誰でも使えるNo-code AIを開発しよう
近頃、文章生成AIや画像生成AIが世間を賑わしています。文章生成AI「ChatGPT」は、わずか2か月でユーザー数が1億人を超え、画像生成AIサービス「DreamStudio」は、有償でありながら2か月でユーザーを150万人以上獲得しています。これらのAIサービスが爆発的なトレンドとなった背景には、「専門家が構築する」といったイメージのある従来のAIとは違い、「誰でも簡単に使える」という点が大きいと言えます。
このように、AIをもっと身近に、ふつうの人が作ったりカスタマイズしたりできるようにする動きがあります。それが「No-code AI」です。
No-code AIとは、その名の通り、コードを書かずにAIモデルを作れる手法のことを言います。No-code AIでは、ドラッグ&ドロップやキー入力など簡単な操作でAIモデルを作ることができます。
例えば、Google社の「Teachable Machine」では、ブラウザにデータをアップロードするだけで、ボタン一つで画像認識や音声認識のAIを作ることができます。また、Microsoft社の「Power Apps」プラットフォームでは、生成AIを用いて、自然言語による会話によって「No-code」でAIアプリの開発ができます。
No-code AIは、すでに、国内・海外IT企業が導入に積極的です。技術調査を得意とするITR社の調査によると、2021年からの5年間で2倍にまで成長すると予測されています。今後さらに利用者は増えていくでしょう。
誰でも使えるAIを作るための障壁
誰でも使えるAIと聞くと「AIを作るPythonコードにGUIをくっつければいいのでは?」とまず考えたくなりますが(実際にそういうサービスもありますが)、実はそれだけでは誰でもAIを作れるようにはなりません。
実際に開発をしている方であれば分かると思いますが、AI開発の最大の障壁の一つが、学習データの準備にあるためです。質の良い学習データを大量に集めたうえで、その一つひとつに適切な正解ラベルをつける作業が、実用的な精度をもつAIの開発にはどうしても必要になるのです。
そして「質の良い」とか「適切な」といった感覚を得るには、やはり何度もAIを作って評価して修正して……という実践経験が不可欠になります。仮にPythonコードを1行も書く必要がなかったとしても、適切な学習データを大量に準備しなければならなかったら、とても「誰でも作成できる」とは言えません。
つまり、本当に使ってもらえるAIとなるにはふつうの会社の事務処理レベルの難易度のマウス、キーボード操作だけで、AIに認識させたいものや事象を指定できなければならないのです。これが No-code AIの基本的な考え方です。
この記事では私たちが実際に開発した、CNNを用いた映像認識のNo-code AIを題材にどのような点に気をつければ使いやすいAIができるかについて解説していきます。
カメラ画像認識とNo-code AI
学習データを準備せずにAIシステムを開発する現実的な方法の一つは、AIを適用する分野を前もってある程度しぼりこみ、その分野で必要とされる物体(人・車・特定の工場の製品など)を認識するCNNを事前に準備しておく方法です。この記事では、 この事前に学習されたCNNを「学習済AI」と呼ぶことにします。
