



前回は、Bedrockを使ってテキストを作成し、その結果をDiscordに送信しました。今回は、Bedrockを活用して画像生成にチャレンジします。
画像を作るためには、Bedrockの基盤モデルの一つである
使用するコードはgihyo-torecaディレクトリ内のchapter-4ディレクトリに用意してあります。
cd gihyo-toreca/chapter-4
Stable Diffusionにおけるプロンプト作成
Bedrockとの連携や、プロンプト成形のために前回説明したgenerate_generate_関数に画像生成コードを追加していきましょう。
生成方法の流れは文章生成の時と変わりません。プロンプトを成形し、Bedrockに渡して結果を得ます。基盤モデルのStable Diffusionにおけるプロンプト作成は、Claudeの基盤モデルよりもルールは少なめです。ただし、Stable Diffusionはプロンプトを英語で作る必要があるため、英訳処理をする必要があります。詳しい情報が必要な場合は、AWS Stable Diffusionについてのサイトを参照してください。
# モンスターの画像を生成するためのプロンプトを作成
prompt_image = generate_prompt_for_image(user_request, monster_episode)
# AWS Translateを利用して英訳する 日→英
translated_prompt = translate_japanese_to_english(prompt_image, 'ja', 'en')
# イメージを生成
monster_image = invoke_image_model(translated_prompt)
return {
"monster_name": monster_name,
"monster_level": monster_level,
"monster_element": monster_element,
"monster_ability": monster_ability,
"monster_episode": monster_episode,
"monster_image": monster_image # 生成イメージの返却を追加
}
Amazon Translateを使ってプロンプトを英訳する
今回はプロンプトを英訳するために、日本語でプロンプトを作成した後、機械翻訳サービスである
具体的には、Amazon Translateのtranslate_translate_といったかたちで指定します。より詳しい情報については、Amazon Translateのサイトを参照してください。
# AWS Translateサービスにアクセスするため、Boto3を使って連携します。
translate_client = boto3.client('translate')
# AWS Translateを利用してテキストを翻訳する関数です。
def translate_japanese_to_english(text, source_language_code, target_language_code):
# Translateサービスのtranslate_textメソッドを使用して翻訳を実行します。
response = translate_client.translate_text(
Text=text,
SourceLanguageCode=source_language_code,
TargetLanguageCode=target_language_code
)
# 翻訳されたテキストを返します。
return response['TranslatedText']
# AWS Translateを利用して英訳する 日→英
translated_prompt = translate_japanese_to_english(prompt_image, 'ja', 'en')
生成画像を高画質・高品質にする
プロンプトに
今回はプロンプト成形時にコンマ区切りで、これらの単語をプロンプトの最後に追加しています。
# モンスターの画像を生成するためのプロンプトを成形する関数
def generate_prompt_for_image(user_request, monster_episode):
return (
f"{user_request}"
f"『{monster_episode}』を象徴した色鮮やかで緻密な背景"
"master pease, best quality"
)
画像生成関数のinvoke_image_model
前回、文章生成AI用にinvoke_関数を説明しました。今回は画像生成AI用の関数としてinvoke_関数を作成します。
invoke_関数では文章生成時と同様、プロンプトを渡すと基盤モデルを呼び出し、画像を生成できるようにしています。
# 画像生成モデルを呼び出し、指定されたプロンプトに基づいて画像を生成する関数です。
def invoke_image_model(prompt):
# 画像生成に必要なパラメータを指定します。
body = json.dumps({
'text_prompts': [
{'text': prompt, 'weight': 1.0}, # 生成したいものを指定します。
{'text': 'setting material, multiple images', 'weight': -1.0}, # 生成したくないものを指定します。
],
'width': 1024,
'height': 1024,
'cfg_scale': 10,
'steps': 130,
'seed': 5,
'style_preset': 'fantasy-art',
})
# Bedrock Runtimeのinvoke_modelメソッドを使用して、画像生成モデルにリクエストを送信します。
response = bedrock_runtime.invoke_model(
modelId='stability.stable-diffusion-xl-v1',
body=body,
accept='application/json',
contentType='application/json'
)
# レスポンスボディをJSONオブジェクトとして読み込み、画像データ(Base64化されている)を返します。
response_body = json.loads(response['body'].read())
return response_body['artifacts'][0]['base64']
この関数で重要なのは次のパラメータ設定です。
body = json.dumps({
'text_prompts': [
{'text': prompt, 'weight': 1.0}, # 生成したいものを指定します。
{'text': 'setting material, multiple images', 'weight': -1.0}, # 生成したくないものを指定します。
