



寺田 学
アプリケーケーションが利用するメモリの使用状況を把握したいことがあると思います。今回の記事ではPythonコードが利用するメモリの使用状況の把握を行いたいと思います。
この記事は、2023年4月にアメリカで行われたPyCon US 2023のトーク
メモリプロファイラ
状況把握の難しさ
Pythonのコードが実行されるとオブジェクトが生成されます。それらのオブジェクトがどれだけメモリを利用しているのかを把握するツールがメモリプロファイラです。Pythonのコードが実行され、それらの命令が必要なメモリをOSに対して要求し、メモリを確保します。
Pythonにおいては必要な時にメモリを確保し、不要になったら
アプリケーション実行時に大量のメモリを消費することがあります。たとえばデータ分析において大量データの加工を行う際に、メモリエラーで処理が途中で止まることがあります。このような場合、メモリの状況を把握し適切に対処を行う必要があります。しかし、Pythonではメモリ確保を自動的に行っているため状況が把握しにくいです。そのためにメモリプロファイラを使って状況把握をします。
プロファイリングの手法
プロファイリングにはいくつかの手法があります。そのうちの1つに
トレーシングの手法では実行負荷や余分な命令が増えてしまいますが、極力負荷を減らしたツールとして
なお、サンプリングの手法を用いるライブラリとして有名なものに
Memrayとは
Memrayは、もともとブルームバーグ社内で使うツールとして開発が始まり、2022年4月にオープンソース化されたツールです。1年前のPyCon US 2022のライトニングトーク
Memrayは、LinuxとmacOS上で動作するツールです。残念ながらWindows上では動作しません
Memrayの概要は以下のとおりです。
| 項目 | 内容 |
|---|---|
| ライブラリ名 | memray |
| プロファイリング手法 | トレーシング |
| 対応OS | Linux / macOS |
| Python バージョン | 3. |
| 公式サイト | https:// |
| PyPI | https:// |
| GitHub | https:// |
| 執筆時点のバージョン | 1. |

