



本連載では分散型マイクロブログ用ソフトウェアMisskeyの開発に関する紹介と、関連するWeb技術について解説を行っています。
今回はMisskeyのチャート生成機能のバックエンド実装
チャートとは
Misskeyのチャート機能は、サーバー上で発生した様々な種類のイベントの推移をグラフやヒートマップ等でグラフィカルに表示できる機能です。
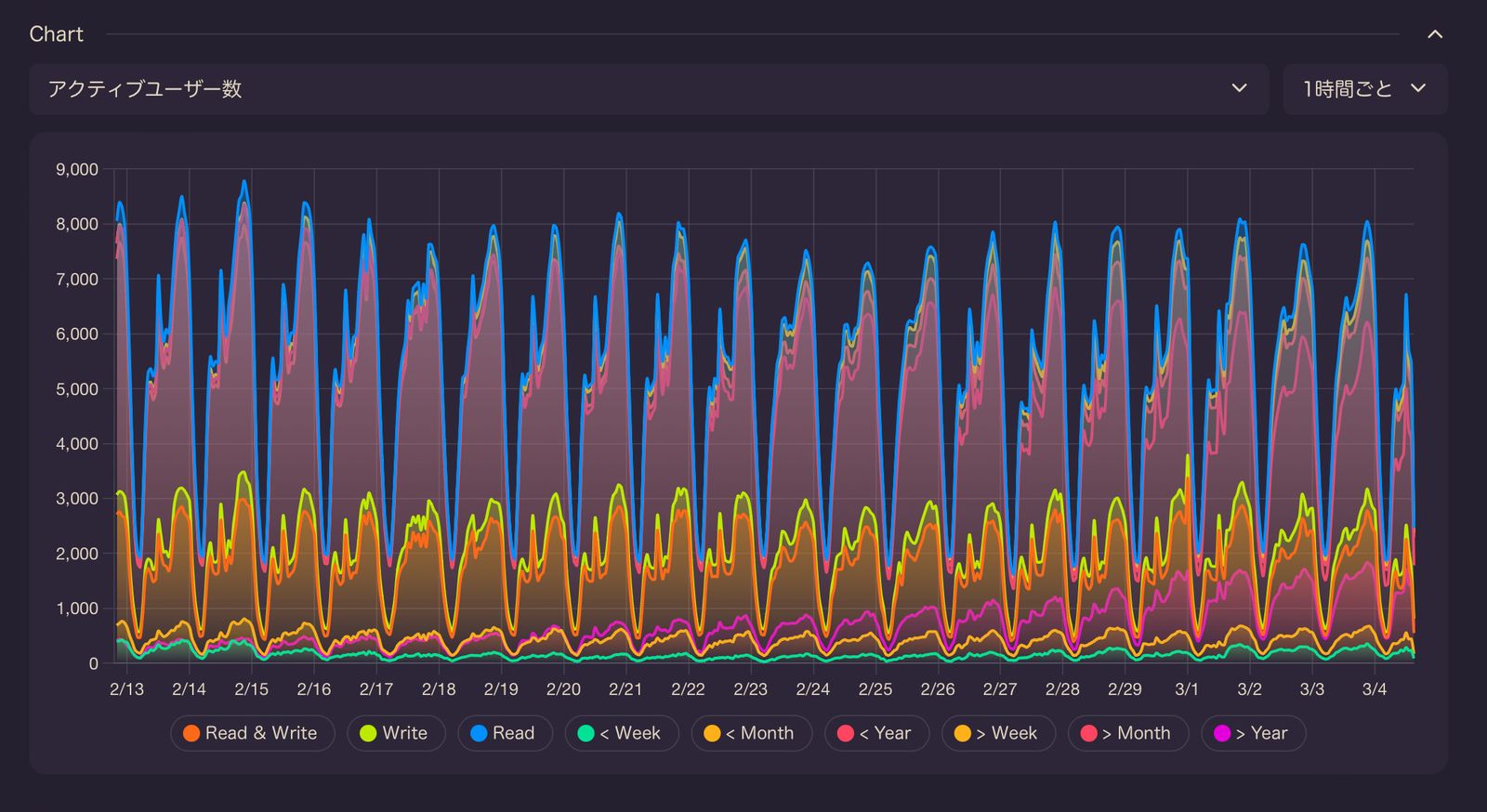
チャート表示できる情報には、例えば次のものがあります。
- アクティブユーザー数の推移
- 投稿数の推移
- 連合しているサーバー数の推移
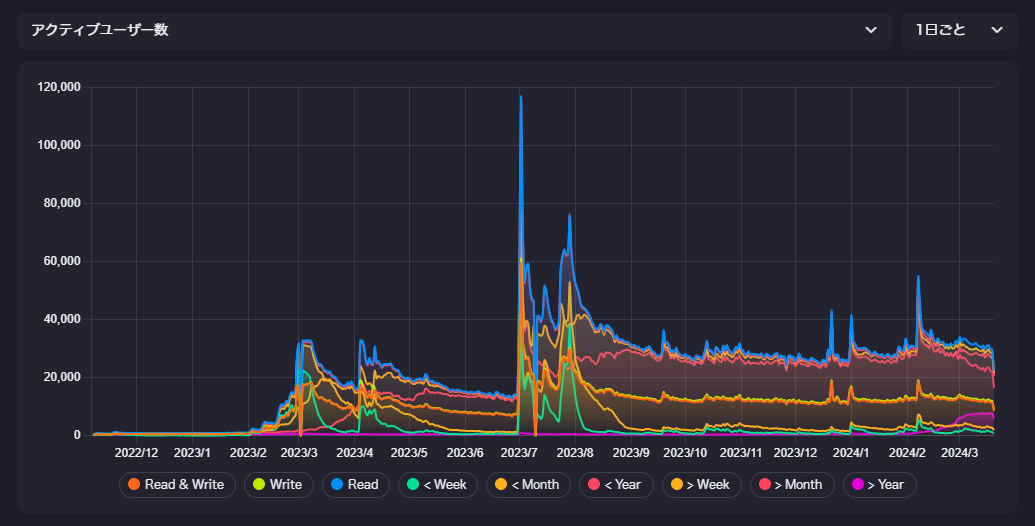
このようなサーバー全体の情報だけではなく、他にも
- あるユーザーのフォロワー数の推移
- あるユーザーのプロフィールページのPV数の推移
- あるサーバーのリクエスト数の推移
さらに、取得するチャートの分解能を
なお、チャートの描画にはChart.
設計
まずチャートを生成するためのデータを集計する方法はどういうものがあるかを考えてみます。
データベースから集計する方法
チャートを得るには、データベースにある実際のデータを集計するのが処理的には最も簡単で愚直な方法です。一般的に各レコードには挿入日時カラムがありますので、それを元に範囲を指定して集計すればチャートが得られます。
実際、Misskeyでも一部そのような処理を行っている個所もあります。
しかしこの方法では、得られる情報がチャート生成を行う時点のものに限られます。例えばデータベースから物理的に削除されたデータを推移として結果に反映させることができませんし、レコード量が多いとパフォーマンスが低下するため実用的ではありません。