],
'width': 1024,
'height': 1024,
'cfg_scale': 10,
'steps': 130,
'seed': 5,
'style_preset': 'fantasy-art',
})
text_ではユーザーが生成したい内容を説明するプロンプトで、weight: 1.を割り当てることにより、プロンプトが強く考慮されるようになります。
反対に、生成したくない内容はweight: -1.を割り当てます。ここではsetting materialmultiple images
widthとheightは生成される画像の幅と高さをピクセル単位で指定しています。64ピクセルの倍数で指定しないとエラーとなります。
cfg_は値が大きいほどプロンプトが強く反映された画像を生成します。通常は7〜11の範囲で設定します。
stepsは大きいほどより正確な画像となりますが、生成にかかる時間も長くなります。
seedはランダム値の元となる数で、変更すると違った雰囲気の画像になります。
style_は絵のスタイルを指定することができ、今回はfantasy-artにしました。他にも、3d-model、analog-film、anime、cinematic、comic-book、digital-art、enhance、fantasy-art、isometric、line-art、low-poly、modeling-compound、neon-punk、origami、photographic、pixel-art、tile-textureなどがあります。
BedrockではStable Diffusionのサンプルが用意されているので、いろいろ設定を変えて生成を試してみましょう。
画像データの取り扱い
Stable Diffusionの画像はBase64という形式の文字列で返却されます。プログラム中では、HTMLで表示するまでそのまま文字列として値を渡していきます。
次のコードでJSONとして受け取った結果データの中から、画像データであるBase64形式の文字列を取得しています。
# レスポンスボディをJSONオブジェクトとして読み込み、画像データ(Base64)を返します。
response_body = json.loads(response['body'].read())
return response_body['artifacts'][0]['base64']
以上で、generate_
トレーディングカード画像作成のimage_processing.py
文章と画像のデータが生成できるようになったところで、これらの生成データを組み合わせて一つのコンテンツ、トレーディングカードとして完成させます。新たなファイルimage_
image_
テンプレートエンジン「Jinja」の利用
今回はHTMLとCSSの利用にあたってJinjaというテンプレートエンジンを利用します。Jinjaを利用することでHTMLにPythonの変数や文を埋め込み、動的なコンテンツを簡単に生成できるようになります。
from jinja2 import Environment, FileSystemLoader
def generate_card(monster_info):
template_dir = './templates' # テンプレートが格納されているディレクトリを指定
env = Environment(loader=FileSystemLoader(template_dir)) # Jinja2テンプレートエンジンを初期化してテンプレートをロード
template = env.get_template('monster_card_template.html') # 使用するテンプレートを指定
# テンプレートにモンスター情報を渡してHTMLコンテンツを生成
html_content = template.render(monster_info=monster_info)
まず、テンプレートが保存されているディレクトリをEnvironmentオブジェクトで指定し、FileSystemLoaderを使って設定します。
そしてimage_
次にget_メソッドを用いて、使用するテンプレートを選択します。ここでは、monster_というテンプレートを指定しています。
最後に、renderメソッドを使って、テンプレートにデータを渡しHTMLを生成します。例えば、monster_という辞書型データをテンプレートに渡して、HTMLコンテンツを作成することができます。
トレーディングカードのテンプレートHTML
トレーディングカードのテンプレートとして使うmonster_
生成した素材を埋め込むために、monster_として辞書型データを受け取ったものをテンプレート内で利用します。{{ 変数 }}のように波括弧2つで囲むことにより、HTML内で変数として取り扱うことができます。
<!-- 生成した名前の配置 -->
<p class="monster-name">{{ monster_info.monster_name }}</p>
<!-- 生成した属性の配置 -->
<p class="monster-element">{{ monster_info.monster_element }}</p>
<!-- 生成した強さの配置 強さを星で置き換え-->
<p class="monster-strength">
{% for _ in range(monster_info.monster_level | int) %}
★
{% endfor %}
</p>
<!-- 生成した能力の配置 -->
<p class="monster-ability">{{ monster_info.monster_ability }}</p>
<!-- 生成した物語の配置 -->
<p class="monster-episode">{{ monster_info.monster_episode }}</p>
また、テンプレート内ではこのように繰り返し文などの制御文が利用可能です。ここでは強さの表示を星の個数を置き換えるのに繰り返し処理を使っています。例えば強さが5の場合、★★★★★と表示されるようにしています。
生成画像はBase64の文字列のままですが、src="data:image/とすることで画像として表示できます。
<!-- 生成したモンスター画像を配置 -->
<img src="data:image/png;base64,{{ monster_info.monster_image }}" alt="Monster Image" class="monster-image">
CSSとレイアウト用装飾画像の読み込み
Jinjaではstaticというディレクトリを用意し、その中にファイルを配置することで、テンプレートから外部ファイルを読み込むことができます。
今回は外部ファイルとして画面レイアウト用のstyle.
