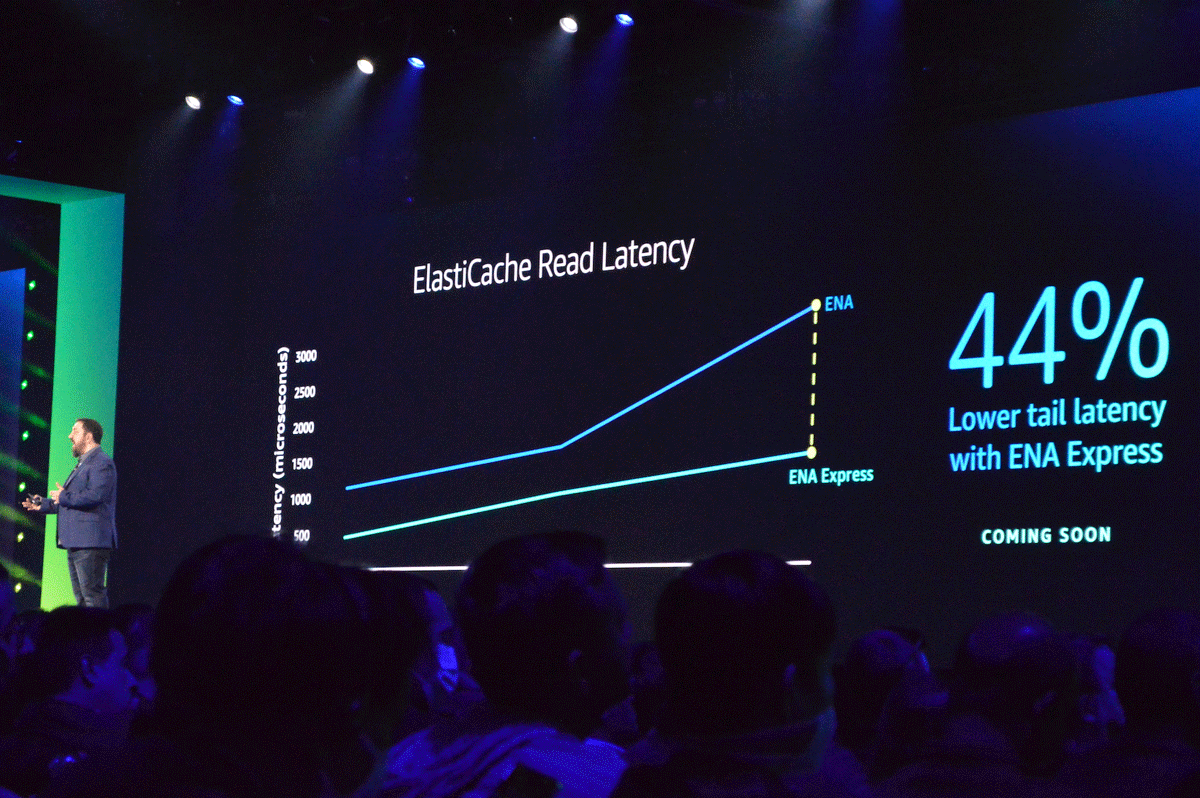
SRDをネットワークインタフェースに適用した「ENA Express」を使うことで、TCPと比較してトラフィックのレイテンシを大幅に改善することが可能に
ENA Expressにより、ひとつのストリームで最大5Gbpsから25Gbpsのスループットが実現
マシンラーニング ―大規模並列環境における潜在的なボトルネックを取り除く
前述したように、HPCと並んでインフラに大きな負荷がかかるワークロードがマシンラーニングの世界です。デサンティス氏は「カスタマイズされたハードウェアを実装したコンピュート環境、メモリをたくさん積んだいくつものインスタンス、並列にトレーニングできる複数のインスタンス、さらに低レイテンシなネットワーク - マシンラーニングのトレーニングがインフラに要求する内容は独特で、インフラへの負荷が高い」とコメントしており、AWSはマシンラーニングユーザの” 無茶振り” に応え続けるように新しいインスタンスを提供してきました。
その象徴ともいえる存在が2021年のre:Inventで発表された「Amazon EC2 Trn1」インスタンスです。AWSがマシンラーニングのトレーニングのために開発したカスタムチップ「AWS Tranium」を16個搭載し、512GBのメモリと800Gbpsのネットワーク帯域という、非常に高いスペックのインスタンスで、デサンティス氏は「もっともコスト効率が高く、ハイパフォーマンスな、クラウドでのディープラーニングトレーニングに最適化されたインスタンス」と強調しています。すこし大げさにいえば、オンプレミスで利用していたスパコン並みの性能がクラウド上から比較的安価なコストで利用可能になったイメージでしょうか。
2021年のre:Inventで発表された「Trn1」インスタンスはその名前の通り、マシンラーニングのトレーニングに特化したインスタンス。スパコン並みのスペックをクラウドから安価に利用できることも話題になった
