


こんにちは。サイバーエージェントの杉浦です。
連載
オブザーバビリティとプロファイル
安定してサービスを提供するためには、デプロイしたアプリケーションの状態を継続的に観測し、不具合やその予兆を察知・
アプリケーションの状態を観測する能力をオブザーバビリティ
それぞれメトリクスはCPU使用率やメモリ使用量といった時系列の数値データ、トレースは個々のアプリケーションを伝播する特定のリクエストの追跡データ、ログはタイムスタンプと共に出力される文字列データを指します。
ただし、今日ではこの3種類のデータでは不十分という見方があり、イベント・
イベントは商品の購入や席の予約といったサービスに対してのアクションのデータ、例外はエラーやそのエラーを引き起こした入力値のデータ、そしてこの記事で取り上げるプロファイルはスタックトレースとそれに関連するCPU使用率やメモリ使用率といったメトリクスのデータを指します。
また、プロファイルデータの可視化では、スタックトレース中の一つ一つの関数やメソッドで枠を定義し、その枠の長さを注目するメトリクス値の大小で決定して、フレームグラフを形成するのが一般的です。アプリケーション運用者はこのフレームグラフを見て、全体に対してどの処理が大きな割合を占めているかを把握し、パフォーマンス向上のための改善案を検討できます。
Kubernetesの世界では、外部からのアクセスによる負荷や、内部の計算機環境の変化など様々な要因によって、アプリケーションの実行環境が動的に変化します。このような頻繁に変更が伴う環境では、メトリクスをはじめとするモニタリングデータを各アプリケーションごとに個別に管理するのは、運用コストの面から現実的ではありません。
