



Cerebras Systems, Inc.はWSEというシリコンウェハーまるごと1枚を使った巨大なAIプロセッサを独自に開発し、それを使ったAIトレーニング向けのシステムCS-2を販売しているシリコンバレーのスタートアップです。
2024年の3月に最新バージョンのWSE-3が発表されたため、2024年5月、2年ぶりにCerebrasを訪問し、Senior Vice President, Product & StrategyであるAndy Hock氏に取材しました。
本稿ではWSE-3の設計方針や、それを使ったCS-3のクラスタシステムについて紹介します。

Cerebrasシステムの紹介
まずCerebrasシステムのアーキテクチャについて簡単に紹介しておきます。Cerebras社はシリコンウェハーまるごと1枚使ったプロセッサ、WSE
WSEはAIモデルのトレーニングを主たるターゲットとして設計・

2019年に作られた最初のWSEはTSMCの16nmプロセスで製造されましたが、2021年のWSE-2は同7nm、そして2024年のWSE-3は5nmで製造されています。各コアはデータフローマシンであり、メモリは各コアに局所的に割り当てられており、それらの総計はWSE-3では90万コア、44Gバイトにもなります。このアーキテクチャの概要については、筆者執筆の2020年のgihyo.
CerebrasはこのWSEに100G Ethernet 12本からなるI/
AIモデルのトレーニングにはとても時間が掛かるため、複数台のシステムを用いて効率良く並列に学習できることが重要です。
WSEはそれ1つで数十台のGPUクラスタに相当する回路規模がありますが、CS-2、CS-3を複数台接続してクラスタを構成し、分散学習させることも可能です。Cerebrasは高効率なクラスタを実現するためにSwarm X、Memory Xと呼ばれる製品を開発し、提供しています
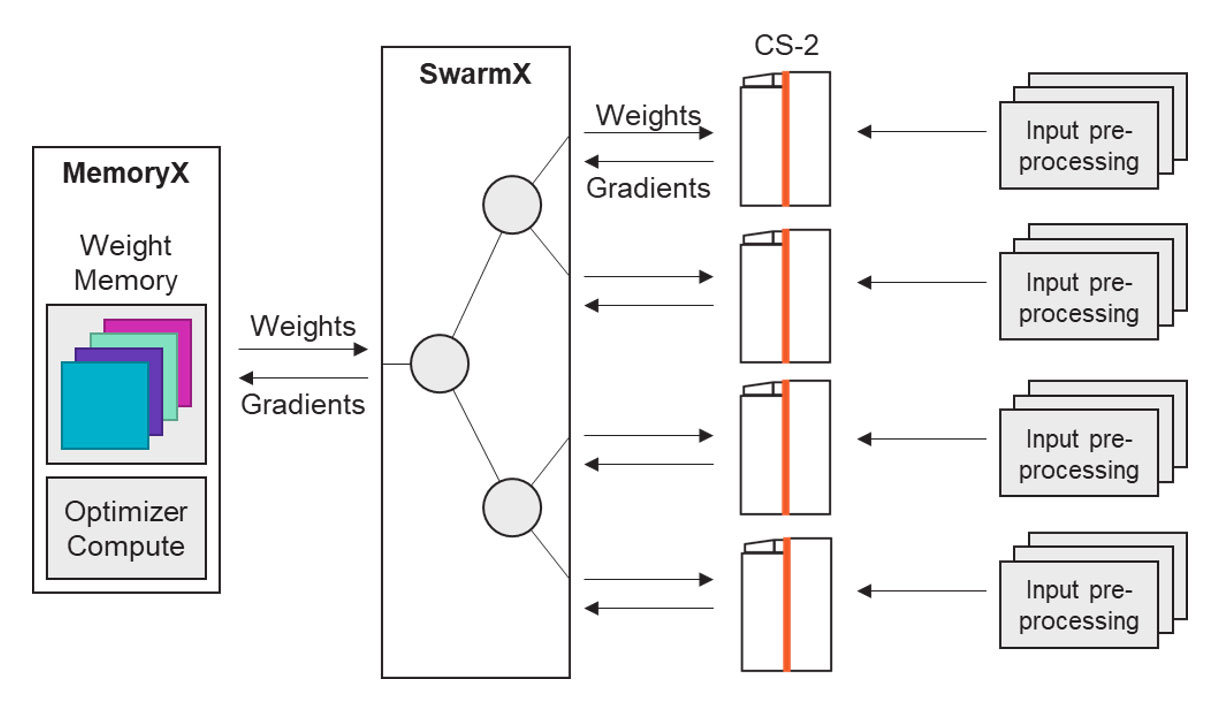
Memory Xはメモリを大量に搭載し、全ニューロンのWeight情報を保持しています。ここから各システムに最新のWeight情報を配るのが、通常のシステムならネットワークスイッチに相当するSwarm Xです。
本記事の前半では新しいWSE-3と並列学習のためのクラスタシステムについて、後半ではクラスタシステムを前提とした大規模AIトレーニングの
WSE-3
筆者はまだCerebrasがステルス状態だった2018年以来、継続的に何度もオフィスを訪問し、その着実な歩みを見て来ました。今回の訪問は2年ぶり、応じてくれたAndyとも2年ぶりの再会でした。
- Andy:さて
(今回は) どこから始めましょうか。 - Yasu:私の最初の質問はCS-2からCS-3の進化についてです。まずCS-2の7nm から今回5nmに進み、トランジスタバジェット
(予定したサイズに詰め込めるトランジスタの数) は2倍近くになったはずです[1]、[2]。しかしコアの数は80万から90万とほとんど増えていません。今回の進化の主たるターゲットは何だったのでしょう? - Andy:我々はコアに変更を加えました。つまりFP16を拡大し、INT8を加えました。WSE-2ではFP16, BF16をサポートしていましたが、この新しい16本のSIMDによって、コアあたり実質2倍のFLOPSになりました。
