全国銀行資金決済ネットワーク(以下、全銀ネット)とNTTデータは12月1日、2023年10月10日~11日にかけて全国銀行データ通信システム(以下、全銀システム)で発生した通信障害に関する報道関係者向けの説明会を開催しました。本件についてはNTTデータが11月6日に行った途中経過報告の内容をもとにレポートしましたが、今回、全銀ネットとNTTデータが揃って会見を行ったことで、より詳細な障害の原因が判明したので、あらためてその内容を検証してみたいと思います。
説明会の登壇者。左から、全銀ネット 企画部長 千葉雄一氏、事務局長兼業務部長 小林健一氏、理事長 辻松雄氏、NTTデータ 代表取締役社長佐々木 裕氏、取締役副社長執行役員 鈴木正範氏

なお、全銀ネットとNTTデータは、今回の障害に関して金融庁より受領した報告徴求命令に従い、それぞれ11月30日付で金融庁に報告を完了しています。今回の会見はその報告完了を受けて開催されました。
あらためて「10月10日に何が起こったのか」
10月10日~11日にかけて何が起こったのか、障害の経緯の詳細は既報を参照していただきたいのですが、概要としては以下となります。
- 三連休明けの10月10日午前8時35分ごろ(オンライン通信開始直後)、連休期間に新機種への移行作業を行った中継コンピュータ(RC23)が10の金融機関でシステムダウン、全銀ネットとの間で振込などテレ為替業務が全面的にできなくなる
- 障害発生を受け、全銀ネットは直接影響を受けた10の金融機関に「新ファイル転送(複数の為替通知データを一括して送受信)を利用してファイルを拝受する」または「電子媒体(テープなど)でファイルを拝受する」という代替対応を依頼、しかしいずれも当該金融機関が慣れない手法であったことから時間を要し、仕向電文の発信が遅延→被仕向電文の受信および後続の入金処理も遅延という事態に
- 全銀システムとNTTデータは障害が「RC23が内国為替制度運営費(他行への振込手数料)のテーブルを参照するときに発生」することを解析(ただしこの時点では詳細な原因は不明)、10日17時ごろに暫定対処1(テーブルを参照するのではなく、固定値で内国為替制度運営費の金額を入力するプログラム修正)を決定
- プログラムの改修完了は10日23時を予定していたが、改修項目が多く時間を要する。さらに11日午前1時40分ごろにプログラム改修の検証でエラーを検知、加えて午前3時45分ごろにも別のエラーを検知、このため午前8時30分のオンライン開始時間には間に合わないと判断し、暫定対処1のリリースを断念
- 11日13時ごろ、全銀ネットとNTTデータは「内国為替制度運営費の金額を一律ゼロ円とするプログラム修正」を行う暫定処理2の実施を決定、11日のコアタイムオンライン終了前から先行してプログラム修正に着手、12日午前3時30分ごろに暫定処理2が問題なく起動していることを確認、復旧へ
