


株式会社MIXIで
みてねのインフラはAWSを全面的に利用しています。サービスがリリースされた2015年から2021年ごろまではAWS OpsWorksというAmazon EC2のオーケストレーションサービスの利用をしておりました。その後Amazon EKSに移行し、AWSのインフラにおける大きな変化となりましたが、同様にモニタリングやオブザーバビリティに関わるツール、サービスについても大きく変化してきました。
本記事ではオブザーバビリティにまつわるツールやサービスの変遷、工夫点などについて紹介します。
オブザーバビリティとは何か
開発したソフトウェアをシステムにデプロイして運用を始めた後、システムが正常に動作し、良いパフォーマンスが出ているのかをモニタリングするというのは開発者にとってよくある習慣です。
モニタリングはあらかじめ監視の対象を決めておきメトリクスを計測するため、障害の防止にフォーカスしがちですが、オブザーバビリティは予測できない障害でもデバッグできるようにするという点で違いがあります。
いざ問題が起きたときに、問題の原因調査に必要なメトリクスやログが不足していて分析できない状況では困ってしまいます。オブザーバビリティがしっかりしていれば、問題の未知や既知を問わず、調査や原因の特定ができるようになります。
現在のシステムでは、コンテナやKubernetesなどのオーケストレーションツールによって複雑化していることや、システムを構成するアプリケーションがいくつものサービスに分かれている場合が多くあります。システム内部の多数のコンポーネントで収集されたメトリクス、ログ、トレースといった多くの情報から効率よく的確に原因を探るためには、それぞれの紐付け、集計、可視化が必要になります。
オブザーバビリティの変遷
みてねの開発スタートから現在に至るまでのオブザーバビリティの変化について振り返ってみます。
2014年~:みてね黎明期
Amazon CloudWatchやAWS OpsWorksで提供される各種メトリクスを活用しつつ、New Relic APMを導入していました。New Relic APMはRuby on Railsのアプリケーションで起きていることを細かく把握でき、パフォーマンス劣化やエラーの原因を探るのに重宝していました。Rubyとの相性が良く、サクッと導入できた点が良いところです。
アプリケーションのログはFluent loggerというライブラリを利用してログをS3に転送していました。
このころは問題が発生した際に個別のメトリクスやログを見たり、APMでApdexスコアやエラーレートをチェックするといった運用をしていたようです
2018年~:SREチーム発足後のみてね
SREチームが発足し、インフラやアプリケーションにおいてさまざまな改善の取り組みが始まりました。
モニタリングの観点ではGrafanaを導入し、重要なメトリクスをGrafanaダッシュボードにセットして確認のしやすさと一覧性を高めました。
New Relicの利用の幅も広がり、New Relic InfrastructureとNew Relic Mobileを導入し、EC2で起きていることやクライアント側で起きていることを把握しやすくなりました。CloudWatchアラームはTerraformで管理されるようになり、設定の変更経緯などがPull Requestで追えるようになりました。
Amazon Aurora Performance Insightsを有効化し、データベース内部の負荷状況やメトリクスを把握できるようにしました。
2021年~:Amazon EKSへ全面移行
Amazon EKSに全面移行され、Kubernetesとの相性が良いPrometheusを活用するようになりました。Amazon EKS移行については
PrometheusからNew Relicにremote writeし、GrafanaからNew Relicに対してPromQLを発行することで、GrafanaのダッシュボードにはCloudWatchに加えてPrometheusのメトリクスも確認できるようになりました。
アラート通知を確実に行えるようにPagerDutyを導入しました。CloudWatchアラームとNew Relicアラートの通知先をPagerDutyにして、当番制度の運用が始まりました。
2022年~:Amazon Managed Service for Prometheus活用、Grafana Loki導入
コスト最適化の観点でNew Relic Infrastructureは使うのをやめ、Prometheusに寄せる形にしました。また、PrometheusからNew Relicに送るメトリクスは最小限にし、Amazon Managed Service for Prometheusに送るように変更しました。
運用者と開発者がログを検索しやすくするためにGrafana Lokiを導入しました。開発環境のログやKubernetesの標準出力のログをもとにトラブルシューティングがしやすくなりました。
New RelicのアラートはTerraformで管理されるようになりました。
現在のみてねのオブザーバビリティ
現在におけるみてねのオブザーバビリティの全体像は図のとおりです。
2023年3月に行われたMIXI TECH CONFERENCE 2023での登壇資料より
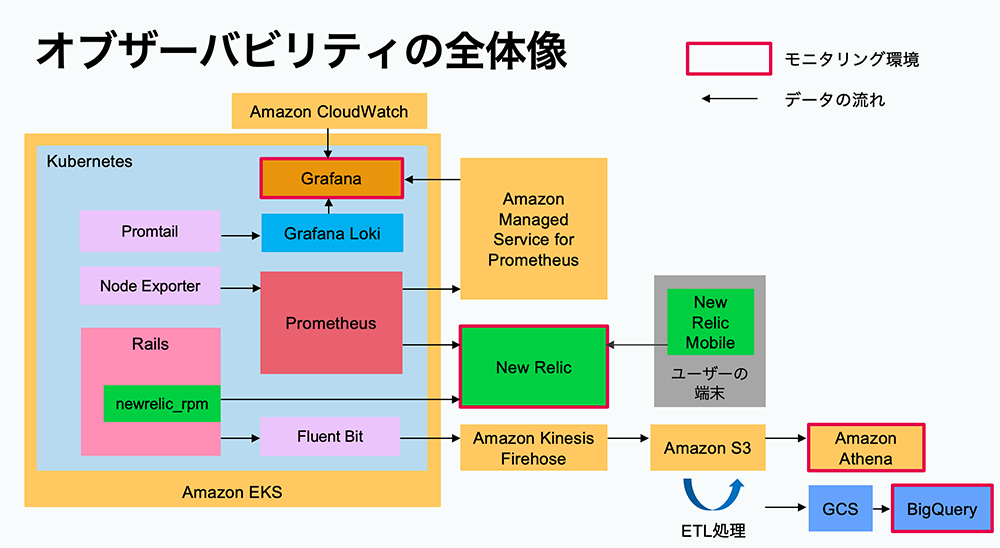
Grafanaを活用した日々のモニタリング
オブザーバビリティに関連して、日々のモニタリングについて紹介します。みてねでは毎朝デイリースクラムを実施した後、SREチームメンバー全員でGrafanaのダッシュボードを確認する時間があります。確認にかける時間は大体5分くらいです。過去1週間分のグラフを基本として
