



ちょっと前に新年の挨拶をしたばかりと思っていたら、いつの間にか1年の1/
歳のせいか、最近は時の流れがますます早くなってくると共に、残された時間の短さも実感するようになりました。この話題
GStreamerを使った録音
GStreamerの使い方には多少悩んだものの、前回紹介したコマンドラインで聴き逃しサービスの音声データをダウンロードできたので、このコマンドラインを以前紹介したJSONデータを解析するスクリプトに組み込んでみます。今回のスクリプトは音声データもダウンロードするので"get_
$ cat -n get_ondemand.py
1 #!/usr/bin/python
2 import sys,pprint,json,requests
3 query = sys.argv[1].split("=")[1] # "p=0442_01_3834250"の"0442_01_3834250"を取り出す
4 q = []
5 q = query.split("_")
6
7 base_url = 'https://www.nhk.or.jp/radioondemand/json/'
8 bangumi_id = "{}/bangumi_{}_{}.json".format(q[0], q[0], q[1])
9 url = base_url + bangumi_id
10
11 response = requests.get(url)
12 prog_info = json.loads(response.text)
13
14 for i in prog_info['main']['detail_list'] :
15 for j in i['file_list']:
16 if j['file_id'] == q[2] :
17 URL = j['file_name']
18 title = j['file_title'].replace('\u3000','_')
19 break
20 outfile = title + '.mp4'
21
22 import subprocess
23 cmd = ['gst-launch-1.0',
24 'curlhttpsrc','location=',URL,
25 '!','hlsdemux',
26 '!','decodebin',
27 '!','audioconvert',
28 '!','faac',
29 '!','mp4mux',
30 '!','filesink','location=',outfile]
31 print(cmd)
32 subprocess.run(cmd)
33
スクリプトの20行目までは先に紹介した聴き逃しサービスのプレイヤーへのリンクからその番組のJSONデータを入手する処理、23行目から30行目がGStreamerを使って指定したURLから音声データをファイル'ls -l'としたい場合も['ls','-l']のように指定する必要があります。GStreamerでは各コマンドをつなぐ'!'
さて、それでは実際の動作を確認してみましょう。このスクリプトでは、聴き逃しサービスのページにあるプレイヤーへのリンクに記された"p=0308_
$ ./get_ondemand.py 'p=0308_01_3851097'
['gst-launch-1.0', 'curlhttpsrc', 'location=', 'https://vod-stream.nhk.jp/radioondemand/r/308/s/stream_308_5c7083f5fb\
737e7b7e8d74fe1c1b64de/index.m3u8', '!', 'hlsdemux', '!', 'decodebin', '!', 'audioconvert', '!', 'faac', '!', 'mp4mux',\
'!', 'filesink', 'location=', '名曲スケッチ「ロンドンデリーの歌」_「ケンタッキーのわが家」.mp4']
パイプラインを一時停止 (PAUSED) にしています...
Pipeline is PREROLLING ...
Got context from element 'souphttpsrc1': gst.soup.session=context, session=(SoupSession)NULL, force=(boolean)false;
Pipeline is PREROLLED ...
パイプラインを再生中 (PLAYING) にしています...
....
Freeing pipeline ...
$ file 名曲スケッチ「ロンドンデリーの歌」_「ケンタッキーのわが家」.mp4
名曲スケッチ「ロンドンデリーの歌」_「ケンタッキーのわが家」.mp4: ISO Media, MP4 v2 [ISO 14496-14]
ちゃんとダウンロードしてMP4形式で保存できたようです。保存したファイルはaudaciousやsmplayerといった各種メディアプレイヤーで問題なく再生できました。
番組情報の追加
新しいスクリプトであれこれ聴き逃しサービスの番組をダウンロードしているうち、ちょっと物足りなく感じるようになりました。というのも、かって
以前に書いた
調べていった過程は省略して結論だけ述べると、番組情報のJSONデータの中の"aa_
18 title = j['file_title'].replace('\u3000','_')
19 (ch, area) = j['aa_vinfo2'].split(',')
20 onair_id = j['aa_vinfo3']
21 break
22 outfile = title + '.mp4'
23
24 info_url = "https://api.nhk.or.jp/r5/pg2/info/4/{}/{}/{}.json".format(area, ch, onair_id)
25 response = requests.get(info_url)
26 bangumi_info = json.loads(response.text)
27 pprint.pprint(bangumi_info)
28
29 sys.exit()
19~20行目でチャンネルと地域ID、放送履歴IDを設定し、24行目のURLを構成、そこからJSONデータを読み込んで、27行目で出力、という流れです。
さて、この改造したコードで適当なリンクを処理してみます。区別のため、改造したコードは"get_
$ ./get_ondemand2.py 'p=0444_01_3851974'
{'list': {'r3': [{'act': '逢地真理子',
'area': {'id': '130', 'name': '東京'},
'ch': {'id': '', 'name': '', 'station': '首都圏'},
'change': [],
'codes': {'code': '4776229', 'split1': ['4776', '229']},
'content': '',
...
