テキストを入力するだけで美麗な画像を自動生成するAI、いわゆる画像生成AIがいま注目されています。本特集では、画像生成AIの裏側にある機械学習のしくみについて、易しく解説していきます。前編では、画像生成AIの全体像と、「 text-to-image」技術の柱のひとつ「テキストエンコーダ」を紹介します。
画像生成AIの衝撃
世界を席巻した画像生成AI
今AI業界で最もホットな話題は何かと聞けば、多くの人が画像生成AIと答えるのではないでしょうか。2022年はテキストから画像を生成するAIが急速に発展し、AI業界にとどまらず世間一般の注目を大いに集めました。アメリカのAI研究企業であるOpenAIがDALL・E
2を発表したのを皮切りに、MidjourneyやStable Diffusionといった画像生成AIが次々と登場しました。これらのAIが生成する画像の品質の高さは、表1 のように一目瞭然です。
表1 画像生成AIの入出力例
AI
DALL・E 2
Stable Diffusion
入力文
A humanoid made out of sushi
A small cabin on top of a snowy mountain in the style of Disney, artstation
日本語訳
寿司でできた人型ロボット
雪山の頂上にある小屋。ディズニー風。ArtStation
生成画像
さらに、その多くはユーザーがテキストを入力するだけで画像を生成できるアプリケーションを備えていたため、人々が気軽に使える身近な存在として急速に普及しました。これまでにも囲碁AIのAlphaGoや言語AIのBERTやGPT-3を始め、強力なAIは多数登場していますが、ここまで多くの人が積極的に利用するAIはありませんでした。
生成AIとは何者なのか
画像生成AIという言葉から想像できるように、「 文章生成AI」や「音楽生成AI」なども存在します。本記事ではこれらをまとめて「生成AI 」と呼ぶことにします[1] 。
生成AIはこれまでのAIと何が違うのでしょうか。従来のAIの例として、入力画像がホットドッグかどうかを判別する画像分類AIを考えましょう。このAIは、入力データを処理して、それがホットドッグである確率を予測します。
しかし、このAIは訓練データの画像が従う分布に関する情報を持っていません。つまり、「 ホットドッグの画像の例を挙げよ」と問われても答えることができません。
これに対して生成AIが異なるのは、データの分布を内部でモデリングしており、生成時にはその分布からデータをサンプリングして出力するところです。生成AIは「ホットドッグの画像の例を挙げよ」の問いに答えることができるのです。もし仮にデータが正規分布に従っているなら、分布は平均と分散というたった2つのパラメータで表現できます。しかし、実際のデータ(ホットドッグの画像)の分布は単純な関数の形で表すことができない、複雑なものです。生成AIはこの複雑な分布をニューラルネットワークで近似しており、近似を良くしていく過程を「学習」と呼んでいます。
生成AIは、ただランダムにデータ(たとえば画像)を生成することもできますが、Stable Diffusionなどで注目されているのは、テキストによる指示に従って画像を生成する機能です。
この機能ないしタスクのことをtext-to-image と呼びます。同様に、ラフスケッチのような下書きから高品質な画像を生成する機能をimage-to-image、テキストから音楽を生成する機能をtext-to-music などと呼びます。text-to-imageは、生成したい画像の要件をテキストで指示できるという簡便かつ直感的なインターフェースが魅力だと言えます。絵画や写真やCGのスキルがなくても、「 こういう画像がほしい」という要件をうまく言語化できさえすれば所望の画像を得られるのだから、便利です。
