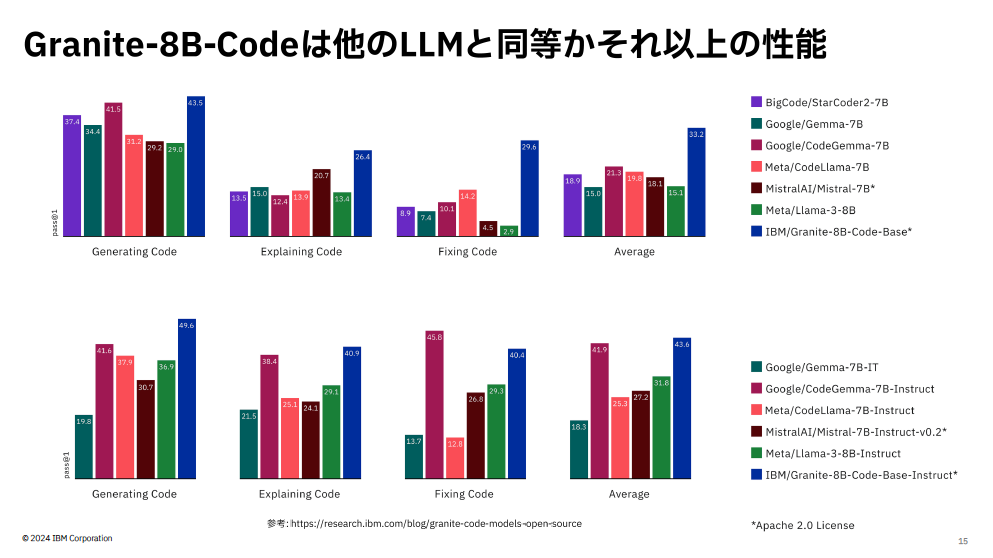
IBMが2023年から提供する大規模言語モデル「IBM Granite」ファミリの一覧。言語、コード、時系列、地理空間情報などの分野に特化したモデルを提供するパラメータサイズが70億~80億のコード生成に特化したLLMの性能比較。Granite‐8B-Code(各グラフの右から1番目)は他のLLMと同等またはそれ以上のパフォーマンスを示している(出典: IBM Reserach)
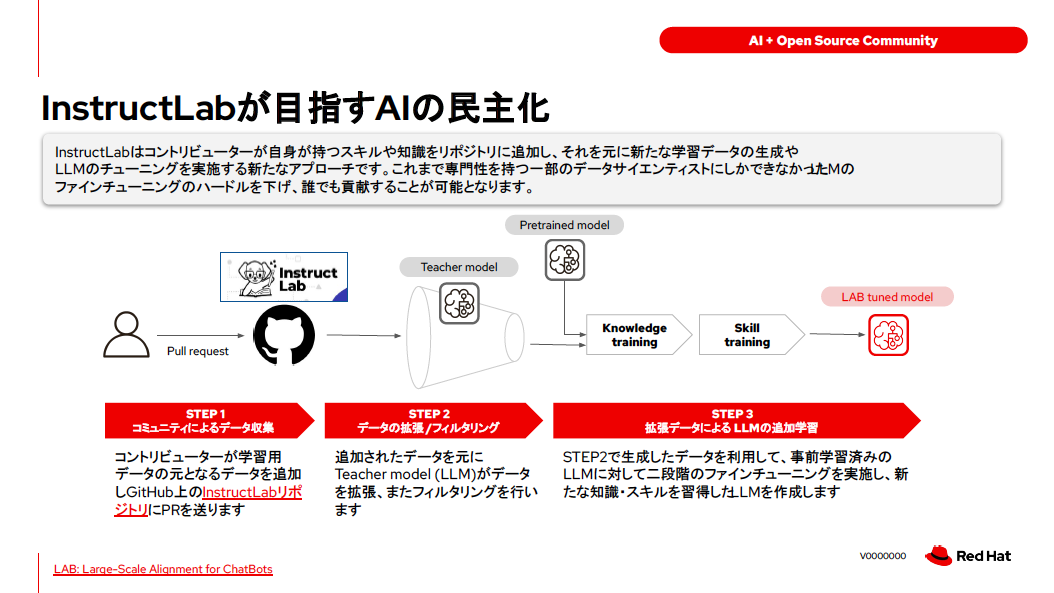
InstructLabは任意のLLMに対して補足的にスキルや知識を追加し、ファインチューニングによって精度を高めていくシステムです。ベースとなっているのはIBM Researchの研究成果である「Large-scale Alignment for chatBots(LAB:チャットボットのための大規模アラインメント)」というメソッドで、InstructLabはさらにプルリクエストを起点とした知識/スキルの追加や、新しい学習データ(合成データ)の生成、モデルのフォークなどを可能にしています。
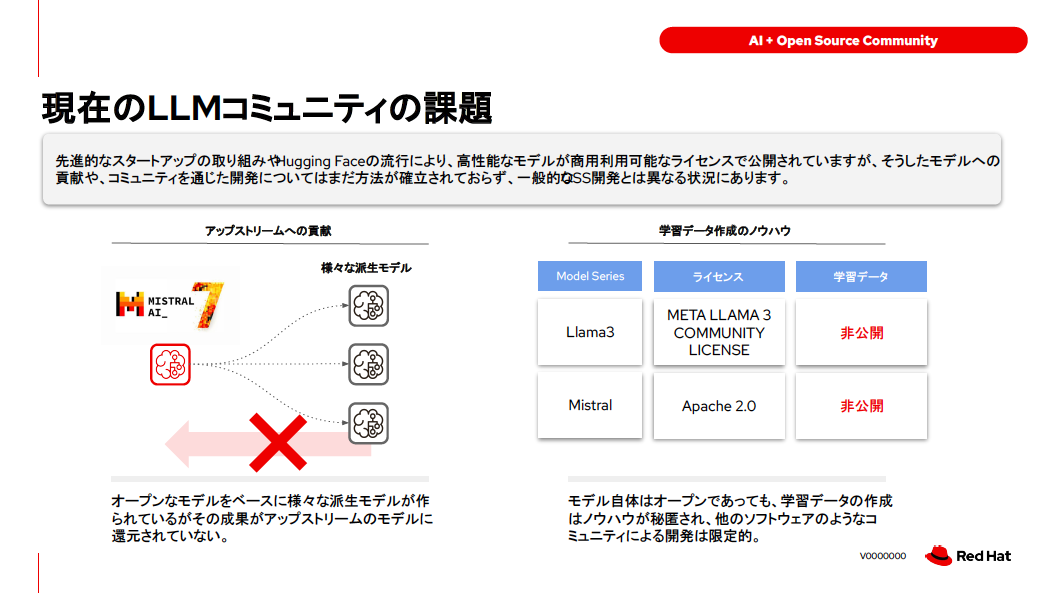
IBM Researchによって開発されたLABメソッドをもとに、AIモデル開発の新たなしくみとしてオープンソースプロジェクトとして提供されるInstructLab。GraniteもInstructLabを採用しているが、InstructLab自体は特定のモデルに特化したものではなく、LlamaやMistralなどの他のAIモデルや企業のプライベートLLMをトレーニングすることが可能
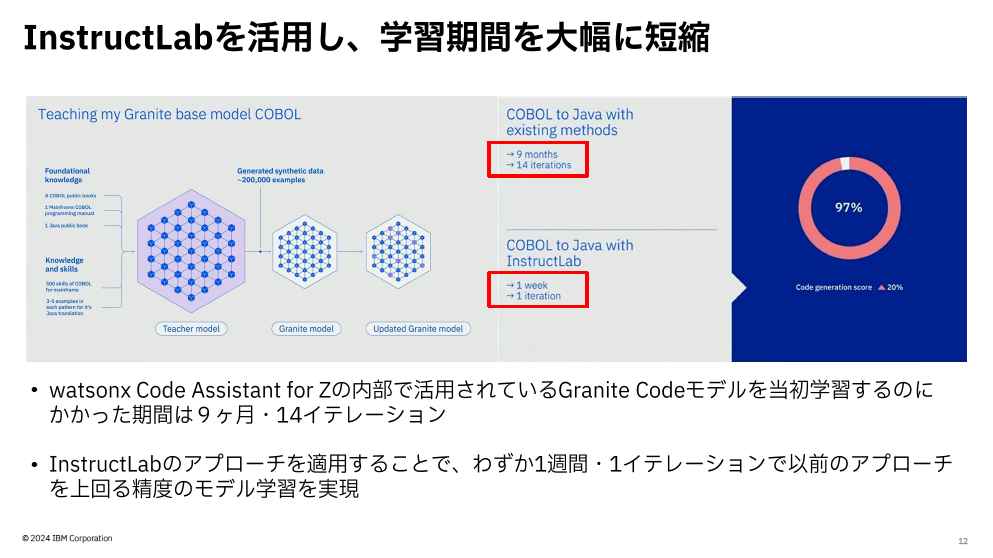