また、そもそもデータベースのレコードとして記録しないようなデータ
ログを記録する方法
次に考えられるのは、イベント発生時にその変動
この方法であれば、
しかしイベント発生ごとにログを行っていくと、1億回投稿が行われたら1億個のログが挿入されることになるため、やはりレコード量が膨大になり、パフォーマンス上の問題が生じてしまいます
ログを記録する方法[発展]
そこでMisskeyでは、イベントごとにログを挿入していくのではなく、
ある程度期間を決めて、その期間ごとの変動を記録していくことで、チャートの分解能を犠牲にする代わりにデータ量が抑えられます。
Note: 期間ごとにログを挿入するといっても、
このような設計にしたのは、ズレや集計処理の抜けが生じる可能性をなくすためと、やはりそのようにすると集計時にデータの量によってはパフォーマンスが悪化するためです。それに並列環境との相性も悪いです。
さらに、パフォーマンス向上のため
この方法であれば、例え1時間のうちに1000回投稿されてもレコードは1つしか挿入されないので、データ量は格段に少なくなりますし、既に集計された値がそのまま入っているため長い期間のチャートを取得する場合も一瞬で処理できます。
Misskeyではこの方法を使いながら推移を記録していきます。
チャートエンジンの実装
こういった仕組みでチャートの記録と集計を行うMisskeyのバックエンド実装がチャートエンジンです。
実際の実装が記述されいてるpackages/
また、チャートの種類ごとにChartクラスを継承したクラスが用意される実装になっており、各チャートクラスは以下にあります。
テーブルの生成