本記事では、生成AIの中でもとくに画像生成AIまたはtext-to-imageに注目し、一見魔法のようにも思えるAIのしくみを紐解きます。
AIや機械学習に関する専門知識を必要としない形で書いていますが、興味をお持ちになった方が知識を深められるよう、重要な概念は誤魔化さずに紹介しています。かつては「クリエイティブなことはできない」と評されることも多かったAIが、いかにして高度なtext-to-imageを実現しているのか。そのしくみを知ることは、来る生成AI時代に重要になっていくのではないでしょうか。
テキスト入力に基づく画像生成
text-to-imageの処理過程
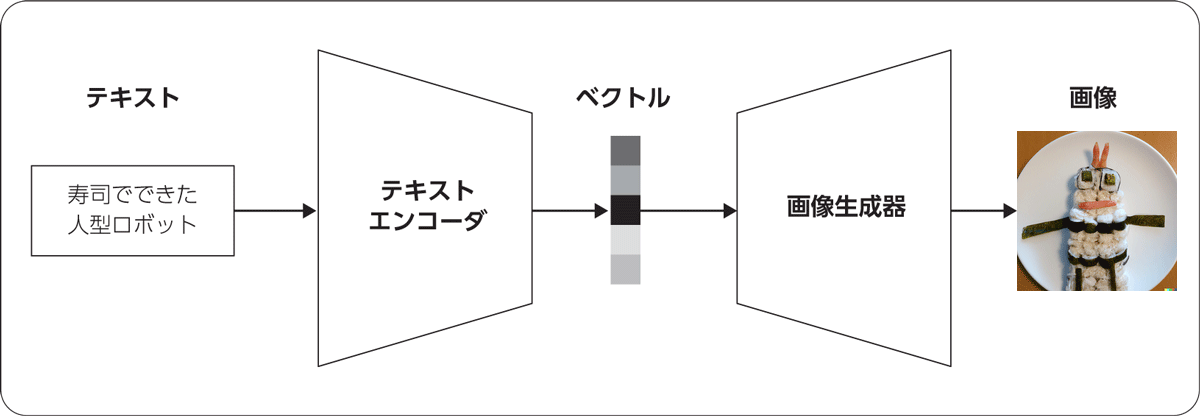
まずは、text-to-imageで行われている処理の全体像を俯瞰《 ふかん 》 してみましょう。典型的なモデルは、図1 のように「テキストエンコーダ 」と「画像生成器 」という2つの部分からなります。
図1 text-to-imageの典型的な処理過程
テキストエンコーダは入力されたテキストを低次元のベクトル[2] に変換し、画像生成器はこのベクトルを画像に変換するという役割をそれぞれ担っています。
このベクトルは何者かというと、「 入力テキストの意味」ないし「画像の内容」を表す「数字の列」です。意味的に近いベクトル同士は空間的にも近いようになっていて、「 『 寿司』という単語に対応するベクトル」と「寿司の画像に対応するベクトル」は空間上で近くに配置されることが期待されます。また、「 『 刺し身』という単語に対応するベクトル」はこれらの近くに、「 ロボットの画像に対応するベクトル」は離れたところに配置されるでしょう。低次元といっても数百次元くらいのオーダーになりますが、それでも入力テキスト(語彙のサイズと単語数の積によって決まり、少なくとも数百万のオーダー)や出力画像(画像の幅と高さの積にRGBの3をかけたもので、256×256のサイズなら約20万)の次元に比べるとかなり圧縮されています。
text-to-imageの発展によりテキストエンコーダや画像生成器の中身は変遷してきましたが、これら2つの部分からなるというパラダイムは基本的に変わっていません。ですので、DALL・E 2やStable Diffusionなどのtext-to-imageの個別実装を調べるときは、この図を念頭に置いて論文やコードを読み進めるとわかりやすいのではないかと思います。
内部処理を俯瞰したところで、text-to-imageの発展の歴史を通してその成功の鍵を見ていきましょう。一言で言うとその歴史は「大規模化の過程」であり、深層学習とデータの強力さを物語っています。
黎明期の研究
text-to-imageの研究の元祖は2015年のalignDRAW [文献1] だとされています。alignDRAWは、テキストエンコーダと画像生成器の両方をRNN(Recurrent Neural Network )で実装したモデルです。RNNは1次元の系列データを扱えるニューラルネットワークで、当時のデファクトスタンダードでした。
参考文献[文献1] の著者らは、このモデルをMS-COCO [文献2] というデータセットで学習させることで、図2 のような画像を生成することに成功しました。図2は、alignDRAWが「砂に覆われた広大な砂漠でスキーをする人(原文:A person skiing on sandclad vast desert. ) 」というプロンプト[3] から生成した画像です(実際にはカラー画像です) 。