インストール方法は以下のとおりです。
$ pip install memray
Memrayの基本的な使い方
Memrayがインストールされていると、memrayコマンドが使えるようになります。
プロファイリング対象のスクリプトをmemrayから実行すると、スクリプトを実行した同じフォルダに実行時のプロファイリング結果がバイナリ形式でファイルに保存されます。
プロファイルの実行
サンプルのPythonスクリプトとしてsample.を準備します。以下のコードでは、状態表示をわかりやすくするために1秒間の待ちを入れています。実行内容は、リスト内包表記で要素数が約1億個のリストを生成しています。
import time
time.sleep(1) # 状態表示をわかりやすくするために1秒待つ
result = [1 for _ in range(1024 * 1024 * 1024)] # リスト内包表記で要素数が約1億個のリストを生成
time.sleep(1)
del result # 変数を削除
time.sleep(1)
このPythonスクリプトを実行する例を見てみます。
$ memray run sample.py
実行すると以下のようなメッセージが表示され、結果が保存されているファイル名memray-...)flamegraphという形式での出力方法も示されます。
[memray] Successfully generated profile results. You can now generate reports from the stored allocation records. Some example commands to generate reports: (省略)/venv/bin/python3 -m memray flamegraph memray-sample.py.172322.bin
結果をHTMLで出力
結果が出力されたファイルをflamegraph形式のHTMLに変換して出力することができます。
$ memray flamegraph 結果ファイル名
プロファイル実行時にmemray-sample.というファイル名が出力されましたので、以下のコマンドで変換します。