この記事ではプロファイルに注目し、Kubernetesに対応したプロファイルデータを管理するツールとしてParca・
Parca
Parcaはプロファイルデータの継続的な収集・
ParcaはParca Agent・
Parca AgentはeBPFを活用して、ユーザ空間・
なお、Parca Agentが収集するプロファイルデータはコンテナに限らず、モニタリング対象のホスト上のすべてのプロセスのデータを収集します。Parca Agentの詳しい内部の設計については公式ドキュメントの
また、Parca Agentは収集したプロファイルデータに対して自動的にラベルを付与します。例えばKubernetes上のコンテナについては、Pod名やコンテナ名、属するNamespaceの名前をラベルとして付与します。付与するラベルについては設定ファイルを使って自分で指定したり、削除したりもできます。
Parca ServerはParca Agentまたはアプリケーションのもつプロファイルデータを公開しているHTTPエンドポイントからデータを収集します。収集したデータは、関数名やファイル名といったメタデータはGo製のKey-ValueストアであるBadgerDBに、プロファイルデータ本体は列指向データベースのFrostDBにそれぞれ保存します。
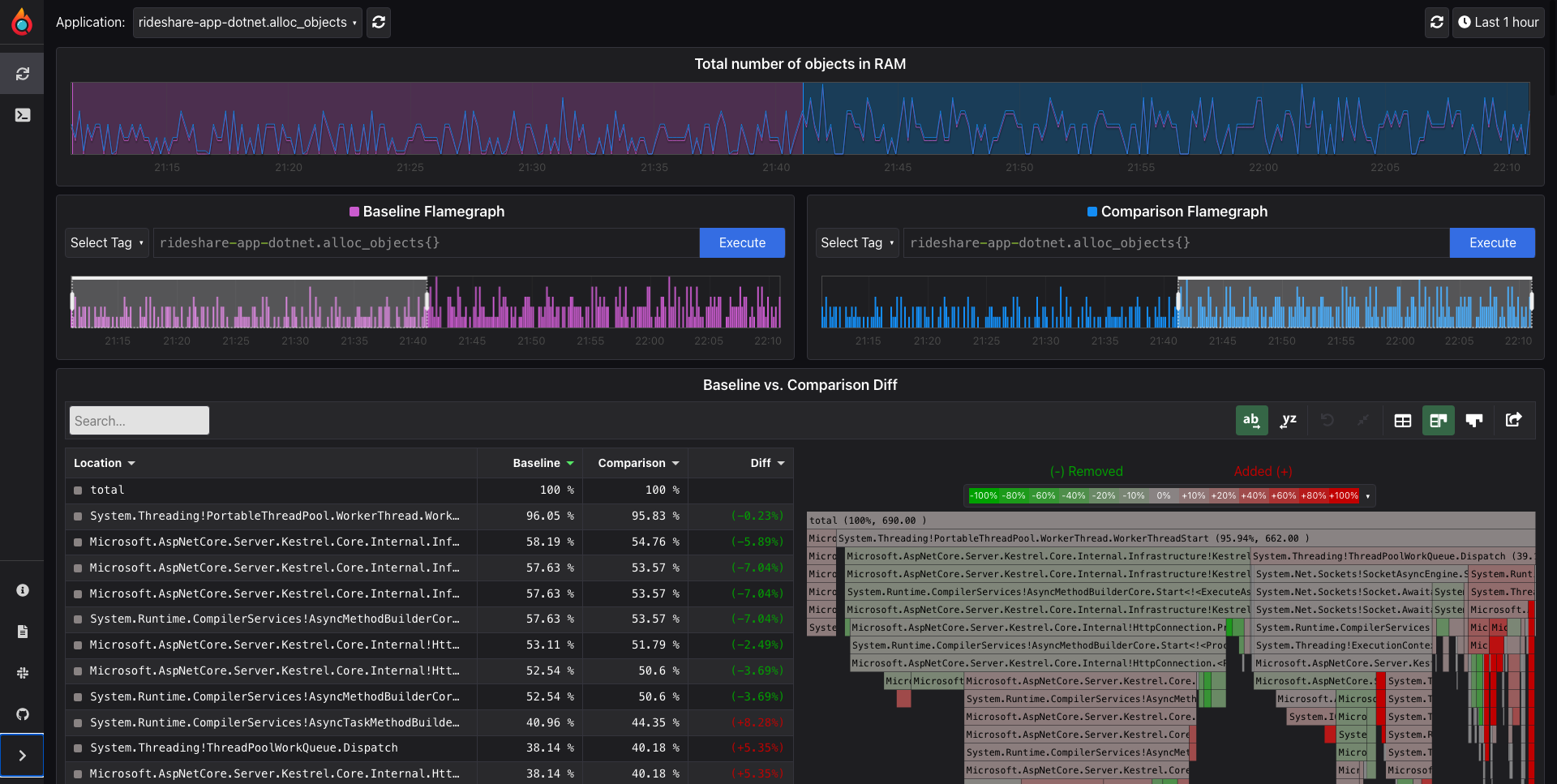
