



みなさん、RubyKaigiは楽しかったでしょうか? 今年は2020年にできなかった松本でのリベンジをはたし、久し振りの完全なオフラインでの開催になりました。おかげで大変に盛り上がったKaigiだったと思います。
その中でも特に盛り上がっていたのがパーサーだったと思います。世はまさに大パーサー時代という感じでしたね。なぜ、今パーサーに注目が集るのでしょうか?
理由の1つには最近はLSPが普及してエディタの入力補完機能がエディタ毎に実装されるのではなく実装が共有されるようになったということがあるでしょう。またRubyに型定義ができるようになったことによってエディタに求められる入力補完機能も高度になっています。
エディタで入力補完をするにはプログラムコードを言語の文法にのっとってパースする必要がありますが、エディタでの入力中のプログラムコードは文法的に不完全な状態が起こりえます。文法的に不完全なプログラムコードは当然パースに失敗します。エディタで入力をサポートするには、このエラーをどうにかしてユーザーの意図に沿う形でリカバリーする必要があります
このユーザーの意図に沿うというのが難しいところです。いろいろな解釈ができるものを少ない情報から意図を汲み取ることが必要で、ユーザーにとって自然なフィードバックをすることが大切です。このことは、どんなソフトウェアでもユーザーとのインタラクションがあるような場合に重要なことで、ソフトウェアの開発において難易度が高く面白い課題です。
ちょっと横道にそれましたが、RubyKaigi 2023の最後のセッション、キーノートスピーチもパーサーの話題でした。スピーカーはこのRubyKaigiの大トリを飾るにふさわしくMatsumotoさんでした!
SoutaroさんはRubyの型チェッカーであるSteepの作者として知られています。SteepはRBSというフォーマットで記述された型定義やRubyのプログラムコード中に記述された型注釈に従って、型の整合性を静的にチェックします。本トークは

課題定義
RBSの最新バージョンは3.
SteepにはLSPの機能があってエディタの補完機能に利用できます。以下のようなコード:
module Parseg
class ParsingSession
def intersect?: (Parseg::TokenFactory::change) -> c
end
end
を入力すると、次のように型名が補完されます。
module Parseg
class ParsingSession
def intersect?: (Parseg::TokenFactory::change) -> TokenFactory::change
end
end
ここで不思議なことが起こります。このコードの意図としてはintersectメソッドはParseg::型を受けとってParseg::型を返すような関数として型を定義します。
ところが引数の型は名前空間をフルに記述したParseg::になっており、返り値の型はトップレベルの名前空間が省略されたTokenFactory::として記述されています。これは双方ともコード補完によって入力されたものでコンテキストによって補完されるコードの違いがあることを示しています。
なぜ、このようなことが起こるのかを順を追ってみていきましょう。まず、引数の型を入力するために以下のところまで入力します。
module Parseg
class ParsingSession
def intersect?: (c)
end
end
この場合、入力が不完全なためdef intersect?: (c)のとろでパースエラーとなります。ここでパースエラーになると、ここで補完されるコードがParsegという名前空間の中にあるというコンテキストが失われます。そこで補完されるコードとしてはParseg::になります。
次に、以下まで入力されたコード:
module Parseg
class ParsingSession
def intersect?: (Parseg::TokenFactory::change) -> c
end
end
は文法的には正しくパースできます。よって、cの箇所を補完する場合にParseg名前空間の中にあることが分かります。Steepはなるべく短かく表記するためにTokenFactory::を補完候補として提示します。
本トークでは、このようにパースエラーによって名前空間のようなネストするコンテキストが失なわれてしまう問題を解決するために、どのようにリカバリーするかという問題を扱っています。
エラーリカバリの概要
それではエラーリカバリについて解説します。ただ、本トークはかなりテクニカルで込み入っています。そこで本稿ではまず概要を説明して、込み入った詳細は後述します。なるべく概要を読めばトークの全容がつかめるように努めます。
さて、本トークでは以下のようなセクションに分けて話が進みました。
- Top-down parser outline
- Error recovery(1) - insert MissingTree
- Error recovery(2) - Skip tokens
- Error recovery(3) - Change based errror recovery
それぞれ順に取り上げていきます。
Top-down parser outline
steepのRBSパーサーはParsegというパーサージェネレーターによって生成されたものを使っています。Parseg自体がSoutaroさんの作品でRBSパーサーのために作られたようです。
構文規則のトップレベルの構文規則から順番に構文規則を再帰的に適用して構文解析を進めていく方法を取っており、これをトップダウンパーサーと言います。RBSの構文はRubyに比べると非常にシンプルなので、エラーリカバリの機能にフォーカスして開発できるということだそうです。
本トークではPersegの生成するRBSパーサーを例にしてトップダウンパーサーの動作を解説しました
Error recovery(1) - insert MissingTree
以下のような完全な
class Talk
def initialize: (String) -> void
end
に対して、以下のような不完全なコードについて考えます。
class Talk
def initialize
end
不完全なコードではinitializeメソッドに型定義が足りていません。パーサーはinitializeの後に:endが来るため構文エラーになります。
このようなケースに対応するために、パーサーは構文エラーとするかわりにMissingTreeというノードを出力します。こうすることで構文エラーで止まることなく構文解析を続けられます。
Error recovery(2) - Skip tokens
MissingTreeは不完全な穴の空いた構文構造に対して穴を埋めるように挿入されます。ところが以下のようなコードはどうでしょう?