私たちの開発したシステムでは、「カメラ映像から人の行動を認識するシステム」に適用分野をしぼり、「人間」および「人間の関節位置と姿勢」を認識する学習済AIを作成しました。その理由は、人間はまさに全世界で同じ形をしているため、いちど人を認識する学習済認識モデルを作ってしまえば様々な用途に応用できるからです。加えて、表情認識、属性(年齢や性別など)推定といった学習済AIも併用すれば、さらに応用可能なシーンを広げることができます。
ノート:「人間」および「人間の関節位置と姿勢」を認識する学習済AIの技術詳細については記事末尾にコラムとして取り上げていますので、興味のある方はご一読ください。
一方で、学習済AIをそのまま使うだけでは、人がいることを認識する、人の姿勢を認識するという決められた用途にしか使えません。認識対象をユーザーが指定できなければ「AIを作った」ことにはならないでしょう。認識する行動を自由に指定できること、そしてそれを簡単に設定できることが必要です。
例えば「病院内で転倒した人がいたらナースセンターに自動通報がいくシステム」を作るためには、カメラ映像から「転倒」という行動を認識するエンジンが必要です。あるいは、「小売店でお客様が店員をさがしていたら店員に知らせるシステム」では「キョロキョロ」という行動を、「駅のホームで長い時間ウロウロしている人がいたら駅員に通知するシステム」では「ウロウロ」という行動を認識するAIが必要です(図1)。
図1 No-code AIの活用シーン

こういったカスタマイズに毎回専門のAI技術者を呼ばないといけないということでは、なかなか実用的なシステムはつくれないでしょう。
そこで私たちは学習済AIとNo-codeデータ処理システムを連携させることで、ユーザーにとって使いやすくカスタマイズしやすい エンジンを作ることにしました。
No-codeデータ処理システムの作り方
次に、使えるNo-code AIの肝とも言うべきNo-codeデータ処理システムについて、私たちが実際に開発したシステムを例に詳しく解説します。
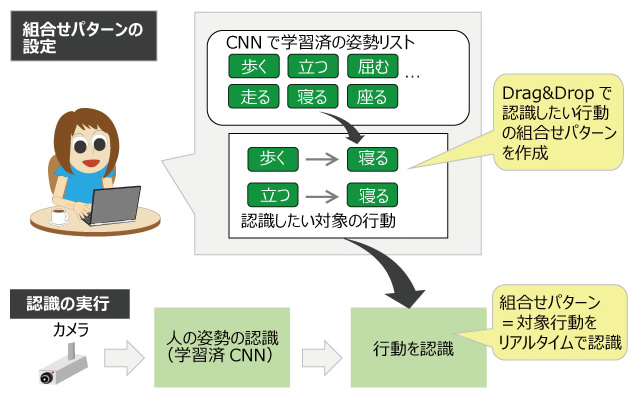
まず、私たちが作りたいと考えたユーザーインタフェースを、図2に示します。このインタフェースのポイントは以下の3点です。
- 学習済の人の姿勢をリストとして表示する。
- ユーザーは、認識したい行動を、その姿勢リストの組合せパターンとしてNo-codeで設定する。
- 実際に行動の認識をする際は、学習済AIの認識結果をリアルタイムで処理して設定された組合せパターン(=対象行動)を認識する。
図2 No-codeインタフェースによる組合せパターンの設定
こうしたインタフェースでユーザーがAIエンジンの作成やカスタマイズができるように、次のようなステップで学習済AIの認識結果を処理する手法を開発しました。
Step1:人の姿勢から、基本的な行動を認識