Parca Web UIは、ブラウザ上でParca Serverが保存したデータの、ラベルを使った検索機能と、グラフを提供します。Parca Web UIは2つのグラフを並べて表示する機能をもち、一つのモニタリング対象に対して任意の2つのプロファイルデータ収集時点での比較ができます。例として次の図は、あるコンテナの2つのデータ収集時点を選択しているときのParca Web UIです。フレームグラフの緑の部分が一つ目に選択した時点より2つ目に選択した時点よりスパンが小さいことを、赤の部分がスパンが大きいことを示しています。
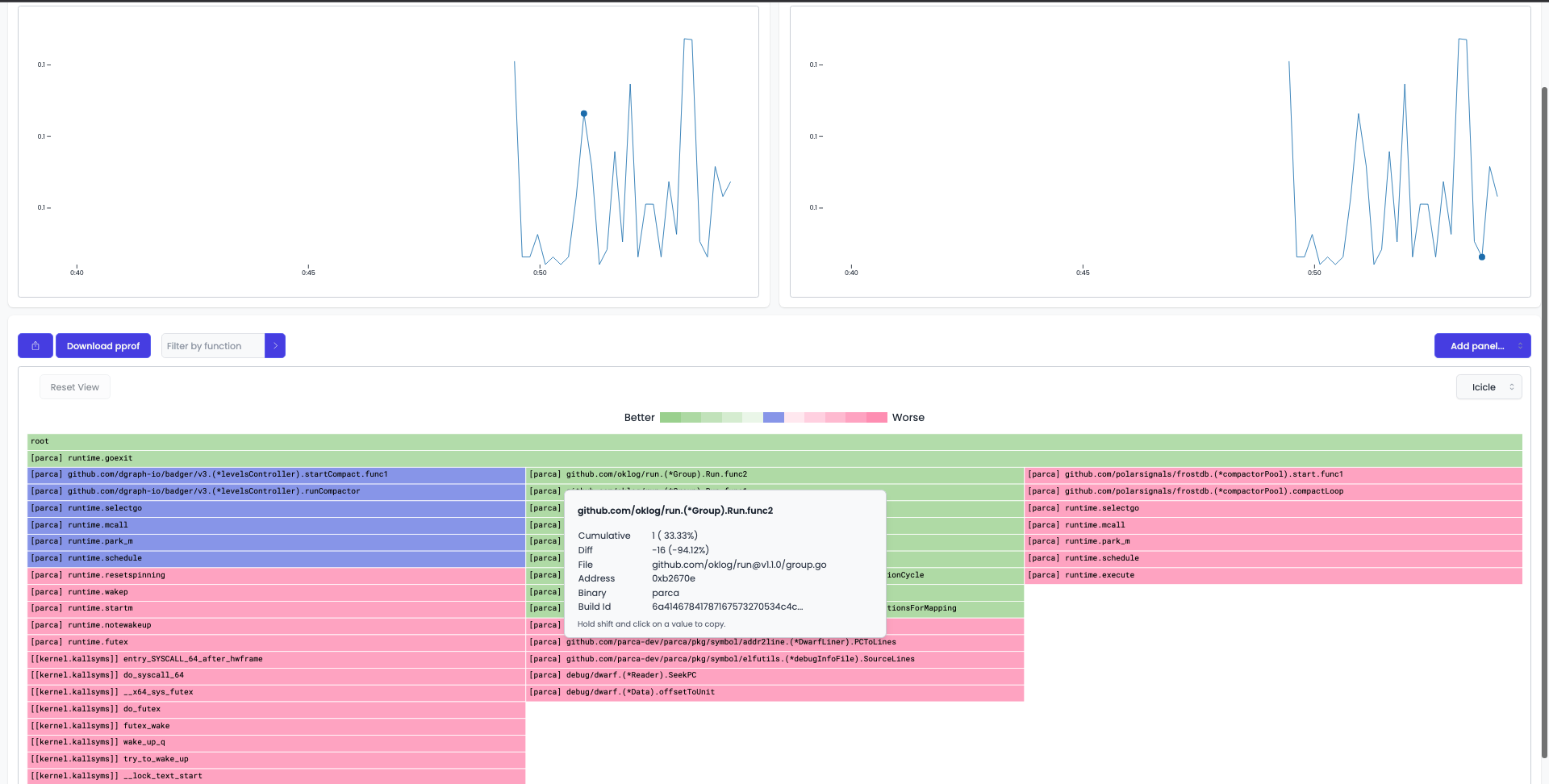
Parcaは公式のデモ用Webページを用意しています。実際にWeb UIを操作してみたい方は利用してみてください。
また、ParcaにはGrafana Pluginが用意されており、Grafanaダッシュボード上でもParcaが収集したプロファイルデータを表示できます。
Pixie
PixieはKubernetesクラスタを対象としたオブザーバビリティを提供するツールです。Pixieはプロファイリングだけでなく、クラスタ内のネットワークトラフィックの可視化や、CPUをはじめとする使用計算リソースの可視化、通信リクエストのレイテンシやスループットの可視化など様々な機能を持っています。
執筆時点でプロファイルがサポートされている言語はGo・
Pixieは各モニタリングデータを収集するのにeBPFを活用しています。プロファイリングにおいてはeBPFを用いて定期的にCPUが実行しているプログラムを調べ記録し、そのデータを集積してフレームグラフを構築しています[3]。また、PixieではeBPFによるプロファイリングで収集したプログラムの命令ポインタとそれに対応する関数名を紐づけるシンボル化処理を、実装が難しいとされているインタープリタ型の言語であるJavaでもできるよう実装しています。Java