class Talk
attr_reader title: -> String
def initialize: () -> void
end
このコードでは->は余分です。MissingTreeは足りない要素は埋めてくれますが、このような余計なもの・MissingTreeを挿入しつづけてしまいます。つまり->はどの構文規則にも当てはまることなく、それ以降の構文解析が止まってしまいます。それ以降の定義は完全なのにも関わらずです!
このようなことが起こらないためには->というトークンが構文要素のどこに当てはまるかを探るのはあきらめて、なかったことにするしかありません。この->を無視すれば次のStringは期待通りのトークンとして構文解析を続けられます
Error recovery(3) - Change based errror recovery
これまでは期待するトークンがなかった場合、期待するトークンとは違うトークンがある場合のエラーリカバリーついて解説しました。しかしネストした構造では別の問題も発生します。
以下のようなコードはinitializeメソッドはConferenceクラスに属するのかTalkクラスに属するのか判別できません
class Conference
class Talk
def initialize: (String, Integer) -> void
end
実際にはパーサーはこの場合initializeメソッドはTalkクラスに属するものとして解析します。これはユーザーの意図した挙動でしょうか? 例えば:
class Conference
def initialize: (String, Integer) -> void
end
というコードに対して、Talkクラスを挿入しようとしている場合には期待した動作ではありません。
この時点ではinitializeメソッドはConferenceクラスに属しますが、class Talkという行を挿入し、最初に挙げたコードの状態になったときにinitializeメソッドはTalkクラスのメソッドに移動します。endを挿入して次の状態になると、再びinitializeメソッドはConferenceクラスに戻ります。
class Conference
class Talk
end
def initialize: (String, Integer) -> void
end
このように入力途中の状態ではユーザーの意図している構造を再現できません。また、編集中に親要素が変わってしまうため移動をくり返すことになります。

このような状態を回避するためには、ユーザーの編集しているという状況をエラーリカバリに反映するのがよさそうです。
Parsegでは[EOC]マーカートークンという特別なトークンを挿入することによって、入力中のTalkクラスを編集中としてツリー構造を変更しないように動作します
締めくくりに
トークの最後にsoutaroさんは、これまで15年に渡ってRubyの型チェックについて活動してきたことについて語りました。始まりは2007年に大学の学生としてMLの型推論を基にしたものだそうです。2017年の大江戸Ruby会議では、rbiファイルというフォーマットでsteepの元となるアイデアの発表もしたことも取り上げました。
長きに渡ってRubyの型チェックについて研究されて、それを実現されたその実行力にはほんとに頭が下る思いでした。
最後にMatzが1日目のキーノートで話した
詳細解説
ここまで読んでいただければ、本トークの内容を大方理解していただけたかと思います。
先に述べたように、ここまで概要を説明することで、なるべく詳細に触れずかつ課題とその解決方法の概略をつかめるように努めました。そのため、細かくここはどうなっているのだろう?
Top down parser outline
Parsegの文法規則の定義はRuby DSLで書けるようになっています。例えば次のような感じです。
Perseg::Grammer.new.tap do |grammer|
grammer[:class_decl].rule =
T(:kCLASS) +
NT(:module_name) +
Opt(Repeat(NT(:class_member))) +
T(:kEND)
grammer[:module_name].rule = T(:kUIDENT)
grammer[:class_member].rule = ALT(
NT(:class_decl),
NT(:method_definition),
NT(:attr_reader)
