


前回は、カーネルのお話から一度離れて、LinuxContainersプロジェクトから発表されたIncusというプロダクトを紹介しました。
少し間が空いてしまいましたが、今回からはまたLinuxカーネルの機能紹介に戻りましょう。第53回、第54回で紹介したCPUコントローラの話に続いて、メモリコントローラのお話をします。
メモリコントローラについては、以前、第5回で簡単に説明しています。このときの説明はcgroup v1のメモリコントローラを説明しました。今回は、cgroup v2のメモリコントローラを紹介します。
メモリ回収処理とメモリ負荷
コントローラを説明する前に、メモリコントローラを説明する前提となる、メモリの回収処理とメモリ負荷について簡単に紹介します。さらに詳しい情報については、Linuxカーネルの解説文書などをご参照ください[1]。
OS実行中には、色々とメモリを使う要素が存在します。もちろん、起動するプログラムがメモリを消費します。
また、ファイルを毎回直接ディスクから読み出していては処理が遅くなるので、一時的にメモリ上にファイルのデータをキャッシュします。このようなファイルのキャッシュを、ページキャッシュと呼びます。ページキャッシュの処理については第52回で説明していますのでご参照ください。
それ以外にもネットワーク通信のためのバッファーや、カーネルがさまざまな処理を行うためにメモリを使います。
メモリに余裕がある間は、空いているメモリを新たに割り当てていけます。しかし、システムの負荷が高くなり、メモリがたくさん使われるようになると、メモリが不足するようになります。そうなると、カーネルがすでに利用されているメモリを回収して解放し、新たに必要とされているところに割り当てます。このような処理をメモリの回収処理といいます。
図1のように、解放できるメモリ領域を回収して解放し、空きメモリを増やし、新たに必要なところに割り当てます。
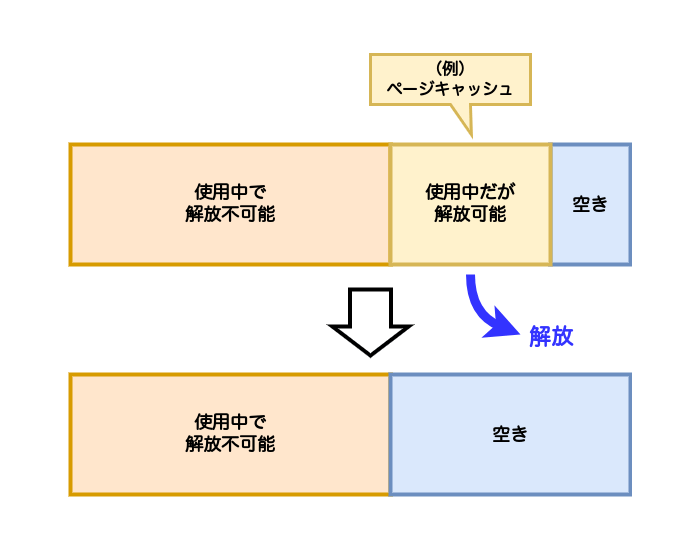
この回収処理は、たとえばページキャッシュや、あまり使われていないプログラムのデータから回収されます。ページキャッシュの場合は、ファイルから読み込まれて変更されていないのであればそのまま解放できます。変更されていればディスクへ書き戻したあと、解放できます。プログラムのデータの場合であれば、スワップへの書き出しが行われます。
このメモリが足りない状況が発生し、メモリを回収して新たに必要としているところに割り当てる動きや状態をメモリ負荷
メモリの回収処理を行っても必要なメモリが確保できない場合は、メモリコントローラとも密接に関係するOOM Killerという機能が発動し、システム上のプロセスを強制終了させ、空きメモリを作ります。cgroupに設定したメモリ制限に達した場合で、メモリが回収できない場合も、OOM Killerが、cgroup内のプロセスを強制終了します。
コントロールの対象
cgroup v2のメモリコントローラは、cgroupに属するタスクが消費しているメモリを追跡し、コントロールします。次のようなメモリ消費を追跡します。
- カーネル以外のユーザ空間のメモリ消費。つまりユーザ空間のプログラムが使用するメモリ
- カーネルデータ構造のメモリ消費
(dentryやinodeなど)。cgroup内のタスクが動作することで消費される、カーネル空間のメモリ - TCPソケットバッファ
cgroup v1との違い
cgroup v2のメモリコントローラでは、全体的にインターフェースファイルや機能が整理され、わかりやすくなりました。具体的な変化としては次のような項目があげられるでしょう。
メモリ保護
v1では、システムを安定して運用するために、特定のタスクがメモリを消費しすぎないように、メモリ消費の上限を設定できました。v2でも、この機能に変化はありません。
v2では、メモリ負荷が高まったときでも、cgroup内のタスクが動作しつづけられるよう、必要以上にメモリが回収されないように、メモリ保護が設定できるようになりました。第49回で説明したリソース分配の方法のうち、
第49回で書いたように、保護はツリー構造をたどったすべての祖先cgroupが保護レベル以下にある場合のみ保護されます。つまり、ツリーをルート方向にたどったときの最小値が保護の値となります。末端のcgroupに、そのcgroupより上位のcgroupで設定されているより大きな値を設定しても意味がありません。
メモリコントローラでは、保護のうち、強い保護とベストエフォートの保護の両方が実装されています。
メモリ保護については、次回説明します。
カーネルメモリの制限ファイル
cgroup v1のメモリコントローラでは、memory.というようなファイルが存在しました。このファイルを使い、cgroup内のタスクの動作することで消費される、カーネルが使用するメモリが制限できるとされていました。
先に説明した通り、cgroup v2のメモリコントローラでは、カーネルが使用するメモリ消費についても同時にカウントされますので、カーネルが使用メモリだけを制限するためのファイルは存在しません[3]。
OOM処理の充実
cgroup v1では、cgroup内のタスクが使用するメモリが制限値を超えた場合、OOM Killerを発動するかしないかを設定できました。