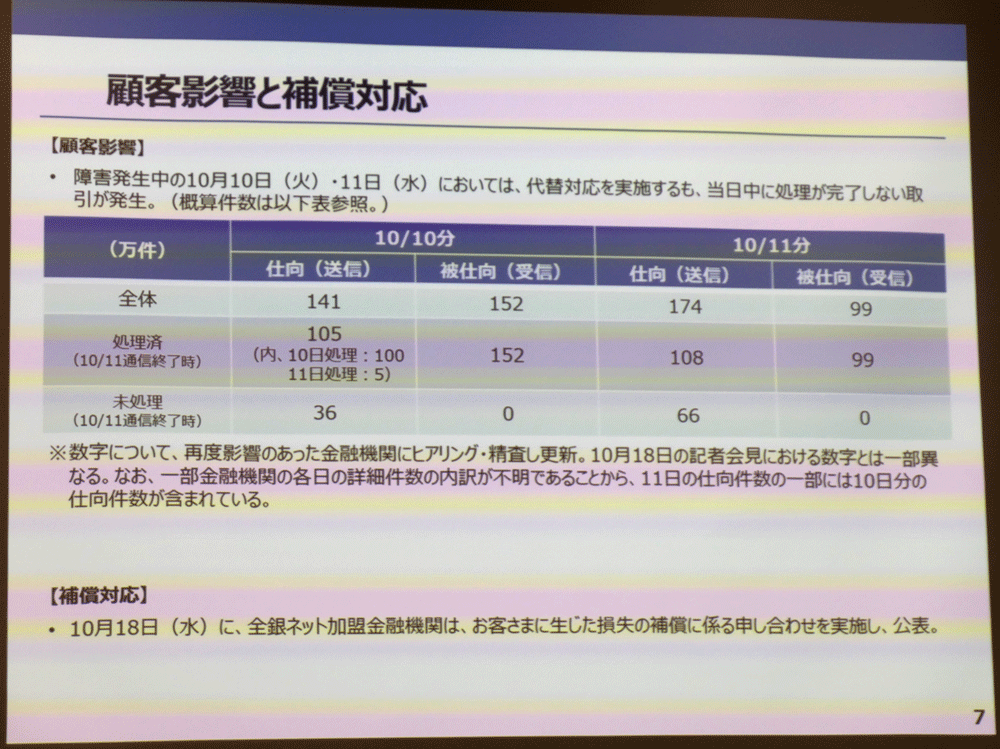
この2日間の障害発生において、当日中に処理が終わらなかった取引件数は全体で約566万件、うち全銀システムが補償対応を実施した件数は約8,000件、金額にして約800万円と公表されています。ただしこれらの数字は12月1日時点のものであり、今後、さらに調査が進めば増える可能性があります。
また、後述しますが暫定対処2による運用は12月1日時点においても継続中で、改修プログラムのリリースについては「12月以降順次予定だが、現段階で確定したスケジュールはない」(NTTデータ)という説明がありました。
10/10~11の大規模障害によって影響を受けた処理の件数と概要。送受信あわせて2日間で566万件の処理が影響を受けた。なお、ここに掲げられている数字は12/1発表時点の暫定値であり、今後さらに増える可能性がある
インデックステーブルはなぜ破損したのか?
今回のシステム障害を起こした直接的な原因は、RC23の共有メモリ上に展開されたインデックステーブルの一部が破損したことにあります。会見に登壇したNTTデータ 取締役副社長執行役員 鈴木正範氏によれば「特定のカナで始まる一部の金融機関のインデックスが壊れてしまっていた」状態にあり、これによりRC23内のアプリケーション(内国為替制度運営費付加/チェック処理を行うプログラム)が特定のカナで始まる金融期間のインデックステーブルにアクセスしても正常な値を取得することができずに異常終了してしまい、結果としてRC本体のシステムダウンに発展しました。
もう少し原因を深掘りしてみます。RCは起動する際、「ロードファイル」と呼ばれるテーブルの初期設定を保持するファイルを読み込み、これを共有メモリ上に展開します。アプリケーションはロードファイルによって展開されたテーブルを参照し、振込手数料のチェックなどを行いますが、このロードファイルを生成するプログラムのテーブル作成処理に不具合があり、ロードファイルの内容が破損、そして破損したロードファイルの破損したデータが共有メモリ上に展開され、アプリケーションは結果として壊れたデータを参照→異常終了という流れとなったようです。
障害の直接の発生原因は、RCが起動時に読み込むロードファイルの生成プログラムにおけるテーブル作成処理の不具合。あらかじめ確保されたメモリ領域に4つのテーブルを展開しようとすると、一部のテーブル(インデックステーブル)が領域内に収まらず、異なる領域(別のプログラムが使用する領域)に展開され、データが破損された。物理的なメモリ容量が足りなかったのではなく、生成プログラムが自身の作業領域として宣言するメモリサイズが、本来確保すべきサイズよりも小さかったことが破損につながっている
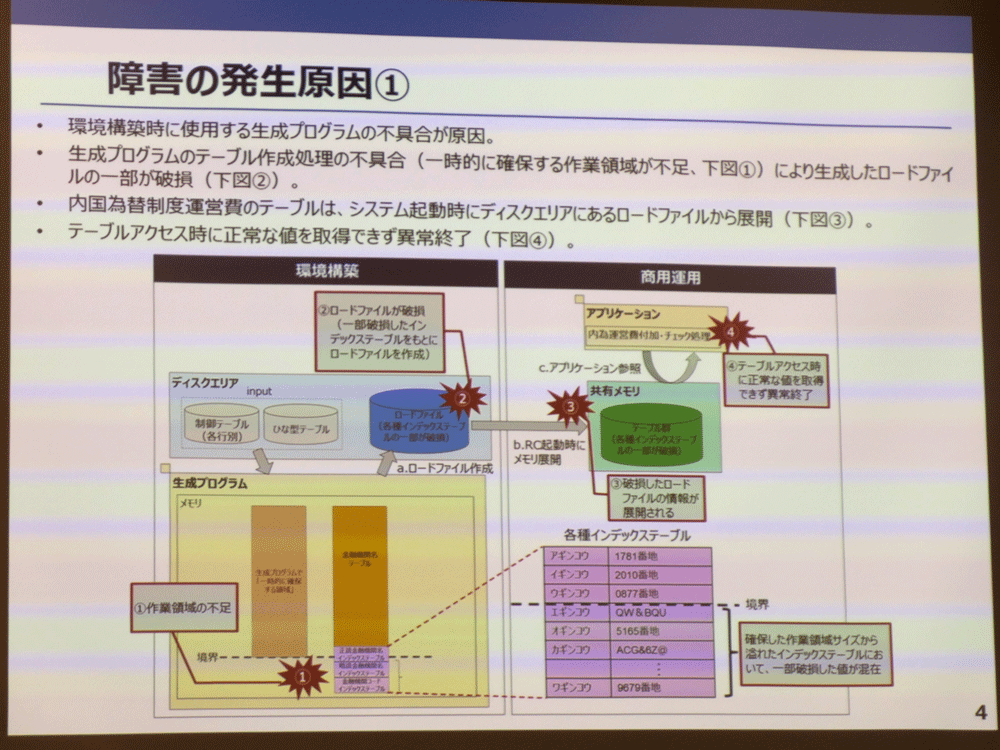
