



皆さんこんにちは。スリーシェイク代表の吉田です。
今回より生成AIを、金融業界や製造業、医療業界など各事業ドメイン固有の課題解決にどう使われているのか、具体的なユースケースを提示しながら、それを実現するアーキテクチャについて解説していきます。この連載を通して、これまで生成AIを実際のシステムに組み込むイメージが湧かない方への第一歩として手助けになれば幸いです。
第1回は、生成AI自体の一般的な得意不得意を踏まえながらユースケースを解説します。
生成AIが得意とする処理とは?
生成AIが得意とするのは、
モデルに関わらず生成AIのAPIのレスポンスは1秒以上、複雑なタスクだと30秒を超えるケースも多く、アプリケーションとしてレスポンスを意識しなくてはいけないものには不向きです。
生成AIをシステムに組み込むユースケース
生成AIを選択する考え方としては4パターンあると考えます。
創造性が求められるシーン(とくに人とコミュニケーションを取る箇所)
ゲームのBot
ゲーム世界のキャラクターと自然な会話をするBotやNPC
この場合、以下2点を注意して実装する必要があります。
- コスト面:ユーザの会話量に比例して生成AIのAPI利用料が嵩んでいきます。ユーザの入力に対して、直接生成APIをコールするのではなく、中間に会話量の制約を設けるロジックをいれるか、ルールベースの回答を主とし、特定のシーンだけに生成APIをコールするロジックとするのが良いでしょう。
- クオリティ面:ゲームの状況から見て、不適切な発言をさせないコントロールが必要です。こちらもユーザーの入力に対して、直接生成APIをコールするのではなく、中間にフィルタを掛けて反応しないようにしたり、生成APIからレスポンスされたデータに対してフィルタを掛けて、条件が達していない内容は再帰的に問い合わせることでユーザーに表示する会話品質を担保すると良いでしょう。
高度な専門性を求められない物体/音声認識、検出
OCRの代替
生成AIを使ってOCRの代替となるソリューションが非常に増えています。
たとえば、Google CloudのDocument AIは、PDFや画像データから請求書や帳票データ、手書き文字をかなり高精度で構造化データに変換することが可能です。また出力フォーマットもプロンプトエンジニアリングで簡易に変更できる点も魅力です。
大量のデータを安く、レスポンシブにOCRシステムとして組み込む場合には、既存のOCRソリューションや独自にmodelを構築した方が良いです。一方で、OCR機能を簡易実装できる点を考えると、強力な利用用途だと考えられます。
音声文字起こし、感情解析
生成AIを使った議事録作成、トーク分析はとても相性が良い例です。
弊社で以前、gemini-1.
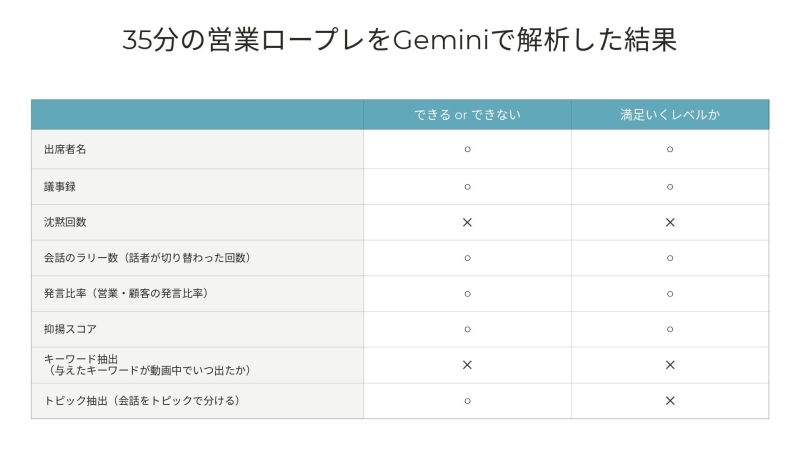
高度な専門性を求められない文章の作成や評価
各種レポートの作成(例:契約書や報告書など)、レビュー、要約、翻訳
生成AIを使って契約書のリーガルチェックや有価証券報告書の要約など、従来専門家が必要となるレポート周りの業務は大幅に簡素化することが可能で、生成AIが得意とする領域の1つです。
RAGやプロンプティングに定型フォーマットや前提知識を組み込みながら、動的な条件、たとえば議事録データや売上データ、システム変更データなどから、各種報告書を自動で生成するシステムはコスト面でも性能面でも十分耐えうる構成が可能です。
とくに、システムに組み込む際に、生成AIに入力するプロンプトを定量的な指標に基づいて改善を行える仕組みを取り入れると良いでしょう。
既存のMLやDeep Learningが得意とする処理とは?