そしてこのTrn1インスタンスにおけるネットワーク通信のパフォーマンスを引き上げたインスタンスとして、今回「Amazon EC2 Trn1n」インスタンスが発表されました。このインスタンスは前述したEFAによるネットワーク最適化機能を備えており、最大で1.6Tbpsの低レイテンシを提供、並列分散環境での超巨大モデルのトレーニングにおいてボトルネックになりやすいノード間通信の性能を大幅に高めることが期待されています。Trn1nインスタンスに関しては現時点ではアナウンスのみですが、AWSによれば「近日中に情報法を共有予定」とのことなので、プレビューなどによる提供も近いと思われます。
Trn1をEFAによってネットワーキング最適化させた「Trn1n」インスタンスがアナウンス(詳細は近日発表予定)、ディープラーニングにおけるトレーニングがさらに高性能かつ低コストで行えるようになる
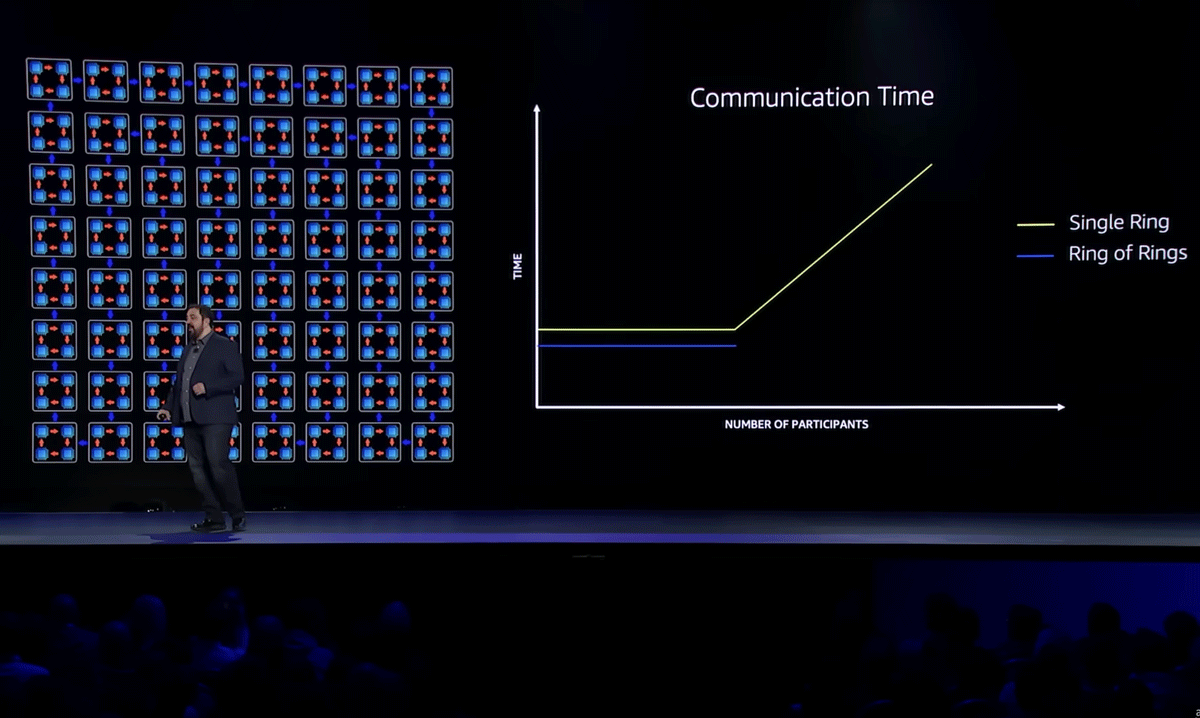
なお、デサンティス氏は大規模並列環境におけるモデルトレーニングのパフォーマンスを高めるアーキテクチャとして「A Ring of Rings」というアプローチを紹介しています。これは"Ring"と呼ばれるクラスタ内で各プロセッサがそれぞれモデルを反復(イテレーション)したあとに別のプロセッサと効率的に情報を交換するアルゴリズムで、いくつものRingを並列的に稼働させることでプロセッサの同期を75%向上させることが可能になります。すでにPyTorchで利用可能となっており、今後の適用の拡大が期待されるところです。
「Ring」と呼ぶ特定のアルゴリズムに則ったクラスタをスケールさせていく(Ring of Rings)と、ある時点(デサンティス氏は128がターニングポイントとしていた)での単一のリングとパフォーマンスに大きく差が開き出したという
PyTorch上でRings of Ringを実装したことで同期のスピードが最大75%向上したという結果も
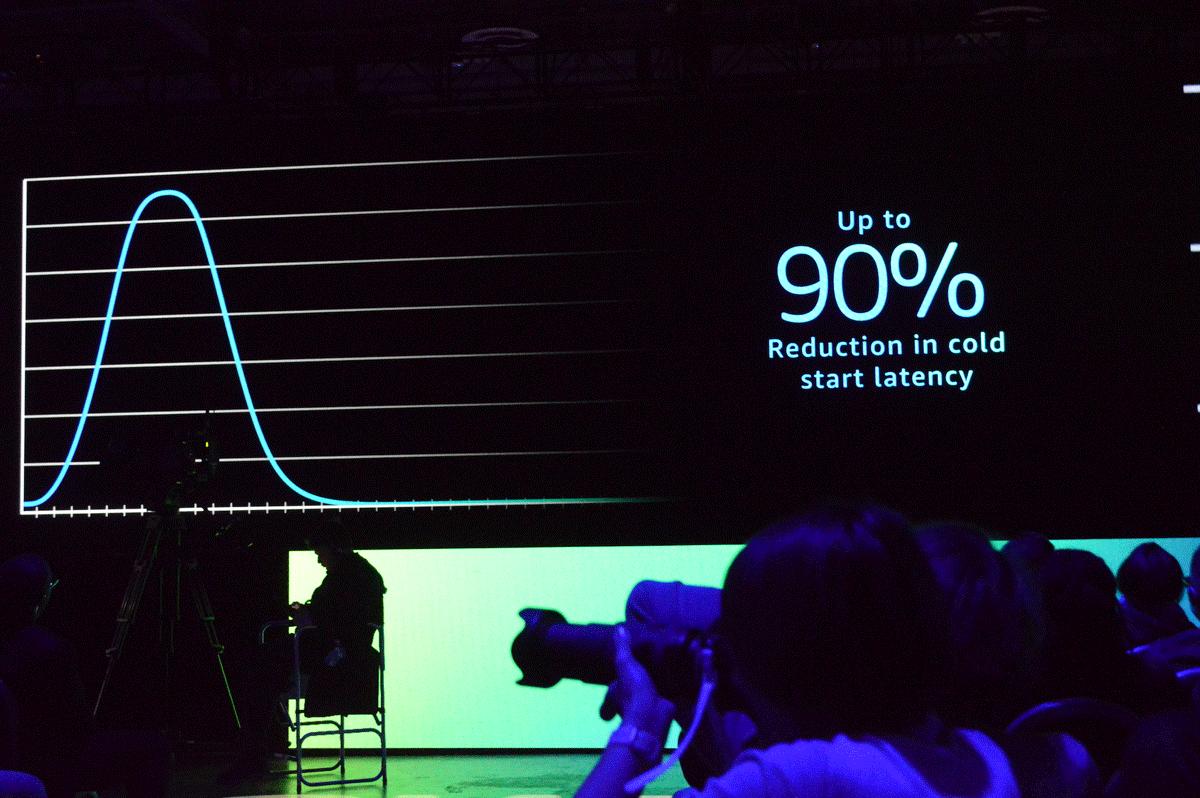
AWS Lambda ―サーバレスのコールドスタートをスナップショットで劇的に改善