学習済AIで認識される「人間の関節位置と姿勢」をもとに、「歩く」「立つ」「手を上に上げる」などの基本的な行動を認識します。これには、人の姿勢情報を入力としたGraph Convolutional Networkを用いる手法[1]や、閾値を設定したルールで認識するルールベース手法があります。私たちのシステムでは、機械学習とルールベースの両方の手法を併用して精度を上げています。
Step2:複数の認識結果の空間的関係性を分析
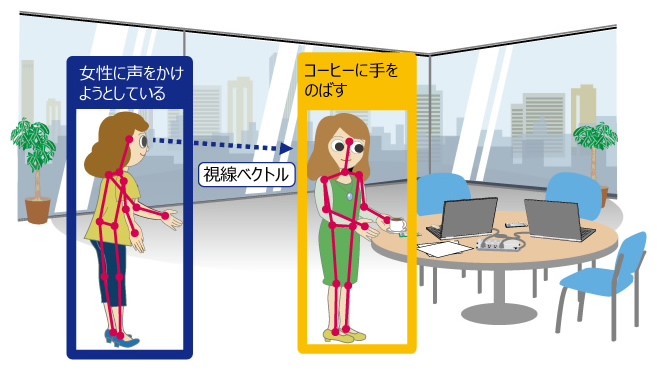
学習済AIの認識は個々の人の単位で行われるため、映像中の複数の人や、人以外の物の認識結果との位置関係は考慮されません。認識結果の空間的な位置関係をもとにした新たな行動を設定することで、認識できる行動の種類を増やします(図3)。
- 認識する行動の例
-
- 人の姿勢情報から視線ベクトルを推定し、他の人の矩形領域が視線ベクトルと重なっていると「人を見る」と認識。
- 人の手と位置と、認識された物体の矩形領域が重なっていると「物に触る」と認識。
図3 認識された空間的関係性
Step3:フレームごとの認識の時間的な分析と、行動の記号化
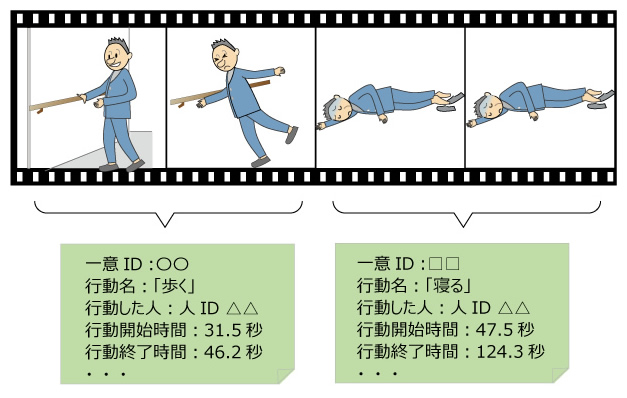
学習済AIの認識結果は、映像中の1フレームごとに時系列で逐次出力されます。またAIは認識誤りが必ず発生するため、あいまいな姿勢の映像では、1フレームごとに認識結果がばらばらと変わってしまう場合もあります。
一方で、ユーザーがマウス操作で行動の組合せを指定するというNo-codeインタフェースを実現するためには、学習済AIの認識結果をひとまとまりの行動として「記号化」する必要があります(図4)。1フレームごとにばらばらと出力されるデータから、「歩く」「立つ」などの記号化された1つの行動を得るために、私たちの開発したシステムでは次のような処理を行っています。
- ある一定の時間領域(Time window)を設定し、その時間内の認識結果を分析して学習済AIの認識誤りを補正。一定の時間 、連続した行動に変換。
- 変換された行動に時間情報や人のIDなどの付属情報をつけて記号化。
図4 認識された行動の記号化
Step4:記号化された行動と、ユーザーが設定する組合せパターンとの照合
Step3で映像からの認識結果を記号化することで、図2のインタフェースでユーザーが設定する組合せパターンとの照合が可能になります。例えば、図4にある「歩く」→「寝る」の変化であれば、
- 同じIDの人が「歩く」と「寝る」を実行
- 「歩く」の行動の終了時刻より「寝る」の行動の開始時刻が遅い
の条件が満たされているかを随時確認することで、リアルタイムで組合せパターンを確認できます。
この例のように順番に行動する「シーケンス」パターンの他、同時に行動する「AND」パターン、どちらかが発生すれば成立とする「OR」パターンなどに対応すると、さらに柔軟なスクリプトが記述できるようになり、表現できる幅が広がります。
まとめると、次のような処理になります。
- 学習済AIの認識結果から、フレームごとの行動を認識する。
- 認識された位置関係などから、他の人や物と関係する行動も認識する。
- 一定の時間領域(Time window)を設定してフレームごとの結果を分析することで、行動を記号化する。
- ユーザーが設定した組合せパターンと記号化された行動を照合する。