- 最終的に我々はWSE-2に比べて2倍のパフォーマンスを手に入れています。また我々はそれを同じ価格で提供します。まさにこれはムーアの法則に沿うものです。でしょう? 我々は効率良く
(2年で) 2倍の性能を提供しているのです。 - Yasu:実際のところそれ
(2倍の性能) をどうやって実現したのでしょう。クロックが速くなる、とか、メモリが高速になる、と言ったことがあったのでしょうか。 - Andy:まず
(先ほど説明した) SIMDのデータパスが倍になったこと。また、きっちり2倍ではありませんが、多めのコア (80万から90万に増えた)、そして多めの電力、です。我々はより多くの電力を供給できており、そのためによりクロックを高速化しています。 - Yasu:もっと多くの電力ですか。
- Andy:ウェーファーに対してより多くの電力です。システムレベルの電力要求は変化ありません。
(データセンター業者に対する電力要求は同じ、という意味) - Yasu:ええっ?
どうやったのでしょう。 - Andy:我々が行ったのは、ウェハーに対するより効率の良い電力供給、です。それらのコンビネーションによってWSE-3はWSE-2に対する2倍の性能を実現しています。
- CS-3
(システム全体) で23KW消費しますが、そのうちWSE-3が18KWです。つまり残り5KWはファン、ポンプ、冷却、I/ O サブシステムなど全ての他の機能にいきます。 - Yasu:まだあなた方はFPGAをI/
Oに使っているのですか? (筆者はWSE-1のときから彼らが100G Ethernetを直接FPGAで扱っているのを見ています) - Andy:ええ、4つのXilinxの高性能FPGAをTCP/
IPの終端と、Ethernetからウェハーへのプロトコル変換に使っています。 - Yasu:それらも電力食いますからね。
- Andy:はい。まあでもポンプや冷却の方が電力を食いますね。それと比べれば小さいです。
- Yasu:なるほど。もう1つ気になるのがメモリです。メモリを今回足しませんでしたが、それは何故ですか?
SIMDエンジンが増えたWSE-3にしても、WSE-2と同サイズでメモリは十分だった、ということですか? - Andy:はい。結果的にわかったんです。大規模言語モデルでさえ、このメモリサイズで足りる、ということが。ただしそれはどうやって実行しているか、によります。
- 我々はチップ上にSRAMを持っています
(そうですね)。またそれとは独立にスケーラブルな外部DRAMバンク、Memory Xを持っています。ここにモデルのフルセット (の内部状態) を保持しています。つまり我々が大規模なモデルをトレーニングするとき、我々はそのモデルをまるごとMemory Xに入れます。1ペタバイトまるごとね。 - それはすなわち、Memory Xは24 Trillion (24兆)パラメータのモデルまでをストアできる、ということです[3]。
- Memory XはモデルのWeightを置く場所になり、あるときに実行するのは送られてきたモデルの1レイヤごとになります。そのためオンチップのメモリ
(SRAM) はモデルの個別のレイヤをサポートするのに十分大きければ良い、つまり実行対象の1つのレイヤだけを保持すれば良いことになります。そして40GバイトのSRAMは、100 Billionを超えるようなモデルであってもサポートできることが結果的に分かったのです。 - Yasu:ほぼキャッシュのような状態ですね?
