



はじめに
こんにちは! 逆瀬川
前回はChatGPTのおさらいとプログラミング活用へのあらましを紹介しました。今回は、OpenAIが提供しているChatGPT APIとWhisper APIという2つのAPIを用いて議事録文字起こしアプリケーションを作り、Hugging Face Spacesで公開してみます。
OpenAI APIを使う準備
まずはAPIを使えるようにします。OpenAIのPlatformにアクセスして、サインアップを行います。

メールアドレス等を入力しアカウント認証を済ませたら、API Keysページにアクセスしてください。
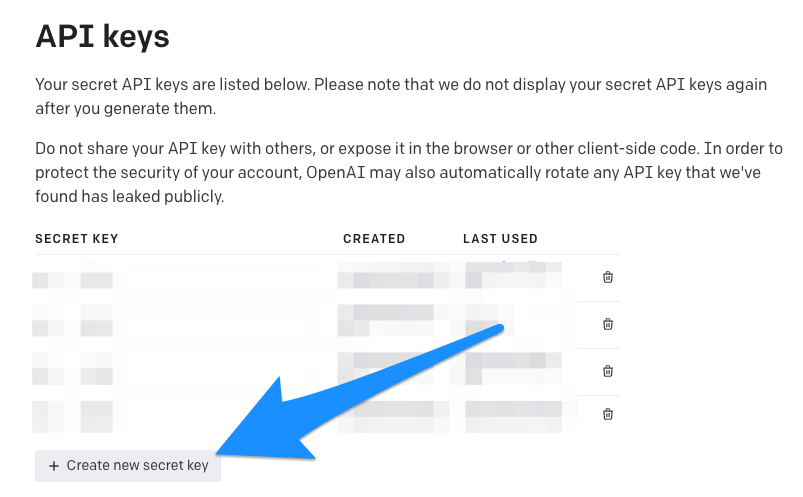
上図のCreate new secret keyをクリックすると新しいAPIキーが作成されます。これでChatGPT APIやWhisper APIを使えるようになりました🎉
ChatGPT APIの料金
ChatGPT APIを使うわけですが、この料金は2023年4月1日現在gpt-3.モデルで$0.
たとえば、

英語に翻訳した

なお、手元でテストしたところ、Tokenizerによる言語間の不公平さは2.
| 文字列 | GPT-3 | GPT-3. |
GPT-4 |
|---|---|---|---|
| こんにちは! |
47 tokens | 38 tokens | 37 tokens |
| Hello! It's a beautiful day today. The laundry is likely to dry well. | 17 tokens | 25 tokens | 24 tokens |
まとめると、目安としては、1k tokens = 750文字程度と考え、GPT-3.
| APIに入出力される合計文字数 | GPT-3. |
|---|---|
| 750字 | 0. |
| 1,000字 | 0. |
ChatGPT APIの使い方
実際にChatGPT APIを使ってみましょう。
openai-pythonのインストール
今回はOpenAIのPython用ライブラリであるopenai-pythonを使います。pipを用いて、openai-pythonをインストールしましょう。
pip install openai
APIリクエスト
ChatCompletion.で対話を生成できます。たとえば、以下のようなコードになります。
import openai
openai.api_key = "sk-..." # APIキー
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "こんにちは!"}]
)
print(completion.choices[0].message.content)
主要なリクエストパラメータは以下のとおりです。詳細はAPIドキュメントのChatの項を参照してください。
- model:モデルの指定
gpt-3.または5-turbo gpt-4を利用できます。gpt-3.や5-turbo-0301 gpt-4-0314などといった日付入りモデルも利用できます。gpt-3.などは更新されていくモデルですが、日付入りモデルは静的なモデルです。なお、リリースから3ヶ月しか保証されないため、使わないほうが良さそうです。5-turbo
- messages:各roleの会話履歴
- roleはそれぞれ以下のように予約されています。
- system: システム設定
- user: ユーザーからの問い合わせ
- assistant: AIからの返信
- roleはそれぞれ以下のように予約されています。
- temperature:温度
- わかりやすく言えば返答のランダムさを司るものです。0から2の間で設定でき、0に近いほど決定論的になります。
- stream:ストリーム処理
- Trueにすると、ストリーム処理でチャットを逐次出力できます。
- max_
tokens:最大出力トークン - 返答の最大トークン数を指定できます。
APIレスポンス
先程のAPIリクエストを行うと、以下のようなレスポンスが返却されます。
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "\u3053\u3093\u306b\u3061\u306f\u3001\u3069\u3046\u3082\u304a\u306f\u3088\u3046\u3054\u3056\u3044\u307e\u3059\uff01",
"role": "assistant"
}
}
],
"created": 1680432099,
"id": "chatcmpl-70pRTo7Y1667VYeVnlHzCyR3aJQzb",
"model": "gpt-3.5-turbo-0301",
"object": "chat.completion",
"usage": {
"completion_tokens": 12,
"prompt_tokens": 10,
"total_tokens": 22
}
}
このパラメータの説明は以下のとおりです。
- choices:返答一覧
choices[0].message.とアクセスすることで、返答メッセージが表示されます。content
- id:リクエストID
- model:使用したモデル
- object:使用したAPIオブジェクト
- usage
- completion_
tokens:返答のためのトークン数 - prompt_
tokens:与えられたプロンプト (「こんにちは!」)のトークン数 - total_
tokens: 合計トークン数
- completion_
Whisper APIの料金と対応ファイル
Whisper APIはOpenAIが公開している音声から文字起こしを行うためのAPIです。料金体系はわかりやすく、$0.