私たちはこのような手法で、ユーザーがNo-codeでAIを開発できるシステムを構築しました。
コンポジット化により様々なNo-code AIを簡単に構築する
新たなAIシステムを必要としている領域は無数にあります。その1つひとつはNo-code AIとして手軽に作ることができたとしても、それぞれをゼロから作り始めるとすると、すべての需要に応えるのはやはり大変です。
様々な用途のNo-code AIを素早く構築するためには、ゼロから作り始めるのではなく、既存のパーツを使いまわすことが有効です。過去に作ったAIモデルや、設計済みの行動の組合せパターンを蓄えておき、必要に応じて組み替えながら使うことで、幅広い応用領域に対応できるようになります。
このような考え方は、近年、コンポジットAIとして注目されており(図5)、SASの「Viya」やIBMの「Neurosymbolic AI」などの実装例も出てきました。
図5 コンポジットAIのイメージ
私たちは、コンポジットAIの考え方に基づいて、多くのNo-code AIを素早く構築するためプラットフォームも作りました。この記事の後半では、このプラットフォーム上で開発したいくつかのユースケースを紹介します。
ユースケース1:製造分野
1つ目のユースケースとして、多くの先行事例があり、ニーズも多い製造分野での適用について考えてみます。製造分野では、工場内で作業者の行動を把握し、ムリ・ムダ・ムラを特定することで、製造現場のDXを実現する活用方法が想定されます。
そこで、これまでに紹介したNo-code AIの枠組みを使い、実際に製造分野へ適用してみましょう。以下の順番に沿って設計します。
- Step1:AIシステム構築の内容を目的とともに検討
-
今回は「各個人ごとの作業効率をAIで判定するため、作業員が溶接をしている時間帯を自動で計測する」とします。
- Step2:行動が、どのような人の動作の組み合わせから成り立つかを特定
-
今回は、特定の場所でしゃがんで作業している人を、溶接しているとみなすことにします。
- Step3:組合せパターンを設定
-
- 組合せパターン:「溶接場所」で、「腕を下に向け」「顔を下に向け」「しゃがんでいる」が並列に発生している
図6に、組合せパターンと認識対象の行動をNo-codeインタフェースで指定した例を示します。このGUIの右上には事前に定義した動作パターン例が並んでいます。ここから下のルール欄にパターンをドラッグ&ドロップして、組合せパターンを作成します。この例では、「溶接場所にいる」「腕を下に向けている」「顔を下に向けている」「しゃがんでいる」の4つのパターンを同じ枠内に入れて、AND(同時に行動している)の関係性を定義しています。この組合せパターンをまとめて「溶接している」行動として命名します。
図6 No-code AIインタフェースによる溶接認識対象の行動の設定
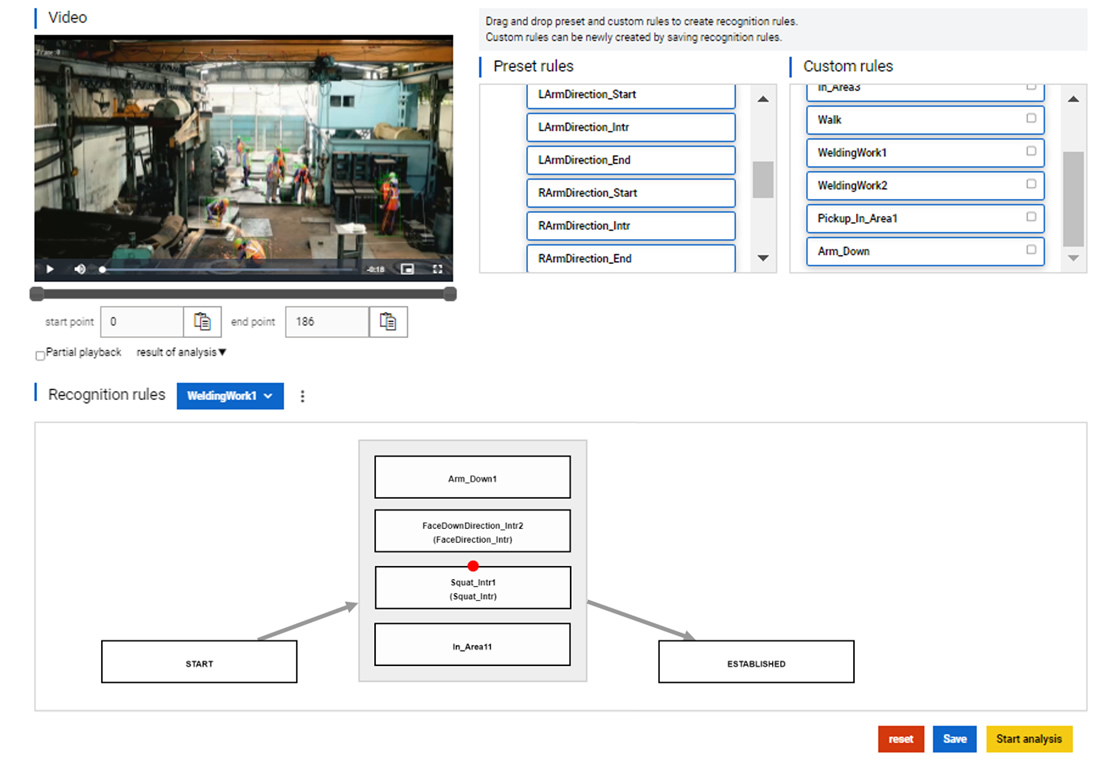
- Step4:認識対象の行動を検知し、結果を可視化
-
図7は、実際のカメラ映像に対して「溶接をしている」行動を検知してみた結果です。人の姿勢を認識した結果が、人の上に重畳表示されています。さらに人の体の向きや顔の向きは青いビームとして表示されています。