既存のデータからパターンを学習し、それを元に判断や分類をするケースは、既存手法を選択するほうが相性が良いです。生成AIはあくまでも
具体的には、
- 数値予測
- 異常検出
- 過去のデータを鑑みたレコメンド
- 専門性を求められる画像や音声の分類、検出
などが挙げられます。
また一般的なMLやDeep Learningを組み込んだシステムにおける処理パフォーマンスは1s/
既存のMLやDeep Learningを優先するユースケース
既存手法を選択する考え方としては大きく2パターンあると考えます。
パフォーマンスを求められるケース
工場内での画像認識、物体検出
工場内のロボットなどで利用される画像認識
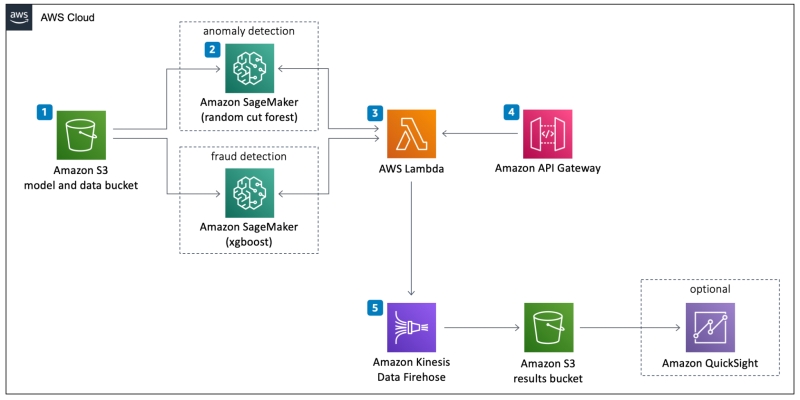
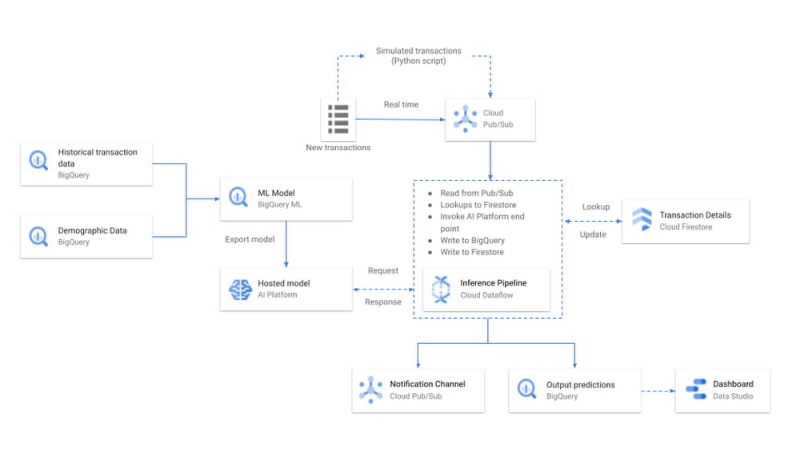
不正検知
前述に挙げたとおり、決済や送金時にタイムリーに不正を検知するようなユースケースにおいては、既存手法を用いたほうがベターです。一方で、敢えてタイムリーな不正検知ではなく、バッチ処理を前提として、金額や購入品目、IPアドレスだけでなく、より広範囲なSNSの情報を使って、異常検出を生成AIで行う試みは、教師あり学習を前提とした既存手法と比べて、開発 / 運用効率がリーズナブルで各企業がR&Dをしています。
過去データから判断が必要なケース
予測系
不動産価格や株価、売上、在庫、リスクの予測などは、過去データをベースにした回帰予測ベースの手法が適切です。予測自体は既存手法を使い、それを用いた活用の部分、たとえば予測に対してどういう手段で対処するべきか? というところで生成AIを使ったアーキテクチャを組むと相性が良いでしょう。
最適化系
配送ルートや在庫の最適化は、複数の条件