なお、ファイル等の制限は以下のようになっています。
- 対応言語:Afrikaans, Arabic, Armenian, Azerbaijani, Belarusian, Bosnian, Bulgarian, Catalan, Chinese, Croatian, Czech, Danish, Dutch, English, Estonian, Finnish, French, Galician, German, Greek, Hebrew, Hindi, Hungarian, Icelandic, Indonesian, Italian, Japanese, Kannada, Kazakh, Korean, Latvian, Lithuanian, Macedonian, Malay, Marathi, Maori, Nepali, Norwegian, Persian, Polish, Portuguese, Romanian, Russian, Serbian, Slovak, Slovenian, Spanish, Swahili, Swedish, Tagalog, Tamil, Thai, Turkish, Ukrainian, Urdu, Vietnamese, and Welsh
- ファイルサイズ:25MBまで
(25MB以上の場合は、分割処理が推奨されています) - ファイル形式:
mp3,mp4,mpeg,mpga,m4a,wav,webm
Whisper APIの使い方
ここで、Whisper APIの使い方をみておきます。
APIリクエスト
WhisperのAPIリクエストは、mp3等のファイルを開き、Audio.に渡してあげるだけです。
import openai
audio_file= open("/path/to/file/audio.mp3", "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file)
主要なリクエストパラメータは以下のとおりです。詳細はAPIドキュメントのAudio/
- file:ファイル
- 音声ファイルを渡します。
- model:モデルの指定
- 2023年4月1日時点では
whisper-1のみが利用可能になっています。
- 2023年4月1日時点では
- temperature:温度
- ChatGPTのtemperatureとほぼ同じです。0から1の間で設定でき、0に近づくほど決定論的になります。
- language:言語
- 渡した音声の言語をISO-639-1形式で指定できます。指定しなくても動きますが、指定すると精度と待ち時間が改善されます。
- response_
format:レスポンスフォーマット - verbose_
jsonにするとsegmentsが返却されます。
- verbose_
APIレスポンス
主要なレスポンスパラメータは以下のとおりです。
- text:文字起こし全体
- duration:秒数
- language:言語
- segments:発話一覧
- start:開始秒
- end:終了秒
- text:セグメントの文字起こし
「会議サマリー生成アプリ」を実装する
それでは今回作る
- 音源を作る
- ChatGPTで文章を作成してもらい、それをもとに収録します。
- Whisper APIで文字起こしにする
- ChatGPT APIでサマリーを作成する
- Hugging Face Spacesを作成する
- アプリケーションのUIを作る
- Hugging Face Spacesで公開する
なお、実装全体はGoogle Colabrateryに掲載しています。詳細はこちらをご覧ください。
1. 音源を作る
今回使う議事録も、ChatGPTに議論内容を作ってもらいましょう。
## 醤油 or ソース
A: ねえ、目玉焼きには醤油が一番だと思わない?
B: いや、僕はソース派だよ。目玉焼きにソースが合うと思う。
A: 醤油のほうがシンプルで美味しいと思うんだけどな。ソースはちょっと味が濃すぎる気がする。
B: でもソースの甘さと酸味が、卵の旨味を引き立てると思うんだよね。それに、ソースはバリエーションが豊富だし。
A: そうかもしれないけど、醤油は日本の伝統的な調味料だし、目玉焼きには合うと思うよ。それに、塩分が少なめでヘルシーだし。
B: 確かに醤油もいいかもしれないけど、ソースの風味が好きなんだよね。どっちも一長一短があると思うけど、僕はやっぱりソースが好きかな。
A: まあ、それぞれの好みだよね。どっちにしても、美味しい目玉焼きができればそれが一番だよ。
B: そうだね。美味しい目玉焼きのために、焼き方にもこだわりたいよね。焼き加減って大事だと思うんだ。
A: 確かに。卵の黄身がトロトロの状態が好きなんだけど、どうやって焼くといいんだろう?