なお、InstructLabの活用事例としては、IBMがメインフレームアプリケーションのモダナイゼーション製品「IBM watsonx Code Assistant for Z」でCOBOLからJavaへのコード変換を学習させたケースが公開されています。watsonx Code Assistant for Zの内部で使われているGraniteコードモデルを既存のメソッドで学習した場合、およそ9ヵ月/14イテレーションを要していましたが、InstructLabを適用したことで学習期間がわずか1週間/1イテレーションに短縮され、さらに既存メソッドを大幅に上回る精度での学習が実現しました。
IBMでInstructLabを活用し、Granite Codeモデルを強化した事例。メインフレームモダナイゼーションの一環として、watsonx Code Assistant for Z内部のCOBOL→Java変換学習にかかる期間と精度を大幅に向上した(9ヵ月/14イテレーション→1週間/1イテレーション)
「RHEL AI」の登場
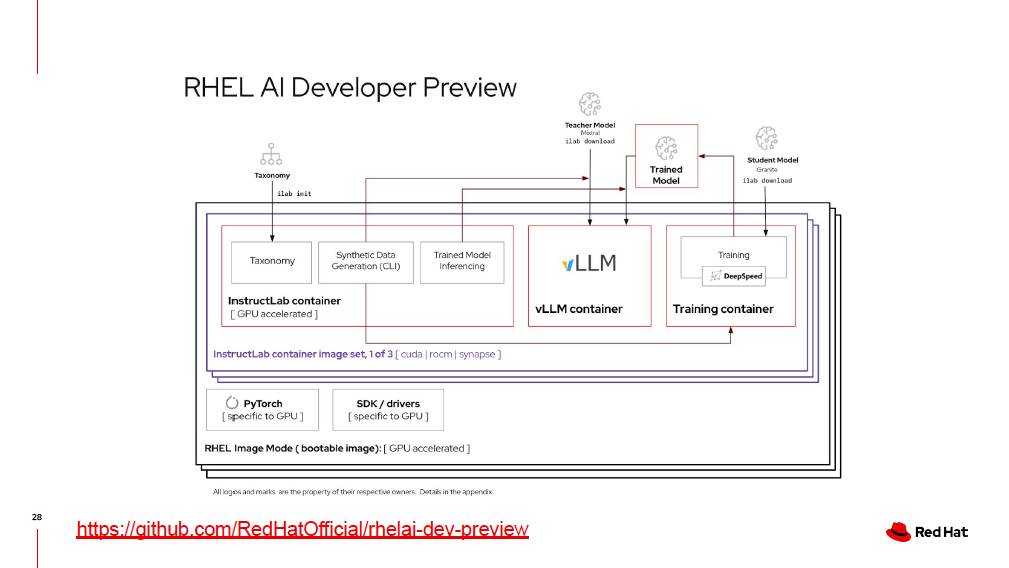
Red Hatはこれらの2つの発表に加え、エンタープライズ企業のAIモデル開発を支援するためのプロダクトとして、シングルサーバ上で商用グレードのLLMトレーニングを可能にする「Red Hat Enterprise Linux AI (RHEL AI)」を開発者プレビューとしてリリースしました。RHEL AIにはGraniteファミリの各種トレーニングデータセットやInstructLabで使用するモデルアラインメントツール、ユーザのハードウェア環境に最適化されたOSイメージとパッケージ化されたGrraniteモデルおよびInstructLabツール、およびRed Hatによるサポートが含まれています。Grranite/InstructLabを使ったモデル開発を具現化するベースプラットフォームとして位置づけられます。
InstructLabとともにRed Hatから発表された「Red Hat Enterprise Linux AI」の構成(現時点ではデベロッパプレビュー)。GPUリソースを含むRHELイメージ上に開発ツールとともにInstructLabコンテナ、教師モデルを含むvLLMコンテナ、学習用のトレーニングコンテナが配置されている