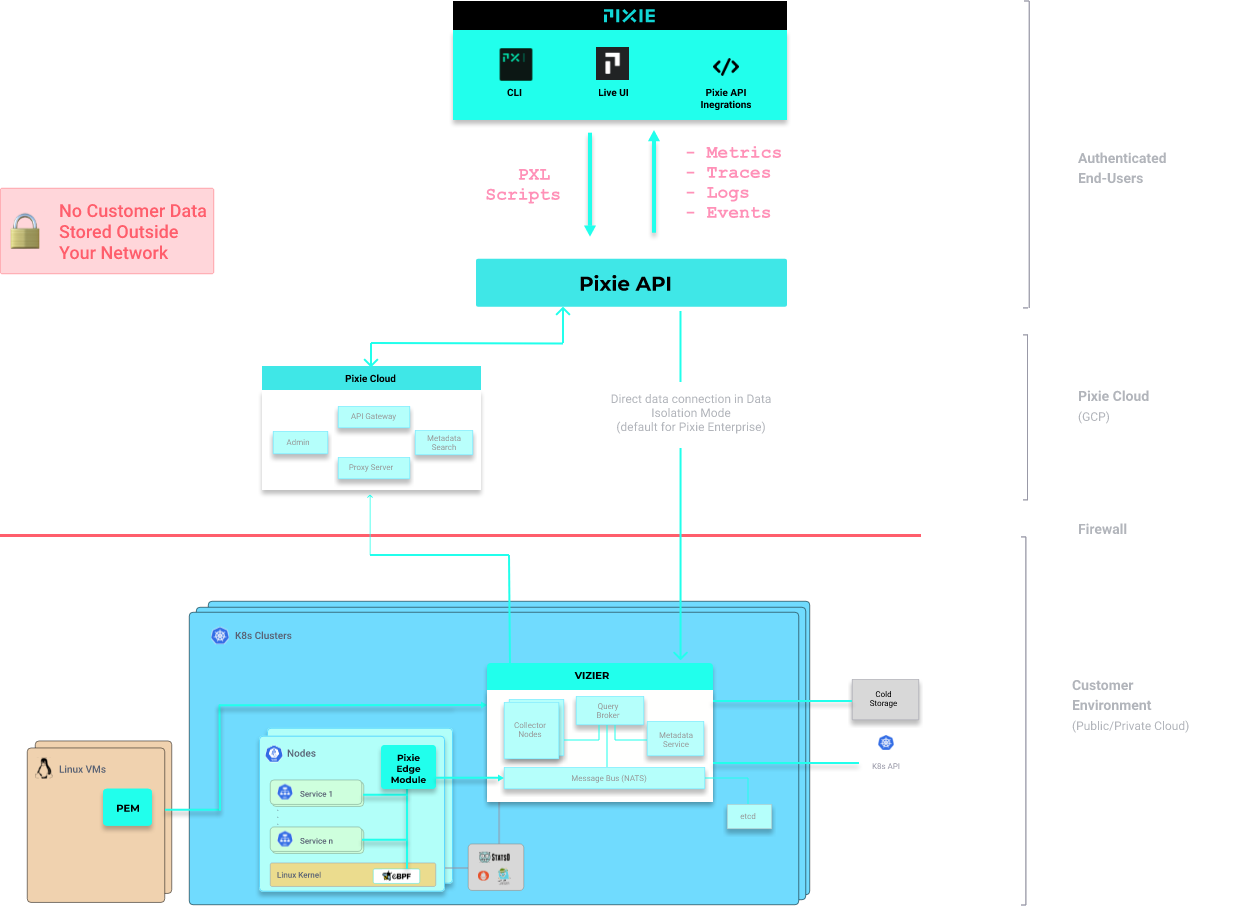
Pixieは大きく分けてPixie Edge Module
PEMはデータを収集するエージェントで内部ではeBPFが使われています。VizierはKubernetesクラスタごとに動作する、クエリの実行とPEMの管理を担うコンポーネントです。Pixie Cloudはユーザの管理や認証、データのプロキシとして使われます。Pixie Cloudは自前での運用も、Pixie Community Cloudの使用もできます。Pixie CLIはPixieのデプロイやクエリの実行などを担います。Pixie Client APIはプログラム経由でPixieへアクセスするためのインターフェースを提供します。
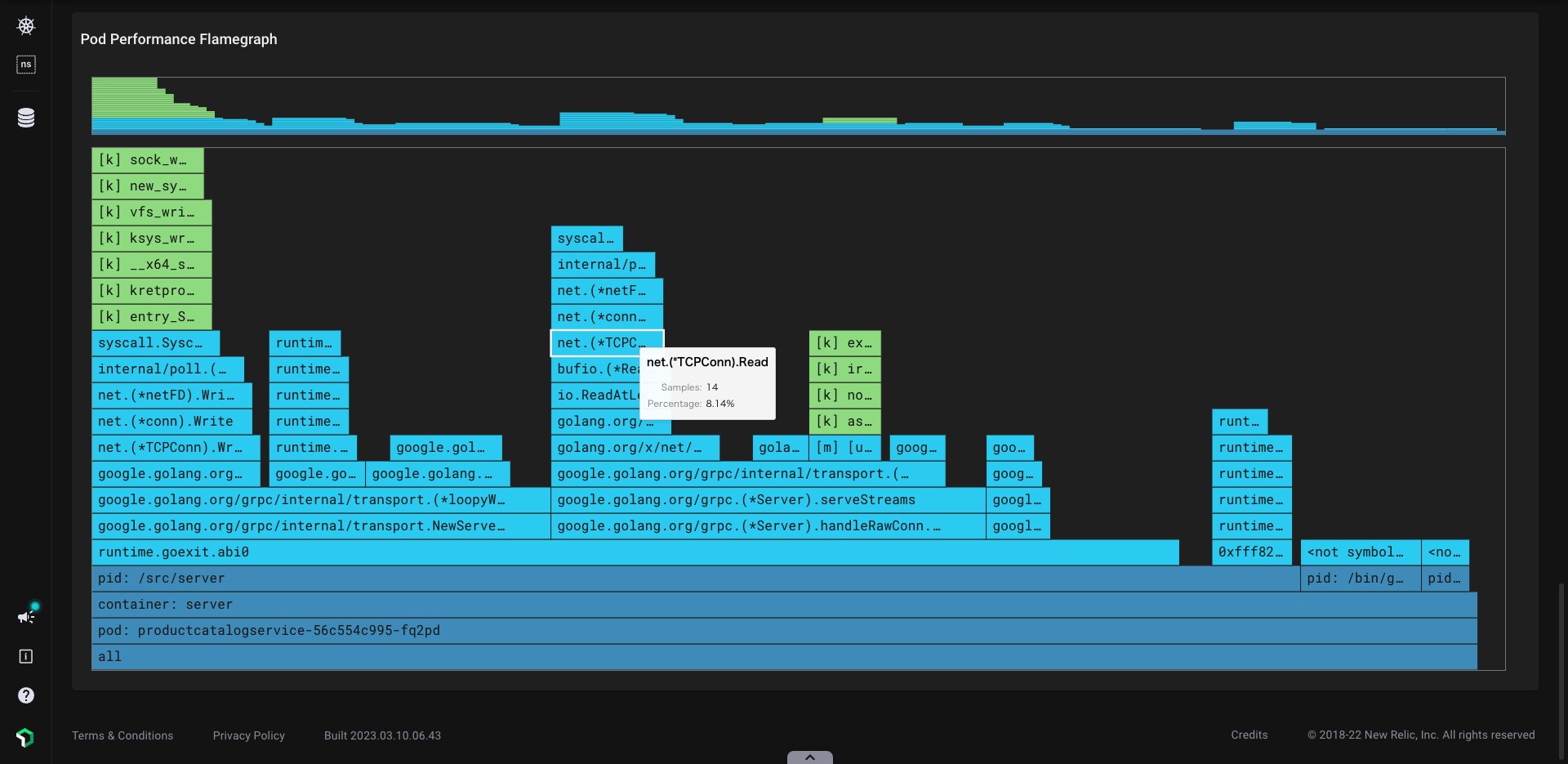
PixieもWeb UIを用意しており、Pixie Cloudから各モニタリングデータが見れます。フレームグラフは各Podの詳細画面のページ下部に用意されています。フレームグラフの各スパンは色分けされており、濃い青色はKubernetesのメタデータ、水色はユーザ空間のアプリケーションコード、緑色はカーネルのコードを示しています。
Grafana Pyroscope
Grafana Pyroscopeは他のツール同様、プロファイルデータの収集・