# static内ファイル構成
static
├── style.css
└── card-frame.png
日本語表示の対応
テンプレート内で日本語のコンテンツを表示させるためにフォントが必要なので、Web上から取得しています。
<!-- 日本語を利用するために必要 -->
<link href="https://fonts.googleapis.com/css2?family=Noto+Sans+JP" rel="stylesheet">
HTMLの画像化
HTMLを画像化させるために、一旦HTMLをPDF化した後、PDFを画像化します。
HTMLのPDF化にはWeasyPrintというライブラリを使っています。
from weasyprint import HTML # HTMLをPDF保存できるライブラリ
# HTMLからPDFを生成
pdf_bytes = HTML(string=html_content, base_url=".").write_pdf()
base_は、現在のカレントディレクトリを起点として、外部CSSなどを相対パスで参照できるようにしてます。
PDFの画像化にはpdf2imageというライブラリを使っています。
from pdf2image import convert_from_bytes # PDFを画像形式で保存できるライブラリ
# PDFを画像に変換
images = convert_from_bytes(pdf_bytes)
なお、pdf2imageを使用するには、ディストリビューション
そのため今回の開発環境のDockerfileには必要なインストール設定を追加しています。
# 第4回用のpoppler-utilsのインストール
RUN apt-get update && \
apt-get install -y poppler-utils
画像の保存
今回は簡単に、プログラムが実行している環境内に画像を保存をしてみます。その際、同じファイル名だと上書きが発生してしまうため、作成時のタイムスタンプをファイル名に追加します。
from datetime import datetime # 日付用のラブラり
# 現在の日時を取得してフォーマット (例: 2023-01-01_12-00-00)
current_time = datetime.now().strftime('%Y-%m-%d_%H-%M-%S')
# ファイル名にモンスターの名前と現在の日時を組み込む
file_name = f"{monster_info['monster_name'].replace(' ', '_')}_{current_time}.png"
現在の日時を得るために、datetimeライブラリをインポートしています。また、ファイル名にスペースが入るとエラーが起こるのであらかじめアンダーバーに変換をしています。
次に、画像のファイル名と拡張子を指定して保存をします。
# 画像を保存
images[0].save(file_name, format='PNG')
# 保存されたファイルの完全なパスを取得
full_path = os.path.abspath(file_name)
# ログに情報を出力
logging.info(f'画像が保存されました: {file_name}')
return full_path
images[0]としているのは、PDF生成の結果の1ページ目だけを指定するためです。
app.pyの変更点
app.generate_関数をapp.import文に追加し、app.
# image_processing.pyに作った『generate_card』関数を呼び出す
from image_processing import generate_card
# 生成したモンスター情報を使用してカードをレイアウトし、画像に変換
image_path = generate_card(monster_info)
ローカル環境での動作確認
本番公開前にローカル環境で動作確認をしてみましょう。成功するとローカル環境内に画像が作成されます。
今回は新たに3つのライブラリを利用しました。その関係でrequirements.
discord.py # 第2回で追加
boto3 # 第3回で追加
Jinja2 # 第4回で追加
weasyprint # 第4回で追加
pdf2image # 第4回で追加
requirements.
docker-compose build --no-cache
再構築後、Docker起動前に忘れずにボットのトークンを環境変数に登録します。
