「SREの現場から」と題した本連載では、さまざまな企業におけるSREの実践事例を不定期に紹介していきます。
こんにちは、LINE株式会社の加藤(maru)です。SREチームに所属し、主にLINEスタンプや着せかえ、ホームタブ、ウォレットタブでEmbedded SREとして信頼性の改善に従事しています。
LINE株式会社は、コミュニケーションアプリ「LINE」を機軸として、コミュニケーション・コンテンツ・エンターテイメントなどモバイルに特化した各種サービスの開発・運営と広告事業に加え、Fintech事業、コマース事業などを展開しています。基軸となる「LINE」アプリは2023年現在、世界で約2億人が利用しており、LINEスタンプと呼ばれる画像を用いたコミュニケーションがユーザー同士で活発に行われている点が大きな特徴のひとつです。
これから数回にわたり、SREの私が主に担当しているLINEスタンプをとりまく過負荷対策の事例を紹介していきます。それにあたってまずはSREを含むLINEスタンプの組織、そしてLINEスタンプに求められる機能とそれを実現するシステムアーキテクチャについて概観しておきます。
LINEスタンプの組織とSRE
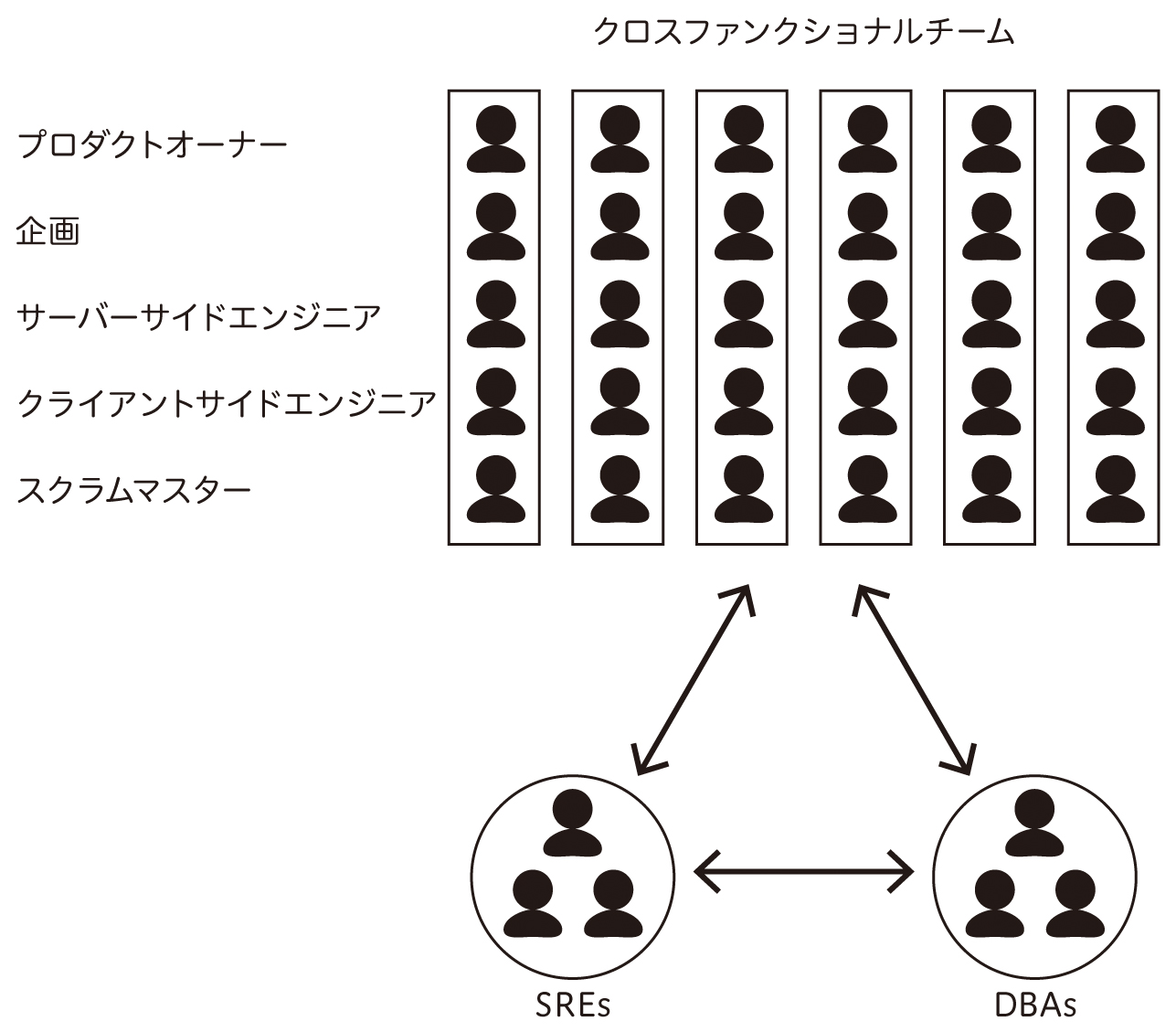
LINEスタンプのプロダクト開発は6つのクロスファンクショナルチームで並行しており、それぞれのチームごとにプロダクトオーナー・企画担当者・サーバーサイドエンジニア・クライアントサイドエンジニア・QAエンジニア・スクラムマスターが所属しています。私たちSREはこれらクロスファンクショナルチームには所属せず、横断的に信頼性の改善を行っています。ただし、オンコール対応はサーバーサイドエンジニアと同じ輪番グループに参加しています。また、MySQLやMongoDBやRedisなどのデータベースの管理運用は、別途専属のDBAチームがそれぞれ担当しています(図1)。
図1 LINEのクロスファンクショナルチーム
私たちSREチームの特徴を『Team Topologies』[1]という書籍の定義で表現すると、開発のバリューストリーム(調査分析→企画→設計→開発→運用)に沿って信頼性を改善するStream alignedチームであり、このLINEスタンプの開発を通じて得た知識や経験を他チームに共有するEnablingチームでもあります。そのため、私たちはSWE[2]と同様にJavaやKotlinで書かれたアプリケーションに変更を加えることもありますし、運用負荷を軽減するための小さなツールを開発したり、モニタリングダッシュボードやアラート設定を整備したりすることもあります。
SREチームは現在4名で構成されており、それぞれが異なるバックグラウンドを持っています。過去にJavaやScalaでWeb API開発をしていたり、DBAをやっていたり、クラウドインフラエンジニアであったり、DevOpsのエンジニアであったりしました。それぞれのメンバーが各自の経験を生かし、たとえば専属のDBAとより専門的なコミュニケーションを取ったり、社内向けにモニタリングツールやCI/CDを支援するツールを提供するプラットフォームチームに対してフィードバックを行ったりしています。
こういった事情から、これから紹介される事例にはあなたの考えるSREの領分でないことも含まれるかもしれません。たとえば、アプリケーション自体の変更はSWEのタスクに感じられる方もいると思います。しかし、ここに紹介する事例が私たちのリアルであり、私たちが維持・改善しようとしている信頼性に直結するプラクティスです。もちろん、すべての対策をSREだけで実施しているわけではなく、SWEやDBAやビジネスサイドなど、すべてのステークホルダーの協力を仰ぎながら行っています。ですので、もしも紹介するプラクティスがSREであるあなたの担当範囲でない場合、担当しているエンジニアらと一緒に読んでいただき、そして議論の種になることができれば何よりだと考えています。
LINEスタンプの機能とシステムアーキテクチャ
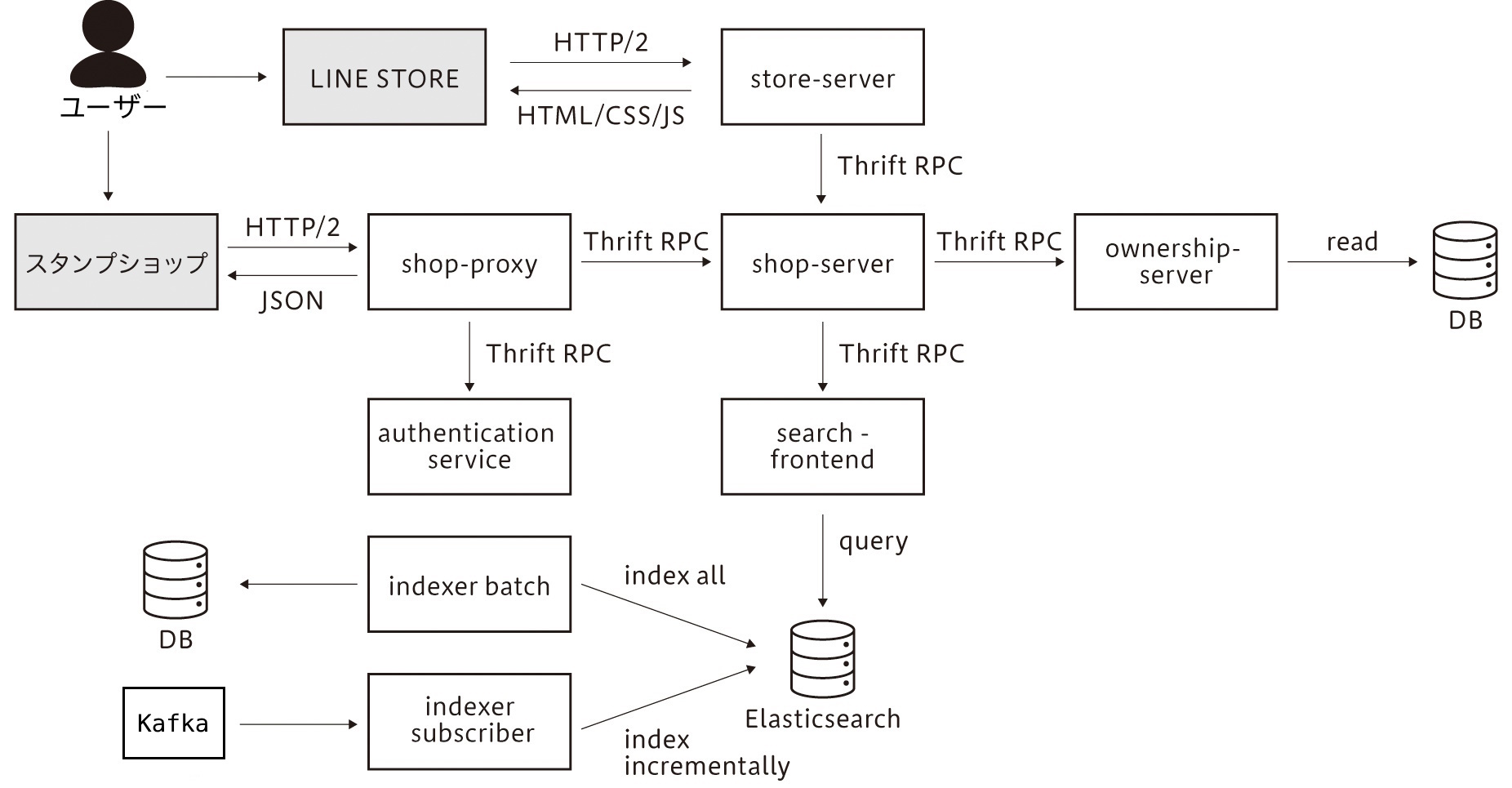
「LINE」アプリにおいてユーザーがLINEスタンプを使うには、都度購入してスタンプを所有する他に「LINEスタンプ プレミアム」というサブスクリプションサービスへ加入する方法や、LINE公式アカウントの友だち追加や特定NFTを所有するといったミッションをクリアする方法があります。これらの機能を実現するLINEスタンプのシステムのサーバーサイドは、20名強のエンジニアが開発しています。多数のエンジニアが機能追加や変更を並行して実施できるように、マイクロサービスアーキテクチャで実装しています[3](図2)。
図2 LINEスタンプ・LINE STOREのアーキテクチャ
LINEスタンプのシステムが提供する機能は、主に下記の4つです。
- 「LINE」アプリ上でスタンプを購入・ダウンロードするための導線であるスタンプショップ
- ブラウザ上でスタンプなどを購入・ダウンロードするための導線であるLINE STORE
- 作成したLINEスタンプの情報や画像を管理する機能
- ユーザーがLINEスタンプを送受信できる機能
このうち、本連載の過負荷対策の舞台となるスタンプショップやLINE STOREでは、公開されているLINEスタンプを検索したり、購入したりできるようになっています。この検索エンジンにはElasticsearchを利用しており、イベントやバッチを用いて検索データを更新するようにしています。また、「shop-proxy」というgateway機能を持つサービスがあり、ここで認証やロードシェディング(Load Shedding)、HTTP-to-RPCの変換を行っています。「shop-server」はさまざまなリクエストを集約したり、ルーティングしたりしています。「search-frontend」はElasticsearchのフロントエンドになっており、Elasticsearchへのクエリを組み立てたり、Elasticsearchからのレスポンスをキャッシュしているレイヤーです。
あけおめLINEの過負荷とその対策方針
こうした組織とアーキテクチャのもとで、私たちは日々さまざまな障害に直面し、原因を調査・解決しています。本連載ではそうした障害のうち「あけおめLINEの過負荷」への対策にフォーカスし、私たちの試行錯誤と独自の工夫も含め、詳細に紹介していきたいと考えています。
あけおめLINEとは
さて、「LINE」アプリでは、毎年1月1日の午前0時ちょうどに多くのユーザーが「あけましておめでとう!」というメッセージを送り合います。このメッセージはテキストメッセージのこともありますし、LINEスタンプを送り合うこともあります。特にLINEスタンプを送り合う文化のことを「あけおめスタンプ」と呼んでおり、このときのLINEスタンプの送信数は平日のピーク時間帯の約13倍にもなります(図3)。また新年挨拶用のLINEスタンプも数多く発売され、ビジネス的にも技術的にも重要なタイミングです。
図3 新年あいさつ時のスパイク

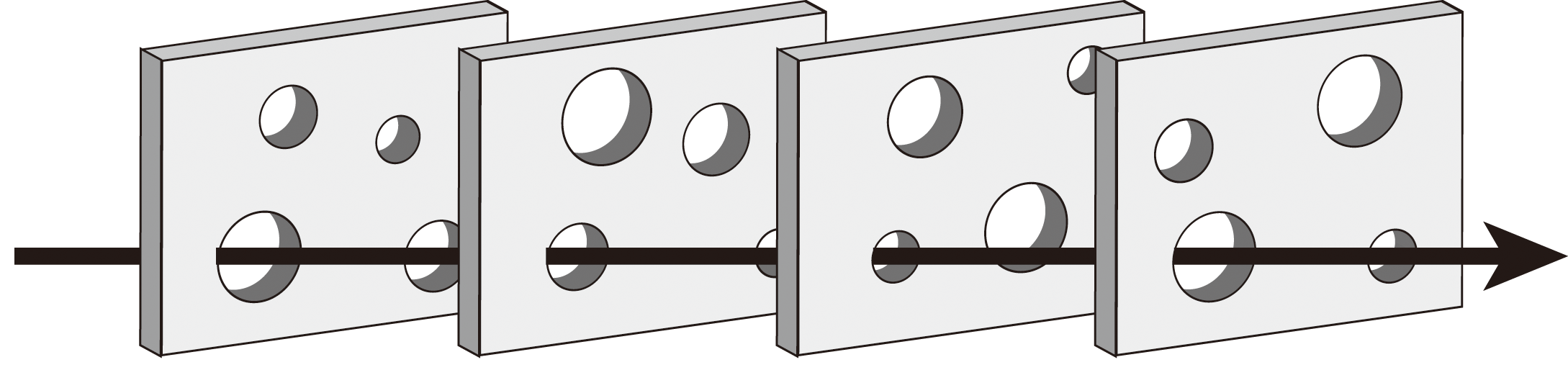
特に技術面では、一年間隔で必ず訪れる季節性のイベントということもあり、この「あけおめLINEの過負荷」への対応は年々ブラッシュアップされています。これからさまざまな対応事例を紹介していきますが、私たちもすべてのマイクロサービスで完璧に対応できているわけではありません。スイスチーズモデル(図4)と呼ばれる不完全な対応を複数枚重ねることで安定したサービス提供を目指しています。事例を参考にされる際には、完璧主義に陥らないようにご注意ください。
図4 スイスチーズモデル
また、「あけおめLINE」は季節性のある特異なアクセス負荷のため、あなたの管理するサービスでは同じような問題を抱えていないかもしれません。しかし、これから紹介するさまざまな対策は、突発的な過負荷一般に効果が期待できるものも含んでいます。また、負荷への適切な対策をすることで、過剰なサーバーリソースを用意する必要もなくなり、コスト最適化にも繋がります。私たちも年々増えるアクセス負荷に反して、サーバーのコストは年々10%から20%ほど削減できています。
リスクとコストを鑑みた過負荷対策
これから紹介していくさまざまな対応において重要となってくるのが、「リスク」と「コスト」の考え方です。ここでそれらの比較衡量の重要性が如実に現われた事例をひとつ紹介しましょう。
「このマイクロサービスのサーバー台数を40倍にしましょう。もしくは、アーキテクチャを大きく変更させてください」
これは過負荷による障害が2年連続で発生していた「shop-proxy」の関連コンポーネントで、その年の「あけおめLINE負荷への対応」を始める際の会議でのとあるSREメンバーからの発言です。
40倍のサーバー増設は一見過剰な要求に見えますが、事情があります。まず、ここ数年でこの「shop-proxy」の関連コンポーネントに大きな変更を加えており、その結果ボトルネックが移動、さらにアクセス数の予測が難しくなっていました。またそれが原因で、2年連続で「あけおめLINE」による過負荷で障害が発生していました。そしてこの障害により、「あけおめLINE」のアクセス数予測の参考になるデータが正しく計測できず、過負荷の障害可能性が高くなるという悪循環が発生していました。
そこで我々SREチームからは、2つの案を提案しました。第一案は、前述のSREメンバーからの発言にもあったように、一時的な過剰投資をしたうえで「あけおめLINE」のアクセス数や傾向について正確なデータを収集し、翌年に適切な縮退を行うというものです。第二案は、SREチーム主導で負荷軽減のための大きなアーキテクチャ変更です。
一方の第一案はローリスク・ハイコストなプランです。他方の第二案はエンジニアリソースを多少必要とする点やアーキテクチャ変更を伴うことから、ミドルリスク・ミドルコストなプランだと言えます。
議論の末、最終的には第二案を採用してアーキテクチャを変更し、過負荷の予防ができました。この件で私たちは「リスク」と「コスト」を軸にさまざまなことを考えました。これは今後紹介していく事例においても重要な視点となっています。
リスクマネジメントとその分類
「リスク」と「コスト」の検討のために必要なのが「リスクマネジメント」の考え方です。
私たちはしばしば、障害対策として予防ばかりを重視してしまいます。しかし特に過負荷による障害では、ユーザーの行動などアンコントローラブルな要素が多数存在するため、完璧な予防策はありません。つまり、予防以外の対策もバランスよく行う必要があります。リスクマネジメントの手法で整理された対応方法は、さまざまな対応を俯瞰することに役に立ちます。
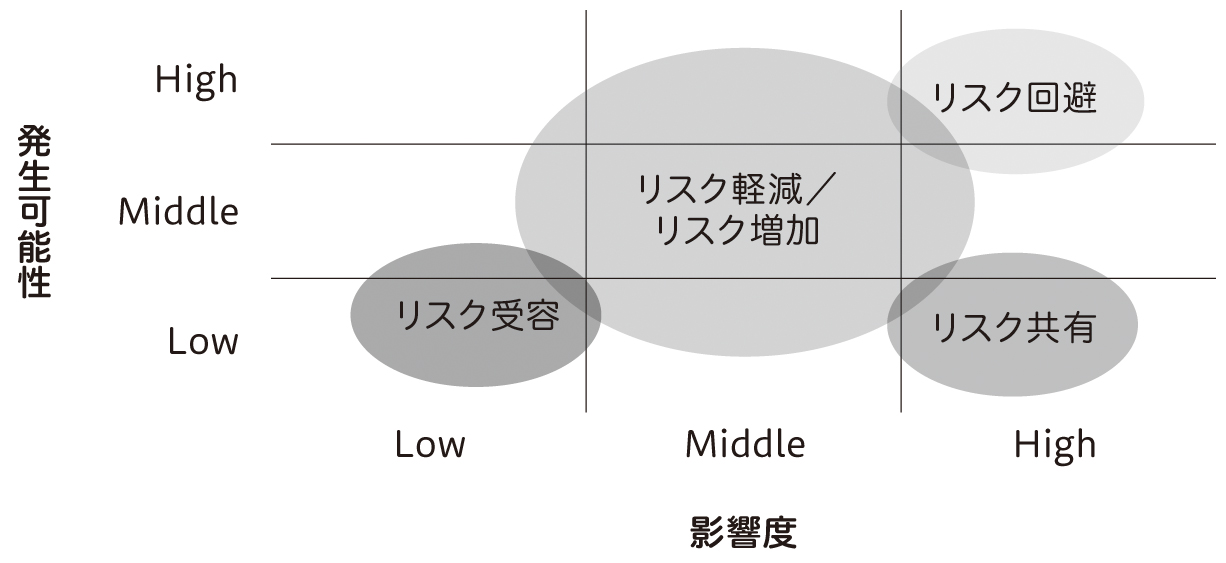
一般的に、「発生可能性」と「影響度」の2つがリスクに関する主な指標です。そして、それぞれの大小によって合理的な対策は変わります。リスクマネジメントの国際規格であるISO31000を参考にすると、リスクへの対応は表1の7つに分類できます。
表1 リスク対策分類
| 大分類 |
対処 |
具体例 |
連載予定 |
| 軽減 |
発生可能性の低減 |
キャパシティプランニングの実施 |
第1回(今回)〜第3回 |
| 共有 |
リスクの共有・移転 |
フォールバック先の準備 |
第4回 |
| 受容 |
リスクの受容 |
リスクについてステークホルダーと合意し、何も対応しない |
第4回 |
| 軽減 |
影響の低減 |
サーキットブレイカーの活用 |
第4回 |
| 増加 |
リスクの増加 |
ユーザーが集中するタイミングに、キャンペーンも企画し、より売上をあげる |
第5回 |
| 軽減 |
リスク源の除去 |
エラー時にもサービス提供が止まらないようにする |
第5回 |
| 回避 |
リスクの回避 |
機能やサービス自体の廃止 |
第5回 |
これらの対応を「発生可能性」と「影響度」を軸に持つR-Mapにプロットすると図5のようになります。特に「リスクの増加」は違和感がある方もいるかもしれませんが、リスクとは不確実さのことを指し、それにはポジティブな不確実さも含まれます。したがって、リスクを増加するという対処を選択することもあります。
図5 リスク分析におけるR-Map
本連載では、私たちが行った対応をこの7つの項目の視点から分類し、それぞれについて細かく紹介していきます。各項目は可能な限り独立した内容となるよう心がけましたので、頭から順に通して読む必要はありません。辞書のように気になった項目から参照してみてください。
リスクマネジメント(1) —— 発生可能性の低減
最初に紹介するのは「発生可能性の低減」です。過負荷の発生可能性を減らすには、アクセス数自体を減らすこと、そして十分な処理性能を用意することの2つで達成できます。ひとつずつ見ていきましょう。
キャンペーンの開催期間を長く取る
ユーザーによる「あけおめLINE」をより盛り上げるために、私たちはさまざまなキャンペーンを同時期に実施しています。たとえば、対象のスタンプを購入するとおみくじが引けたり、ユーザー自身が一年間に送信したLINEスタンプトップ3を対象のSNSにシェアすることでLINEポイントが獲得できるキャンペーンです。
キャンペーンの内容や期間は年によって異なり、2023年のお正月に向けたキャンペーンでは、2022年12月初旬から始まる約1ヶ月間のキャンペーン期間となりました。これにより、ユーザーのアクセスも分散し、過負荷になるリスクの軽減効果がありました。
しかし、開催期間を長く取ることはメリットばかりでもありません。重要なキャンペーンが続くということは、それだけ開発者に精神的な負担がかかり続けることを意味します。実際に、1ヶ月間続いたキャンペーンの開発リーダーに聞いたところ、「長いキャンペーンは監視のストレスでとても苦しかった」とのことでした。この精神的な負担を和らげるために何ができるかは、より深く検討する必要がありそうです。
表示されるコンテンツの数を減らす
「LINE」アプリのホームタブでは、パーソナライズされたおすすめスタンプ一覧や人気のスタンプや新着のスタンプなど、さまざまなコンテンツが列挙されています。ホームタブはアプリを起動した際の初期画面であり、表示した時点でアクセスが発生します。パーソナライズされた一覧はキャッシュヒット率も低いため、「あけおめLINE」時では表示されるコンテンツ数を30%減らす対応を必要に応じて実施しています。
コンテンツ数の変更はアプリケーションの再起動不要で動的に適用できるようにしています。この動的な適用のためのConfiguration Repositoryとして、私たちはLINEが開発しOSSとして公開している「Central Dogma」を利用しています。Central DogmaはGitHubのリポジトリと連携する機能を持つため、当日は「あけおめLINE」のタイミングで必要に応じて適用できるように、プルリクエストを事前に用意してCPU使用率をモニタリングしていました。
こういったサービス品質の「劣化」のことを「グレースフル・デグラデーション」と呼びます。サービスの品質とコストを検討し、グレースフル・デグラデーションを適切に実施するには、ビジネス側との合意形成などの事前準備が必要不可欠ですが、効果が高い対策のひとつです。
多段キャッシュを利用する
私たちはキャッシュを、クライアント・CDN・アプリケーションのローカル・Redisと多段で持ち、プライマリデータを保存しているMySQLやMongoDBへのアクセス数を減らすようにしています(図6)。特に更新頻度が低いデータについては、積極的に「LINE」アプリでキャッシュしており、キャッシュの更新のための同期も1日1回行うようにしています。
図6 多段キャッシュ
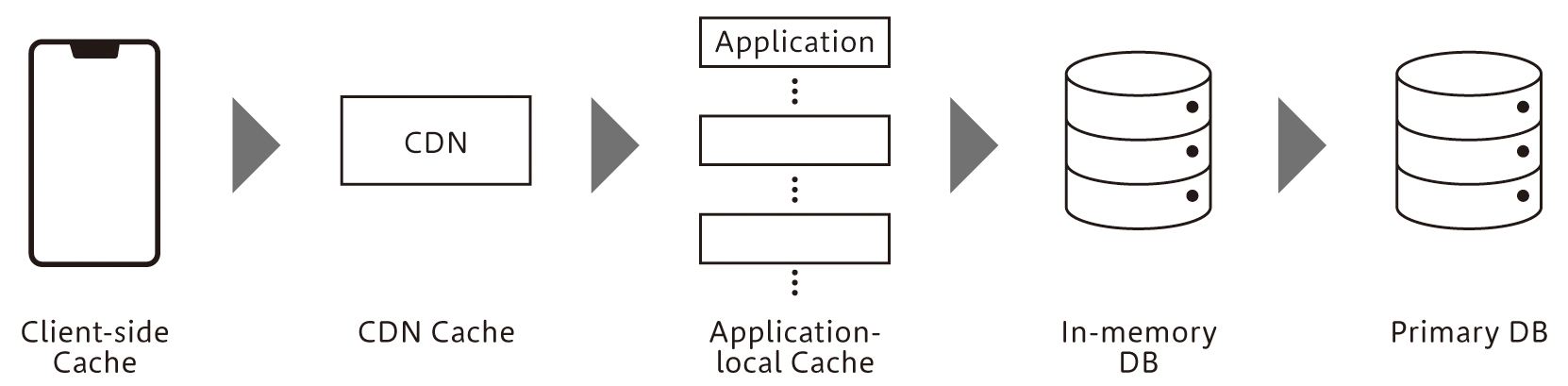
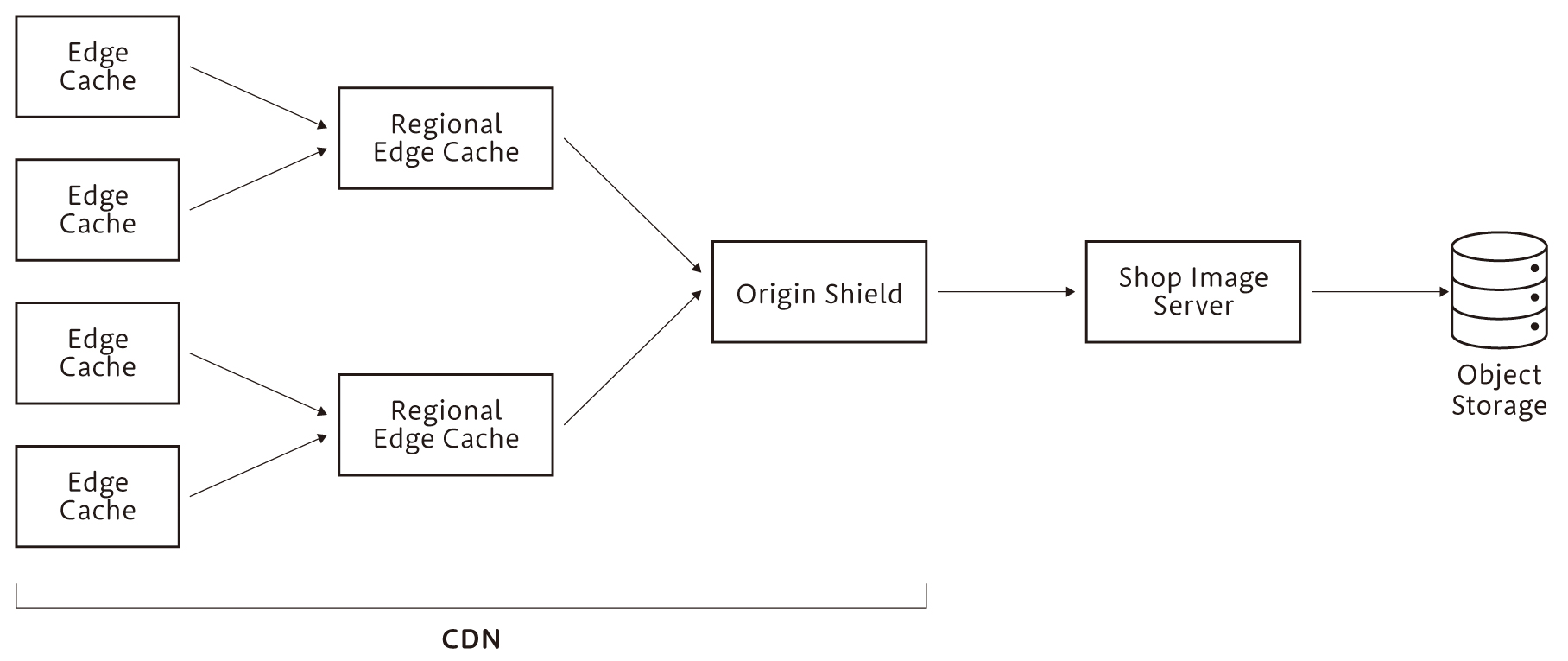
CDNにはAkamai CDNやAmazon CloudFrontなどを併用していますが、特にAmazon CloudFrontではAmazon CloudFront Origin Shieldをキャンペーン期間のみ有効にして、オリジンサーバーへのアクセス数を減らしています。Amazon CloudFront Origin Shieldは、地理的に異なるリージョンからのアクセスを一本化する機能です(図7)。「LINE」アプリは日本を中心に台湾やタイなどのさまざまな国と地域で利用されていることもあり、この機能を一時的に有効にすることでオリジンサーバーへのアクセス数を20%ほど減らすことができました。もちろん、その分コストが発生していますが、過負荷によるリスクと比較するとリーズナブルな選択肢と言えます。
図7 CDNを用いた画像配信のキャッシュ
クライアントやCDNでデータを返すことのできなかったリクエストは、私たちのサーバーに到達します。私たちのサーバーでは、基本的にアプリケーションのヒープメモリにキャッシュしており、アプリケーション再起動時にも備えてRedisにもキャッシュしています。アクセス制限(Throttling)によって過負荷から守るといった対策を取ることも多いと思いますが、アプリケーションのヒープメモリからキャッシュを使ってユーザーにレスポンスを返すことができれば、Throttlingと同じ程度の処理負荷でユーザーにデータを返すことができるため重宝しています。
しかし、アプリケーションでのオンメモリキャッシュ利用を推進するには、いくつか乗り越えなければいけない課題があります。まず1つ目は、水平スケールと相性が悪いことです。たとえば、数百台のAPIサーバーがあり、秒間10アクセスしかこないAPIの場合、キャッシュしているサーバーへアクセスが振り分けられることが少ないため、ヒット率が悪くなりがちです。2つ目は、モノリシックアーキテクチャと相性が悪いことです。キャッシュするデータをアプリケーションのヒープメモリに持つため、モノリシックアーキテクチャのような多様なAPIを1つのサーバーで持つ場合、メモリが枯渇しやすくなります。最後に、キャッシュの有効期限(TTL)とメモリ溢れ時の挙動(eviction)をうまく設計する必要がある点も注意が必要です。
水平スケールの問題とモノリシックアーキテクチャの問題については、マイクロサービスアーキテクチャ(以下MSA)やモジュラーモノリスアーキテクチャ(以下MMA)の適用が効果的です。特定の役割に特化したサーバーをサービスごとに用意することで、その役割以外のデータをオンメモリにキャッシュする必要がなくなります。また、特定の役割に関連するアクセスのみを処理すればよいため、モノリシックアーキテクチャよりサービスごとのサーバーの台数は少なくなります。もちろん、アーキテクチャの選定にはさまざまな要素が関連するため、オンメモリキャッシュのためだけにMSAやMMAを採用するのは過剰でしょう。MSAやMMAを採用する際の利点として捉えるのが肝要だと思います。
ローカルキャッシュの有効期限(TTL)とメモリが溢れた際の退避(eviction)の実装については、成熟したライブラリを使うことを推奨します。メモリ溢れ時の退避アルゴリズムには、Least Frequently Used(LFU)という参照頻度が低い、つまりキャッシュが有効に使われていないものを優先的に退避するアルゴリズムや、Least Recently Used(LRU)というしばらく参照されていないものを優先して退避するアルゴリズムなどがあります。キャッシュ退避アルゴリズムはキャッシュヒット率やメモリ効率やレイテンシに大きく影響するため重要ですが、正しく理解して実装するのは難易度が高いものです。そのため、私たちはW-TinyLFUアルゴリズムを採用している「Caffeine」というJavaライブラリを利用しています。また、キャッシュの種類ごとにPrometheus用のメトリクスを出力しており、キャッシュヒット率が低いものは定期的に見直ししています。
イベントループ用のスレッドをブロッキングしない
過負荷による障害には、自身のサーバーが過負荷になって応答を返せないパターンの他に、通信先であるDBやAPIサーバーが過負荷になり連鎖的な障害(カスケード障害)になるパターンがあります。
カスケード障害に対してはサーキットブレイカーが重要な対策のひとつですが、これについては本連載第4回の「影響の低減」にて説明する予定です。「発生可能性の低減」にあたるリスク対応としては、アプリケーションのイベントループスレッドのブロッキングを避けることです。通信先からの応答を待っている間にイベントループスレッドがブロックされず他の処理を継続することで、カスケード障害のリスクを小さくできます。
私たちは、Kotlin coroutineやRxJavaなどを用いてこれを実装しています。また、イベントループスレッドをブロッキングしてしまうような誤った実装に気づくためのに、Hiccup(しゃっくり)monitoringを利用しています。Hiccup monitoringとは、定期的に監視用スレッドのsleepとwake upを繰り返し、GCによる停止やイベントループスレッドのブロッキングなど、実行中のアプリケーションに影響を与える可能性のある一時停止を検知するためのものです。そのほかに、Javaでは「BlockHound」というライブラリをブロッキングの検知に利用しているサービスもあります。
適切なボトルネックを設計する
十分な処理性能キャパシティを用意するためにもっとも重要なことは、サーバーリソースの消費傾向について未知を減らすことです。たとえば、アクセスが増えた際に、どういったサーバーリソースが最初に枯渇するか不明な場合は、監視や即時的な対処が複雑化しやすくなります。私たちは経験的に、ボトルネックを解析することよりも、ボトルネックを設計することの方が簡単だとわかっています。そのため、私たちは過負荷の際に可能な限りCPUリソースが先に枯渇するように、APIサーバーのスペックを選定してチューニングしています。
この際の基本方針は、より少ない労力で致命的なボトルネックを発見し、CPUをボトルネックにすることです。そのため、手間のかかる負荷試験環境や負荷試験シナリオの準備は行っていません。ではどのように検証しているかといえば、実際のユーザーリクエストを特定のサーバーに偏らせて擬似的に高負荷状態を作り、その際のメトリクスを確認しています。このメトリクスは1サーバーあたりの処理性能も明らかにできるため、後述するキャパシティプランニングにも利用されます。
このボトルネックの設計については、連載第2回にて詳しく紹介します。
なお、このようなボトルネックの設計は、スケールアウトが容易なAPIサーバーに対してのみ可能なものです。DBサーバーではAPIサーバーほど柔軟なスケールアウトはできません。そのためDBサーバーについては、コストをかけて事前に十分な処理性能キャパシティを確保するという判断をしています。ただし、バッチやイベントストリームによって冪等な書き込みがされており、アプリケーションからは参照しかされないElasticsearchについては、Elasticsearchクラスタ自体を複数用意してスケールアウトすることもあります。こうすることで、キャンペーン期間が終了した後の縮退作業がクラスタ単位となります。クラスタ内のノードを取り除く作業と比較すると、クラスタ単位で削除するほうが縮退作業が安全かつ簡単になります。