Grafana Labsは元々プロファイリングを扱うツールとしてGrafana Phlareを開発していました。しかし、Pyroscope社との合併に伴い、Grafana PhlareプロジェクトをPyroscopeと統合しGrafana Pyrosoceプロジェクトを発足させました[5]。執筆時点では、まだGrafana Pyroscopeとしてのドキュメントが用意されていないため、以降のGrafana Pyroscopeについての内容はPyroscopeについての情報をまとめたものです。
Grafana Pyroscopeはデータの収集を担うPyroscope AgentとPyroscope Serverの2つのコンポーネントで構成されています。
{kind=link}

Pyroscope Agentはプロファイルデータの収集に各言語のライブラリとeBPFのプロファイラを用意しています。Pyroscope Agentが対応している言語とプラットフォームは公式ドキュメントの
Grafana Pyroscopeを使ったKubernetesにおけるプロファイルデータの収集にはeBPFと各言語のライブラリ、両方を組み合わせた方法が推奨されます。
eBPFを使ったプロファイリングは、言語の依存なく、またアプリケーションの変更なしにシステム全体に導入できます。ただし、Pixieの項で説明した通り、eBPFを使ったプロファイリングは特にインタープリタ型の言語で困難です[6]。
一方で、各言語のライブラリを使ったデータ収集は導入にアプリケーションのプログラムの変更が必要ですが、eBPFを使ったアプローチが苦手とするソースコードレベルでのプロファイリングが容易になります。
そのためGrafana Pyroscopeは両方の収集アプローチを用意し、より包括的なシステムのプロファイリングを実現しています。