チャートのログはデータベースに保存されるので、最初にテーブルを定義する必要があります。しかし、チャートの種類が多く、さらに各チャートテーブルの中でも必要になるカラム数が多く複雑になります。
そこでチャートエンジンはチャート定義を元にして自動でテーブル定義を生成できるようになっています。
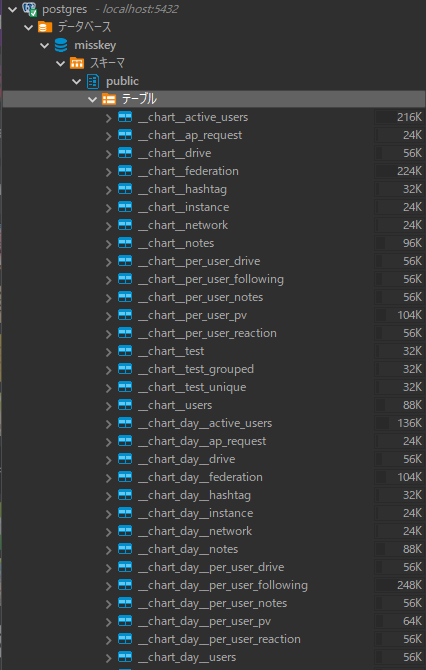
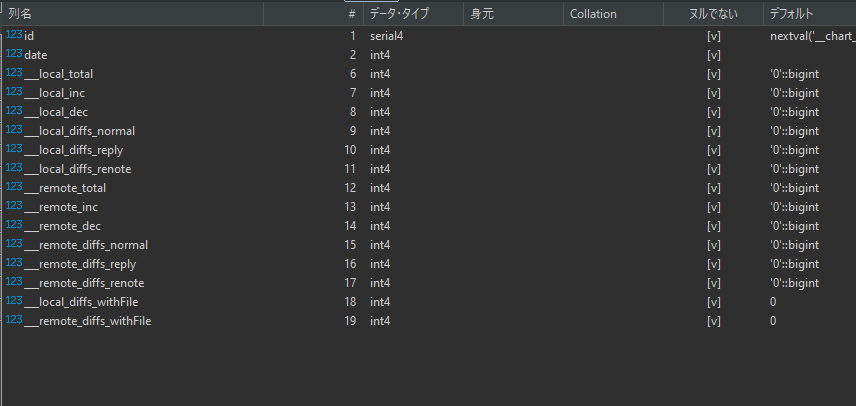
これらのテーブルは以下のような定義から自動生成されています。
import Chart from '../../core.js';
export const name = 'notes';
export const schema = {
'local.total': { accumulate: true },
'local.inc': {},
'local.dec': {},
'local.diffs.normal': {},
'local.diffs.reply': {},
'local.diffs.renote': {},
'local.diffs.withFile': {},
'remote.total': { accumulate: true },
'remote.inc': {},
'remote.dec': {},
'remote.diffs.normal': {},
'remote.diffs.reply': {},
'remote.diffs.renote': {},
'remote.diffs.withFile': {},
} as const;
export const entity = Chart.schemaToEntity(name, schema);
チャート定義からテーブル定義を生成するコードはcore.