AI業界のあいまいな”オープンソース”という言葉の使い方を、オープンソース企業としてRed Hatはどう見ているのか ―この質問に対し、Red Hat米国本社のInstructLab / RHEL AI / OpenShift AIの関係者から回答を得たので、以下、引用します。
Red Hatからの回答
AI業界では「オープンソース」の定義をあいまいに使っているという点に関しては、ご指摘のとおりだと思います。AI全般に関して言えば、業界はまだ「オープンソース」が何を意味するのかを定義しようとしているというのが今の現実だとみています。この点に関しては、Red Hat CTOのクリス・ライト(Chris Wright)の最近のブログ記事で、これらのコンセプトのいくつかに触れているので、参考になるかもしれません。
OpenShift AIは、RHEL AIの開発環境で個別にチューニングされたLLMをスケールさせ、エッジでも、クラウドでも、あらゆる環境に展開できるMLOps プラットフォームとして位置付けます。OpenShift AIは、Red Hatが数年前に立ち上げたOpen Data Hubコミュニティをもとに、MLOpsを支援するプラットフォームとして、多くのオープンソースプロジェクトによって構成されているオープンなアプローチから生まれています。
Red HatのCEOであるマット・ヒックス(Matt Hicks)氏はRHS 2024での報道関係者向けセッションで「私はオープンソースのビリーバー(believer)として、AIモデルのオープンソース化が可能だと信じている。AIの現在はオープンソースが誕生した1990年代後半とよく似ており、若干の混乱はあるが、大きなポテンシャルがあることも同じ」とコメントしていました。
Red Hatが言う通り、AIのオープンソース化は簡単な道ではありませんが、30年以上にわたってオープンソースを推進してきた企業として、オープンソースによるAIの民主化を推進するリーダーとしての役割が期待されます。