



部署を問わず多くの人がデータ分析基盤を活用しているというのが、高度なデータ活用の事例として取り上げられることがあります。このような形は理想的かもしれませんが、簡単に実現されるものではありません。
むしろ、データ分析基盤を作ったものの適切に使われないのはよくあることです。データはそれ自体に価値があるのではなく、事業の推進に貢献するからこそ価値がある以上、作った基盤をいかに組織に浸透させていくかは重要な課題です。
本記事では、データ分析基盤をより効果的に活用していくための取り組みとして、
データ分析基盤とはなにか
本題に入る前に、データ分析基盤について簡単に確認しておきましょう。データ分析基盤とは、データ分析やデータ活用を行うためのシステム基盤のことを意味しています。
近年、データ活用が事業においてより重要になっていますが、データは個別のシステムに散在してそのままでは効果的に使うことができません。そこで、データを収集・
データ分析基盤が適切に使われないとどう困るのか
では、ここからが本題です。せっかく作ったデータ分析基盤が使われないと困るというのは当然ですが、改めて具体的にどう困るのかを確認しておきましょう。
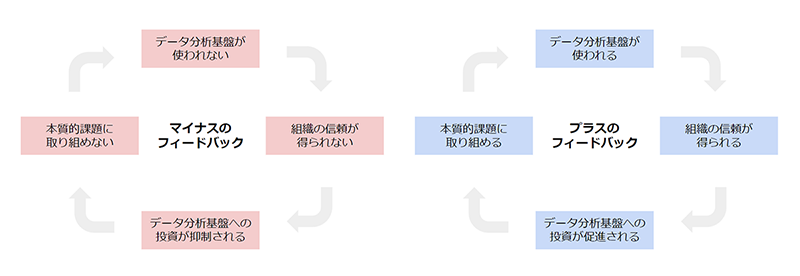
まず、使われないと事業成果につながらないため、データ分析基盤の存在意義自体に疑問を抱かれてきます。これの何が問題かというと、信頼がない状態で投資の費用対効果をより厳しく見られることにつながるので、
- 基盤構築に必要な技術利用に対して意思決定が遅く、投資的取り組みが承認されにくくなる
- 他部門からの協力を得にくくなるため、より活用に向けての取り組みが難しくなる
- 上記のような環境で些末な作業が増えることで、より本質的な業務に工数を割けなくなる
- データエンジニアの社会的需要の増大で給与水準が上がってきているのもあり、最終的にはデータ分析基盤チーム自体の継続が怪しいものになりうる
というような結果につながってきます。逆に言うと、データが活用されるからこそデータへの投資が促進され、投資が促進されるからこそより本質的な課題に取り組みデータが活用されるというフィードバックループが回るようになりうるのです。
データ分析基盤が適切に使われていない3つのケース
では、データ分析基盤が使われないのにはどのような背景があるのでしょうか。それは、大きく分けて3つのあり方があると考えています。
| あり方 | 発生する問題 |
|---|---|
| ①スキル不足で無秩序な活用 | 時間が経つにつれて負債が蓄積 |
| 複雑すぎるデータ処理や分析で属人化 | |
| KPI定義に齟齬が発生 | |
| 一部のアドホッククエリでリソース競合 | |
| ②すべてをデータエンジニアに頼み込む | はじめは利用促進につながるならと依頼を受ける |
| 徐々に依頼が増えて業務の逼迫につながる | |
| 依頼側のスキル不足で期待値の齟齬が発生しやすく、 |
|
| ③どう使っていいかがわからず使おうとしない | まさにデータ分析基盤の存在意義を問われることにつながる |
| 相手の状況に応じて対応の難易度に幅がある |
※ちなみに①の状況で、データの統制にはdbtやLookerのLookMLなど、リソースの競合にはDWHのチューニングやシステム変更など、技術面の対応も重要な解決策になりますが、本稿ではその側面は割愛します。
これらの①~③のあり方に共通するのは、データ分析基盤を構築するデータエンジニアと、基盤を利用する非エンジニアで連携が取れていないことです。そしてこの間を埋めるものとして、データエンジニアリングスキルがあると考えています。
より理解を深めるために、いくつか職種を取り上げて、それぞれがよく陥る問題と、スキルがあることでどういった取り組みができるかを整理してみます。
職種別にデータエンジニアリングスキルの価値を考える
例1)データアナリスト
まずは、データエンジニアと最も近い関係で業務をすることの多い、データアナリストです。データエンジニアリングに関連してデータアナリストがしばしば抱える問題は、データの品質が担保されないことで事業上のKPI数値に齟齬が生じることや、さまざまな事業部の個別依頼を受けることで、データの分析者というより抽出者に近い形になってしまうことです。
データアナリストにデータエンジニアリングスキルが身に付くと、データエンジニアと協働しながらデータマートを整備してKPIの統一化を進めることにつながります。データパイプラインやデータ加工の知見が深まることで、事業部の依頼への対応についても、作業時間が短縮されたり、要望を技術要件に的確に落とせることで手戻りを少なくしたりすることができます。
加えて、クエリの品質が上がったり、重い処理を回避するような配慮ができたりするようになることで、属人化やリソース競合のリスクを低減することにもつながります。データエンジニアへの単純なデータ抽出依頼を減らすことで、分析結果をよりタイムリーに事業に反映することにもつながるでしょう。
最近では、より事業ドメインに近いところでデータ整備を行う職種として、
例2)営業企画/マーケター
次に、SFAやMAというシステムを活用する職種として、たとえば営業企画やマーケターがあります。近年はSaaSが多く導入され、各職種で業務プロセスを回すためのシステムが個別に採用されていることも多くあります。システムをベースにした業務運用になると、そのデータで効果検証を行い、PDCAを回していくことが重要になってきます。