インデックスやユニーク制約も自動で定義され、最終的に以下のようなマイグレーションコードが生成されます。
ログの更新と挿入
情報の変動が発生した時はログレコードを更新または挿入しなければなりません。
claimCurrentLogメソッドで、更新すべきログをデータベースから取得します。ログがなければ新たに挿入します。
まず現在の期間に合致するログがすでに存在するか確認し、あればそのログを返して終了します。なければ新たにログを生成する必要があるので処理を続けます。
新たにログを挿入するためには、そのMisskeyサーバー初めてのログ挿入時を除き、
そのために、まずもっとも最近のログがあれば取得します。
その過去のログがあった場合は、派生クラスで実装されているgetNewLogメソッドにそのログを渡して現時点でのログにデータを引き継げるようにします。例えば
過去のログがなかった場合
そのようにしてclaimCurrentLogメソッドから更新すべきログを取得できたら、ログの情報を更新して処理は終了です。
同期
先述した
というのも、リレーショナルデータベースではデータの依存関係を定義し、
つまり、こういったデータベースによる自動的な削除は、Misskey側で動いているチャートエンジンには感知できません。
他にも、外部ツールを利用してMisskeyのデータベースを操作した場合なども、Misskey側から行ったことではないので同じくチャートエンジンから感知できません。
したがって、Misskeyによる
同期処理の実装
同期処理はチャートの種類ごとに実装されていて、この処理を以前の記事でも解説したジョブキューを用いて定期実行されるようにしています。
例えばユーザー数のチャートでは以下のような実装になっています。
protected async tickMajor(): Promise<Partial<KVs<typeof schema>>> {
const [localCount, remoteCount] = await Promise.all([
this.usersRepository.countBy({ host: IsNull() }),
this.usersRepository.countBy({ host: Not(IsNull()) }),
]);
return {
'local.total': localCount,
'remote.total': remoteCount,
};
}
このメソッドが定期的に実行されることで、ズレが発生しても修正されるようになっています。
なお、このメソッドは親クラスであるChartクラスで以下のようにabstractメソッドとして定義されているため、子クラスはこの同期処理を実装することが義務付けられています。
/**
* 1日に一回程度実行されれば良いような計算処理を入れる(主にCASCADE削除などアプリケーション側で感知できない変動によるズレの修正用)
*/
protected abstract tickMajor(group: string | null): Promise<Partial<KVs<T>>>;
/**
* 少なくとも最小スパン内に1回は実行されて欲しい計算処理を入れる
*/
protected abstract tickMinor(group: string | null): Promise<Partial<KVs<T>>>;
ユニークカウント
例えばあるユーザーのプロフィールに対するPV
そういったユースケースに対応するために、Misskeyのチャートエンジンには
実装としてはcore.
ロック
当然ではありますが、MisskeyはバックエンドのMisskeyプロセスを複数並列に動作させることが可能です。
そのためチャートエンジンも同時に複数のインスタンスが動くことになり、場合によってはそれぞれの処理が競合し意図しない値がデータベースに書き込まれることが発生しえます。
それを防ぐためにcore.
その他
集計グループ
「ユーザーごとの投稿数」
インターセクションカラム
集合Aと集合Bに含まれている値をカウントする機能もあります。例えばアクティブユーザーのチャートでは
インターセクションカラムの集計処理はcore.
accumulateカラム
前のログの値を引き継ぐカラムを設定できます。累計ユーザー数など、値が蓄積されていくデータに設定します。
引き継ぎ処理は新規ログ取得時である、core.
バッファリング
イベントが発生するたびにデータベースへ書き込みを行うと負荷が高いため、ある程度メモリ上にログを貯めてからまとめて書き込みを行うようにしています。
チャートの取得
チャートの取得は、データベースからログを持ってきてまとめれば良いだけなので難しいことはありませんが、ログの補間処理は必要になります。
ログの補間
「あくまでもデータが変動したときにログを挿入/更新する」
データ出力の際にただ単にデータベースにあるログを集めてくるだけではこういった抜けが発生するため、この間の記録を補間
Note: 「ログがなければ投稿がされていないことは明らかなのだから、その時間は投稿が0だったことにするだけで良いのではないか」
たしかに
ペイロードの圧縮[予定]
取得するチャートの期間が短ければそこまで気にする必要はありませんが、数年分といったチャートを取得する場合はそれなりのデータ量になるので効率的なレスポンスが求められます。そこでAPIのレスポンスペイロードを工夫し、圧縮して送信することを検討しています。
具体的には、現状それぞれの値が100000, 100002, 100005, 99998であるチャートを取得したとき、レスポンスはそのまま[100000, 100002, 100005, 99998]のような配列にシリアライズされています。
これでは無駄があるので、[100000, 2, 3, -7]のように前の値のデルタ値
データの転送効率だけを追求するのであれば、JSONを使わずにバイナリでやり取りする選択肢もあるのですが、実装は複雑になります。
テスト
チャートエンジンのテストはpackages/
チャートエンジンは内部的に時刻情報に依存した処理を行うため、テスト内で時間を任意に操作できるように@sinonjs/
例えば以下のように書くと、1時間の間隔を空けて2回incrementメソッドが呼ばれた扱いになります。
await testChart.increment();
clock.tick('01:00:00');
await testChart.increment();
まとめ
今回はMisskeyにおけるチャート機能のバックエンド実装について紹介と解説を行いました。
チャートのバックエンド実装はいかに効率よくデータを記録できるかと、いかに高速にデータを取得できるかが課題になります。今後もチャート機能のパフォーマンス向上を考えていますので、また紹介できればと思います。