あらかじめ溶接場所として2か所を設定しておきます。すると、その場所で先ほどのパターンを行っている人のみ、溶接認識対象の行動が検知されています(「WeldingWork1」「WeldingWork2」)。
最後に、青枠が表示された時間帯を棒グラフなどで可視化します。これにより、「作業員が溶接をしている時間帯を自動で計測する」システムがNo-codeで構築できました。
図7 溶接作業の検知結果

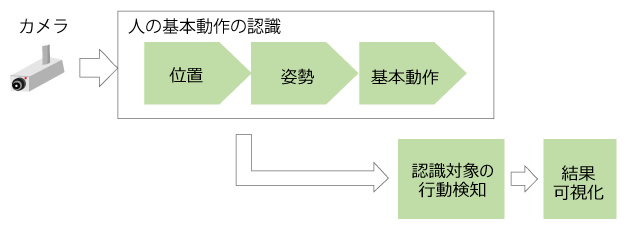
このシステムは図8のような処理の流れになっています。カメラから入力された映像に対し、あらかじめ学習されたモデルを使って人の位置・姿勢を推定し、基本動作を認識します。それらの情報はパターンによる認識対象の行動検知に使われ、最終的に結果が表示されます。
図8 No-code AIの処理の流れ
このシステムを実際に作って運用してみると、もう少し機能拡張をしたくなるかもしれません。例えば、作業員ごとの作業のムラを把握するために、作業員ごとに作業時間を計測することが考えられます。しかし、このシステムでは誰が、という情報が欠落しているため、シーン全体としての作業時間しか計測できません。
そこで、先ほどご紹介したコンポジットAIの考え方を活用して、「作業員ごとに作業時間を計測する」という形に機能を拡張してみます。作業員Aさんの作業時間を計測するためには、Step3で次のようなパターンと認識対象の行動を設定する必要があります。
- 組合せパターン:「溶接場所」で、「作業員Aさん」が、「腕を下に向け」「顔を下に向け」「しゃがんでいる」が並列に発生している
すると、認識対象の行動検知の前段にAさんをAさんと特定する処理が必要になることが分かります。
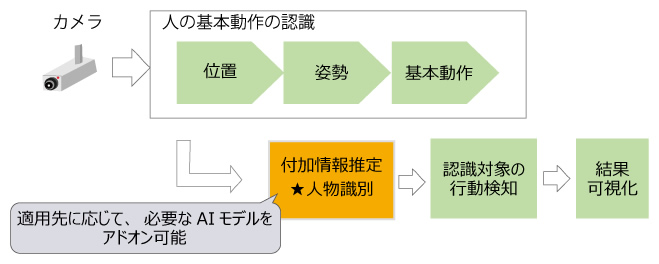
コンポジットAIであれば、機能拡張に必要な情報(付加情報)を求めるためのAIをアドオン的に付加することが可能です。図9に、今回の機能拡張に対応した処理の流れを示します。緑色の部分は図8からの流用部分です。この人の基本動作の認識と認識対象の行動検知の間に、付加情報推定部分として人物識別AIエンジンを追加します(オレンジ色)。
図9 製造分野での機能拡張に対応した処理の流れ
付加情報を求めるためのAIは複数存在しますが、No-code AIの枠組みにとって最適なAIを選択する必要があります。今回私たちは、服の腕の部分の色に応じて人物を特定するAIを作成しました。あらかじめ服の腕の部分の色と作業者ナンバーを対応付けておきます。そしてカメラから画像が得られるごとに、人の姿勢情報から服の腕の部分の画像上の位置を特定し、その周辺の色分布から作業者を特定します。
図10は、図7と同じ映像に対し、特定の作業者のみの溶接作業を検知した結果の例です。手前の「WeldingWork1」の作業者のみ、作業者が特定されて黄色の枠で囲まれていることが分かります。
図10 特定の作業員の溶接作業の検知結果

ここで、単なる組み合わせであれば、どのようなAIを選択してもよいと思うかもしれません。しかし、個々のAIは大抵の場合汎用的に作られているため、実用に耐えうる精度を得られないことがほとんどです。