B: 僕はフライパンに油を引いて、卵を割り入れたら、フタをして蒸し焼きにするんだ。そうすると、黄身がトロトロになるよ。
A: ああ、なるほど。それは美味しそうだね。僕も次回は試してみるよ。それに、醤油でもソースでも、トロトロの黄身には合うと思うしね。
B: うん、そうだね。トロトロの黄身には、どちらの調味料も合うと思うよ。結局は、自分の好みで楽しむのが一番だよね。
A: そうだね。色々な調味料や焼き方を試して、自分好みの目玉焼きを見つけるのも楽しいかもしれないね。
B: 本当にそうだね。これからもっと美味しい目玉焼きを作るために、いろんなレシピや調味料を試してみようよ。
OBS Studioを用いて会話を録音します。なお、ここではOBS Studioを用いてテキストを会話として変換する方法は割愛します。収録した音声はwavファイルとして保存しておきます[1]。
2. Whisper APIで文字起こしにする
作成したファイルをWhisper APIにかけます。
import openai
audio_file= open(meeting_file_path, "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file)
3. ChatGPT APIで文字起こしをサマリーにする
以下のようなプロンプトでサマリーにします。
import openai
openai.api_key = "sk-..." # APIキー
system_template = """会議の書き起こしが渡されます。
この会議のサマリーをMarkdown形式で作成してください。サマリーは、以下のような形式で書いてください。
- 会議の目的
- 会議の内容
- 会議の結果"""
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": system_template},
{"role": "user", "content": transcript.text}
]
)
response_text = completion.choices[0].message.content
print(response_text)
4. Hugging Face Spacesを作成する
Hugging Face SpacesはStreamlitやGradioなどを使って機械学習のデモアプリを簡単にリリースするための場所です。ベーシックなCPUリソースであれば無料なので、今回はこのサービスを使ってアプリケーションを公開してみます。
はじめて利用する場合には、Hugging Faceの登録ページにアクセスし、アカウントを作成します。

次に、新しくHugging Face Spaceを作成するページにアクセスし、スペースを作成します。ここではライセンスをapache-2.

5. アプリケーションのUIを作る
アプリケーションのUIを作りましょう。まず、作成したHugging Face Spaceのリポジトリをダウンロードします。
git clone https://huggingface.co/spaces/sakasegawa/whisper-gijiroku-summary
Gradioは機械学習のデモアプリ等を作るためのPython製のWebフレームワークです。TextboxコンポーネントやAudioコンポーネントを使ってUIを作ります。処理関数はcreate_に格納します。
import gradio as gr
import openai