cgroup v2では、cgroup内のファイルでOOM Killerが発動するかしないかは設定しません。代わりに、絶対的な制限としてmemory.を使うか、制限を超えた場合に可能な限りメモリを回収しようとするものの、OOM Killerは発動させないmemory.を使うかで、OOM Killerの発動をコントロールできます。
memory.とmemory.の動きについては、このあと説明します。
また、OOM Killerが発動する際に、cgroup内で動作している一部のタスクだけがkillされてしまうと、cgroup内のタスク全体が不安定になる可能性があります。
このように、cgroup内のタスクが不安定になることを防ぐために、cgroupのメモリ消費が上限を超過した場合、cgroup内のタスクすべてを強制終了できるようになりました。
cgroupは通常はコンテナ単位で作成されますので、コンテナ内の一部のタスクのみがkillされて、コンテナ全体が不安定にならないように、コンテナ全体のタスクをkillできるようになりました。
インターフェースファイル
メモリコントローラを有効にした際に現れる主なインターフェースは表1のとおりです。
| ファイル名 | 機能 | 操作 | デフォルト値 |
|---|---|---|---|
memory. |
cgroupとその子孫のcgroupが現在使っているメモリの総量 | 読み取り | ー |
memory. |
cgroupとその子孫のcgroupのメモリ消費が設定した値より少ない場合、cgroup内のタスクのメモリは回収されない。回収可能なメモリがない場合はOOM Killerが呼ばれる | 読み書き | 0 |
memory. |
cgroupとその子孫cgroupのメモリ消費が設定した値より少ない場合、回収可能なメモリがない場合をのぞいては、cgroupのメモリは回収されない | 読み書き | 0 |
memory. |
cgroupとその子孫のcgroupのメモリ消費が設定値を超えた場合、メモリ回収の圧力がかかる。OOM Killerが呼ばれることはない | 読み書き | max |
memory. |
cgroupとその子孫のcgroupのメモリ消費が設定値を超えた場合で、減らせない場合はcgroupに対してOOM Killerが呼ばれる。デフォルト値はmax | 読み書き | max |
memory. |
スワップ使用量の制限値。cgroupとその子孫のcgroupのスワップ使用量が設定値を超えた場合、それ以上はスワップアウトしない | 読み書き | max |
memory. |
スワップ使用を絞る制限値。cgroupとその子孫のcgroupのスワップ使用量が設定値を超えた場合、スワップアウトを可能な限り絞る | 読み書き | max |
memory. |
この書き込んだバイト数分、メモリを回収する | 書き込み | ー |
memory. |
cgroup作成以降の自身とその子孫が使った最大のメモリ使用量 | 読み取り | ー |
memory. |
OOM Killerが呼ばれるとき、cgroup内と子孫のタスクをまとめて扱うか、扱わないか | 読み書き | 0 |
memory. |
cgroupとその子孫のcgroupで起こったイベント数 | 読み取り | ー |
memory. |
現在のメモリ使用の状況をメモリタイプごとに表示 | 読み取り | ー |
ここにあげたファイルのうち、memory.とmemory.はroot cgroupに存在します。それ以外はroot以外のcgroupにのみ存在します。
いずれのファイルの値も、階層構造が考慮されます。つまり、設定値や使用量は子孫のcgroupが使用する量まで含めた値です。
例えば、下位のcgroupで設定した制限値が、上位のcgroupで設定された制限値より大きな場合、下位で設定した制限値は上位に設定した制限値で制限されるため、設定する意味がありません。
メモリ使用の制限値
メモリコントローラで制限値を設定した場合の動きは、目に見える形では、cgroup v1のときと変わりません。cgroup内のタスクは、設定した制限値以上にメモリを使用できません。
制限値を設定する方法は、memory.とmemory.の2種類あります。この2つの違いを説明しておきましょう。
第49回で説明したとおり、この両方の設定値がmaxはハードリミットとしての絶対的な制限値で、highはソフトリミットとしてのベストエフォートの制限値です。
これだけでは具体的な違いがわかりづらいですね。
まず、memory.は、ここで設定した以上にメモリを使用させないため、設定した制限値に達し、メモリを減らせない場合は、OOM Killerが呼ばれ、強制的にメモリ消費を抑えます。一時的に制限値を超える可能性はありますが、絶対的な制限値として働きます。
一方、memory.は、設定した値を超えると、cgroup内のタスクに厳しいメモリ回収の圧力がかかります。厳しくメモリ回収を行い、メモリ消費を制限値以下に抑えようという動きになります。しかし、OOM Killerは発動しません。強制的にタスクを終了してメモリ消費を抑えることはありません。
memory.とmemory.の違いも同様です。
つまり、memory.では、絶対にメモリ消費が制限値内に抑えられる保証はありません。このとき、制限値に沿った運用をおこなうためには、管理ソフトウェアなどでモニタリングを行い、他のcgroupに所属するタスクを含め、ホスト全体で動作しているタスクのメモリ消費を調整したり、ホスト全体が不安定にならないように設定値を調整することが求められます。カーネル付属ドキュメントにも、