図2 alignDRAWが「砂に覆われた広大な砂漠でスキーをする人」というプロンプトから生成した画像(参考文献[文献1] より引用)
生成された画像はプロンプトの内容をある程度は反映している(デタラメな画像ではない)ようですが、解像度が32×32と小さい上に全体がぼやけているため、何を表しているか判別するのは容易ではありません。
生成画像の品質は、後続の研究により少しずつ向上していきました。アーキテクチャや学習方法のさまざまな改善により、2017年ごろには256×256の画像を生成できるようになりました[文献3] 。
大規模データによる学習
しかし、text-to-imageはその後しばらく主要な改善が起きず、停滞とも思われる時期が続いていました。そんな中、2021年にOpenAIが発表したDALL・E [文献4] は研究者たちに衝撃を与えました。生成画像の表現の幅が圧倒的に向上し、「 アコーディオンでできたバク」のような、誰も見たことのない画像を生成できるようになったのです。
DALL・Eは、テキストエンコーダにTransformerを、画像生成器にVQ-VAE(discrete VAE)を採用したモデルです。
ただし、ここで注目したいのは、DALL・Eのアーキテクチャではありません。アーキテクチャ自体は当時の既存技術の組み合わせで、細かい工夫を除けばシンプルとすら言えるものです。DALL・Eの新規性は、モデルとデータ量の大幅な拡大にあります。
まず、従来のモデルのパラメータ数は数千万から数億のオーダーでした。これに対して、DALL・Eは120億パラメータと、従来比で100倍以上の拡大を行いました。
また、従来モデルは研究用に作られたデータセットを利用して訓練されていました。たとえば先出のMS-COCOは、約8万枚の画像に5人以上のアノテータが英語のキャプションを付与することで作成されたデータセットです。一見すると十分な量にも思えますが、DALL・Eの開発者らは既存のデータセットこそがtext-to-imageの性能の制約になっていると考え、大規模モデルを訓練するのに十分な大規模データセットを作成するところから研究を始めました。Web上にある画像とHTMLの代替テキストをクロールし、適切なフィルタリングを施すことで、最終的に2.5億もの大量の画像・キャプションペアを入手しました。画像枚数で比較するとMS-COCOの約3,000倍です。代替テキストは不正確なことも多々ありますが、質を量で圧倒しようというわけです。
これらの工夫により、DALL・Eは従来手法を圧倒する表現力を実現しました。それまでの手法は、研究用に整備されたデータセットを所与のものとしていた結果、表現できる画像の幅が研究用データセットに閉じられてしまっていました。DALL・Eはモデルとデータの拡大により「表現力の天井」を突き破り、text-to-imageの新時代を切り開いたのです。
アーキテクチャの成熟
そのあと、2022年にDALL・E 2 [文献5] やStable Diffusion [文献6] [文献7] が登場して世界の注目を集めたのはご存じのとおりです。表1や図3 に示したように、これらのモデルは、ほとんど任意のキャプションに対して、意味的に整合する画像を768×768から1024×1024の解像度で生成できます。黎明期の研究(alignDRAW)との差は歴然たるものです。