今回のデサンティス氏のキーノートの中で、開発者にとってもっともエキサイティングだったといえる発表が最後に行われた「AWS Lambda SnapStart」だったかもしれません。AWS Lambdaのコールドスタート問題は多くの開発者にとって悩みのタネで、過去、さまざままな解決方法がAWSやパートナー企業から提案されてきましたが、今回のSnapStartはとくにコールドスタートの負荷が高いとされるJava 11ランタイム(Corretto)に特化し、追加費用なしでLambdaファンクションのレイテンシ(待ち時間)を90%削減しています。発表と同時に一般提供が開始されており、東京リージョンを含む多くのリージョンですでに利用可能となっています。
アナウンスと同時に開発者から歓声があがった、JavaランタイムにおけるAWS Lambdaのコールドスタートの待ち時間を大幅に改善する「AWS Lambda SnapStart」
SnapStartを有効にすることにより、コールドスタートにおけるレイテンシが最大で90%削減可能に
この劇的なレイテンシ低減を実現させたのは、AWSのサーバレスコンピューティングを支えるKVMベースの仮想化技術「Firecracker」のスナップショット機能の改善です。Firecrackerはサーバレスに特化しているため、機能が限定されている分、非常に軽量で、高いパフォーマンスでマイクロVMを立ち上げることが可能です(Lambdaには2018年から実装) 。SnapStartでは、実行環境(メモリやディスク)の初期化(init)が終わった時点でFirecrackerのスナップショットを作成して保存/暗号化しておき、Lambdaファンクション実行時にスナップショットから実行環境を復元することで処理時間の90%削減を実現させています。
AWS Lambda SnapStartをJava 11に特化してサポートしたことについて小林氏は「Javaはとくにランタイム初期化に時間がかかる傾向があり、コールドスタート改善のリクエストを多くの顧客からもらっていた。Javaはフレームワークが大きく、また既存の資産を有効に使いたいという声が大きいことから今回のサポートに至った」とコメントしています。顧客のリクエストによってのみ技術を進化させていくというAWSのイノベーションの方針が見えるアップデートともいえるでしょう。