このような調整を行わないまま、memory.を使用し、制限値を超えた状態でメモリ圧力が高い状態が継続するような場合、回収できるメモリがなく、サービス自体が不安定になることにもつながりかねません。
memory.、memory.、memory.などのような統計値を表示するファイルなどを使ったり、PSI機能を使ったりして、メモリ消費状況を監視しながらメモリ消費を調整する必要があるでしょう。
それでは、実際に制限値を設定したときの動きを見ていきましょう。
以降の実行例では、次のように、メモリが2GB、スワップを2GB確保したホスト上で試しています。
$ free -m
total used free shared buff/cache available
Mem: 1963 179 1506 1 277 1631
Swap: 2168 0 2168
memory.max
まずは、memory.で絶対的な制限値を設定してみましょう。
まず、test01という名前でcgroupを作成し、シェルのPIDをtest01 cgroupに登録します。そして、test01 cgroupのmemory.を128MBに設定します。
$ sudo mkdir /sys/fs/cgroup/test01 (cgroupの作成) $ echo $$ | sudo tee /sys/fs/cgroup/test01/cgroup.procs (プロセスをtest01に追加) 985 $ echo 128M | sudo tee /sys/fs/cgroup/test01/memory.max (memory.maxを128MBに設定) 128M $ cat /sys/fs/cgroup/test01/cgroup.procs (cgroupに登録されたプロセスの確認) 985 1029 (←これはcatコマンドのPID) $ cat /sys/fs/cgroup/test01/memory.max (制限値の確認) 134217728
シェルから、メモリを256MB確保する設定でstress-ngコマンドを実行します。
$ stress-ng --vm 1 --vm-bytes 256M --vm-hang 0 -v :(略) stress-ng: debug: [3384] starting stressors stress-ng: debug: [3384] 1 stressor started stress-ng: debug: [3385] stress-ng-vm: started [3385] (instance 0) stress-ng: debug: [3385] stress-ng-vm using method 'all' :(略)
別のシェルを起動し、test01 cgroupのmemory.の値を監視します。watch -n1 cat /sys/のように監視しても良いでしょう。
$ while :; do sleep 1; cat /sys/fs/cgroup/test01/memory.current ; done 274432 274432 134184960 134184960 :(略) 134115328 134172672 134168576 134103040 :(略)
このように、メモリ使用量は大体128MBに設定した制限値を超えません。しかし、stress-ngコマンドに対してOOM Killerは発動せず、実行は続きます。
これは、スワップが確保されているためです。
$ free -m
total used free shared buff/cache available
Mem: 1963 315 1364 1 283 1495
Swap: 2168 165 2003
このように、スワップの使用量が増えており、memory.の設定を超えた分はスワップを使用していることがわかります。
では、スワップがない状態で試してみましょう。次のようにスワップをオフにします。
$ sudo swapoff -a (スワップをオフにする)
$ free -m
total used free shared buff/cache available
Mem: 1963 177 1502 1 283 1634
Swap: 0 0 0
さきほどと同様に、メモリを256MB消費する設定でstress-ngコマンドを実行します。
$ stress-ng --vm 1 --vm-bytes 256M --vm-hang 0 -v :(略) stress-ng: debug: [4796] stress-ng-vm: child died: signal 9 'SIGKILL' (instance 0) stress-ng: debug: [4796] stress-ng-vm: assuming killed by OOM killer, restarting again (instance 0) stress-ng: debug: [4796] stress-ng-vm: child died: signal 9 'SIGKILL' (instance 0) stress-ng: debug: [4796] stress-ng-vm: assuming killed by OOM killer, restarting again (instance 0) :(略)