図3 DALL・E 2が図2と同じ「砂に覆われた広大な砂漠でスキーをする人」というプロンプトから生成した画像(筆者作成)
DALL・Eの新規性がモデルとデータの拡大にあったとするなら、DALL・E 2やStable Diffusionの意義は「大規模text-to-imageに適したアーキテクチャの探索」だと言えるでしょう[4] 。これらの研究によって、テキストエンコーダには事前学習済みTransformer を、画像生成器には拡散モデル を採用するのが良いということがわかってきました。これがどういうことなのか、以降で詳しく見ていきます。
パーツ1:テキストエンコーダ
言葉の意味を理解させる方法
テキストエンコーダの役割は、人が自然言語で行う指示を「理解」することです。具体的には、入力テキスト(クエリ)をベクトルに変換するわけですが、このベクトルに「クエリを画像で表現するとしたら、どんな画像になるか」の情報が詰め込まれます。たとえば、「 赤い立方体」というクエリであれば、それを理解して画像に表現することはさほど難しくないでしょう。しかし、もう少し複雑な「赤い立方体の上に2つの青い球体がある」というクエリだとしたらどうでしょうか。正確な画像を生成するためには、各物体と色の関係、各物体の数、物体同士の位置関係などの要素を理解する必要があります。ここの理解が不正確だと、仮に画像生成器がどれほどきれいな画像を生成できたとしても、色や数や位置の関係があべこべな画像が生成されてしまいます。
したがって、text-to-imageの大前提は自然言語を理解すること、すなわちテキストを適切なベクトル表現に変換することです。これはAI研究で最も主要な研究テーマの1つでもあり、盛んに研究が進められています。
言葉の「意味」をAIに理解させる試み(事前学習 )は、典型的には言語モデリング によって行われます。言語モデリングとは、文章をトークン[5] に分割し、そのトークン列の確率分布をモデリングすることです。文章が持つ表現の多様性を考えれば想像できるとおり、トークン列の確率分布は極めて複雑ですが、これを表現力の高いニューラルネットワークで近似してやろうというわけです。
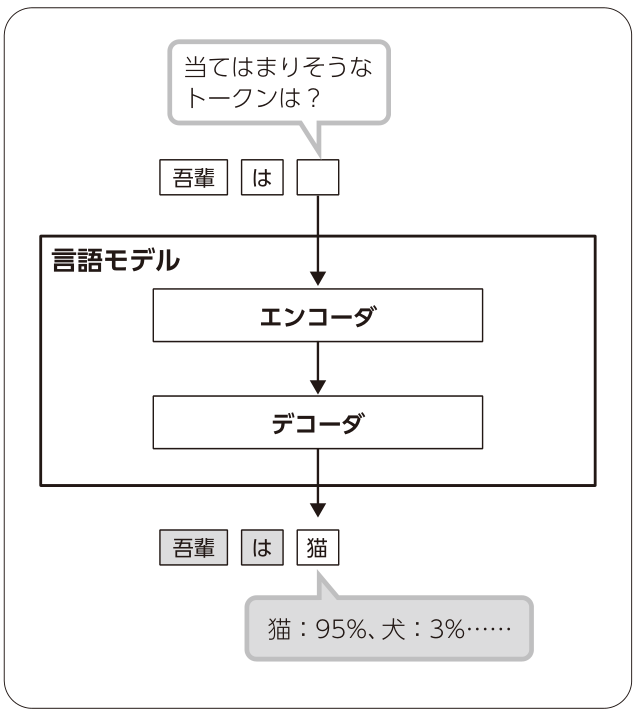
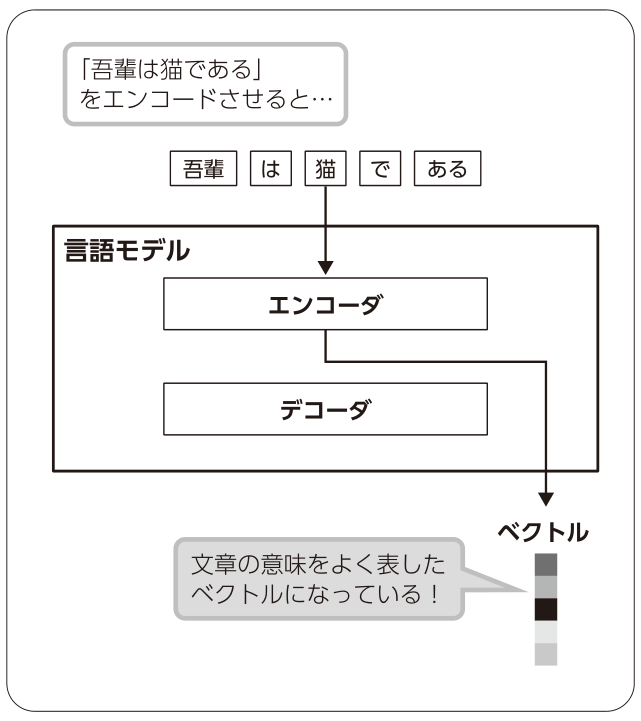
言語モデルは、「 文章の一部を周辺の文脈から予測させる」というタスクを解かせることで学習されます(図4 ) 。「 文章の一部を予測できるAIを作って何がうれしいのか」と思われるかもしれませんが、そのAIの中間出力を取り出すと、入力した文章の意味をよく表したベクトルになっており、text-to-imageを含むさまざまなタスクに利用できて都合が良いのです(図5 ) 。そのため、言語モデルの性能向上のための研究が盛んに行われています。
図4 言語モデルの訓練の模式図
図5 言語モデルからテキストのベクトルを抽出する挙動を示した模式図
なお、テキストエンコーダの事前学習を実現する方法は言語モデリングだけではありません。DALL・E 2やStable Diffusionで採用されているCLIP (Contrastive Language-Image Pretraining )[文献8] のテキストエンコーダは、画像との対照学習 によって訓練されています。すなわち、多数の画像・テキストペアをシャッフルしてモデルに見せたうえでペアを当てさせるというタスクを解かせています。訓練データのソースがHTMLの代替テキスト(ごく短い文章であることが多い)であることから推測すると、画像との対照学習は複雑な長文の処理で言語モデリングに劣る可能性が高いでしょう。しかし、複雑な長文が登場しにくいtext-to-imageを応用先とするならば、訓練時に画像情報を入れられる対照学習に合理性を見ることができます。
