



本連載は、Google Cloudのアプリ開発とDBプロダクトにおけるスペシャリスト達が、Google Cloudプロダクトを利用した、クラウドネイティブな開発を実践する方法を解説しています。
第2回では、Google Cloudが提供するフルマネージドなKubernetesプラットフォームであるGoogle Kubernetes Engineのアーキテクチャや特徴を紹介します。この記事を読むことでGoogle Kubernetes Engineのユースケースや利点について理解できます。
対象となる読者として、クラウドを利用したアプリケーションプラットフォームを開発/運用するエンジニア、またそのプラットフォーム上でアプリケーションを開発するエンジニアを想定しています。
Kubernetesとは
KubernetesはOSSのコンテナオーケストレーションシステムです。
Google内部で利用している
Kubernetesが解決する課題
1台のマシン上でDocker等コンテナランタイムを動かすことでコンテナ化されたアプリケーションを実行できます。
しかし、複数のコンテナアプリケーションを複数のマシン上で動かすような場合には以下のような課題が発生します。
- 複数マシン間でのコンテナのスケジューリングをどう制御するか
- コンテナ間のサービスディスカバリーや通信をどう制御するか
- コンテナやマシンに負荷がかかった場合にどう対処するか
- コンテナやマシンに障害が発生した場合にどう復旧させるか、等
Kubernetesは上記のような課題を解決します。Kubernetesでは複数マシン間のスケジューリングやコンテナ/マシンの自動スケール、自動修復といった機能を提供しており、多くのコンテナが必要となるような大規模な環境においてもコンテナ アプリケーションを運用することが可能になります。
Google Kubernetes Engine(GKE)とは
Google Kubernetes Engine
先述の通り、Kubernetesはコンテナ化されたアプリケーションのプロダクション利用に必要となる各種機能を提供してくれます。しかしOSSのKubernetesを自前で運用する際は以下のような運用作業が必要となります。
- Kubernetesコンポーネントのアップグレード作業
- Kubernetesコンポーネントのセキュリティ対策
- Kubernetesマシンのプロビジョニング
- Kubernetesマシンの修復、等