しかし、職種別でシステムがあることで、データも別々に扱われてしまうことも多くあります。たとえばマーケターでは、数多くの媒体で広告運用を行うことがありますが、それぞれの広告媒体の管理画面から手動でデータをダウンロードする形だと、データの集約までに多大な工数がかかってしまうことになります。また、抽出作業をデータエンジニアに都度依頼しているような形もあり得るでしょう。
さらには、マーケティング領域はMA、営業領域はSFAと別のシステムをもとに別の数値管理を行っていると、リードは多く獲得しているが、営業ターゲットとずれていて成約には全然つながらないということになりかねません。
データエンジニアリングスキルが身に付くと、たとえば各種広告媒体のデータ取得から統合を自動化することで、PDCAを回す速度を上げることにつながります。また、SFAとMAのデータを連動させることで、部門単位ではなく組織単位で事業の最適化を進めることができます。データを活用する自身の業務を自律的に行い、また他部門との連携も円滑になってくるのです。
例3)営業/カスタマーサクセス
最後に、対人業務の割合が高い営業やカスタマーサクセスです。これらの職種では、過去の対応と一貫性を持たせたり、顧客の行動に即した対応をしたりするためにデータを活用する必要があります。対応が不十分であると、商談からの成約率が低くなる、突然解約を告げられるなどの結果につながります。
データに苦手意識を持ち、まさに
非エンジニアがデータエンジニアリングスキルを学ぶ意義
ここまでの内容をふまえて、非エンジニアがデータエンジニアリングスキルを学ぶことの意義をまとめてみます。
- データを活用した施策を自身で完結して回せることで、PDCAが高速化する
- 別々のデータを連動させることで、部門
(システム) 単位の個別最適化を脱却し、組織単位で事業の最適化ができる - 上記に合わせて、データエンジニアリングの考え方に準拠することで、こうすればもっといいやり方ができるのではという発想が生まれるようになる
このように、自身がデータエンジニアでなくとも、そのスキルを身に付けることは自身の業務を発展させる大きな力になります。そして、これらはデータエンジニアにとっても望ましい効果をもたらします。
- 共通知識の欠如による期待値の齟齬が減少し、コミュニケーションコストが下がる
- 上記により、よりデータエンジニアリングの本質的な部分に力を割けるようになる
- データ分析基盤の有用性が認知されることで、データエンジニアの金銭的/
人的な体制強化に取り組みやすくなる
以上、非エンジニアがデータエンジニアリングスキルを学ぶことは、データ分析基盤の浸透に対して重要な役割を果たすことになります。
非エンジニアのデータエンジニアリングスキルの育成方法
データエンジニア向けのデータエンジニアリングスキルの育成方法については、本特集の過去記事
実は、弊社ではこれまで非エンジニア向けのデータエンジニアリングワークショップを数多く実施してきました。以下では、その際の経験を踏まえたポイントを三点取り上げます。
データエンジニアリングの考え方のエッセンスを伝える
データエンジニアリングの技術的に難しいところは、たとえば大規模データ処理やリアルタイム処理などにありますが、これらは非エンジニアの理解が必要なものではありません。非エンジニアでは、データエンジニアリングの考え方のエッセンスを理解することが重要です。
具体的にどのようなことを理解するとよいのかというと、大枠としてデータ分析基盤がなぜ/
どういったことをやろうとすると工数がかかって、どういったことならそうでないのかの感覚が身に付くと、以後の依頼時のコミュニケーション円滑化につながるでしょう。
自社や個々の業務領域に即したハンズオンを交える
データエンジニアにとってももちろんですが、非エンジニアにとってはより一層、自分で手を動かした結果を見ながら学ぶことが学びを深めることにつながります。そして、普段から業務で慣れ親しんでいる領域で、その意味を経験的に理解しやすいデータを扱うと効果的です。
ハンズオンの内容としては、データ分析基盤としてのDWHやCDP環境等で、データエンジニアリングの基礎であるSQLを取り上げるのが一案です。SQLは広く使おうとすると奥深いですが、簡易な分析用途に限定すると学ぶことの幅はかなり限定されてきます。
分析者向けのSQL入門書としては2015年に出版された青木峰郎
対象を絞って、ある程度の時間をかけて行う
また、これらの育成は一日二日ですぐにできることではないというのも重要なことです。データエンジニアリングはなかなか触れる機会が少ない分、きちんと習得するには時間がかかります。一方で、きっちり身に付けることができると、前述したような大きな効果を出すことができます。
育成に向けてのはじめの一歩としては、個々の部署でのデータ活用に中心的に協力してくれそうな人を見つけ出し、相手の業務上のメリットを説きながら一緒に進めていくのが良いでしょう。育成を進めていく際には、相手の職種・
まとめ
今回の記事では、作ったデータ分析基盤が適切に使われないことが多いのを出発点に、なぜ使われないのか、どう使われるといいのかを整理しながら、非エンジニアがデータエンジニアリングスキルを学ぶ意義とその育成方法について紹介しました。
そこでは、非エンジニアのデータエンジニアリングスキルを育成することで、非エンジニアはもちろん、データエンジニアにとってもデータ分析基盤の活用に向けて、大きな効果を持つことをお伝えしました。
技術や組織の側面は本記事では触れられませんでしたが、少なくともデータ活用の拡大に向けての1つの側面として、今回の内容が少しでも参考になれば幸いです。