では、なぜロードファイル生成プログラムは破損してしまったのでしょうか。ロードファイルには「金融機関名テーブル」と「正読金融機関名インデックステーブル」「略読金融機関名テーブル」「金融機関コードインデックステーブル」という3つのインデックステーブル、合計で4つのテーブルが含まれます。ロードファイルを生成する際、プログラムはテーブル作成処理に必要なメモリ領域を一時的に確保するのですが、この「一時的に確保する領域」が不足していたことが破損の直接の原因となりました。
RC17→RC23の更改に伴い、NTTデータ側は非互換対応を実施、ロードファイルに含まれる「金融機関名テーブル」の64ビット化を行った結果、テーブルサイズが一時的に確保するメモリ領域に収まったため、一時的に確保する領域の拡張は行わなかった(実線のサイズから変更なし)。本来は4つのファイルをまとめて展開したときのサイズ(点線までのサイズ)を割り当てる必要があったのだが、製造工程では「ファイルは個別に展開される」と誤認しており、作業領域の不足が生じた
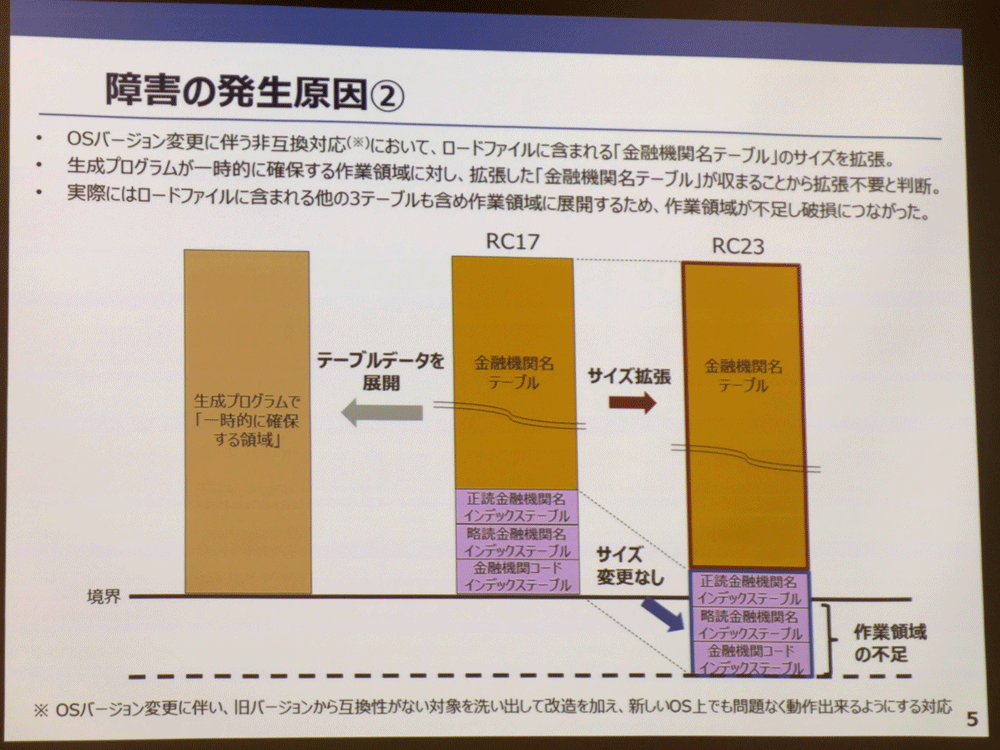
通常、32ビット→64ビットといったOSの更改時には、旧バージョンから互換性がない対象を洗い出して改造を加え、新バージョンでも問題なく動作できるようにする「非互換対応」が行われますが、NTTデータも今回、RC17(32ビット)で動作していたロードファイル生成プログラムをRC23(64ビット)で動かすための非互換対応を行っています。しかしこの非互換対応に問題がありました。具体的には4つのテーブルのうち、金融機関名テーブルのサイズを64ビット対応で拡張しましたが、拡張した金融機関名テーブルのサイズが「一時的に確保するメモリ領域」(RC17で一時的に確保していたメモリ領域と同じサイズ)に収まったため、RC23上で「一時的に確保するメモリ領域」を拡張しなくてもよいという判断に至ってしまっています(金融機関名テーブル以外の3つのインデックステーブルは64ビット化によるサイズ変更はなし)。
本来なら、「一時的に確保する領域」に4つのテーブルをまとめて展開することを前提に領域を計算する必要があり、全銀ネットの詳細設計書にもその旨が記載されていたのですが、NTTデータ側の設計/製造工程プロセス担当者は「各テーブルが個別に(一時的に確保した領域に)展開されるものと理解」し、拡張された金融機関名テーブルのサイズのみを見て、「一時的に確保する領域の拡張不要」という判断を行いました。その結果、本番稼働時のロードファイル展開において作業領域が不足し、作業領域からあふれたインデックステーブルが本来ほかのプログラムが使用する領域に展開され、別のプログラムがそれを上書きしデータは破損、アプリケーションはテーブルを参照できなくなり、最終的にはRC23の異常終了を引き起こしました。
なお、鈴木氏の説明によれば、RCのOSはLinux系で、生成プログラムの開発言語はC言語、破損したインデックステーブルのデータの割合は全体の約2%だったということです。