Pyroscope ServerはPyroscope Agentが収集したプロファイルデータをPyroscope Agentから送信
取得したデータはBadgerDBへ保存し、保存したデータはクエリを用いて任意の時間区間でデータを外部に提供します。
保存したプロファイルデータを参照するには、Pyroscopeのクエリ言語であるFlameQLを使います。FlameQLではアプリケーション名とプロファイリングデータに付与されたタグを使います。アプリケーション名にはcpuやalloc_といったプロファイルの種類がサフィックスに付与されている場合があります。
例えばappアプリケーションのcpuプロファイルは以下のクエリを実行すると参照できます。
app.cpu
env=productionのタグが付与されたデータに限定したい場合は以下のクエリを実行します。
app.cpu{env="production"}
FlameQLの詳しい仕様については公式ドキュメントを参照してください。
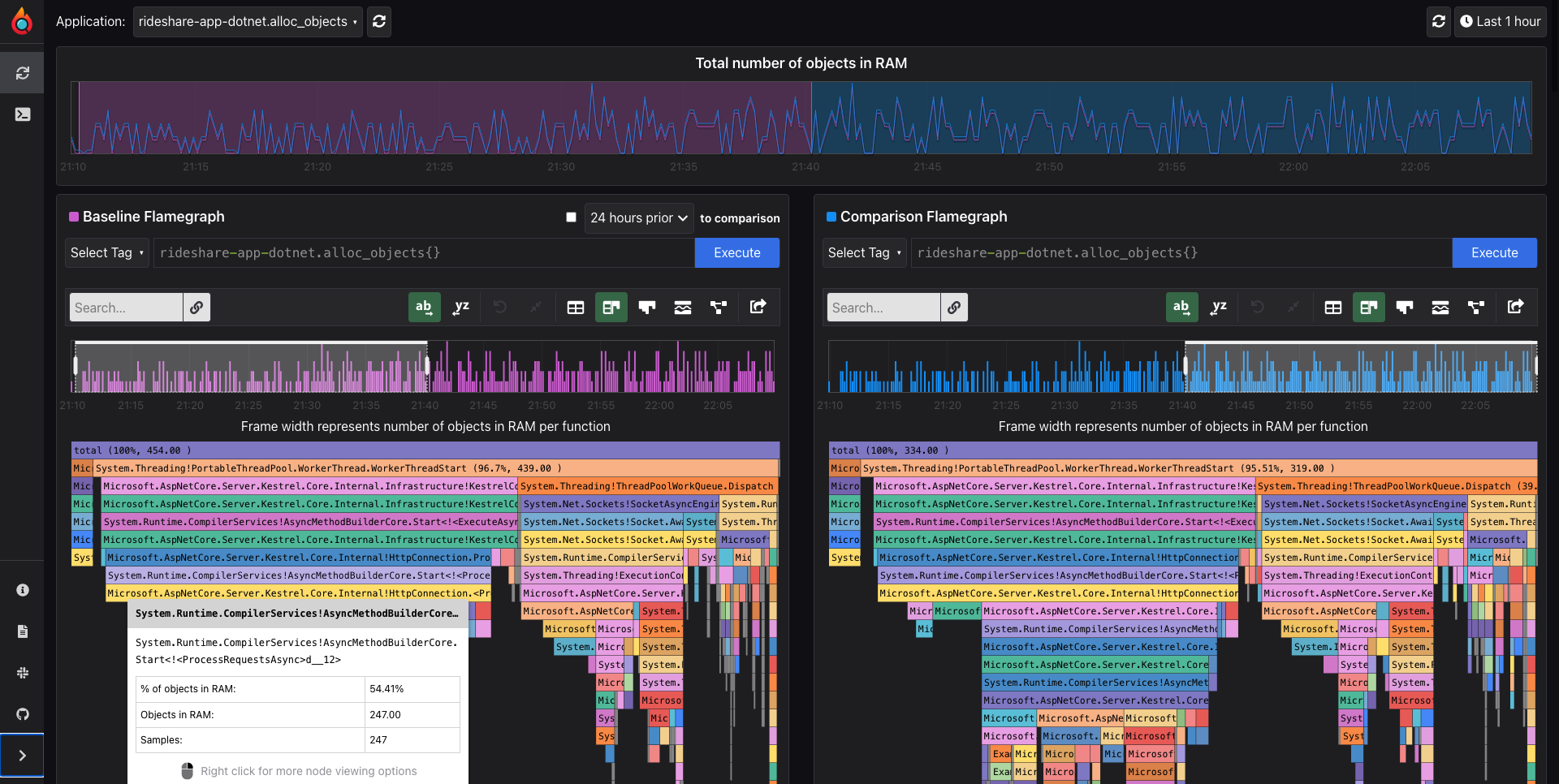
また、Pyroscope Serverはプロファイルデータを参照するためのWeb UIも用意しています。Web UIではある時間区間のフレームグラフが見れるだけでなく、2つの時間区間を並べて見れたり
PyroscopeのWeb UIもParca同様、公式のデモ用Webページを用意しているので、実際に触ってみたい方は活用するとよいでしょう。
またPyroscopeもParca同様、Grafana Pluginが用意されており、Grafanaダッシュボードでプロファイルデータを表示できます。