問題発生時のトラブルシューティングの際などはKubernetesに関する深い知見も求められますし、高度にKubernetesを運用しようとすると、マシンやロードバランサー等のプロビジョニングを自動で行うために物理/仮想化基盤とのインテグレーションも自ら実装する必要がでてきます。
Google Cloudが提供するGKEでは、上記のような各種運用作業を自動化しており、Kubernetesをより簡単かつ安全に使うための機能を多く提供しています。
また、Google CloudのIaaSやロードバランサー、モニタリング・
GKEのユースケース
Google CloudにはGKE以外にもCloud Runなどのコンテナプラットフォームサービスが存在しますが、GKEはKubernetesというコンテナオーケストレーションのデファクトスタンダードがベースになっているため、様々なOSSやKubernetesエコシステムを活用し自社に最適化されたプラットフォームを作り上げることができるというのが大きな差別化ポイントになります。
ただし、GKEを運用するにはKubernetesに関する基本的な知識が必要になるためCloud Runに比べると学習コストが若干高くなりがちで、GKEを管理する担当者が存在するような組織体制での利用が望ましいです。特に中〜大規模な環境になるとGKEによる運用の共通化のメリットを享受しやすくなり、学習コストに対する導入効果も高くなります。
小規模な環境やインフラ専任者が不在な組織体制の場合はCloud Runなどサーバレスの製品、もしくはこれから紹介するGKE Autopilotというモードを活用するのがおすすめです。
GKEのアーキテクチャ
GKEはクラスタという単位で管理され、1つのGKEクラスタはControl PlaneとNodeという2種類のコンポーネントから構成されます。
Kubernetes APIのエンドポイントを提供するkube-api serverやコンテナのスケジューリングを行うkube-scheduler、Kubernetesオブジェクトの構成情報を保管するetcdなどシステム関連コンポーネントが動いているマシンをControl Planeと呼びます。
一方、実際のコンテナアプリケーションが動いているマシンをNodeと呼びます。NodeはNode Poolという単位でグルーピングされ管理されます。
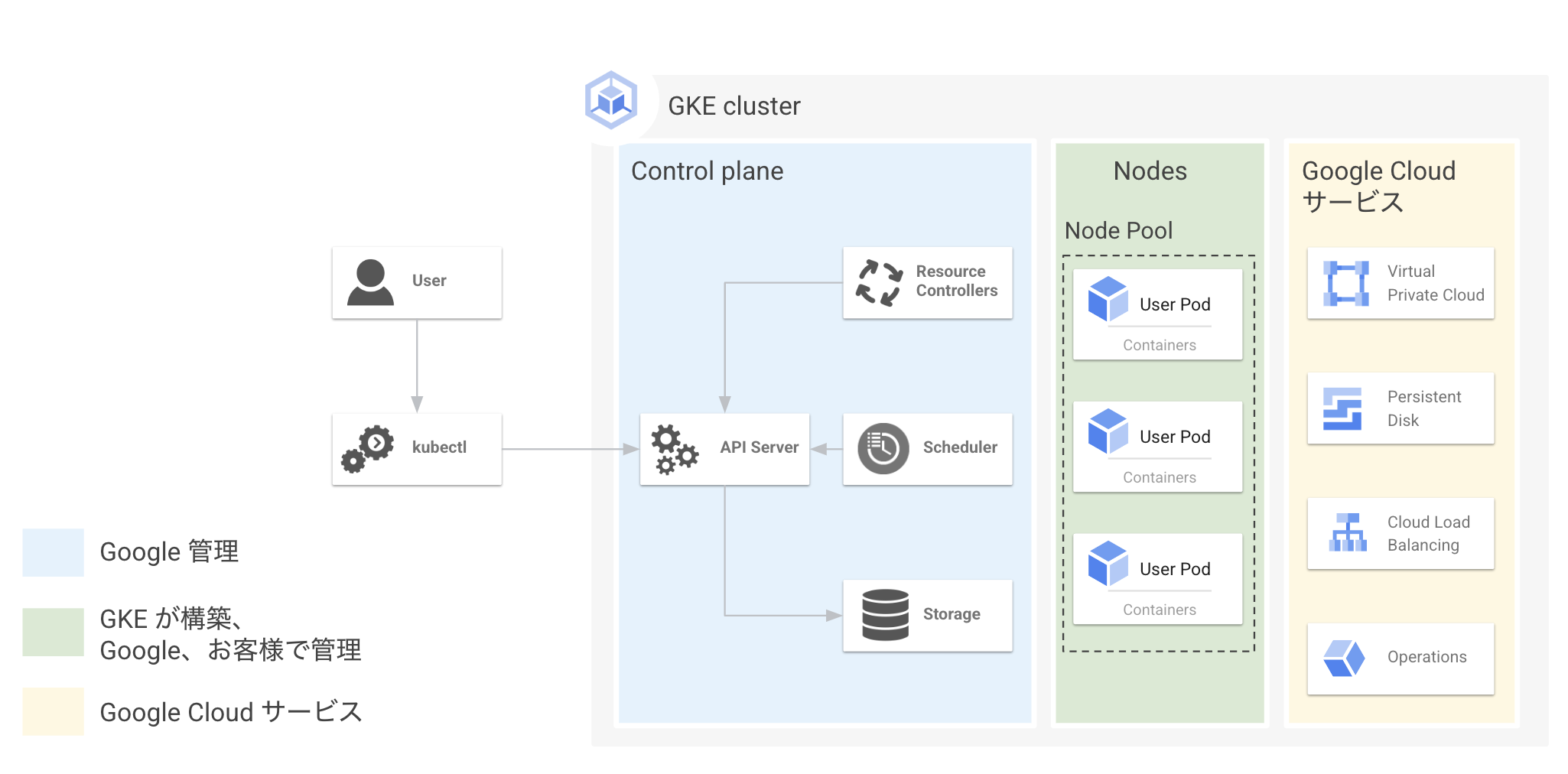
GKEではControl PlaneはGoogleが管理しており、ユーザー側でControl Planeの運用