def create_meeting_summary(openai_key, uploaded_audio):
openai.api_key = openai_key
transcript = openai.Audio.transcribe("whisper-1", open(uploaded_audio, "rb"))
system_template = """会議の書き起こしが渡されます。
この会議のサマリーをMarkdown形式で作成してください。サマリーは、以下のような形式で書いてください。
- 会議の目的
- 会議の内容
- 会議の結果"""
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": system_template},
{"role": "user", "content": transcript.text}
]
)
response_text = completion.choices[0].message.content
return response_text
inputs = [
gr.Textbox(lines=1, label="openai_key"),
gr.Audio(type="filepath", label="音声ファイルをアップロード")
]
outputs = gr.Textbox(label="会議サマリー")
app = gr.Interface(
fn=create_meeting_summary,
inputs=inputs,
outputs=outputs,
title="会議サマリー生成アプリ",
description="音声ファイルをアップロードして、会議のサマリーをMarkdown形式で作成します。"
)
app.launch(debug=True)
このコードをapp.として保存します。また、requirements.を作成して、以下のようにopenai-pythonのバージョンを指定しておきます。
openai==0.27.2
6. Hugging Face Spacesで公開する
最後にgit add、commit、pushをして、spaceにデプロイします。
git add . git commit -m 'Initial Commit' git push origin main
これで、OpenAIキーを入力させ、音声ファイルをアップロードしてサマリーを作成するという簡単なアプリケーションができました。次のページで試すことができます。
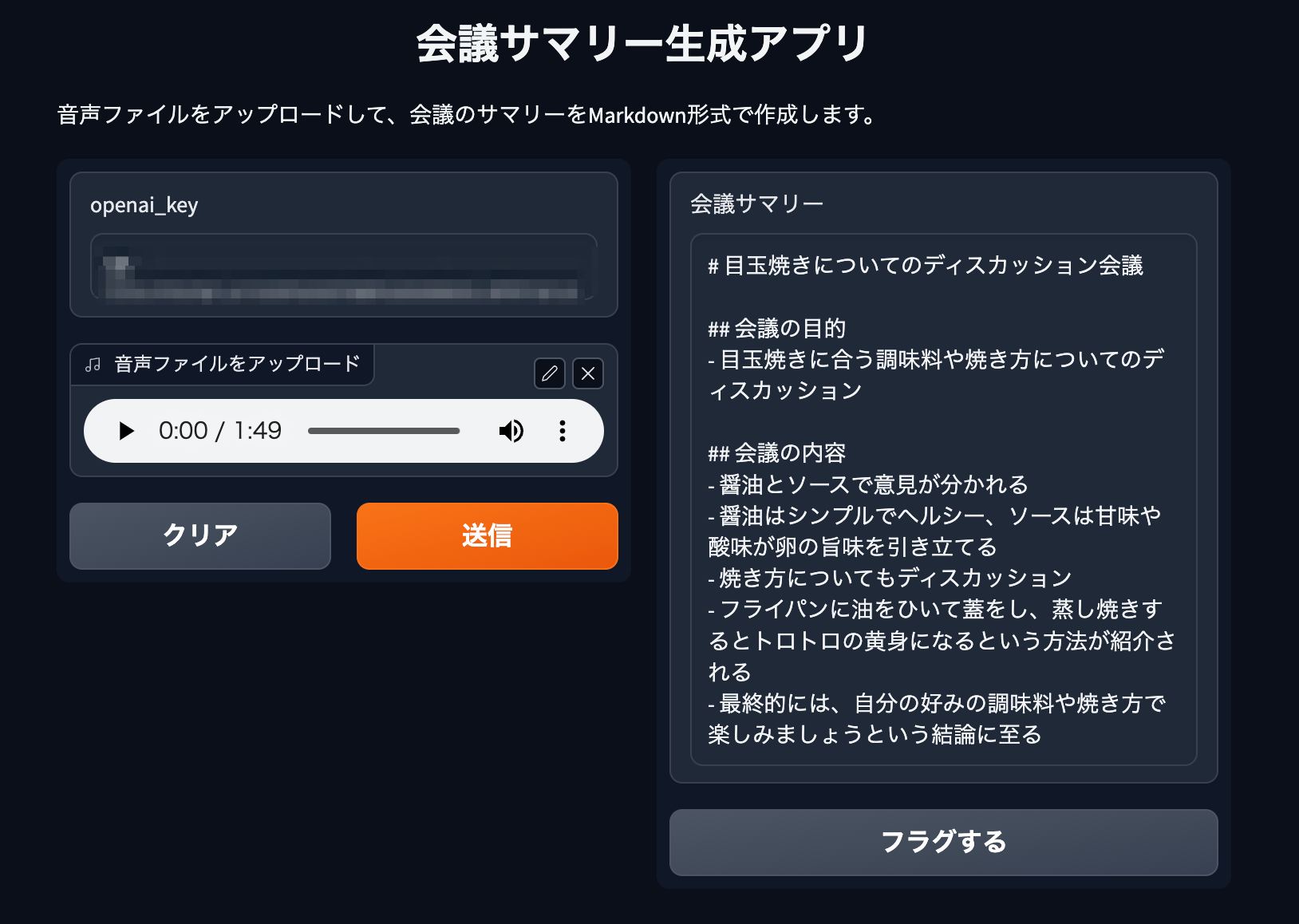
おわりに
今回はChatGPT APIとWhisper APIを使って議事録サマリー作成アプリを作り、Hugging Faceにデプロイしました。Hugging Face SpacesでGradioやStreamlitを使うと一瞬でアプリケーションがデプロイできます。もし興味があれば、ぜひ試してみてください。
補足情報[4月7日追記]
議事録文字起こしアプリに、話者分離機能を付ける方法が著者のQiitaページで公開されています。ぜひご覧ください。
ここから発展させて、話者をアサインして書き起こしにするアプリも作りました!
— 逆瀬川 (@gyakuse) April 6, 2023
話者埋め込みを使うとメッチャ面白いことできるのでゼヒ遊んでみてください!https:// t. https://co/ gizMQSLyyI t. pic.co/ tLf7fNbyPg twitter. com/ oE4XIHTJ82