意図しないスパイクなど明らかなトレンドの変化があった場合は、その時間帯を深掘りして調査の必要性や優先度について話し合いが行われます。調査にはNew Relicなどのツールも併用しています。
クラウドサービスには機械学習を利用した異常検知
しかし、必ずしも規則性どおりのトラフィックではないケースもあり、何も対応する必要のないアラートが発報されてしまうことがあるため、あまり積極的に活用していません。
パフォーマンス監視とエラー検出の方法
サービスが拡大してくるとパフォーマンスの問題が起きやすくなります。みてねではユーザ数の増加、サービスの機能拡充によってさまざまなパフォーマンス上の問題が発生し、都度解決してきました。アプリケーションのパフォーマンスの問題はUXを低下させてしまうだけでなく、クラウド利用コストが無駄にかかったりと、サービスの継続性にも影響を及ぼします。
みてねでのパフォーマンス監視にはNew Relic APMとAmazon Aurora Performance Insightsをよく使います。New Relic APMではサービスのAPIへのスループットやレスポンスタイム、ジョブの処理時間、データベースのクエリ状況を確認することが多く、ここから多くのことを発見し、改善につなげることができています。エラーの状況についてもAPMの画面から確認することができ、エラーの傾向や原因となったコードの特定ができます。データベース内部の負荷状況や、APMの結果として現れてこなかったデータベースのクエリについてはAmazon Aurora Performance Insightsを使って分析します。AuroraインスタンスのvCPU数に対する平均アクティブセッション
マルチリージョン構成におけるオブザーバビリティ
みてねのインフラは国内ユーザだけでなく海外ユーザにも快適にご利用いただけるように複数のAWSリージョン
それぞれのリージョンのサーバアプリケーションの状態を知るためにメトリクスやログが必要になりますが、収集先で混ざってしまうとリージョン固有の問題がわからなくなってしまいます。そのため、メトリクスやログにリージョンを識別できる情報を何らかの方法で付加して区別できるようにする必要があります。利用しているツールごとにどのように対処しているか解説します。
New Relic APM
New Relic APMは環境変数NEW_RELIC_APP_NAMEでアプリケーションの名前を定義できるため、リージョン名をサフィックスとして付加することで区別できるようにしています。Helm Chartでは以下のように定義しています。- name: NEW_RELIC_APP_NAME
value: "{{ .Values.appName }}-{{ $.Values.regionSuffix }}"
こうすることで、各リージョンのアプリケーションのパフォーマンスやエラーの状況を把握することができるようになります。
Prometheus
Prometheusは各リージョンのEKSクラスタ上で動作し、収集されたメトリクスは東京リージョンのAmazon Managed Service for Prometheusへ送信されます。PrometheusのHelm ChartはArgo CD Applicationとしてデプロイされる構成になっており、リージョン固有のValuesが優先されるように上書きしています。helm:
valueFiles:
- values.yaml
- values-production.yaml
- values-region/production-{{ $.Values.regionSuffix }}.yaml
これにより、リージョン固有の設定ができるようになり、バージニア北部
writeRelabelConfigs:
- replacement: "us-east-1"
targetLabel: "region"
action: "replace"
これでPromQLのラベルマッチャとして region を利用してリージョンごとにフィルタしてクエリできるようになります。
Grafana Loki
Grafana Lokiは各リージョン、各ノードのDaemonSetで動作するPromtailからログを受け取ります。Prometheusと同様に、どこのリージョンのノードから送信されてきたかわかるようにする必要があります。リージョンのラベルを付加するためにPromtailのHelm Chartでは以下の設定をしています。extraRelabelConfigs:
- source_labels: [__meta_kubernetes_pod_node_name]
regex: '^[a-z0-9-]+\.([a-z0-9-]+)\..+'
target_label: "region"
replacement: "${1}"
- source_labels: [region]
regex: "ec2"
target_label: "region"
replacement: "us-east-1"
EC2のノード名はバージニア北部リージョン
最後に
本記事ではみてねのオブザーバビリティに関わるさまざまな施策を紹介しました。毎年のように改善を繰り返してきましたが、今後も改善は続きます。より良いオブザーバビリティを追求するためにまだいろいろやることはありそうです。たとえば、ツールが複数に分散しているために分析に手間を取ることがあります。
また、Kubernetesクラスタ内のオブザーバビリティはもう少し強化したいところがあります。まだ最良の構成とはいえないかもしれませんが、今回紹介した内容がどなたかのお役に立てたら幸いです。