一方Nodeについてはユーザー側で管理するGKE StandardもしくはGoogleで管理するGKE Autopilotという2つのモードから選ぶことができます。
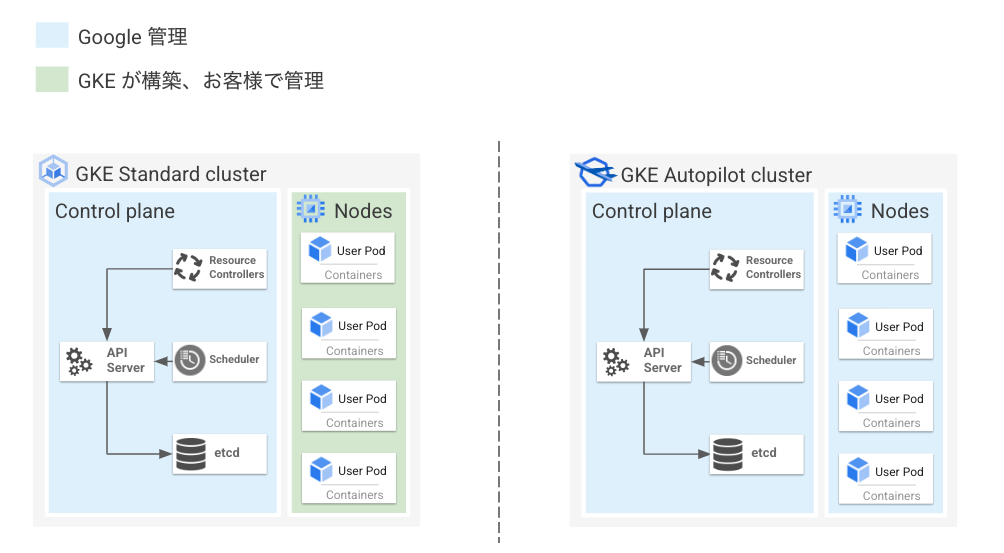
GKE Autopilotの特徴
先述の通り、GKE StandardにおいてControl PlaneはGoogle管理ですがNodeはユーザー管理となっています。
一方GKE AutopilotはControl PlaneだけでなくNodeもGoogle管理になっています。
具体的には以下のようにNode管理を自動化することで管理負荷の低減を実現しています。個々の自動化機能の概要については後述します。
- Nodeのサイズや台数調整などリソース管理の自動化
- Nodeのアップグレード作業の自動化
- UnhealthyなNodeの修復を自動化
GKE AutopilotはNodeが管理不要なモデルになっているものの、何かしら特殊なアーキテクチャで構成されているわけではありません。通常のGKEクラスタをベースにしつつ各種自動化機能を有効化することにより実現しています。
したがって、JobやDaemonSetなどKubernetesの基本リソースをデプロイできますし、IstioやArgoCDなど多くのKubernetesのエコシステムの実行もサポートしています
また、GKE AutopilotはGKEのベストプラクティスが組み込みで実装されており、プロダクションレディなクラスタをすぐに利用できます。
特にセキュリティの観点だと以下のような特徴があり、比較的セキュアな構成を簡単に払い出せます。
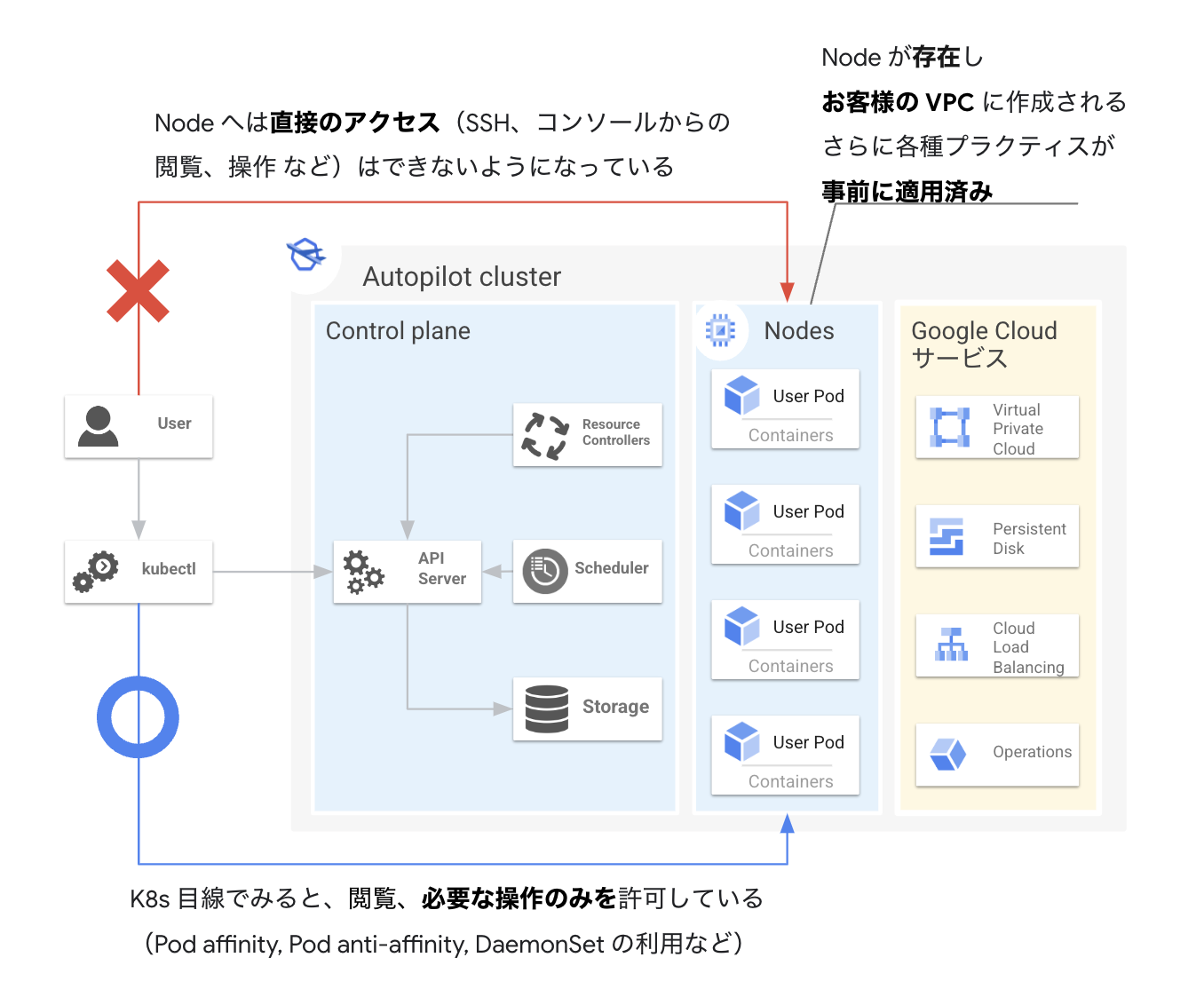
- Container-Optimized OS
(Googleが提供するセキュアなノードイメージ) のみ利用可能 - NodeへのSSH不可
- 特権コンテナのデプロイ不可
- 利用可能なLinux capabilitiesが制限されている、等
以上より、GKE AutopilotはKubernetes/
GKEの特徴
ここからは以下GKEの特徴について具体的に紹介していきます。
- 運用負荷を軽減するための各種自動化機能
- 高い拡張性
- 豊富な周辺サービス・
エコシステム
特徴① 運用負荷を軽減するための各種自動化機能
まず1つ目の特徴として、GKEは以下のようなKuberentesクラスタをより簡単に運用するための各種自動化機能を持っているというのが挙げられます。
- 自動スケール
- 自動修復
- 自動アップグレード