'lastupdate': '2023-03-24T15:22:33+09:00',
'music': '「亜麻色の髪の乙女」\n'
'ヴィレッジ・シンガーズ\n'
'(2分58秒)\n'
'<ソニー\u3000SRCL3917>\n'
'\n'
'「グッド・ナイト・ベイビー」\n'
'ザ・キングトーンズ\n'
...
'start_time': '2023-04-01T12:30:00+09:00',
'subtitle': '逢地真理子',
'title': '歌謡スクランブル\u3000選\u3000▽プレイバック1960年代(6)',
'url': {'nod': '',
'nod_portal': '',
'pc': 'https://www.nhk.jp/p/kayou/rs/N8M9ZPVK4L/',
'short': 'https://nhk.jp/P444'}}]}}
思ったよりも大量の情報が返ってきました。どのような情報を記録すべきかをいくつかの番組を比べながら確認したところ、
MP3ファイルのID3タグ同様、MP4ファイルにもメタデータとしてアーティスト名やアルバム名、楽曲名などを書き込めるので、これらの情報はそこに記録するのがよさそうです。もっとも、MP4の仕様としてilstアトムと呼ばれる領域にさまざまなデータを書き込めるようになってはいるものの、どのようなフィールド名
"\xa9"は
iTunesが使っているフィールド名は音楽CD等のトラックごとの楽曲情報を記録するように設計されているため、今回のような番組情報にどう適用するかは悩ましいものの、アルバム名を示す \xa9albを
記録したい情報をまとめるために"tag{}"という辞書型の配列を用意して、そこにJSONデータから得られた情報を保存するようスクリプトを修正します。
12 prog_info = json.loads(response.text)
13
14 tags = {}
15 tags['album'] = prog_info['main']['program_name']
16 for i in prog_info['main']['detail_list'] :
17 for j in i['file_list']:
18 if j['file_id'] == q[2] :
19 URL = j['file_name']
20 title = j['file_title'].replace('\u3000','_')
21 tags['title'] = title
22 tags['date'] = j['onair_date']
23 (ch, area) = j['aa_vinfo2'].split(',')
24 onair_id = j['aa_vinfo3']
25 break
26 outfile = title + '.mp4'
27
28 info_url = "https://api.nhk.or.jp/r5/pg2/info/4/{}/{}/{}.json".format(area, ch, onair_id)
29 response = requests.get(info_url)
30 bangumi_info = json.loads(response.text)
31 tmp = bangumi_info['list'][ch]
32 tags['comment'] = tmp[0]['content'] + '\n' + tmp[0]['act'] + '\n' + tmp[0]['music']
デバッグ用に "pprint.
$ ./get_ondemand2.py 'p=0933_01_3852397'
{'album': 'クラシックカフェ',
'comment': '\n'
'貞平麻衣子\n'
'「喜歌劇「軽騎兵」序曲」\n'
'スッペ:作曲\n'
'(管弦楽)ニューヨーク・フィルハーモニック、(指揮)レナード・バーンスタイン\n'
'(7分05秒)\n'
'<CBS/SONY\u3000CSCR-8164>\n'
'\n'
...