するとstress-ngが、OOM Killerが原因で、子プロセスがSIGKILLを受け取ってkillされたことを出力しています。
memory.を監視すると、メモリを256MB確保しようとして、徐々にメモリ使用量が増えています。しかし、制限値付近に達すると、ふたたび消費量が少なくなっていることがわかります。プロセスがkillされたため、メモリが解放されたためです。
$ while :; do sleep 1; cat /sys/fs/cgroup/test01/memory.current ; done :(略) 91172864 110833664 134217728 5279744 5648384 23281664 37236736 53387264 74612736 95354880 121896960 15044608 5513216 :(略)
OOM Killerが発動したことは、カーネルが出力するログを確認しても出力されているはずです。
$ sudo dmesg :(略) [ 1845.108346] oom-kill:constraint=CONSTRAINT_MEMCG,nodemask=(null),cpuset=test01,mems_allowed=0,oom_memcg=/test01,task_memcg=/test01,task=stress-ng,pid=4797,uid=1000 [ 1845.108353] Memory cgroup out of memory: Killed process 4797 (stress-ng) total-vm:318184kB, anon-rss:127224kB, file-rss:268kB, shmem-rss:60kB, UID:1000 pgtables:600kB oom_score_adj:1000 [ 1845.213445] stress-ng invoked oom-killer: gfp_mask=0x1100cca(GFP_HIGHUSER_MOVABLE), order=0, oom_score_adj=1000 :(略)
memory.swap.max
先の実行例で、スワップがある場合は、プロセスが確保したメモリの一部はスワップを使用しましたので、OOM Killerが発動しませんでした。
ここで、スワップにも制限値を設定し、様子を観察してみましょう。
$ sudo mkdir /sys/fs/cgroup/test01 $ echo $$ | sudo tee /sys/fs/cgroup/test01/cgroup.procs 988 $ echo 128M | sudo tee /sys/fs/cgroup/test01/memory.max 128M $ echo 64M | sudo tee /sys/fs/cgroup/test01/memory.swap.max 64M $ cat /sys/fs/cgroup/test01/memory.swap.max 67108864
memory.を設定するところまでは、先の実行例と同じです。その後、memory.に制限値64MBを設定しました。
この状態で、stress-ngコマンドを実行します。
$ stress-ng --vm 1 --vm-bytes 256M --vm-hang 0 -v :(略) stress-ng: debug: [1170] stress-ng-vm: child died: signal 9 'SIGKILL' (instance 0) stress-ng: debug: [1170] stress-ng-vm: assuming killed by OOM killer, restarting again (instance 0) stress-ng: debug: [1170] stress-ng-vm: child died: signal 9 'SIGKILL' (instance 0) stress-ng: debug: [1170] stress-ng-vm: assuming killed by OOM killer, restarting again (instance 0)
スワップにも制限がかかっているため、OOM Killerが発動し、プロセスがkillされていることがわかります。
別のシェルでmemory.を監視すると、次のようになっていました。
$ while :; do sleep 1; cat /sys/fs/cgroup/test01/memory.current ; done :(略) 65323008 65323008 134180864 134184960 2064384 43810816 105848832 74170368 :(略)
memory.の制限値付近までメモリが確保されたあとは、OOM Killerによってプロセスがkillされたため、メモリ消費量が減っています。
さらに、memory.を監視すると、次のようになっていました。
$ while : ; do sleep 1; cat /sys/fs/cgroup/test01/memory.swap.current ; done :(略) 63832064 63832064 3678208 6983680 :(略)