サービスの成長に比例してKubernetesクラスタの運用負荷は増加しますので、より効率的に運用し作業負荷を軽減するために各種自動化機能を活用することが求められます。
自動スケール
バースト性があるワークロードや新規ワークロードでは明確なリソース要件を事前に把握することが難しいケースもよくあるのではないでしょうか。必要リソースを多めに見積もるとオーバープロビジョニングでコストが想定よりもかかってしまう可能性もありますし、少なく見積もるとワークロードが正常に動作しなくなってしまう可能性もあります。
Kubernetesではこのような課題を解決するための自動スケールの機能を元々持っていますが、GKEではさらに独自に拡張したような自動スケール機能も提供しています。
ここではGKEが有している以下5種類のPod/
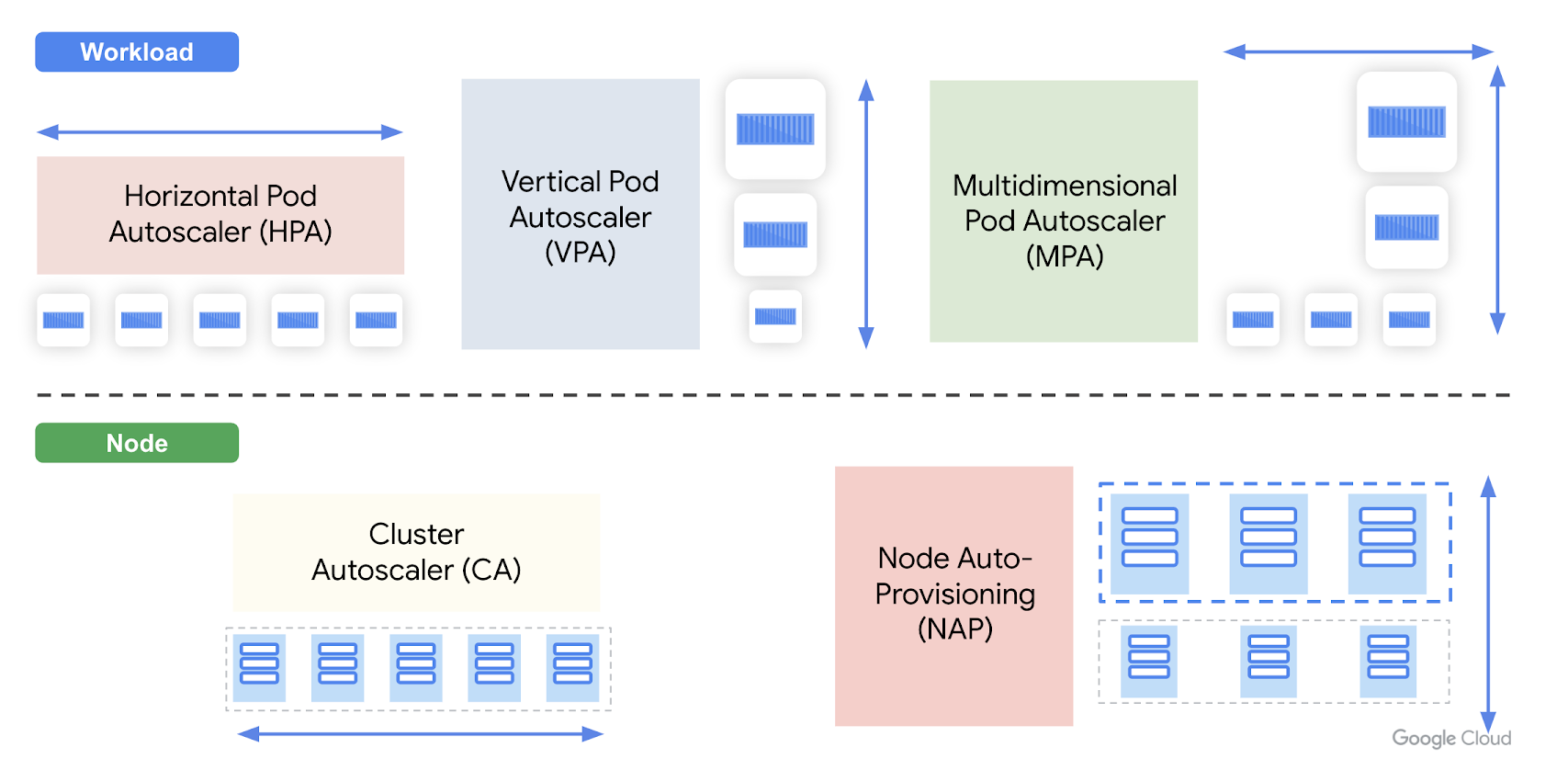
Horizontal Pod Autoscaler(HPA)
Horizontal Pod Autoscaler
CPU/メモリ以外にも、カスタム指標や外部指標を使ったオートスケールもサポートしており、例えばロードバランサーのリクエスト数メトリクスをベースにしたスケールや、Pub/
主にステートレスなワークロードのオートスケールで利用されます。
Vertical Pod Autoscaler(VPA)
Vertical Pod Autoscaler
VPAの更新モードは以下3種類存在します。
- Off:推奨値を算出するのみ
- Initial:Podの作成時に割り当て、既存Podの再起動なし
- Auto:既存Podの再起動あり
基本的には急激なトラフィック増に対処する場合は、VPAではなくHPAを利用することを推奨していますが、新規ワークロードでの必要リソースの参考値としてupdateMode: OffのVPAを有効にし、推奨値の算出から始めてみるという使い方も可能です。
Multidimensional Pod Autoscaler(MPA)
Multidimensional Pod Autoscaler
本来、CPUやメモリの値をターゲットにしたHPAとVPAを合わせて使うことは非推奨となっていますが、MPAを利用することでこの2つを安全に併用できます。
ユースケースとしては、CPUの利用率ベースでPod数を調整しつつOOMが発生しないようVPAによるメモリの垂直スケールも併せて行いたい場合等の利用が想定されます。
Cluster Autoscaler(CA)
Cluster Autoscaler