設計/製造、試験、復旧 ―すべての工程でミスが発生
1973年の初稼働から50年に渡る全銀システムの歴史において、一般顧客の利用に直接影響する障害が発生したのは今回が初めてとなります。この大規模障害は本当に防ぐことはできなかったのか ―以下、会見の内容をもとに「設計/製造工程」「試験工程」「復旧対応」という3つのプロセスで生じた不具合の連鎖をまとめてみます。
①設計/製造工程プロセスの課題
前述したように、障害の直接的な要因はロードファイル生成プログラムの不具合ですが、NTTデータ 代表取締役社長 佐々木裕氏は「製造関係者のみでプログラム修正方針を判断をしてしまったことに大きな問題があった。(一時的な領域確保の拡張の判断において)もし、詳細設計関係者も含めてプログラム修正方針を決めていれば、また、より基盤に詳しいメンバーがレビューしていれば、回避できたかもしれない」と製造工程における判断の誤りについて語っています。
もっとも、今回のように複数のテーブルを1つの作業領域に展開するケースはかなり特殊であり、「初歩的なミスかどうかと問われると、決して初歩的ではない」(佐々木氏)ものの、委託先の詳細設計書に記載されているにもかかわらず、最終的に判断を誤ってしまった事実に変わりはなく、佐々木氏は「製造の工程で不具合を混入させてしまったことに強く責任を感じている。少なくとも製造有識者のレビュー段階で押さえられているべきだった」と振り返っています。
また、委託元である全銀ネット 理事長 辻松雄氏も「委託元として実施すべき管理が十分にできていなかったことが、開発工程において障害の原因となったテーブル破損を発見できなかったことにつながった」という認識を示しています。特殊なケースであったとはいえ、非互換対応の影響調査に問題があり、その後の製造関係者のみによる修正方針の決定、そしてその誤りを抽出できるプロセスがなく、委託元の管理体制も不十分だった ―こうした製造工程のミスが重なったことが障害発生の重大なトリガとなりました。
②試験工程プロセスの課題
今回の大規模障害は、製造工程で混入した不具合を試験工程で発見できなかったという点でも注目されました。NTTデータの鈴木氏は11月6日に行われた会見で「数千パターンのテストを行ったが、結果としてバグをすり抜けさせてしまった」と語っていましたが、今回はより具体的に「約6,000弱のパターンでテストしており、総合振込や給与振込などテレ為替の電文でありえる組み合わせはすべて試した」と明らかにしています。
6,000ものテストを重ねたにもかかわらず、なぜ本番稼働してから約5分でエラーが発生してしまったのか、鈴木氏は「単体テストはほぼカバーできていたが、変更を加えていないテーブル(3つのインデックステーブル)が、ほかのプログラムが動いている状態でどのように動作するのか、その検証が不足していた」と振り返っています。