高度な画像認識や物体/音声検出
専門的知識を有していない人間が判断ができないもの、たとえば医療画像から癌を特定したり、部品の画像から傷を検出するなどの処理は、既存の手法が適切です。
ただし、これまではこういった画像認識や物体検出が用途問わず教師あり学習をベースとしたモデル開発が必要とされていましたが、専門性が求められなくても判断できる認識や検出には、開発コストを考えて生成AIを活用するケースもでてきています
生成AIをクラウド上で組み込んでいく場合のアーキテクト例
生成AIをパブリッククラウド上でシステムとして構築していく際、ベンダに依らず大体同じ構成になります。
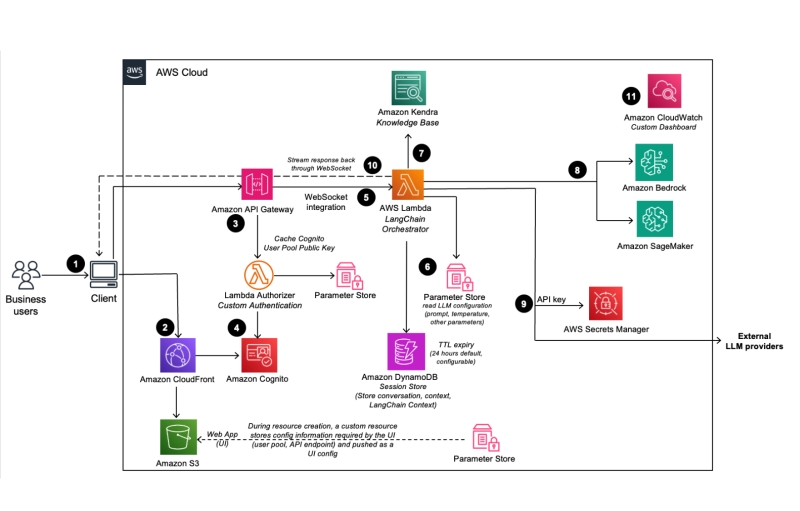
AWSの場合
AWSは検索コンポーネントとして、Amazon Kendra、生成AIコンポーネントとしてAmazon Bedrockを据えて、Lambdaを中心としたワークロードになります。
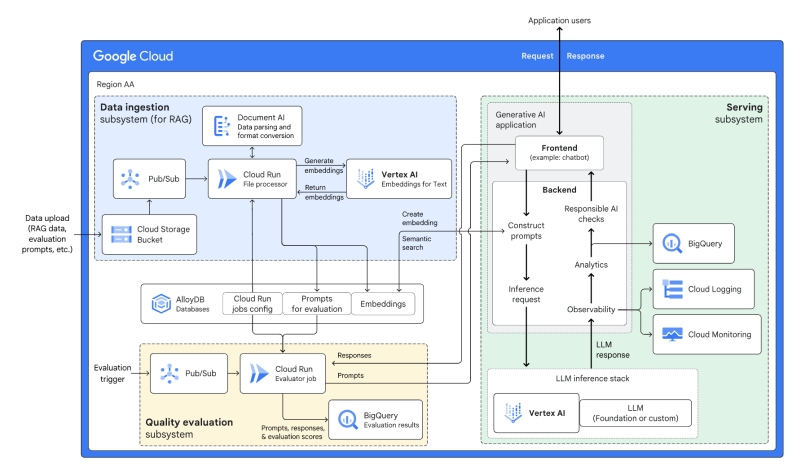
Google Cloudの場合
Google Cloudは検索コンポーネントとして、Vertex AI Search、生成AIコンポーネントとして、Vertex AI Gemini APIやDocument AI APIを据えて、Cloud Runをワークロードになります。
最後に
従来、機械学習を用いたサービス開発はモデル開発の難易度やデータセットに品質が依存するなど数多くの参入障壁があり、ルールベースのロジックに頼らざるを得ないケースもありました。
一方で生成AIを使うことで、簡易的にAIをシステムに組み込むことが可能になりました。ぜひ皆さんの現場でも生成AIを組み込んでみてみましょう!