Node pool内のNode数が不足しPodのスケジューリングができない場合は自動的にNodeを追加し、Nodeの使用率が低く、Node pool内Node数を少なくしてもすべてのPodのスケジューリングが可能な場合は自動的にNodeを削除してくれます。
Node Auto-Provisioning(NAP)
Node Auto-Provisioning
CAはワークロードの需要に基づいて特定Node Pool内の
これにより、ノードのサイジングを含めたリソース管理をGKEに任せることができ、またワークロードに合ったサイズのマシンがプロビジョニングされるためインフラリソースを効率的に活用することが可能になります。
GKE AutopilotではNAPを利用しPodに必要なNodeを自動的にプロビジョニングしています。
自動修復
GKEではNodeがUnhealthyな状態になっていることを検知し、自動的に修復プロセスを開始するNode Auto Repairという機能も提供しています。
例えば以下のような状態の場合にNodeがUnhealthyと判断され、対象Nodeが再作成されます。
- 約10分間、NodeがNotReadyステータスを報告
- 約10分間、Nodeがステータスを何も報告しない
- 長期間
(約30分間)、DiskPressureステータスを報告
この機能により、Nodeレベルでの障害発生時の対応負荷を軽減することが期待できます。
自動アップグレード
Kubernetesクラスタの運用の中でも特に負荷が高い作業がクラスタのアップグレードではないでしょうか。
Kubernetes/
GKEはこのアップグレードの運用負荷を低減するための機能を提供しています。
リリースチャンネル
GKEの Control PlaneはGoogle管理なので、利用者側でアップグレード作業をする必要はありません。
一方Nodeについては手動でのアップグレードもできますが、リリースチャンネルという仕組みを使って自動的にアップグレードができます。Autopilotクラスタはリリースチャンネルに自動的に登録されます。
リリースチャンネルはバージョニングとアップグレードを行う際のベストプラクティスを提供する仕組みです。リリースチャンネルにクラスタを登録すると、GoogleによりControl PlaneだけでなくNodeのバージョンとアップグレードサイクルも自動的に管理されるようになります。
リリースチャンネルは、利用できる機能や安定性の異なる以下3種類のチャンネルを提供しています。利用環境や求められる安定性等に応じて使い分けることが可能です。