$ memray flamegraph memray-sample.py.172322.bin Wrote memray-flamegraph-sample.py.172322.html
同じフォルダにHTMLファイル
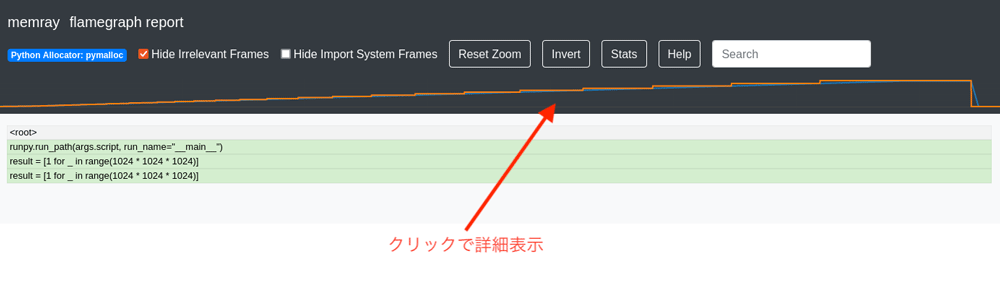
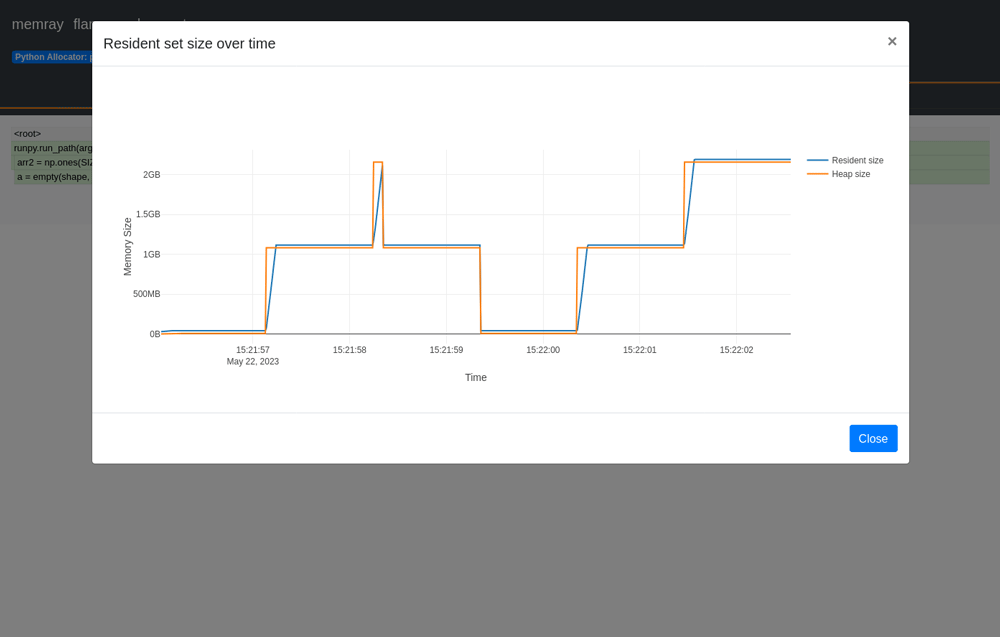
メモリの状態をもっと細かく見るには、上部のグラフをクリックしポップアップ画面で詳細が見れます。
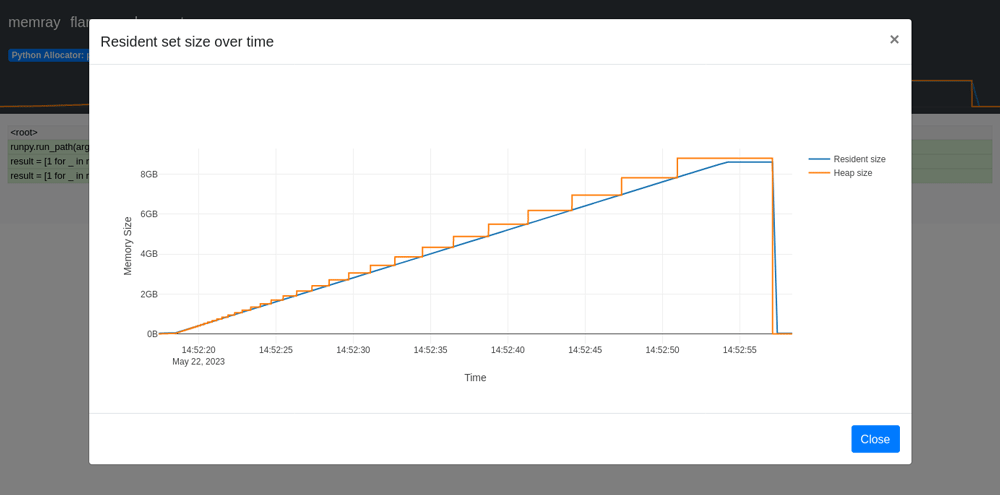
段階的にメモリ確保されていることがわかり、最終的に8GB程度のメモリが使われています。このグラフのオレンジ色の線がHeapメモリサイズで、青色の線がResidentメモリサイズです。Heapメモリはアプリケーションが確保しているサイズで、Residentメモリは物理メモリ上に確保されたサイズです。
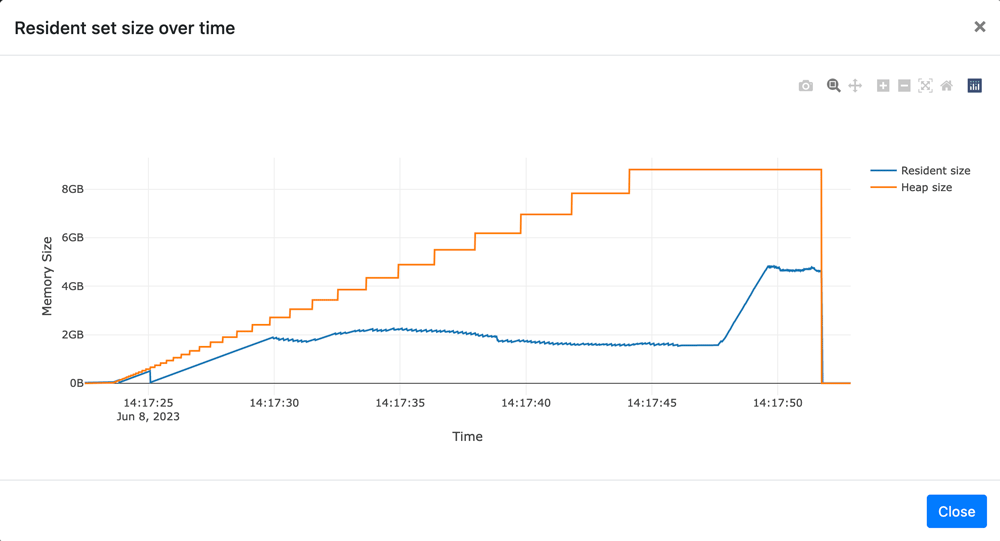
物理メモリに余裕がない場合は、以下のようにResidentメモリのグラフが、最初のサンプルとは大きく違う形となります。
スクリプト実行中の状態を見る
Memrayには、liveモードがあり、スクリプト実行中にコンソールにメモリの状況を出力する方法が2種類用意されています。
- 実行したコンソールに直接状況を出力する方法
- 実行したコンソールとは別に出力結果だけをライブで出力する方法
1つ目の、コンソールに状況を出力するには以下のように実行します。
$ memray run --live sample.py
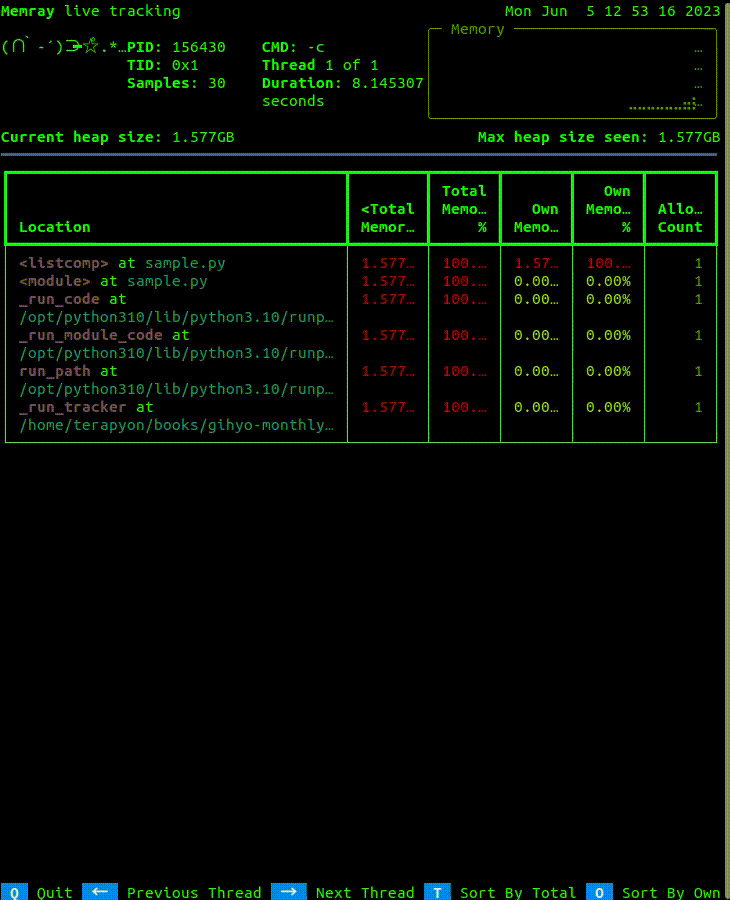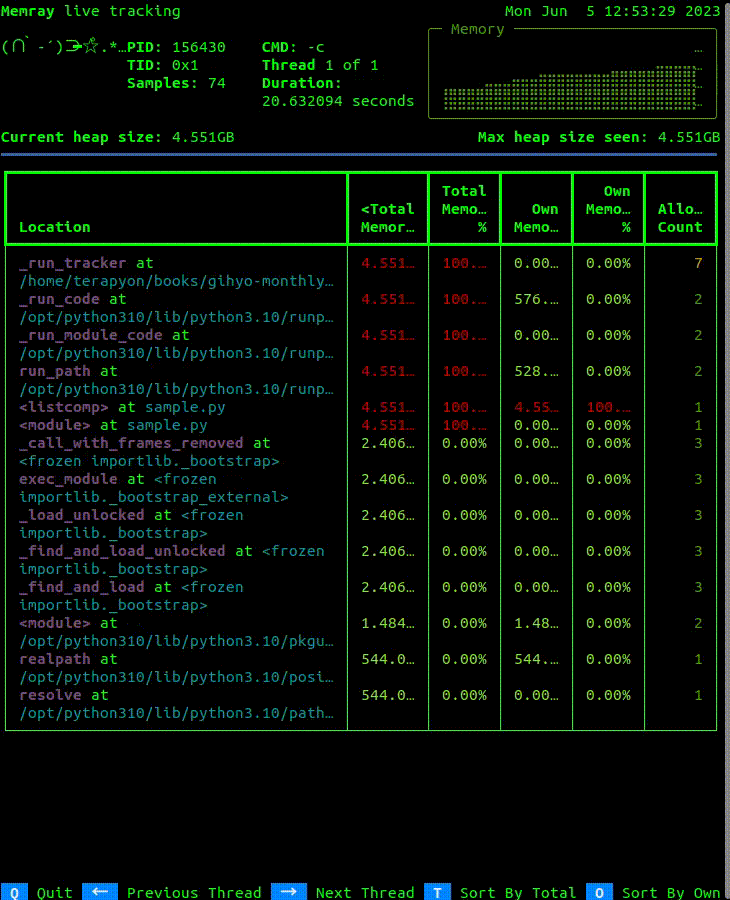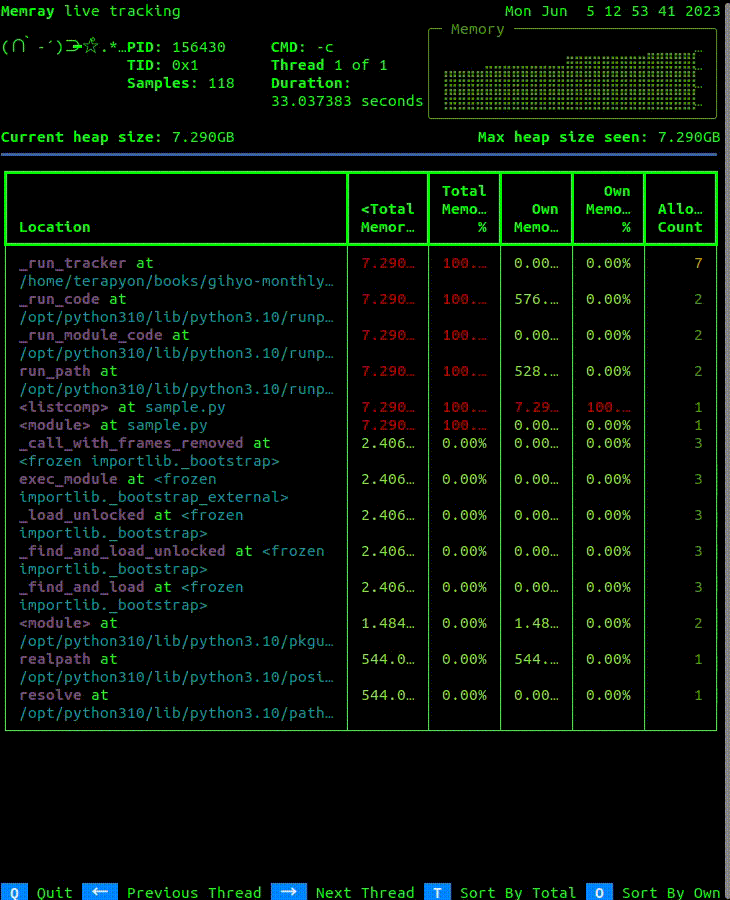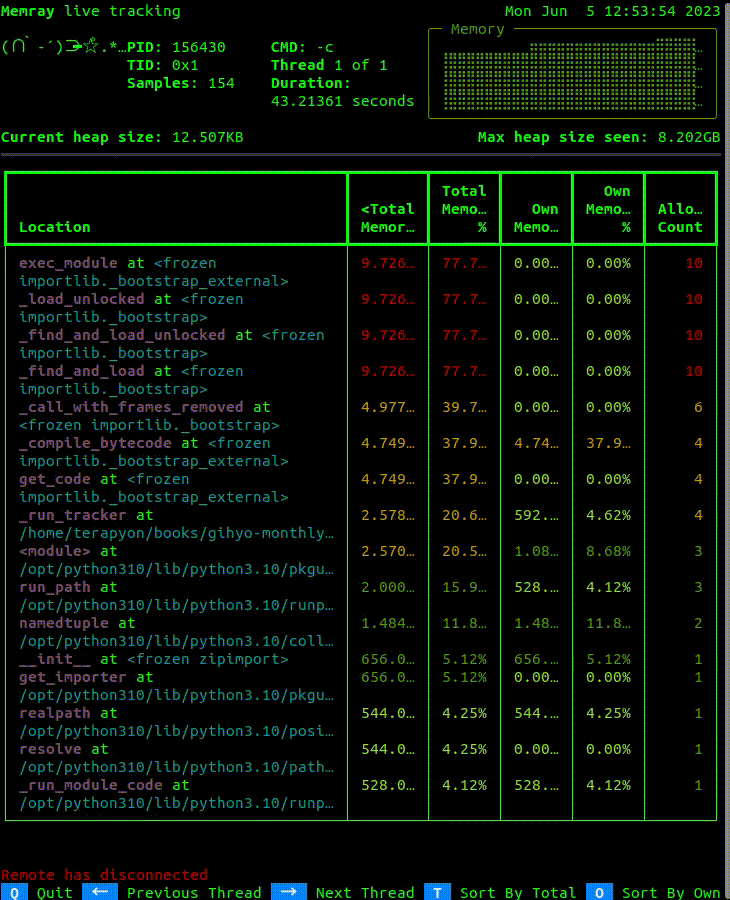
画面の左上部にはPIDや経過時間などの概要が表示され、右上部は現在のメモリ確保の状況がグラフのように表示されます。その下には、現在のヒープメモリサイズと処理中の最大ヒープメモリサイズが表示されます。さらに、表形式でメモリ確保されている場所・
liveモードを終了するには、qを入力します。