こちらも、OOM Killerによりプロセスがkillされたため、スワップの使用量が減っています。
memory.high
ここまでで、memory.を設定すると、メモリの消費が制限できることを確認しました。ここからはmemory.の動きを見てみましょう。
memory.は、先に述べたように、制限値に達してもメモリの割り当てが厳しく制限されるだけで、OOM Killerは呼ばれません。それを確かめるために、スワップを無効にして試してみましょう。memory.のときは、OOM Killerが呼ばれてプロセスがkillされていました。
$ sudo swapoff -a (スワップの無効化) $ sudo mkdir /sys/fs/cgroup/test01 (cgroupの作成) $ echo $$ | sudo tee /sys/fs/cgroup/test01/cgroup.procs (プロセスをcgroupに追加) 991 $ echo 128M | sudo tee /sys/fs/cgroup/test01/memory.high (memory.highに制限値128MBを追加) 128M $ stress-ng --vm 1 --vm-bytes 256M --vm-hang 0 -v (メモリ256MBを確保するようにコマンドを実行) :(略) stress-ng: debug: [1044] starting stressors stress-ng: debug: [1044] 1 stressor started stress-ng: debug: [1045] stress-ng-vm: started [1045] (instance 0) :(略)
このとき、memory.ファイルを定期的に監視すると、次のように制限値近くまでメモリを確保したあとは、メモリ使用量は増加しません。
$ while :; do sleep 1; cat /sys/fs/cgroup/test01/memory.current ; done 81920 81920 136110080 135995392 136081408 136085504 136130560 136093696 136056832 136163328 :(略)
また、このとき、実際にstress-ngコマンドから起動される、メモリに負荷をかけるための子プロセスの状態をpsコマンドで確認すると、実行するタイミングにもよりますが、プロセス状態を示す列STAT列)D"となっています。
$ ps auxf | grep stress-ng karma 1044 1.2 0.3 56040 6216 pts/1 DL+ 13:25 0:00 | \_ stress-ng --vm 1 --vm-bytes 256M --vm-hang 0 -v karma 1045 1.2 0.0 56044 876 pts/1 D+ 13:25 0:00 | \_ stress-ng-vm [run] karma 1046 35.8 6.4 318188 129504 pts/1 D+ 13:25 0:10 | \_ stress-ng-vm [run]
man psで状態Dを調べると、"uninterruptible sleep (usually IO)"という状態であると書かれています。ここではIOが原因ではありませんが、プロセスは起動はしているものの、動作はしていないことがわかります。
カーネルのメッセージを確認しても、OOM Killerが発動したログは出力されていません。
このように、memory.ではOOM Killerは呼び出されないものの、cgroupは強いメモリ回収圧力にさらされます。新たにメモリが割当たるかどうかもわかりません。cgroup内のタスクのメモリ消費がmemory.の設定値を超えた場合でも、プロセス自体はkillされませんが、プロセスが正常にタスクを実行し続けられるかどうかはわかりません。
このように、memory.を超過し、メモリ回収ができないような場合、cgroup内のタスクが正常にタスクを実行しつづけられない可能性が高くなります。このため、先に述べたようにmemory.を設定する場合、cgroup内のタスクが消費するメモリをモニタリングし、なんらかの方法で回収圧力を軽減しなければならないでしょう。
まとめ
今回は、cgroupがv1からv2になり、メモリコントローラがどのように変わったのかについて説明しました。そして、メモリ制限を設定したときの動作について説明しました。
コンテナを運用する際には、コンテナエンジンやオーケストレータを通してメモリに関する設定することが多いでしょうから、memory.やmemory.という制限値や、次回説明する予定であるメモリ保証値を、直接設定することはないかもしれません。しかし、コンテナエンジンやオーケストレータで設定した値が、実際にcgroupでどのように設定され、動作するかを知っていると、実際に設定する値を決定する際や、トラブルが起きた際のトラブルシューティングに役立つでしょう。
もし、手動でメモリコントローラを設定する場合は、実際のワークロードと各種設定値について十分に理解した上で設定しないと、タスクの実行に影響が出る可能性があります。
次回は、今回に説明できなかったメモリ保証に関する設定を説明し、その動きを追う予定です。また、メモリ保証以外の設定や、cgroup v2のその他の機能についても説明する予定です。