Google Cloudは3月30日(米国時間) 、同社が主催したオンラインカンファレンス「Google Data Cloud & AI Summit」においてデータプラットフォーム「Google BigQuery」の新しい料金体系「BigQuery Editions」をリリースしました。また同時に、PostgreSQL互換のクラウドネイティブデータベース「AlloyDB」の一般提供開始(GA)と、ダウンロード可能なデータベースエンジン「AlloyDB Omni」のテクノロジプレビューも発表しています。
本稿ではグーグル・クラウド・ジャパン合同会社 ソリューション&テクノロジー部門 技術部長(DB, Analytics & ML)である寳野雄太氏が報道関係者向けに行った説明をもとに、今回のアップデートの概要を紹介します。
図 報道関係者向けにオンラインで説明を行う寳野雄太氏
複数のエディションを混在、使い分けが可能
説明会の冒頭で寶野氏は、Google Cloudがデータ/アナリティクスプラットフォームでめざすテーマとして以下の3つを挙げています。
柔軟性
プライバシーセーフなデータ共有
ビジネス価値を加速
今回発表されたBigQueryの新しい価格体系「BigQuery Editions」は、この最初のテーマである” 柔軟性” に徹底的にフォーカスし、ユーザのワークロードのニーズに応じた機能とSLAを適切な価格で提供し、より低いTCOでデータクラウドを実現できるように設定されています。BigQueryの価格は「コンピュート」と「ストレージ」に分かれていますが、今回のアップデートではその両方に大きな変更が行われています。
まず新しい価格体系であるBigQuery Editionsですが、今回の発表により
Standard Edition …標準的なSQL分析のための低コストオプション、99.9% SLA、スロット1時間あたり0.04ドル
Enterprise Edition …高度なエンタープライズアナリティクスをサポート、99.99% SLA、スロット1時間あたり0.06ドル
Enterprise Plus …ミッションクリティカルなエンタープライズアナリティクスをサポート、99.99% SLA、リージョンレベルの災害復旧、スロット1時間あたり0.10ドル
という3つのエディションがBigQueryユーザに対して用意されることになりました。
最大の特徴はワークロードごとに選択が可能 な点で、たとえばアドホックな分析や日常的な開発業務、テストなどにはStandardを、機械学習や高度なセキュリティやガバナンスが求められるワークロードにはEnterpriseを、高可用性やリカバリが求められるミッションクリティカルなワークロードにはEnterprise Plusを、といった使い分けが可能で、複数のエディションを組織内に混在させることもできます。また、EnterpriseおよびEnterprise Plusでは1年/3年の確約利用も可能となっており、より大きなコストの圧縮が可能になります。
オートスケーリングと圧縮ストレージ