2つ目の別のコンソールに出力する場合は以下のように実行し、実行時に出力されるportを使って、別のコンソールから状況を確認します。スクリプトの途中経過をコンソールに出力している場合に便利な機能です。
$ memray run --live-remote sample.py
別のコンソールで以下のコマンドを実行
$ memray live <port>
1つ目の--liveを使ったときと同様に出力が出力されます。なお、--live-remoteでスクリプトを起動した場合は、別のコンソールでのプロファイル表示が行われるまでスクリプトの実行待ち状態となり、スクリプトの開始時からの状況が確認できます。
Pythonのリストオブジェクトの状況
ここでは、Pythonのリスト生成方法の違いによるメモリ確保の状況の違いを見ていきます。
以下のPythonスクリプトを準備し、メモリプロファイラを実行し、どの状況でどのようなメモリ確保が行われているかを確認します。このコードでは、3つの方法でリストを生成しています。どれも、リスト型で1を約10億個確保して削除する実行例です。最初にリスト内包表記を使い、次にappendメソッドを使い、最後にリストの掛け算でリストを生成しています。
import time
SIZE = 1024 * 1024 * 1024 # 1G
time.sleep(1)
result = [1 for _ in range(SIZE)] # リスト内包表記でリストを生成
time.sleep(1)
del result # 変数を削除
time.sleep(1)
result2 = []
for i in range(SIZE): # for文とappendメソッドでリストを生成
result2.append(1)
time.sleep(1)
del result2 # 変数を削除
time.sleep(1)
result3 = [1] * SIZE # 掛け算でリストを生成
time.sleep(1)
del result3 # 変数を削除
time.sleep(1)
Python スクリプトを実行しメモリ確保状況を確認します。なお、この実行には5分から10分程度の時間がかかります。またメモリを多く消費する処理が入っているので、環境によって実行できない場合があります。実行できない場合はSIZEを小さくして実行をしてください。