- Rapid:最新のバージョンが利用可能。検証目的での利用を推奨
(SLA対象外) - Regular:機能の可用性とリリースの安定性のバランスが取れている
- Stable:最も安定したバージョンを提供。新機能よりも安定性を優先するケースで採用
自動アップグレードタイミングの制御
自動アップグレード自体は便利な機能ですが、クラスタが知らないうちにアップグレードされると困るという場合もあるのではないでしょうか。GKEでは自動アップグレードのタイミングをコントロールする仕組みも提供しています。
GKEのメンテナンスの時間枠という設定をしていただくことで、アップグレードなど自動メンテナンスを許可する時間枠を設定できます。またメンテナンスの除外を設定することにより、自動メンテナンスを禁止する期間も指定できます。
- メンテナンスの時間枠:自動メンテナンスを許可する時間枠を設定。営業時間・
ピーク時間帯を避けてアップグレードしてほしいケースやオンコール対応のしやすさなどから日中の業務時間帯にアップグレードをしてほしいケース等で利用 - メンテナンスの除外:自動メンテナンスを禁止する時間枠を設定。大型イベント期間中や人手が足りない時期などアップグレードをしてほしくない期間を設定するケース等で利用。マイナーバージョンのアップグレード
(例:1. 22 -> 1. 23) を最大180日間[1]停止することも可能
これらの機能を活用することにより、自動アップグレードによる思わぬサービス影響を抑えたり、人員の不足やイベントの期間中等を避けたりと、より安全なタイミングでアップグレードができるよう制御することが可能になります。
また、ロールアウトシーケンスという機能を活用することにより、複数クラスタ間での自動アップグレードの順序を制御することもできます。
例えば、開発環境→ステージング環境→本番環境という順番で自動アップグレードと検証を行うことで、より安全に本番環境をアップグレードできるようになります。

アップグレードに影響のある構成/API利用の検知
また、GKEには今後のマイナーバージョンでサポートされない構成やKubernetes APIがクラスタで利用されていることを自動的に検出し通知するDeprecation Insightsという機能も提供しています。
例えばDeprecation Insightsでは以下のようなDeprecationを自動的に検出することが可能です。
- 1.
25で削除されるKubernetes APIの利用 - 1.