# ...
)
end
T、NTはそれぞれ終端記号、非終端記号を表しています。例えば、終端記号T(:kCLASS)はclassというトークンclass_)classというシンボルで始まることを表しています。次に非終端記号NT(:module_があります。これは次にmodule_という構文規則を適用することを表しています。
Opt(Repeat(NT(:class_というのはオプショナルで、かつ繰り返しclass_という構文規則を適用することを表しています*に当たるものです)。
このように構文規則が定義され再帰的に構文規則を適用していくのがトップダウンパーサーです。
パーサーの出力
パーサーが出力するのはConcrete Syntax Tree(CST)になります。プログラミング言語のパーサーにおいてよく耳にするのはAbstract Syntax Tree(AST)ですが、本トークでは明確にConcreteであると述べています。
CSTは文法
パーサーが出力する構文ツリーは以下のクラスで表されます。
- TokenTree
- NonTerminalTree
- OptionalTree
- RepeatTree
- AlternationTree

とてもシンプルですが抽象化された表現は強力でRBSを表現するには必要十分なのだと感じました。
出力されるパーサーの実装
Parsegはclass_の定義に対して次のようなパーサーのコードを生成します。
def parse_class_decl
NonTerminalTree.new(:class_decl).tap do |tree|
tree << parse_token(:kCLASS)
tree << parse_module_name()
tree << parse_class_members()
tree << parse_token(:kEND)
end
end
構文要素とメソッドが1対1で対応していることが読みとれるかと思います。各メソッドは構文要素を返し、それがそのまま構文ツリーに適用されます。
class_はAlternative
def parse_class_member
case current_token
when :kClass
parse_class()
when :kDEF
parse_method_definition()
when :kATTRREADER
parse_attr_reader()
...
end
このように構文解析が行なわれ図のようにコードから構文ツリーにが作られます。
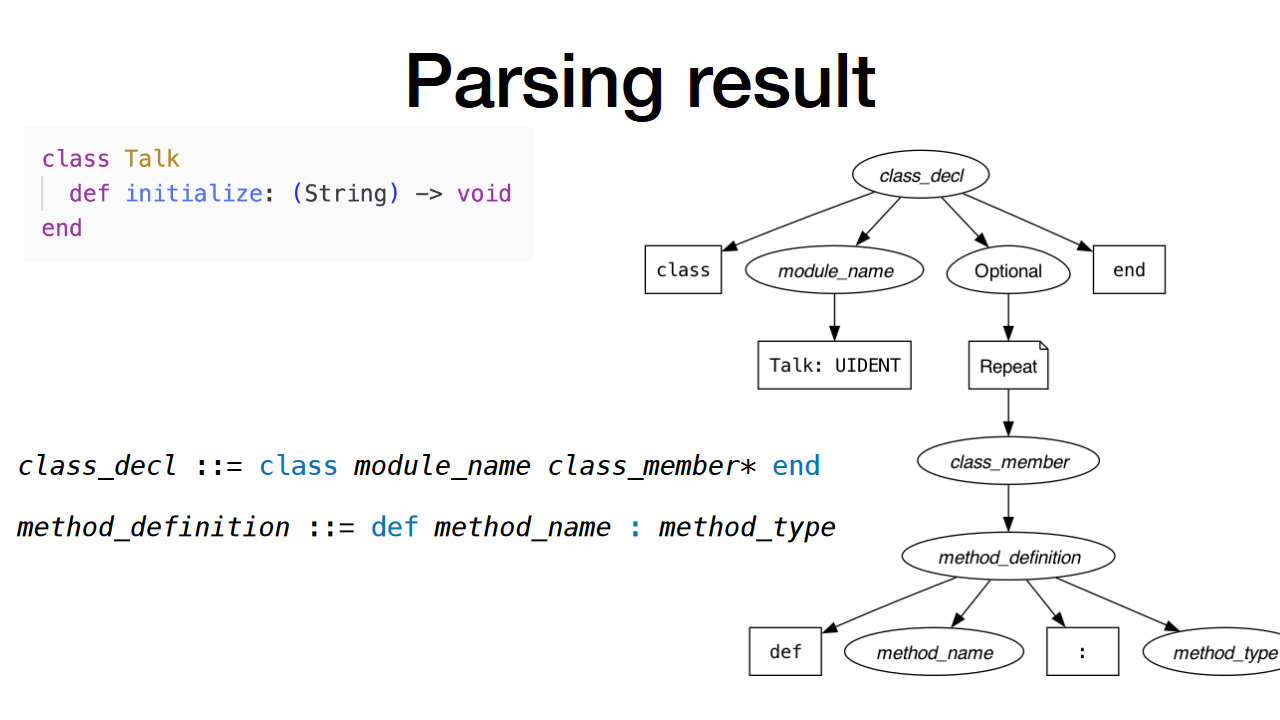
insert Missing Tree
MissingTreeが挿入される例は以下のようなコードでした。
class Talk
def initialize
end
def initializeというトークン列はメソッドの定義にあたります。コードのparse_に当ります。そのparse_は以下のように定義されます。
def parse_method_definition
NonTerminalTree.new(:method_definition).tap do |tree|
tree << parse_token(:kDEF)
tree << parse_method_name()
tree << parse_token(:kCOLON)
tree << parse_method_type()
end
end
次にparse_が呼ばれます。エラーリカバリのないparse_メソッドの実装は以下のようになります。
def parse_token(expected_token)
if current_token == expected_token
advance_token()
TokenTree.new(expected_token)
else
raise SyntaxError.new(...)