複数のエディションの適用というメニューの多様化に加え、BigQuery Editionsではユーザのコスト最適化とコスト制御に大きく貢献するための新機能として「オートスケーリング(Autoscaling) 」と「圧縮ストレージ(Compressed Storage) 」が利用可能になりました。
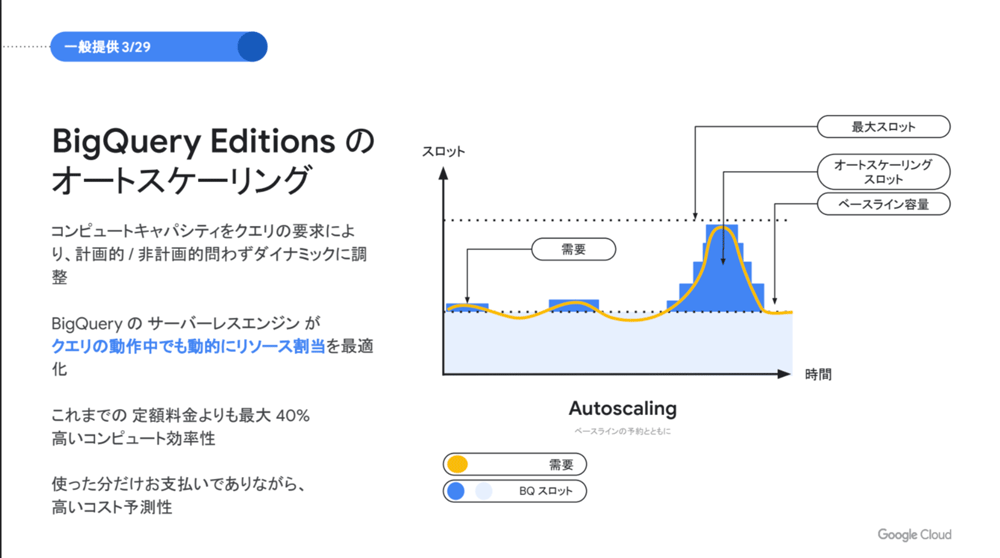
3月29日から一般提供が開始されたオートスケーリングはコンピュート(スロット)のキャパシティを自動で調整できる機能です。ユーザはあらかじめ最大スロットの値(上限値)とベースラインを設定しておけば、BigQueryのサーバレスエンジンがクエリの要求に応じて動的にリソースを割り当ててくれるので、これまでよりもきめ細かなスケーリングが可能になり、料金も利用したスロット分だけを支払うことができます(使用しないスロット分は支払う必要がない) 。
寶野氏はBigQueryのオートスケーリングについて「一般的なデータウェアハウスと異なり、BigQueryはサーバレスなのでクエリの実行中であってもオートスケールが可能」とその優位性を強調していますが、スロットの最大値を設定できることによる高いコスト予測性もメリットのひとつであるといえます。限られた予算のなかで「これまでの定額料金よりも最大40%高いコンピュート効率」( 寶野氏)でクエリの最適化を実現できるオートスケーリングは、より多くのBigQueryユーザ、とくに「ピークの時間だけスケーリングしたい、できればお得に」という予算とスケールのトレードオフに悩むユーザのニーズを捉える機能として注目されそうです。
ストレージ側のアップデートである圧縮ストレージは、データの増加に伴うストレージコストの増加を抑制できる機能です。BigQueryのストレージはこれまで論理的なデータサイズをもとに課金が行われていましたが、今回のアップデートにより、ストレージに保存される際の圧縮されたデータサイズをもとに課金されることになりました。圧縮にあたってはGoogleが10年以上に渡って開発してきたさまざまなストレージ最適化テクノロジ(カラム圧縮、自動データソート、コンパクション、クラスタリングなど)が使われており、非常に高い圧縮率を実現することで、構造化データ/非構造化データ/半構造化データなどさまざまなデータの増加をサポートしつつ、ストレージコストをより低く保ち続けることを可能にしています。
寶野氏は顧客事例としてセキュリティ企業のExabeamがBigQueryの圧縮ストレージ機能を利用したことで1/12の圧縮率を実現したケースを紹介していました。
その他のBigQueryのおもな改良点
今回のカンファレンスでは、ほかにもいくつかのアナリティクス関連のアップデートが発表されています。以下、簡単に紹介します。
BigQuery Data Clean Room
社内外のさまざまな組織/関係者との間で、BigQueryデータをセキュアに共有するためのサービスで、2023年第3四半期に提供予定。ファーストパーティデータと外部データを統合しつつ、データの持ち出しの禁止、生データを共有せずクエリの集約結果のみを返すなど、プライバシーやセキュリティに配慮したデータ共有を実現する。ユースケースとしては、マーケティングキャンペーンデータや金融機関の顧客データ、医療関係者と製薬業者が共有するヘルスケアデータなどで、センシティブなデータセットをセキュアに共有/分析することを可能にする。