モデルの大規模化とプロンプトエンジニアリング
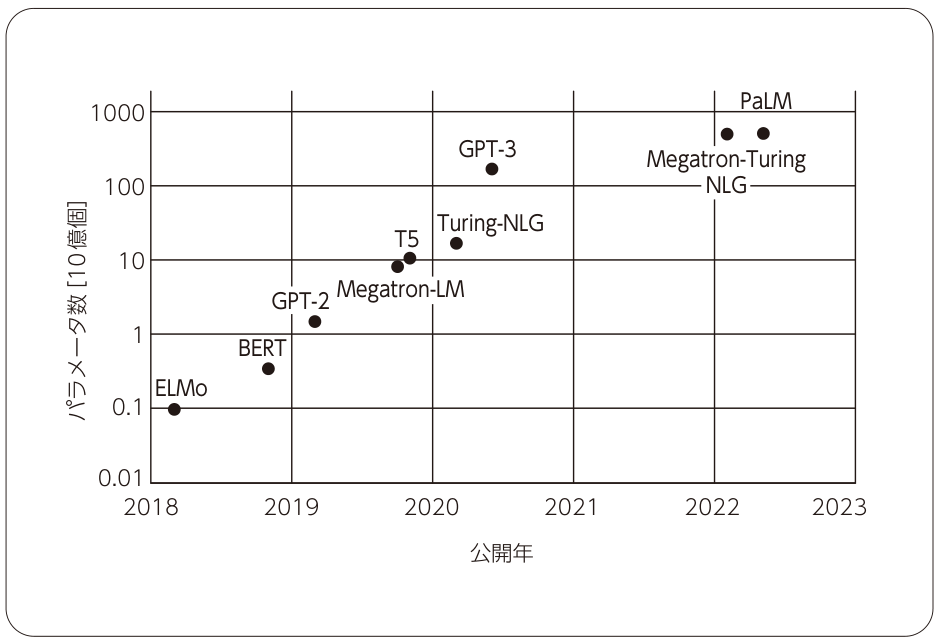
近年の自然言語処理研究の一大トレンドは「モデルの大規模化」です。2017年にTransformer [文献9] というスケールしやすいニューラルネットワークが発表されて以降、モデルを大きくすればするほど、また訓練データを増やせば増やすほど、モデルの精度が高くなるということが経験的にわかってきました[6] (図6 ) 。
図6 大規模言語モデルの公開年とパラメータ数の関係(縦軸は対数スケール)
この経験則は現在ではスケーリング則 として知られています。こういった「大規模言語モデル 」の例としては、BERT、T5、GPT-3 [文献10] などがあります。T5はGoogleが発表したtext-to-imageであるImagenでも使われており、その有効性が確認されています。
大規模言語モデルは、入力文の「書き方」によって出力が変わるという複雑な挙動を示します。たとえば先出のGPT-3は、入力に「次の文をフランス語に訳しなさい」のようなタスク指示文を入れることで、任意のタスクを解くことができます。その幅は想像以上に広く、翻訳・質問応答・要約・対話だけでなく、簡単な四則演算やプログラミングもできてしまいます。タスク指示文にはいくつかの質問と回答の具体例を含めることもできるのですが、この具体例を適切に選ぶことで出力の精度をさらに高めることができます。また、「 思考過程」を含めることで複雑な問題に適応させることも可能です[文献11] (表2 )。大規模言語モデルのこのような性質はまだ発見されたばかりですので、全容の解明はこれからですが、挙動そのものは我々人間にとって直感的に理解しやすいのではないでしょうか。大規模言語モデルも人間と同じで、「 わかりやすい指示を与えると回答の精度が上がる」ということです。
表2 プロンプトエンジニアリングで問題が解けるようになる例(参考文献[文献11] で紹介されている結果をもとに筆者が作成)
このように大規模言語モデルの性能を高めるために入力文を試行錯誤することをプロンプトエンジニアリングとも呼びますが、これはtext-to-imageにおいても有効です。たとえば、表1の2列目に示した例では入力に“ artstation” という単語を入れています。これは「アーティスト向けコミュニティサイトであるArtStationにありそうな画像にせよ」という指示で、画像の品質を向上させる効果があります。ほかにも、「 ゴッホ風」や「マクロ撮影」などの単語を(英語で)追加することで画像の雰囲気をより詳しく指定したり、単語を適当な記号でくくることで強調したりといった操作が可能です。このあたりの挙動はモデルによって異なるので、現状は試行錯誤をもとに探るしかありません。関連論文やユーザー有志による指南書を参考にするのも良いでしょう[7] [8] 。
今回の記事はここまでです。後編では、画像生成器の解説や生成AIの未来に関する考察を行います。お楽しみに。
※「画像生成AIのしくみ【後編】 AIの絵筆はどんな形?「画像生成器」について知る 」の記事もご覧ください。
参考文献
[文献8] Alec Radford et al., Learning Transferable Visual Models From Natural Language Supervision. In ICML, 2021.