この発表で押さえておきたいもうひとつのポイントが、Lambdaの機能改善がインフラ担当トップのデサンティス氏のキーノートで発表されたという点です。AWSはここ数年、既存サービスも含めたポートフォリオのサーバレス化を積極的に推進していますが、サーバレスはもはやAWSにとってもっとも重要なインフラ基盤であることをあらためて示した印象を受けました。
デサンティス氏のキーノートで発表された内容も含め、今回のAWS re:Inventでは「Amazon Omics」( ゲノミクス専用の保存/クエリ/分析サービス)などいくつか大きな新サービスがアナウンスされましたが、ポートフォリオを拡張するというよりも、ひとつひとつのサービスを” Deep Dive” していく傾向が強かったように見えます。とくにデサンティス氏のアナウンスを振り返ってみると、GravitonやNitroの継続的なイノベーション、HPCやマシンラーニングの厳しい要求とともに進化するインフラ、サーバレスの拡充などはまさにインフラの” 深化” という表現がふさわしいように思えます。
そしてAWSの” 進化と深化” を根底から支えているのが顧客からのリクエストです。今回のre:InventでインタビューしたあるAWSのエグゼクティブは「我々は技術トレンドを追ったイノベーションは行わない。我々が追うのは顧客のリクエストのみだ」とコメントしていましたが、デサンティス氏がキーノートで示したパフォーマンスへの驚異的ともいえる追求の数々も顧客からの強いリクエストのみに従っているものであり、だからこそAWSインフラの発表内容には毎年、新鮮な驚きを覚えます。テクノロジ業界の常識やトレンドにとらわれることなく、” re” Inventを重ねるAWSのインフラが来年以降もどう進化&深化していくのか、引き続き注目して見ていきたいと思います。
セキュリティもコスト削減もトレードオフにしないパフォーマンス改善を続けていくのがAWSインフラの”進化と深化”