25で削除されるリソース (PodSecurityPolicy) の利用 - 1.
24でサポートされなくなるDockerベースのノードイメージの利用
この機能により、次バージョンで削除予定のAPIの利用やサポートされない構成が検知されるとマイナーバージョンの自動アップグレードが一時停止される挙動となるため、知らないうちにクラスタがアップグレードされて手元のマニフェストと互換性がなくなっていた、というようなトラブルの発生を防ぐことが期待できます
特徴② 高い拡張性
2つ目のGKEの特徴として、高い拡張性を持っていることが挙げられます。
例えばGKE Standardのクラスタあたりの最大ノード数は15,000です。またGKEは単純なNode数上限の高さだけではなく、より大規模なワークロードの実行に適した構成オプションやリソース拡張のしやすい仕組みを提供しています。
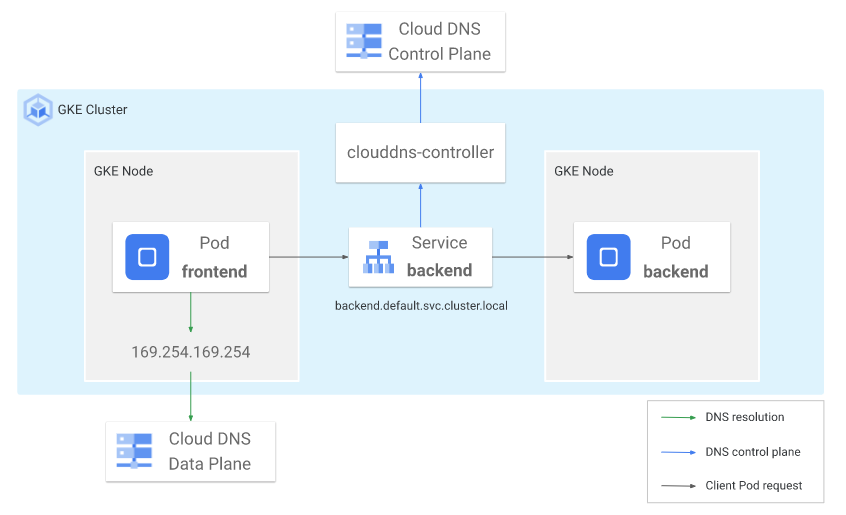
マネージドDNSの利用
GKEでは従来kube-dnsというクラスタ内に存在するDNSコンポーネントを使って名前解決を行っていましたが、クラスタの規模が大きくなるとkube-dnsへの負荷が高くなり問題が発生するようなケースもありました。
そこで現在はCloud DNS for GKEという構成オプションが利用可能になり、名前解決をCloud DNSというマネージドサービスで行うことが可能となりました。
このオプションを有効にしkube-dnsではなくマネージドサービスを利用することで、より高いスケーラビリティが期待できます。
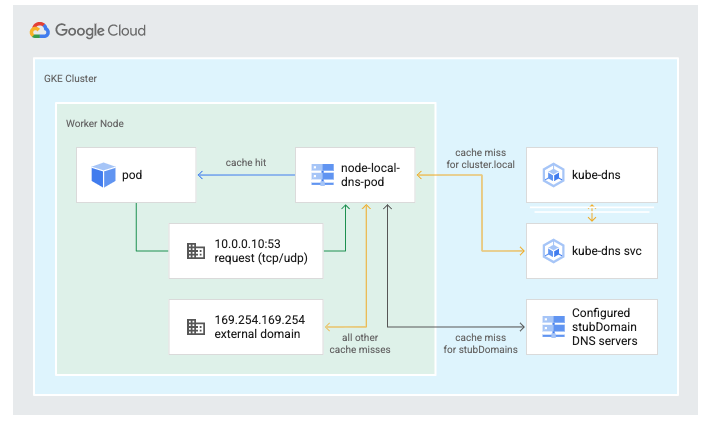
また、NodeLocal DNSCacheというアドオンを有効化することで各Node上でDNSキャッシュを提供できます。
この機能によりPodから送られる名前解決のリクエストを、まずそのPodが動いているNode上のキャッシュで解決しようとするため、クラスタ内のkube-dnsやCloud DNSに対するクエリ発行が抑えられ、DNS側
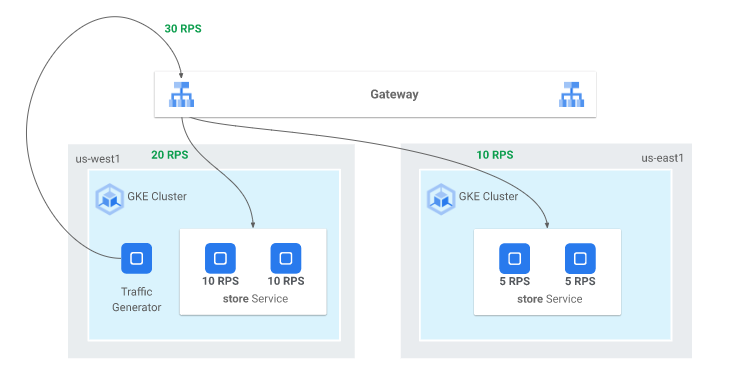
複数クラスタ間での負荷分散
1クラスタあたりのリソース上限の観点やリージョンレベルでの可用性の観点から、複数クラスタ構成を選択するケースもあります。
GKEでは、複数クラスタ間でのNorth-Southトラフィック
- Multi-cluster Ingress
(MCI) (GA) - Multi-cluster Gateway
(MCG) (Preview)
その中でもMutli-cluster Gateway
例えばMCGのキャパシティベースのルーティングを使うとRPSベースの負荷分散が実現でき、とあるクラスタのキャパシティ
特徴③ 豊富な周辺サービス・エコシステム
GKEの特筆すべき特徴の最後として、多くの周辺サービス、エコシステムが提供されていることが挙げられます。
例えば、Google CloudではKubernetesエコシステムのマネージドサービスとして以下のものを提供しています。
- Google Cloud Managed Service for Prometheus
(GMP) - OSSの監視プラットフォームであるPrometheusのマネージドサービス。