$ memray run sample-list.py
結果を見てみましょう。筆者が実行したときにはmemray-sample-list.というファイル名で結果が出力されました。
$ memray flamegraph memray-sample-list.py.173297.bin
結果のHTMLキャプチャを掲載します。
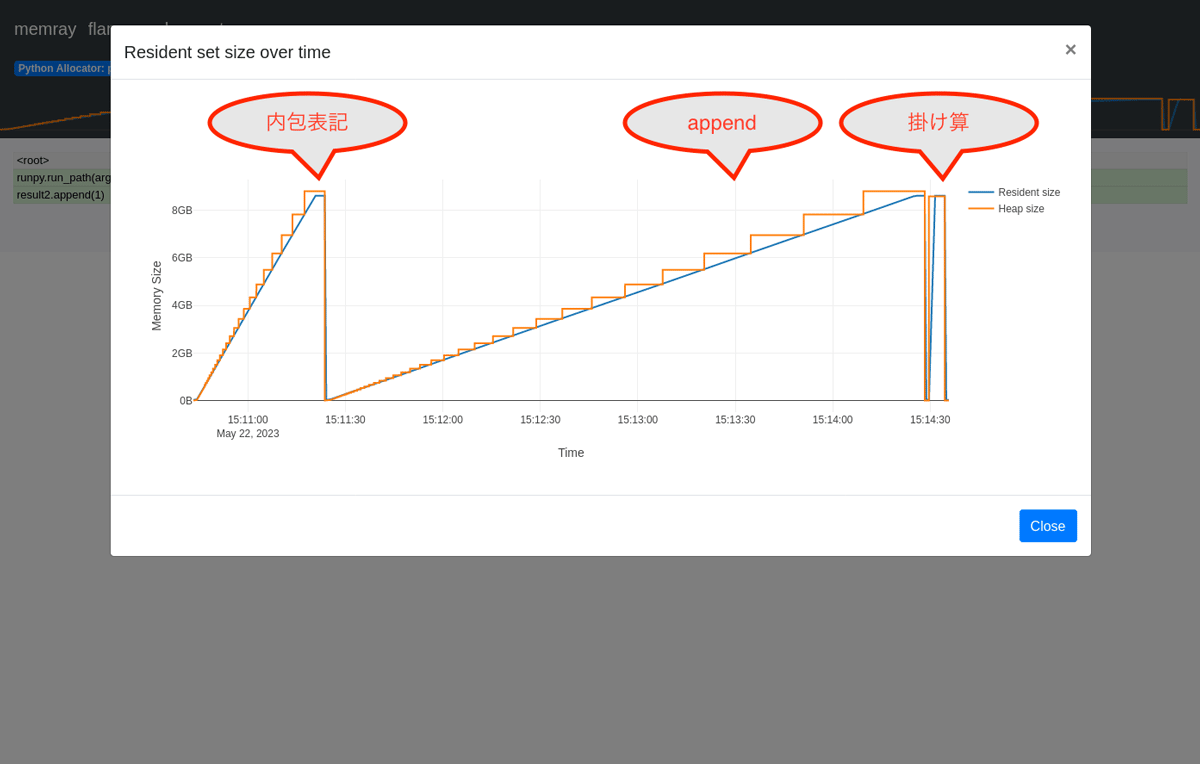
3回のメモリ確保が行われていることがわかります。
ここで実行した結果は、同じメモリ量を確保しています。なお、物理メモリの空きに余裕がない場合は、異なった青色の線のResidentメモリサイズが表示されます。
ここで注目は実行時間です。リスト要素を作る方法によって生成に掛かる時間が大きく違うのが可視化されています。実行時間がこのように可視化されるのはMemrayの副産物として便利な点でもあります。
NumPyで確認
NumPyはC拡張を使ったPythonライブラリです。配列の生成時にメモリを確保してデータを管理します。また、リストとは違いどのようなデータ型が入るかを指定し、データ型に合わせたメモリを確保します。
以下のPythonスクリプトを準備します。このコードは、NumPyのオブジェクトを4回生成しています。毎回NumPyの関数.onesを使い、1を約10億個確保しています。1回目のオブジェクトを生成後、2回目で同じ変数名に別のオブジェクトを上書きしています。その後オブジェクトを削除した後、3回目と4回目は別の変数名に同様のオブジェクトを生成しています。
import time
import numpy as np
SIZE = 1024 * 1024 * 1024 # 1G
time.sleep(1)
arr = np.ones(SIZE, dtype=np.uint8) # 要素数が約1億個のNumPy配列を8bit整数型で生成
time.sleep(1)
arr = np.ones(SIZE, dtype=np.uint8) # 同じ変数名に同じ配列を再代入
time.sleep(1)
del arr # 変数を削除
time.sleep(1)