障害の直接的な原因となった不具合を含んだロードファイル生成プログラムは、単体テストの段階では正常に動いているように見えていました。これは生成プログラムが「一時的に確保した領域」を超えて、本来ロードファイルを展開してはいけない領域(別のプログラムが利用する領域)にインデックステーブルを書き込んでしまっても、そのテストでは別のプログラムを動かしていないので上書きされることもなく、「テーブルとしてはできあがっている」(鈴木氏)状態になるからです。鈴木氏は「もし、結合試験や総合試験でほかのプログラムが多重で動いている環境(より本番に近い環境)でテストをしていれば、今回の破損は検出できていたはず。総合試験の環境においてインデックステーブルのコンペア(R17からR23への突合)の検証を行えばよかったのだが、残念ながらできていなかった」とコメントしており、NTTデータ側の総括にあるように「予期せぬ非互換による異常を検出する観点に課題があった」のは間違いないようです。
また、鈴木氏は試験工程において「より本番に近いデータを使った検証が不足していた」ことも反省点として挙げています。全銀システムでは、最大で1,132にも上る加盟金融機関を効率よく検索するためにインデックステーブルを使っており、金融機関名テーブルと3つのインデックステーブルを一体として扱うことで「◯◯銀行の手数料データは✕✕番地にある」とインデックスを埋めています。鈴木氏は「6,000のパターンは試したが、1,132✕1,132の電文パターンを試すことまではできておらず、また理論上、その数のテストをやり切るのはむずかしい。網羅性という観点からは、1,132✕1,132のバターンをやり切るよりも、たとえば“直近の最繁忙日の1日分のデータ”といった商用データを使ってカバーしていくほうが良いと考えている」と語っており、今後は実取引相当のデータを活用した疎通試験を実施していく意向を示しています。
NTTデータによる設計/製造工程プロセスおよび試験工程プロセスの課題とそれぞれに対する再発防止策。プログラム修正方針に詳細設計関係者を含める、変更対象外のテーブルについても新旧テーブルのコンペア実施、商用で流れている実取引相当のデータを使った疎通試験の実施などが盛り込まれている

③復旧対応プロセスの課題
障害発生から丸2日間という長時間に渡ってシステムが止まってしまったこともまた、全銀システムの信頼性を大きく揺るがしました。NTTデータ側は復旧対応が遅れてしまった理由として以下を挙げています。
- 復旧に向けた優先順位の考え方について、あらかじめ全銀ネットと合意していなかった
- 見積もり精度よりスピード優先で対処し、限られた時間でのフィージビリティ(実現性)検証のまま前進した
- 並走タスクの優先順位の考え方、代替案への切り替え時限の取り決めなく作業を実施した