- Anthos Service Mesh
(ASM) - OSSのサービスメッシュプロダクトであるIstioのマネージドサービス。
- Policy Controller
- OSSのポリシーエージェントであるOPA Gatekeeperのマネージドサービス。
Kubernetes運用における課題の1つとして、エコシステムの運用が大変だという話をよく聞きます。
可能なものはOSSを上記のようなマネージドサービスに置き換えることによって、コンポーネントのアップグレードやセキュリティ対応、可用性の担保、リソース管理など、いわゆるDay2 Operationの負荷を軽減することが期待できます。
他にもGKEでは以下のようなコンテナセキュリティ関連のマネージドサービスとの連携もサポートしています。
- Container Analysis
- コンテナイメージの脆弱性をスキャンしてくれるサービス。Artifact RegistryやContainer RegistryといったGoogle Cloudマネージドのコンテナレジストリ上にPushされたイメージを自動的にスキャンしたり、オンデマンドでコンテナレジストリやローカルにあるイメージをスキャンすることができる。
- Binary Authorization
- 信頼できるコンテナイメージのみがGKEクラスタにデプロイされることを保証してくれるサービス。
「信頼できないリポジトリが提供しているベースイメージやコンテナイメージにマルウェアや脆弱性が含まれている」 リスクや 「CI/ CDをバイパスした有害なコンテナイメージがデプロイされる」 リスクを低減することができる。 - Container Threat Detection
- 実行中のコンテナに対する振る舞い検知機能を提供するサービス。元のコンテナイメージに存在しなかったバイナリ
(マルウェアやクリプトマイナー等) の実行やリバースシェル実行 (ボットネット) のような異常な挙動・ 攻撃を検出することができる。 - GKE Security Posture
- GKE上で動くワークロードのKubernetesマニフェストやコンテナイメージの脆弱性を継続的にチェックしてくれるサービス。例えばワークロードの構成スキャンを有効化すると、特権コンテナの利用や
runAsNonRootが設定されていないワークロード等KubernetesのPod Security Standardsに沿っていないワークロードを検出する。
その他、Backup for GKEというGKE上のワークロードのバックアップ・
まとめ
本記事ではコンテナオーケストレーションであるKubernetesの概要とGKEのアーキテクチャ、特徴について紹介しました。
GKEはGoogle Cloudが提供するフルマネージドなKubernetesであり、Kubernetesをより簡単かつ安全に使っていただくための機能を多く提供しています。
コンテナアプリケーションを中〜大規模で利用するようなケースや、様々なOSSやKubernetesエコシステムを活用し自社に最適化されたプラットフォームを構築したいようなケースでご活用いただけるのではないかと思います。
次回はサーバーレス開発とCloud RunというGoogle Cloudサービスについて紹介します。