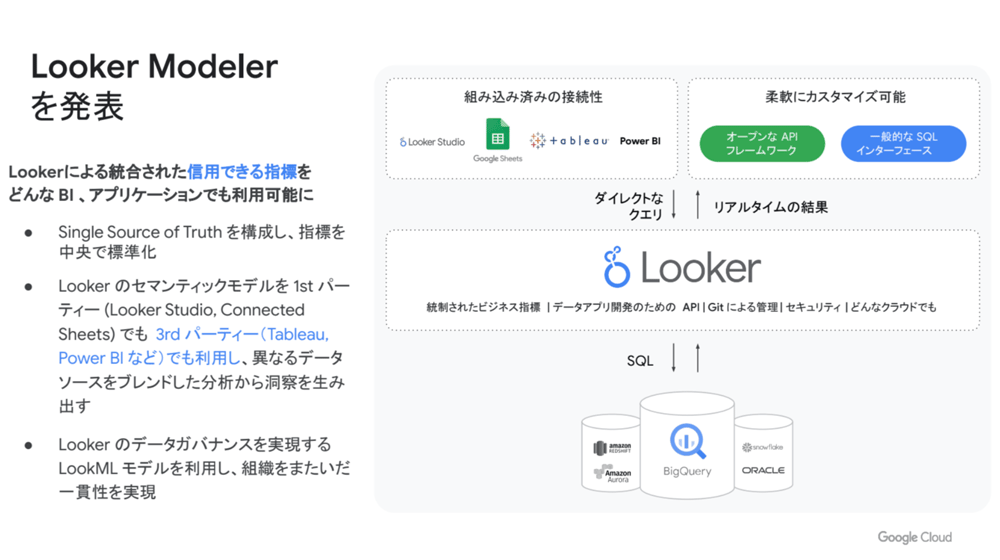
Looker Modeler
Lookerのセマンティクスモデルレイヤを使用して、ビジネスにおける” Single Source of Truth(信頼できる唯一の情報源)” を作成するための指標レイヤ。Looker Studioのほか、TableauやPowerBIなどLooker以外のBIツール、Googleアプリケーションなどさまざまなデータソースをブレンドして分析し、最新の情報にもとづいたインサイトを提供する。その他のサードパーティデータとの統合も、APIやSQLインタフェースを通して可能。「 Lookerを単なるBIツールではなく、すぐれたBIフレームワークとして位置づけ、Single Source of Trustとすることで、多様なデータソースを扱いながら、組織をまたいだ一貫性とデータガバナンスが實現」
BigQuery Inference Engine
SQLだけで機械学習が行える「BigQuery ML」でトレーニングしたモデルのほか、TensorFlowやXGBootからインポートしたカスタムモデル、Vertex AIのリモートモデル、Cloud AIモデル(Vision、NLP、Translateなど)などに対して、BigQuery内でMLの推論を実行できる。ネイティブの関数(ML_PREDICT / ML_ANNOTATE_IMAGE/ ML_TRANSLATE / ML_UNDERSTAND_TEXT)を使ってすぐにSQLで活用可能。BigQuery上で画像の予測や翻訳も可能になり、データを迅速にインサイトに変えることに貢献。
PostgreSQLエンジン「AlloyDB」がGAに
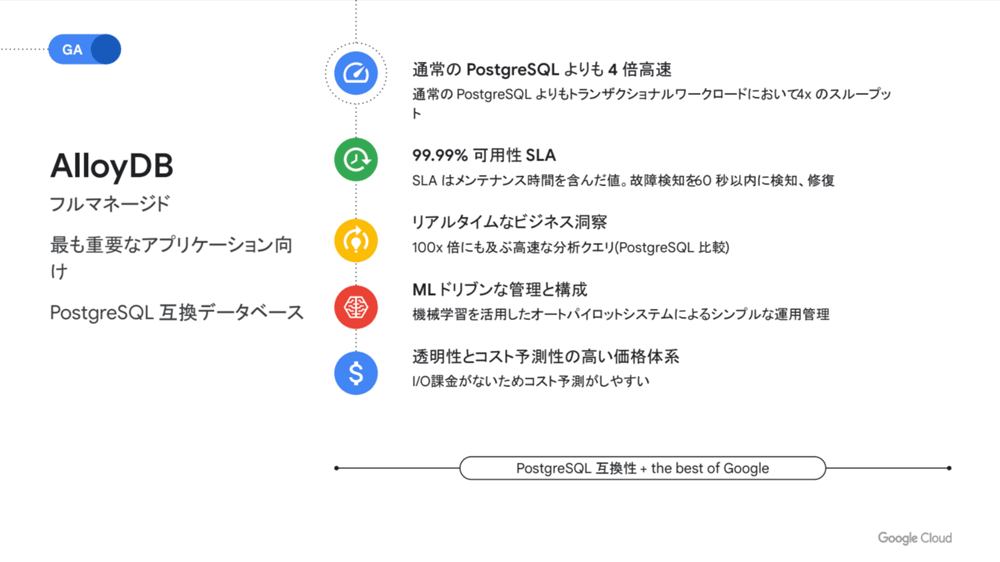
今回のカンファレンスでは、2022年5月に発表された「AlloyDB」のGAも発表されました。寶野氏はAlloyDBの特徴として以下のポイントを挙げています。
通常のPostgreSQLよりも4倍高速
99.99%の可用性
リアルタイムなビジネス洞察
MLドリブンな管理と構成
透明性とコスト予測性の高い価格体系
このAlloyDBの導入をより多くの企業に検討してもらうため、Google CloudはAlloyDBのデータベースエンジンのみをダウンロード可能なパッケージとした「AlloyDB Omni」のプレビュー提供(無償)を開始しました。これによりユーザはデータセンターやローカルのPCなどのオンプレミス環境からAWSなど他社のクラウドを含めたさまざまな環境でAlloyDBの性能を試すことが可能になり、とくにAlloyDBの高いパフォーマンスを支えるインメモリ型のカラムナエンジンを検証するのに適しているといえます。寶野氏はAlloyDB Omniについて「Google Cloudとしては今回は幅広いユーザからのフィードバックが目的」と語っており、今後のリリースなどに関してはまだ未定ですが、レガシーデータベースからの脱却を検討中のユーザにとっては興味深い選択肢となりそうです。