arr = np.ones(SIZE, dtype=np.uint8)
time.sleep(1)
arr2 = np.ones(SIZE, dtype=np.uint8) # 別の変数に代入
time.sleep(1)
Python クリプトを実行してプロファイリングをし、その後結果をHTML形式で出力します。
$ memray run sample-arr.py $ memray flamegraph memray-sample-arr.py.173888.bin
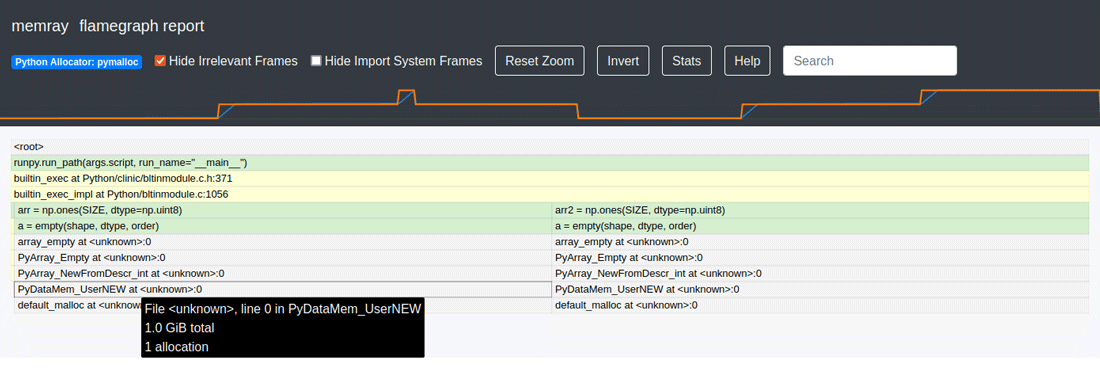
今回はuint8を指定していますので、要素1個あたり1バイトとなり、1つのオブジェクトで約1GBのメモリが確保されています。リストで同じように約1億個の要素を生成した時は約8GBのメモリが確保されたことに比べて少なくなっています。
ここで注目すべきは、同じ変数名にデータを再代入している2回目のメモリ確保です。以下のような処理が内部的に行われています。
- 1回目の
arr = np.で1GB確保ones(SIZE, dtype=np. uint8) - 2回目の
arr = np.でones(SIZE, dtype=np. uint8) np.を実行したところでさらに1GB確保ones(SIZE, dtype=np. uint8) arrに代入すると古い領域が削除されて1GBに戻る
これはオブジェクトを生成している間の変数にオブジェクトが上書きされる直前まで、メモリが倍必要になっています。システムメモリが十分な余裕がない場合は、事前にdelで変数を一旦削除してから実行する方が、メモリ的に余裕ができることがわかります。なお、後半の処理はarrとarr2の2つの変数にオブジェクトを代入しているので、約2GBのメモリが必要となります。
nativeモードでC拡張内の処理を確認する
次に、C拡張が使われているNumPyが具体的にどのようなメモリ確保をしているかを確認します。nativeモードでプロファイルをしてみます。
$ memray run --native sample-arr.py $ memray flamegraph memray-sample-arr.py.173921.bin