そこで、うまく人の基本動作の情報を活用することで、精度を上げることを考えます。コンポジットAIでは、組み合わせることで相乗効果が生まれるAI同士をうまく選択することがポイントになります。
ユースケース2:小売分野
次に2つ目のユースケースとして、小売分野への適用を考えてみます。小売分野では、店舗内で来店客の行動を把握し、売上向上の施策を決定するために活用することが想定されます。製造分野と同様に、次の順番に沿って設計します。
- Step1:AIシステム構築の内容を目的とともに検討
- 今回は「棚割りの改善や各種施策の効果計測のため、来店客が商品棚に手伸ばしをする傾向を可視化する」とします。
- Step2:行動が、どのような人の動作の組み合わせから成り立つかを特定
- 今回は、商品棚の商品を購入する行動を検知します。
- Step3:組合せパターンを設定
-
- 組合せパターン:「商品棚の前」で、「手を伸ばし」、「商品を取り」、立ち去る
- Step4:購入された商品の傾向を可視化する
- このステップに従い、実際のカメラ映像に対して可視化をした例を図11に示します。ここでは、来店客が手を伸ばした頻度をヒートマップとして表示しています。
図11 手伸ばし行動の可視化例

小売のケースについても、実際に運用を始めると様々な要望が出てくることが想定されます。例えば、次のようなものです。
- きめ細かい傾向を把握するため、来店客の大まかな年代や性別を特定したい
具体的にどの商品がどの程度購入されたのかを特定したいこれらに対しても、前述のコンポジットAIの枠組みを用いることで実現できます。
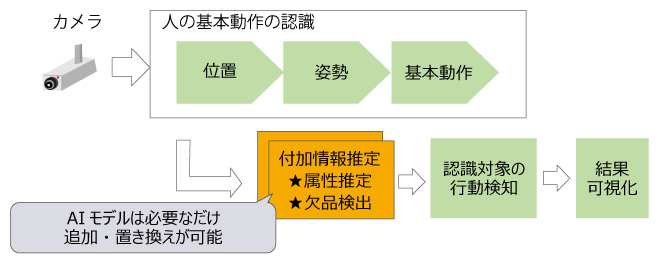
図12に、小売の場合での機能拡張に対応した処理の流れを示します。先ほどの製造の場合の流れと比べると、付加情報推定の部分が「年代や性別を判定する属性推定AIエンジン」や「購入量を推定する欠品検出AIエンジン」に置き換わっています。このような構造にすることで、全体としてはNo-code AIの枠組みを継承しつつ、小売という適用先に最適な形でカスタマイズしながら、よりきめ細かい推定ができるようになります。
また、属性推定は「人の歩き方や動作を使う」、欠品検出は「人の手を伸ばした場所の情報を使う」など、人の基本動作の結果を考慮して付加情報を推定することで、精度を向上させることができます。
図12 小売分野におけるNo-code AIの処理の流れ
まとめ
No-code AIの作り方について、基本的な枠組みと、実際の適用シーンに即した具体例で説明しました。AIの民主化が進むにつれ、No-code AIやコンポジットAIの考え方がより重要になると考えています。この記事が皆様のNo-code AI開発の一助になることを願っています。
最後に自画自賛なのですが、この記事でご紹介した私たちの研究開発成果が、最近「Fujitsu Kozuchi (code name) - Fujitsu AI Platform」として発表されました! あわせてご覧いただけましたら幸いです。
参考文献:






