



門脇
2023年10月2日に
Python 3.
本記事ではPythonにおける並列実行のこれまでと、sub-interpretersが現状どのように使用できるかについて説明します。
なお、執筆にあたり先日開催されたPyCon APAC 2023において、sub-interpretersに関するトークを行ったAnthony Shaw氏の資料やブログ記事なども参考にさせていただいてまとめています。興味のある方は以下のリンクについても参照してみてください。
Pythonの実行環境を取り巻くコンポーネント
最初に、Pythonプログラムの並列実行モデルを理解する際に知っておきたいコンポーネントについて簡単に説明します。
GIL
GIL とは
Pythonオブジェクトに対する安全なアクセスを保証するためのものですが、並列処理の観点では、たとえ複数のコアがあったとしても
インタープリター、サブインタープリター
Pythonインタープリター とは、Pythonコードを読み込み実行するプログラムのことです。Pythonの実装にはいくつかの種類 [1] がありますが、本記事におけるインタープリターとは CPython のことを指しており、先述のGILについてもCPythonにおける概念です[2]。
サブインタープリターはPythonインタープリター内で動作する小さなインタープリターのインスタンスのことです。メインのインタープリターとは別に独立して実行でき、サブインタープリターごとにリソースを割り当てることが可能であるため、複数使用することで並列処理
なお、並列処理や並行処理、あるいはマルチプロセスやマルチスレッドの違いなどに関する解説は本記事では省略します。これらの違いを詳しく知りたい方はWikipediaやIT技術系サイトなどをご確認ください。並列、並行処理については
sub-interpretersとは?
sub-interpretersとは、先述の説明のとおり、メインのインタープリターとは別に独立したサブインタープリターを生成できるようになった機能のことです。ここからはPython 3.
最初にsub-interpretersに関連のあるPEP
PEP 554、PEP 684
2017年にPythonにサブインタープリターを導入するための提案がPEP 554で行われました。PEP 554の本文については以下を参照してください。
PEP 554を簡単に説明すると、
また、PEP 554の関連としてPython 3.
PEP 684の本文については以下を参照してください[3]。
PEP 684が実装されたことによる違いをイメージ図を使用して具体的に見ていきます[4]。
Python 3.
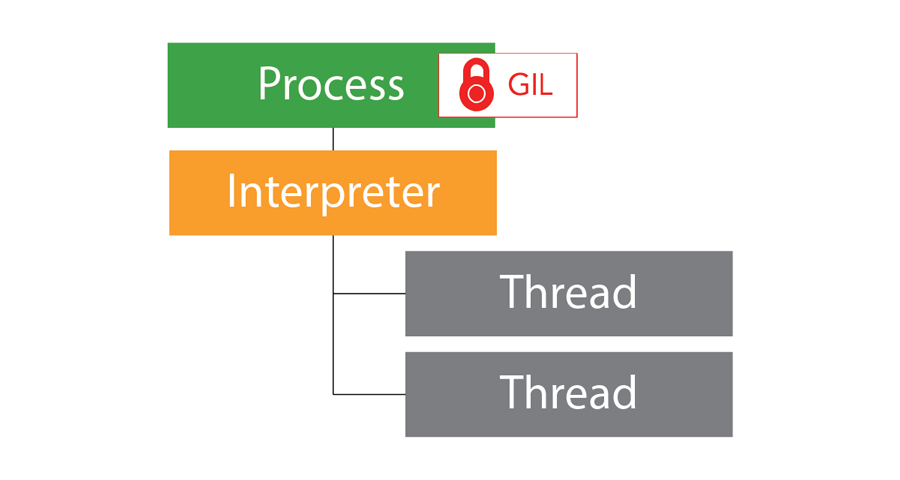
一方、Python 3.
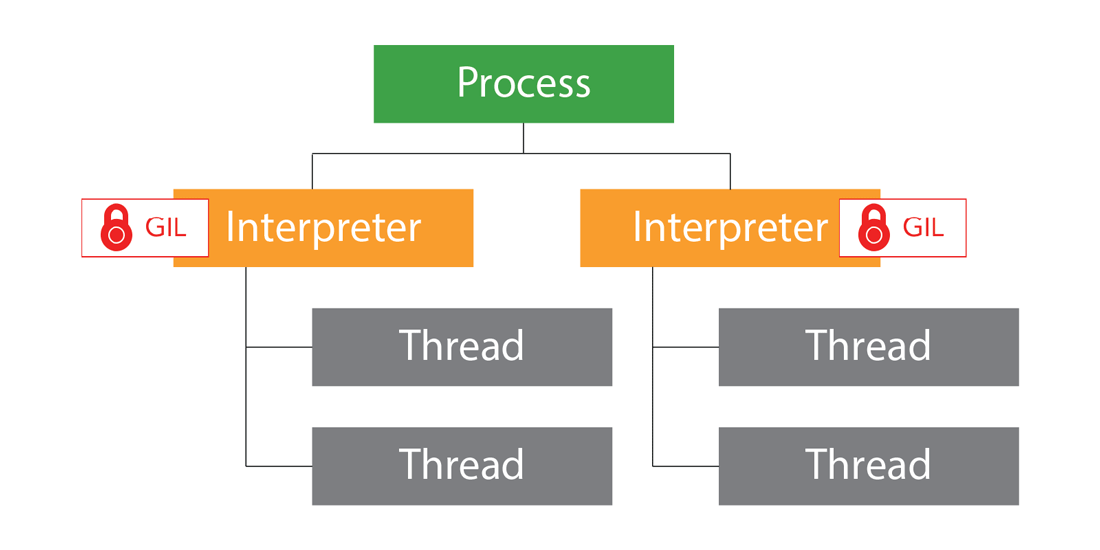
この2つの違いにより、Python 3.
Try it out
ここまで、Python言語の制限やアーキテクチャの変更内容について説明を行ってきました。以降ではsub-interpretersについて、具体的なPythonコードで見ていきます。
残念なことにPython 3.
執筆時点のPythonバージョンは以下を使用しております。
$ python3.12 --version Python 3.12.0
サンプルスクリプト
以下のスクリプトでは、引数で指定された数値範囲に含まれる素数の数を表示する関数calc_を作成しました。以降はこの関数を例に説明していきます。
def calc_primes(num_start, num_end):
prime_count = 0
for num in range(num_start, num_end):
# 試し割法を使って素数を計算
for i in range(2, int(num**0.5) + 1):
if num % i == 0: # 割り切れる数値がある場合は素数ではない
break
else: # ループが最後まで到達したら素数と判定
prime_count += 1
print(f"Prime Count [{num_start:,}-{num_end:,}]: {prime_count}")
まずはcalc_関数を呼び出して動作確認を行うためのスクリプトを以下のように作成しました。rangesリストで指定された数値範囲のタプルを繰り返し実行して結果を表示します。指定する数値は計算コストによる速度の違いを明確にするために、数値範囲を一定にせず範囲の異なる値を指定しています。最終行では処理開始時間と終了時間から処理時間も出力しています。
import time
from prime_number import calc_primes
start_time = time.time() # 処理時間計算用
ranges = [ # 素数を計算する開始値と終了値
(1_000_000, 1_600_000),
(2_000_000, 2_900_000),
(3_000_000, 3_300_000),
]
for num_start, num_end in ranges:
calc_primes(num_start, num_end)
end_time = time.time() # 終了時間
print(f"Processing time: {end_time - start_time} seconds")
このスクリプトを実行した結果は以下のようになりました。rangesで指定した数値範囲の計算が順番に実行され、およそ9.
$ python3.12 example1.py Prime Count [1,000,000-1,600,000]: 42629 Prime Count [2,000,000-2,900,000]: 61176 Prime Count [3,000,000-3,300,000]: 20084 Processing time: 9.447153806686401 seconds
スクリプトの並列化
calc_関数をこれまでのやり方で並列化する場合、threadingモジュールや multiprocessingモジュールを使用する方法があります。ここではthreadingモジュールを使用して以下のようにしてみました。
import threading
import time
from prime_number import calc_primes
threads = []
start_time = time.time() # 処理時間計算用
ranges = [ # 素数を計算する開始値と終了値
(1_000_000, 1_600_000),
(2_000_000, 2_900_000),
(3_000_000, 3_300_000),
]
# ループ内でそれぞれの計算をスレッドで計算開始
for num_start, num_end in ranges:
thread = threading.Thread(target=calc_primes, args=(num_start, num_end))
thread.start()
threads.append(thread)
# すべてのスレッドが完了するのを待つ
for th in threads:
th.join()
end_time = time.time()
print(f"Processing time: {end_time - start_time} seconds")
上記のスクリプトを実行した結果は以下のようになりました。並列実行されたため、計算コストの低い数値範囲の結果が先に出力されていることがわかります。処理時間は先ほどの逐次処理
$ python3.12 example2.py Prime Count [3,000,000-3,300,000]: 20084 Prime Count [1,000,000-1,600,000]: 42629 Prime Count [2,000,000-2,900,000]: 61176 Processing time: 10.180454969406128 seconds
sub-interpretersモジュールの試用
それでは、続いてPython 3.import _xxsubinterpretersとすることでインポートできるようになっています。サンプルスクリプトではas interpretersとして別名を設定しました。
各処理の説明については後述します。
1 import time
2 import _xxsubinterpreters as interpreters
3
4 start_time = time.time() # 処理時間計算用
5
6 # interpreters.run_string()に渡す関数を文字列として読み込む
7 with open("prime_number.py", "r") as f:
8 # ファイルの内容を読み込む
9 calc_prime_script = f.read()
10
11 # 数値範囲のリスト
12 num_ranges = [
13 "1_000_000, 1_600_000",
14 "2_000_000, 2_900_000",
15 "3_000_000, 3_300_000",
16 ]
17
18 intp_id = interpreters.create() # サブインタープリターの作成
19
20 # サブインタープリターの実行
21 for num_range in num_ranges:
22 interpreters.run_string(intp_id, calc_prime_script + f"\ncalc_primes({num_range})")
23
24 interpreters.destroy(intp_id) # サブインタープリターの削除
25
26 end_time = time.time()
27 print(f"Processing time: {end_time - start_time} seconds")
サンプルスクリプトの18行目以降からがsub-interpretersの作成、実行、終了の流れになりますが、これらの概要は下表のようになります。
| 操作 | 使用する関数 | 概要 |
|---|---|---|
| 作成 | .create() |
サブインタープリターを起動してIDを返す |
| 実行 | .run_ |
引数で指定された文字列をスクリプトとして実行 |
| 削除 | .destroy() |
サブインタープリターを削除して終了 |
なお、これらの関数は開発途中ということもあり、calc_関数を外部ファイルからインポートしての実行や、一部のコードは動作しないこともあるようです。したがって、 現時点ではrun_関数に文字列
サブインタープリターの作成create()関数を実行することでサブインタープリターが起動され、IDが返されます。起動されたサブインタープリターはrun_関数に取得したIDとPythonのコードを文字列で渡すことで、サブインターブリターでそのコードを実行します。また、destroy()にIDを渡すとサブインターブリターを終了します。
上記のスクリプトを実行した結果は以下のようになりました。実行時間は逐次処理とthreadingモジュールを使用したサンプルの中間くらいの結果となりましたが、処理順番については逐次処理と同じになっていることにも気がつきます。
処理が逐次処理になる理由について調べてみたところ、現時点の実装では.run_関数を呼び出すとPythonのスレッドはブロッキング
$ python3.12 example3.py Prime Count [1,000,000-1,600,000]: 42629 Prime Count [2,000,000-2,900,000]: 61176 Prime Count [3,000,000-3,300,000]: 20084 Processing time: 9.86731505393982 seconds
sub-interpretersとthreadingモジュールの併用
では、threadingモジュールを併用した場合はどうなるのでしょうか?threading. の引数に interpreters. を渡してサブインタープリターIDと、実行するスクリプトを渡しています。
import time
import threading
import _xxsubinterpreters as interpreters
start_time = time.time() # 処理時間計算用
## interpreters.run_string()に渡す関数を文字列として読み込む
with open("prime_number.py", "r") as f:
# ファイルの内容を読み込む
calc_prime_script = f.read()
# 数値範囲のリスト
num_ranges = [
"1_000_000, 1_600_000",
"2_000_000, 2_900_000",
"3_000_000, 3_300_000",
]
# サブインタープリターのIDとスレッドを格納するリスト
intp_ids = []
threads = []
# 各サブインタープリターの作成とスレッドの開始
for num_range in num_ranges:
intp_id = interpreters.create()
intp_ids.append(intp_id)
thread = threading.Thread(
target=interpreters.run_string,
args=(intp_id, calc_prime_script + f"\ncalc_primes({num_range})"),
)
thread.start()
threads.append(thread)
# すべてのスレッドが完了するのを待つ
for thread in threads:
thread.join()
# すべてのサブインタープリターを破棄
for intp_id in intp_ids:
interpreters.destroy(intp_id)
end_time = time.time()
print(f"Processing time: {end_time - start_time} seconds")
上記コードの実行イメージ図は以下のようになります。interpretes.が繰り返し回数分実行され、起動したサブインタープリターごとに interpreters.を実行しています。
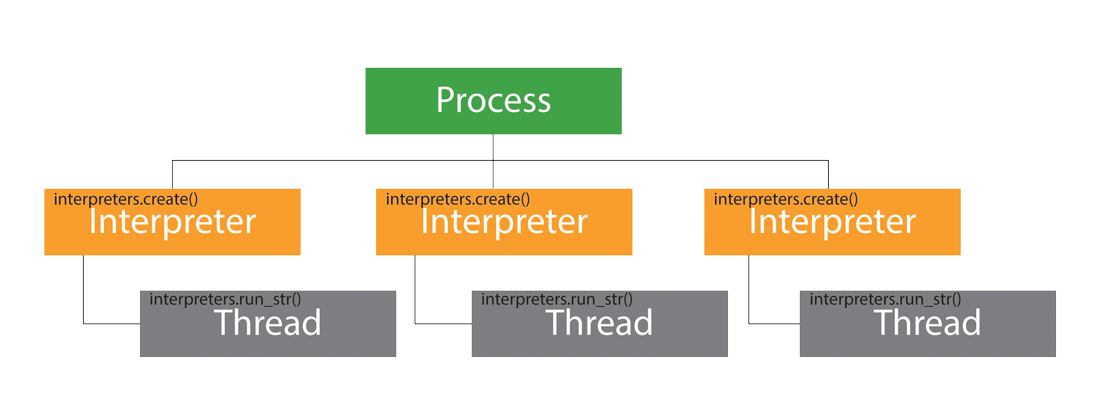
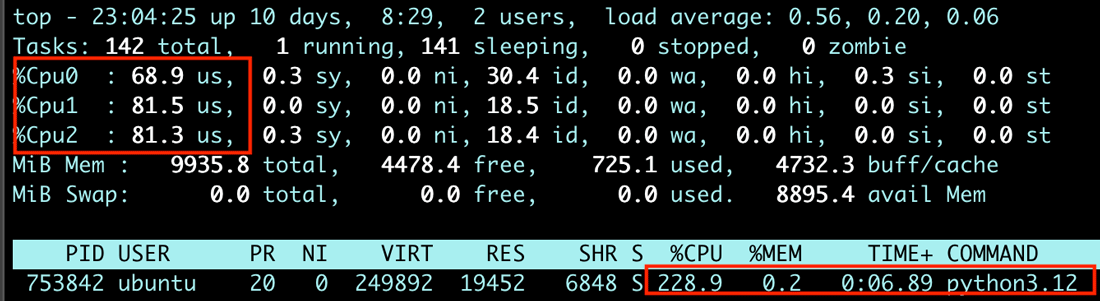
実行結果は以下のようになりました。なんとこれまでの実行時間のおよそ半分で処理が完了しており、開発途中とはいえsub-interpretersに変わった際のパフォーマンスの違いを体験できた気がします
$ python3.12 example4.py Prime Count [3,000,000-3,300,000]: 20084 Prime Count [1,000,000-1,600,000]: 42629 Prime Count [2,000,000-2,900,000]: 61176 Processing time: 5.321488618850708 seconds
sub-interpretersとその他のモジュールの違い
繰り返しになりますが、Pythonにおけるsub-interpretersの実装はPython 3.
これまでPythonで使用されてきた並列・
| モジュール名 | 実行種別 | インスタンス起動時間 | 用途 |
|---|---|---|---|
| threading | 並列 | 小 | IOバウンドで複数コアを必要としない処理 |
| asyncio | 並行 | 最小 | IOバウンドで複数コアを必要としない処理 |
| concurrent. |
並列・ |
小〜大 | CPU、IOバウンドで複数コアを必要とする処理 |
| multiprocessing | 並列 | 大 | CPU、IOバウンドで複数コアを必要とする処理 |
| sub-interpreters | 並列 | 中 | CPU、IOバウンドで複数コアを必要とする処理 |
まとめ
PythonをGIL制限から解放する開発は着々と進んでいるようです。最近ではPEP 703でCPythonでGILをオプションにして、インタープリターごとにGILと協調して動作させる提案が承認されました。PEP 554も含めたこれらのsub-interpretersによる変更は、Pythonにおけるマルチスレッディングとマルチプロセッシングをより効率的に行える選択肢となるに違いありません。
Python 3.