export DISCORD_BOT_TOKEN='あなたのボットのトークン'
準備が整ったところでDockerを起動します。ターミナルに
docker-compose up
今回は!make 深い洞窟に住んでいて、目が溶けているモンスターとDiscordからリクエストしてみます。メッセージを受け取った後しばらく処理が続き、
ちなみに、!makeコマンドの処理が長すぎるため、Discordとの接続エラーが出ていますが、その後再接続しているので問題ありません。
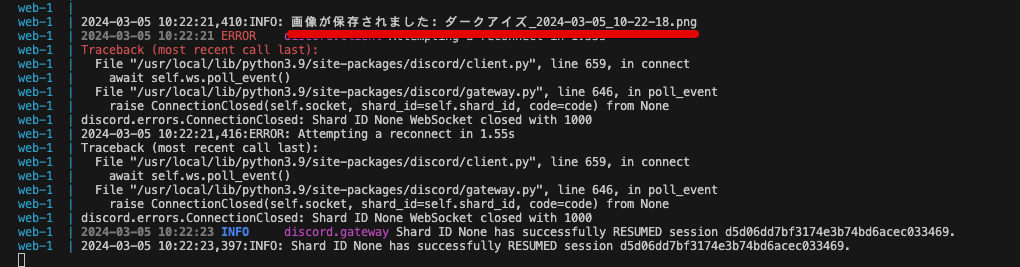
実際に、プログラムを実行しているディレクトリに直接画像が保存されています。
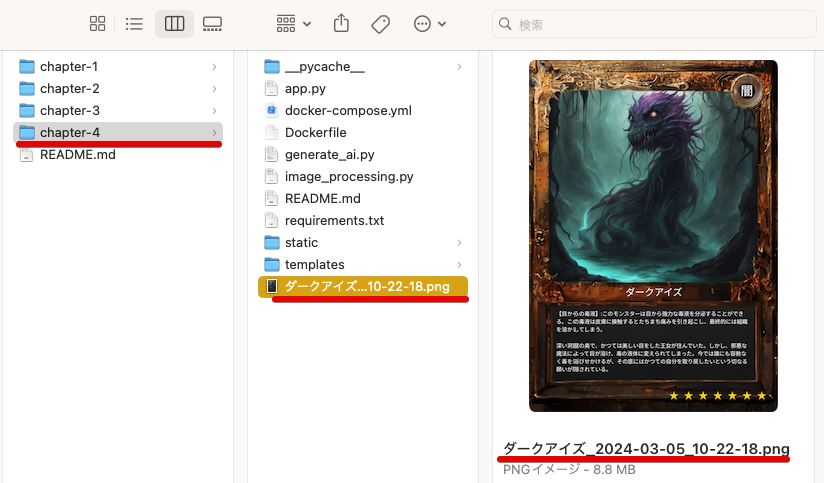
完成したカードを確認し、生成したデータがカード内に配置されているのを確認してみましょう。

CDK環境からアプリを公開
今回もアプリを本番公開します。Amazon TranslateをEC2から呼び出しているため、EC2のロールにポリシーを追加する必要があります。
具体的にはCDKに以下を追加しています。
# 第4回で必要 翻訳権限のインラインポリシーを作成しロールにアタッチ
ec2_role.add_to_policy(iam.PolicyStatement(
actions=["translate:TranslateText"],
resources=["*"],
effect=iam.Effect.ALLOW
))
AWS本番環境の構築
それでは一連の流れで本番公開をしていきましょう。一連の流れはこれまでと同様なので、簡単に説明します。
本番公開
Dockerfileが置いてあるディレクトリに移動してから次のコマンドを実行していきます。自分のPCの環境にあわせて操作してください。
# Dockerfileが置いていある場所へ移動 macでm1およびm2をお使いの方用 cd cdk-gihyo-toreca/mac-m1-m2 # Dockerfileが置いていある場所へ移動 上記以外の方用 cd cdk-gihyo-toreca/cdk # Dockerを起動して、コンテナ内に入ります docker-compose run --rm cdk # AWSへデプロイします 前回cdk destroyでAWS環境を削除していない方は、すでにAWS上に環境が構築されているので、すぐに処理が終わります。削除されている方は5分ほどSで作成されます。 cdk deploy # AWS環境が作成後、EC2に接続します。 aws ssm start-session --target 作成したEC2のインスタンスID sudo su - ec2-user # GitHubよりアプリをクローンする git clone https://github.com/あなたのgithubアカウント名/gihyo-toreca.git # chapter-4に移動 cd gihyo-toreca/chapter-4 # DockerfileからDockerイメージを作成 docker build --no-cache -t gihyo-toreca . # Dockerイメージを起動 コマンド内のボットトークンの指定も忘れずに docker run --rm -it --name app-container -v "$(pwd)":/app -e DISCORD_BOT_TOKEN='あなたのボットのトークン' gihyo-toreca
Discordから!makeでリクエストし、本番環境のEC2内に画像ファイルが保存されたら成功です。
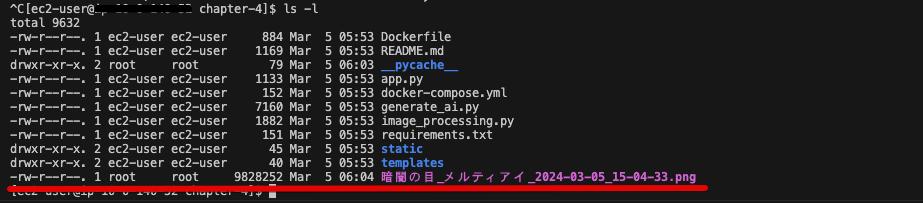
EC2のDockerを終了して、lsコマンドでディレクトリ内を確認してみます。
# EC2のDockerを「Ctrl + C」で終了したのち、 # 現在のディレクトリの内容を表示 ls -l
画像が保存されていれば本番環境での動作は成功です!
公開停止・削除の方法
公開停止および削除の流れも、これまでと同様です。
# EC2とローカルとの接続解除 exit # AWS本番環境の削除 cdk destroy # ローカル環境のDockerの終了 exit
次回、S3への画像保存と、Lambdaを使ったDiscordへの画像送信
生成AIを使ってカードを作成するところまでできました。
ローカル環境であればディレクトリを見れば画像を確認できますが、本番環境ではEC2内の画像を気軽に確認する方法がありません。そこで次回はDiscordへの画像の送信と、S3