オプション--nativeを指定していますので、実行スタック上の内容が増えています。C拡張部分の内部の処理が明確になっています。出力されたHTML上のオブジェクトをマウスオーバーすると、その時のメモリ確保状況を確認することができます。
一歩進んだ使い方
ここでは、Memrayの一歩進んだ使い方を紹介します。
Jupyter Integrationを使う
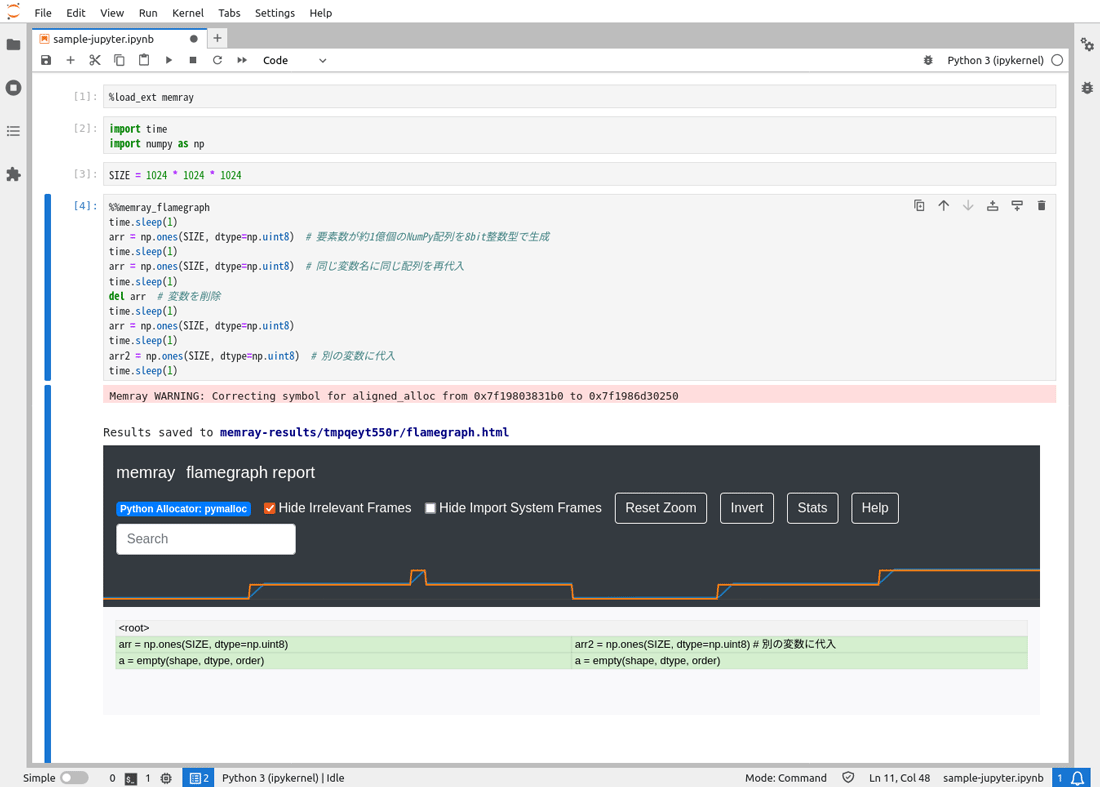
MemrayはJupyterLabとの連携機能があり、Notebookのセル内メモリプロファイリングができ、結果がNotebook上に表示されます。
Jupyter で利用するには、マジックコマンドを用います。以下のコマンドでmemray拡張モジュールをロードします。
%load_ext memray
拡張モジュールをロードすると、%%memray_セルマジックが利用できます。プロファイル対象のセルの1行目に以下のようにマジックコマンドを追記します。すると、プロファイリング結果がNotebook上に表示されます。
%%memray_flamegraph
具体的には、以下の画面キャプチャを参照してください。flamegraph形式のHTML出力と同じ結果がNotebook上に表示されます。
withステートメントで部分的に状態を見る
大規模なコードになった場合、どこでどれだけメモリが確保されているかわかりにくいことがあります。さらに、影響範囲が大きくなりメモリを使っている場所の特定がしにくい場合があります。
このような場合、memrayのTrackerクラスを使用して、部分的にメモリプロファイルができます。プロファイルする場所をwith文の中に入れて、出力するファイル名を指定し部分的に結果を出力します。
以下のように記述します。
import time
import numpy as np
from memray import Tracker
SIZE = 1024 * 1024 * 1024 # 1G
with Tracker("memray-numpyarray-profile.bin"):
arr = np.empty(SIZE, dtype=np.uint8)
time.sleep(1)
del arr
time.sleep(1)