ボトルネックに基いてキャパシティプランニングを行う
ボトルネックの設計を通して「1サーバーあたりのクエリ/秒上限」を確認できますので、これを用いて必要なサーバー台数を計算します。最終的には下記の式が埋まることが目標です。
1サーバーあたりのクエリ/秒上限 * サーバー台数 * 安全マージン > アクセス数
このうち「アクセス数」の予測に求められる精度は、予算と過負荷を受容できるかどうかに依存します。予算が十分ある場合、もしくは過負荷が発生しても大きな問題がない場合は、予測精度を上げるための工夫はそれほど必要ありません。私たちの場合はパブリッククラウドを利用しておらず、サーバー増設がそのまま固定費の増加に繋がるため、予測精度を上げつつ過負荷障害を防止するための工夫を行っています。具体的には、ある程度の精度でアクセス数を予測するために以下の3つの予測方法を併用し、それぞれの予測値の中から悲観的な値を採用しています。
- これまでの「あけおめLINE」アクセス数の変化率の幾何平均
- 平常時と「あけおめLINE」時のアクセス数増加比を前年と比較
- 前年の「あけおめLINE」アクセス数
これらの実際の計算方法やその値を使っている意図については、連載第3回にて詳しく紹介します。
もうひとつ残っているのが「安全マージン」です。安全マージンとは、ここまでで算出した「1サーバーあたりのクエリ/秒上限」や「アクセス数」に誤差があった際(絶対にあります)に、その誤差を吸収するためのマージンです。
この安全マージンは、主に2つの要素を考慮して決定します。ひとつはエンジニアの不安や職人的な勘、もうひとつがスケールアウトの迅速さです。エンジニアの不安や職人的な勘とは、たとえば大規模なアーキテクチャ変更をその年に実施していたり、そもそもこういった過負荷の予防に不慣れだったりと、自身の作業に不安が残っている状態のことを言います。大規模なキャンペーンの準備を行うエンジニアは、キャンペーンが終了するまで、常にそういった不安からくるストレスを感じ続けます。その結果、他のヒューマンエラーを誘発することもあるため、エンジニアの精神衛生を改善するためにも安全マージンを確保しましょう。逆にスケールアウトが迅速に行える場合、たとえば数秒以内にオートスケールが完了するようなケースでは、安全マージンを小さくすることも可能です。
私たちが採用している具体的な安全マージン値についても連載第3回で紹介します。
今回のまとめ
今回は、LINEスタンプなどを担当するSREチームが過負荷対策のために行っていることの全体像と、発生可能性を低減するための対策の一部を紹介しました。リスクマネジメントの分類を行っている大きな理由は、対策が予防にばかり偏っていないかを確認するためです。さまざまな角度から対策を重ねて、ユーザーの信頼性を損なわず、かつビジネスチャンスを活かすリーズナブルな対応のヒントになればと思います。
次回はボトルネックの設計について、具体的な計算や判断基準を深く掘り下げて紹介していきます。