実際、今回の復旧対応は最初の暫定対処に1日かけて取り組みながら結局リリースを断念するなど場当たり的な印象が否めず、NTTデータも委託元の全銀ネットも大規模障害の発生を具体的に想定していなかったように見受けられます。全銀ネットの報告書には、全銀システムが初稼働から50年に渡って安定稼働してきたことに依拠し、「大規模障害は起きない」という潜在意識があったという旨の反省が記されています。辻理事長も会見で「大規模障害の経験がなかったことから、原因調査や復旧の優先度が明確になっておらず、訓練などの対応体制やシステム人材も十分ではなかった。障害は必ず発生するという認識が足りなかった」と危機管理体制が脆弱であったことを認めています。
NTTデータによる復旧対応プロセスの課題とその再発防止策。今回、復旧対応が大幅に遅れた反省を踏まえ、普及させる業務の優先順位とバックアッププランへの切り替え時限を全銀ネットと合意したうえで、復旧ガイドラインを作成し、さらに策定したガイドラインをもとに”東阪同時障害”を前提にした訓練シナリオの検討とブラインド訓練の実施を図る

なお、会見では「RC23で障害が発生した後、旧機種のRC17に切り戻すという選択肢はなかったのか」という質問が出ました。これに対し鈴木氏は「RC17→RC23の移行作業中に不具合が発生したら、RC17に戻すという手順は定めていた。しかし実際に不具合が発生したのは10月10日の本稼働後で、その時点からRC17に戻すには、全銀センター側の接続状況や相手側の金融機関の勘定システムの接続状況などをもとに戻さねばならない。つまり、全銀センターを止めて入れ替え作業を行う必要がある。そうなると今回影響を受けた10行どころでは済まず、全金融機関のシステムを止めることになる」と回答しており、障害の影響範囲を拡大させないためにもRC17への切り戻しは選択肢になかったとしています。
また、「全銀システムは東京と大阪で二重化しているのに、今回はなぜ両方ダウンしてしまったのか」という質問も出ましたが、今回はどちらのセンターのRCにも同じプログラムが適用されたため、同じ破損が発生し、両方が倒れることとなりました。鈴木氏は「東京だけ、あるいは大阪だけが倒れた場合の訓練はやっていたが、両方がダウンした場合の訓練はやったことがなかった」と明かしており、今後のBCP対応において根本的な改善が求められそうです。
全銀ネットによる障害発生原因の分析と再発防止策 その1: 「委託者としてのマネジメント不十分」「加盟金融機関も含めたBCPの実効性不足」という課題認識にもとづき、ベンダマネジメントの向上や復旧対応のマネジメント体制の整備、プロジェクト特性を踏まえたBCPの確立などを再発防止策として掲げている

残された課題 ―不安の解消とさらなる移行へ
これらの障害発生の原因分析をもとに、全銀ネットもNTTデータも再発防止策をすでに公表済みですが、いまだに暫定対処で運用されているRC23の今後の展開はどうなるのでしょうか。