arr = np.empty(SIZE, dtype=np.uint8)
time.sleep(1)
結果は、コード内で示した結果ファイル名memray-numpyarray-profile.に保存されますので、flamegraphを使って結果をHTML に変換し閲覧することができます。
pytest limitでテストにメモリ制限を設ける
pytestを用いた自動テストの実行時にメモリサイズの上限を設定できます。システム上のメモリ上限に達する実行がされないように、事前にチェックすることが可能です。
以下のようにpytest-memrayを追加でインストールします。
$ pip install pytest-memray
メモリ制限を設けたテストを行うには、以下のようにテスト関数にデコレータを追記します。
@pytest.mark.limit_memory("24 MB")
def test_foobar():
pass
詳しくは、pytest-memrayの公式ドキュメントを確認してください。
Flame Graph形式以外のアウトプット方法
今回は、flamegraphを使って結果をHTMLに変換する方法を紹介しました。Memrayには他の形式への変換方法も用意されています。プロファイル実行時に出力される結果ファイルbinファイル)
公式ドキュメントによると、以下のような形式が準備されています。
- Summary Reporter (概要表示)
- Table Reporter (表形式で出力)
- Tree Reporter (ツリー形式で表示)
- Stats Reporter (統計情報出力)
- Transform Reporter (gprof2dotなどを使って結果を変換)
まとめ
今回は、メモリプロファイル
大量のデータを使った分析やシミュレーションを行う場合、プログラムがメモリーエラーを出して強制終了されることがあります。このような場合、どこでメモリを大量に使用しているのか、改善できる場所はどこかを特定する際にMemrayが活用できると思います。
Memrayをうまく活用することでメモリ状況の確認を始め、関数呼び出しの関係性がわかるなど、実行するコードの状況が可視化されるのは面白いと思いました。筆者も継続して利用し最新情報を追いかけてみようと思います。