'date': '4月3日(月)午後2:00放送',
'title': 'クラシックカフェ_スッペの喜歌劇「軽騎兵」序曲'}
PythonでMP4ファイルを操作するには"mutagen"モジュールが便利です。mutagenはPyPIに登録されているので、"# pip install mutagen"でインストールできます。
mutagenでMP4のメタデータを編集するには、MP4ファイルをmutagenオブジェクトと結びつけ、あらかじめ用意されているフィールド用のキーに値を書き込むだけです。先のスクリプトの最後にこのような処理を追加しました。
46 from mutagen.mp4 import MP4
47 dtfile = MP4(outfile)
48 dtfile['\xa9alb'] = tags['album']
49 dtfile['\xa9nam'] = tags['title']
50 dtfile['\xa9day'] = tags['date']
51 dtfile['\xa9cmt'] = tags['comment']
52 dtfile.save()
それでは動作を確認してみます。コマンドラインからMP4のメタデータを調べるのはmutagenモジュールと共にインストールされるmutagen-inspectコマンドが便利です。
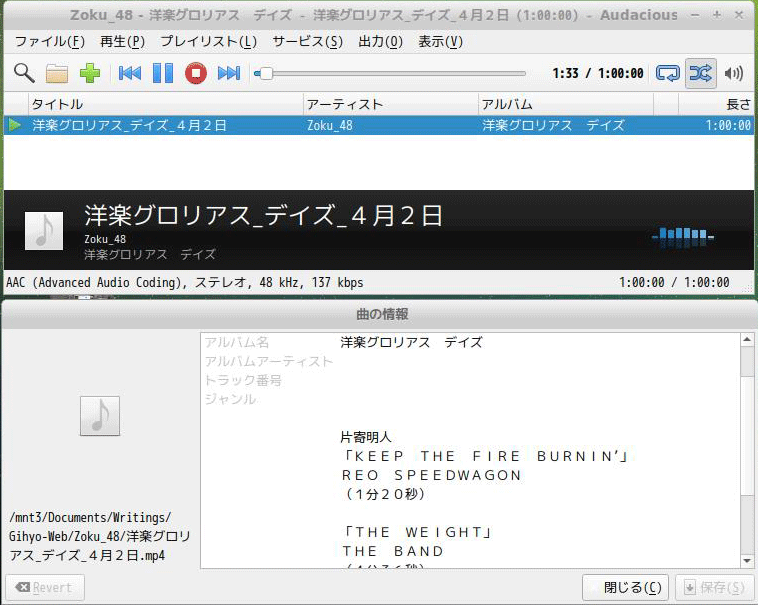
$ ./get_ondemand2.py 'p=3433_01_3852199' ['gst-launch-1.0', 'curlhttpsrc', 'location=', 'https://vod-stream.nhk.jp/radioondemand/r/3433/s/stream_3433_46748aec\ 4a04540010291e98941b4dc3/index.m3u8', '!', 'hlsdemux', '!', 'decodebin', '!', 'audioconvert', '!', 'faac', '!', 'mp4mux',\ '!', 'filesink', 'location=', '洋楽グロリアス_デイズ_4月2日.mp4'] ... $ mutagen-inspect 洋楽グロリアス_デイズ_4月2日.mp4 -- 洋楽グロリアス_デイズ_4月2日.mp4 - MPEG-4 audio (AAC LC), 3600.06 seconds, 128000 bps (audio/mp4) ©alb=洋楽グロリアス デイズ ©cmt= 片寄明人 「KEEP THE FIRE BURNIN’」 REO SPEEDWAGON (1分20秒) ... ©day=4月2日(日)午後4:00放送 ©nam=洋楽グロリアス_デイズ_4月2日
番組情報も正しく書き込まれており、デスクトップで愛用しているaudaciousでも
今回のスクリプトはエラー処理等を考慮しない骨組だけなので、もう少しPythonらしく書き直した方が将来見直した時にも便利とは思うものの、とりあえず50行ほどのコードで必要な処理が実現できたことに満足しておきましょう。
NHKは公式に番組情報APIを公開して、ラジオやテレビの番組情報を提供しています。しかし、このAPIを利用するにはユーザ登録してAPIキーを得る必要があり、1日の利用回数にも制限があります。
一方、今回使ったURLはJavaScriptの専用プレイヤーが利用する隠しAPIのような位置づけで、APIキー無しでも利用できます。もっとも、専用プレイヤー用の非公開APIなので、プレイヤーのバージョンアップに伴ない、暗黙のうちに仕様やURLが変更されることがあり、長期的・