まず、今回の障害で影響を受けた10の金融機関に対しては、ふたたびRC23の本格対処が開始されています。具体的には、NTTデータにおいてRCで動作している「領域確保を実行するすべての処理」に不具合が混入していないことをすでに確認済みで、現在は障害の影響を受けた金融機関から商用データを借用して、内部試験を実施中とのこと。今後は試験結果に問題がないことを確認した後、エラーが発生したプログラムの改修プログラムを、12月以降順次リリースしていく予定となっています。なおリリースにあたっては、東京と大阪で別日程での分散リリースについても検討しているそうです。
全銀ネットによる障害発生原因の分析と再発防止策 その2: 「大規模障害を想定した全銀ネットにおける危機管理体制の脆弱性」「システム人材の不足と組織の脆弱性」という課題認識にもとづき、大規模障害時の対応事項や役割分担の明確化や実質的な訓練の実施、システム人材および組織体制の強化などを、期限を決めて取り組んでいく

一方で、今回の障害は他の加盟金融機関にとってRC23への移行に対する不安を抱かせることにもなりました。辻理事長によれば、2024年1月にRC23への移行を予定していた3つの金融機関のうち1つの金融機関が移行を延期、残り2つの金融機関は暫定対処版で移行する方向で調整中となっています。RCは耐用年数が最長6年であるため、移行を延期したとしても保守期限内に更改する必要は出てくるのですが、当該銀行からは「RC23の本格対処ができるようになってから移行したい」という申し出があり、その要望に従ったとのことです。加盟金融機関の不安を払拭していくことは、全銀ネットとNTTデータの今後の大きな課題となりそうです。
なお、全銀システムは2035年までに現行のRC方式を廃止し、APIゲートウェイによる接続方式の一本化を目指しています。APIゲートウェイ開発も含めた次期全銀システム開発プロジェクトにおいては、今回の障害の再発防止策を踏まえたプロジェクト管理や各種検討が行われることになる予定です。
11月のNTTデータによる会見を受けて、筆者は「バグは“数千パターンのテスト”をすり抜けた」というタイトルのレポートを執筆しました。しかし障害の全容を見ると、実際にバグがすり抜けたのは試験工程だけではなく、開発から運用に至るまでのすべてのプロセスであり、さらに50年の安定稼働の実績によって形成された「全銀システムでは大規模障害は起こらない」という潜在意識がそのすり抜けを助長したともいえます。
今回の障害により、全銀システムの50年の安定稼働の歴史が途切れてしまったことは非常に残念であり、社会的影響の大きさを考えれば全銀ネットとNTTデータの責任がきびしく問われるのは当然でしょう。一方で、今回の復旧対応や原因分析で得られた知見や教訓は少なくないはずです。次の50年に向け、全銀システムが「社会から真に信頼される決済インフラとなるべく」(全銀ネット報告書)、両者による再発防止に向けた具体的な活動に引き続き注目していきたいと思います。