end
end
ここでSyntaxErrorをraiseしている箇所にMissingTreeを挿入するというコードに置きかえることでエラーリカバリします。
def parse_token(expected_token)
if current_token == expected_token
advance_token()
TokenTree.new(expected_token)
else
MissingTree.new(...)
end
end
Skip tokens
トークンをスキップする例は以下のコードでした。
class Talk
attr_reader title: -> String
この場合->がエラーとなりスキップすることでエラーリカバリしたいのですが、このトークンをスキップするべきかどう判断するかが鍵になります。
ここでどのようなトークンを受けいれるべきかを考えます。MissingTreeが導入済みですので、本来ここに入るべきトークンの他に、このトークンの前にMissingTreeが挿入された場合に受け入れられるトークンについても考慮します。このケースの場合は以下になります。
- 本来入るべきトークンつまり型
( UIDENT,void,untyped, ...) class,attr_,reader defなど次にくるclass_member - クラス定義の最後にくる
end - 次のクラス定義
( class)
これらのケースを考慮して、受けいれられるかどうかを判定しトークンを無視して、次のトークンから解析を再開するように各メソッドの先頭にskip_という処理を挿入します。
def parse_type(consumable_tokens)
skip_non_consumable_tokens(consumable_tokens)
...
end
def parse_token(expected_token)
skip_non_consumable_tokens(consumable_tokens)
end
筆者注:ここの実装のところは筆者にはどうやって次のトークンから再開するというリカバリーをするのか理解できませんでしたconsumable_にはいくつか先の分までトークンを含んでいて先読みするというようなことなのだろうと想像しています)。
Change based error recovery
ユーザーの入力状態によって構文ツリー上でノードの所属が行き来するような例として以下のコードがありました。
class Conference
class Talk
def initialize: (String, Integer) -> void
end
この中で新たに挿入されたコードの一部がclass Talkという行だとします
このときパーサーにはclass、Talkというトークン列の後ろに[EOC]というマーカートークンが渡されます。そして、変更中のコードの一部であるという情報と[EOC]トークンを手掛りにパーサーは構造を決定していきます。
parse_の実装は次のようになります。
def parse_class_decl
start_with_change = current_token_changed?
NonTerminalTree.new(:class_decl).tap do |tree|
tree << parse_token(:kCLASS)
tree << parse_module_name()
tree << parse_class_members()
tree << parse_token(:kEND)
parse_token(:EOC) if start_with_change
end
end
current_はclass Talkの箇所に適用されます。パーサーは以下のように処理します。
class、Conferenceというトークン列が来たときにparse_メソッド内でclass_ decl start_がwith_ change falseとなります。class、Conferenceとトークンを消費していって次にclass、Talkというトークン列を受けとったときはcurrent_はtoken_ changed? trueであり、parse_から再帰的にclass_ members() parse_メソッドが呼びだされたときにはclass_ decl start_がwith_ change trueとなります。class、Talkとトークンを消費して[EOC]トークンが渡ってきたときに再びparse_が呼びだされますが、ここではclass_ members() [EOC]トークンを消費できないのでそのまま次に進みます。parse_も同様にスキップして最後にtoken(:kEND) parse_の行でtoken(:EOC) if start_ with_ change [EOC]が消費されます。
[EOC]トークンを使うことによって、変更途中ものものをスキップしつつ、変更中のコード部分の外側の構造に影響を与えないようにしていることが分かるかと思います。
Change based error recoveryは通常のパースをして失敗したときに初めておこなわれます。通常のパースで前回成功したところから変更された箇所に対してパースをおこないます。
result = parser.parse(tokens)
if result.success?
last_successful_result = result
else
result = parser.parse(tokens, change_range)
end
本トークの詳細解説は以上です。