まとめ
この記事では、継続的プロファイリングを実現するツールであるParca・
Parcaはデータ収集にeBPFを活用しており、アプリケーションの変更なしにプロファイルデータの収集が可能です。アプリケーション固有のプロファイリングデータについてもプロファイル用のHTTPのエンドポイントを用意すれば収集可能です。収集したデータはWeb UIから視覚的に確認でき、既存の環境にいち早く低コストでプロファイリングデータの収集・
PixieもParca同様データ収集にeBPFを活用しており、アプリケーションの変更なしにプロファイルデータを収集できます。また収集したスタックトレースのシンボル化も自動的に行う点は魅力的です。Web UIはフレームグラフの比較や差分を表示できるParca・
Grafana PyroscopeはeBPFと独自のライブラリでプロファイルデータを収集します。導入する際はアプリケーションのソースコードに変更が必要なものの、サポートしている言語数が多く、Web UIも多機能なため、非常に有用なツールと言えるでしょう。
ParcaとGrafana PyroscopeはGrafana Pluginを使ってGrafanaダッシュボード上でフレームグラフを表示できます。すでにGrafanaダッシュボードを用意している組織にとっては、メトリクスやログ、トレース情報とともに一貫してプロファイルデータを見れるのは、アプリケーションを運用する上で非常に強力な助けとなるでしょう。
Kubernetesにおける継続的なプロファイリングの歴史はまだまだ浅く、周辺ツールも含めて今後どのように発展していくのか非常に注目です。