- Andy:そのとおり。実際のところ、我々のプログラマはそう考えています。
「これはただ大きなL-zero (Level 0) キャッシュだ」 と。

- オリジナルのCS-1のデザインは1つのモデルの全レイヤをWeight情報ごとウェハーの上に保持して処理する設計でした。
- しかしCS-2世代で登場したMemory Xによって、Weightはウェハーの中に用意する必要がなくなりました。システム外部からストーリミングすることによって、あるモデルの中の最大のレイヤがシリコンの上に収まりさえすれば良い、というアーキテクチャになったのです。
- Weightは外部から受け取り、結果も外部に
(Memory Xに) 戻せば良い。そのためウェハー上のメモリ量は増やさなくてもよくなった、というわけです。
このことについての詳しい説明がCerebrasのブログにありますので興味のある方は参照すると良いでしょう。そこにストリーミングによって生じる遅延の隠蔽に関するホワイトペーパーへのリンクもあります。
Swarm Xを用いたクラスタ
Memory Xのことが出てきたので、気になっていたCS-2, CS-3を用いたクラスタシステムに話を進めました。
- Yasu:Memory Xと組み合わせて使うSwarm Xスイッチがありましたね
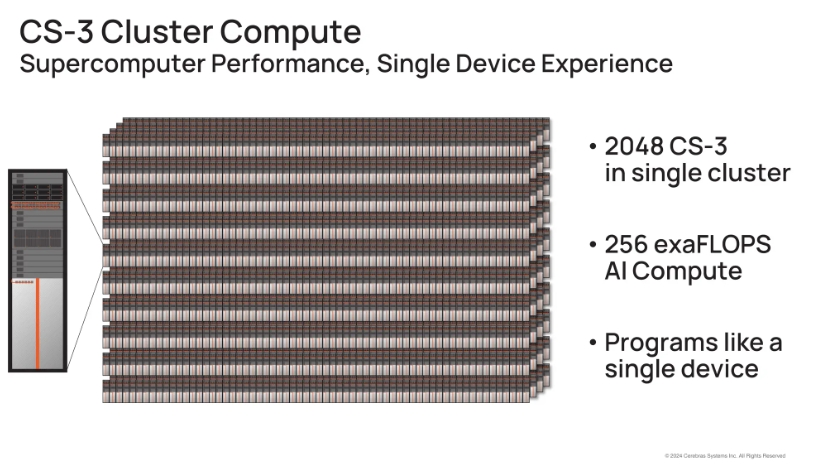
(前述図1参照)。それを使ってツリー構造のクラスタ構成を作っていたはずです。最大幾つのCS-3が接続できるのですか? - Andy:それも新しいアップデートの1つです。2,048台まで接続することができるようになりました
(図2)。
- Yasu:うわあ……
(不覚にもクスクス笑ってしまいました。この高価なCS-3を2,048台とは、なかなか非現実的な数字です。もちろん設計時はそのくらいのスケール感であるべきなのですが……)。 - Andy:
(釣られてクスクスしつつ) いやあ、前にも (2年前のこと) 議論しましたよね。あれから我々はI/ Oを進歩させて、Swarm Xも進歩したんです。CS-2 のときは192台のクラスタが構成できました。 - Yasu:その数は覚えています。
- Andy:だったらそれほど驚くことではないですよね? AIコンピュータへの要求はとても大きいので、いくらかの顧客は192台でもクラスタの大きさについて心配していたくらいです。ただまあちょっと気が遠くなる数字ですね。
- これで256 Exaflopsコンピュータ、つまり究極のモデル、Llama 72bみたいなものを1日で、つまりMeta の巨大なクラスタで1ヵ月掛かるところを1日でトレーニングできるクラスタとなります。
- ところで我々のアーキテクチャのアドバンテージとして、もう1つの
「性能」 のファクタがあります。つまりクラスタにシステムを追加するときに何が起きるか、です。GPUを使ったシステムで 「1GPUから1,000GPUにしたら性能は800倍になる」 というのは真実ではありません。これはGPUクラスタの通信とメモリのボトルネックのためですが、我々のクラスタにはその問題がないのです。
Andyは、Cerebrasのシステムはクラスタに追加したCS-2の台数分だけ性能が上がるグラフを見せてくれました
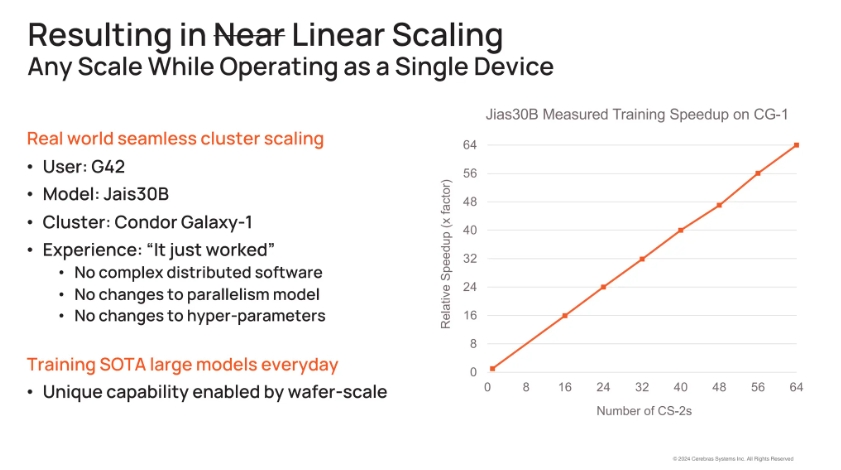
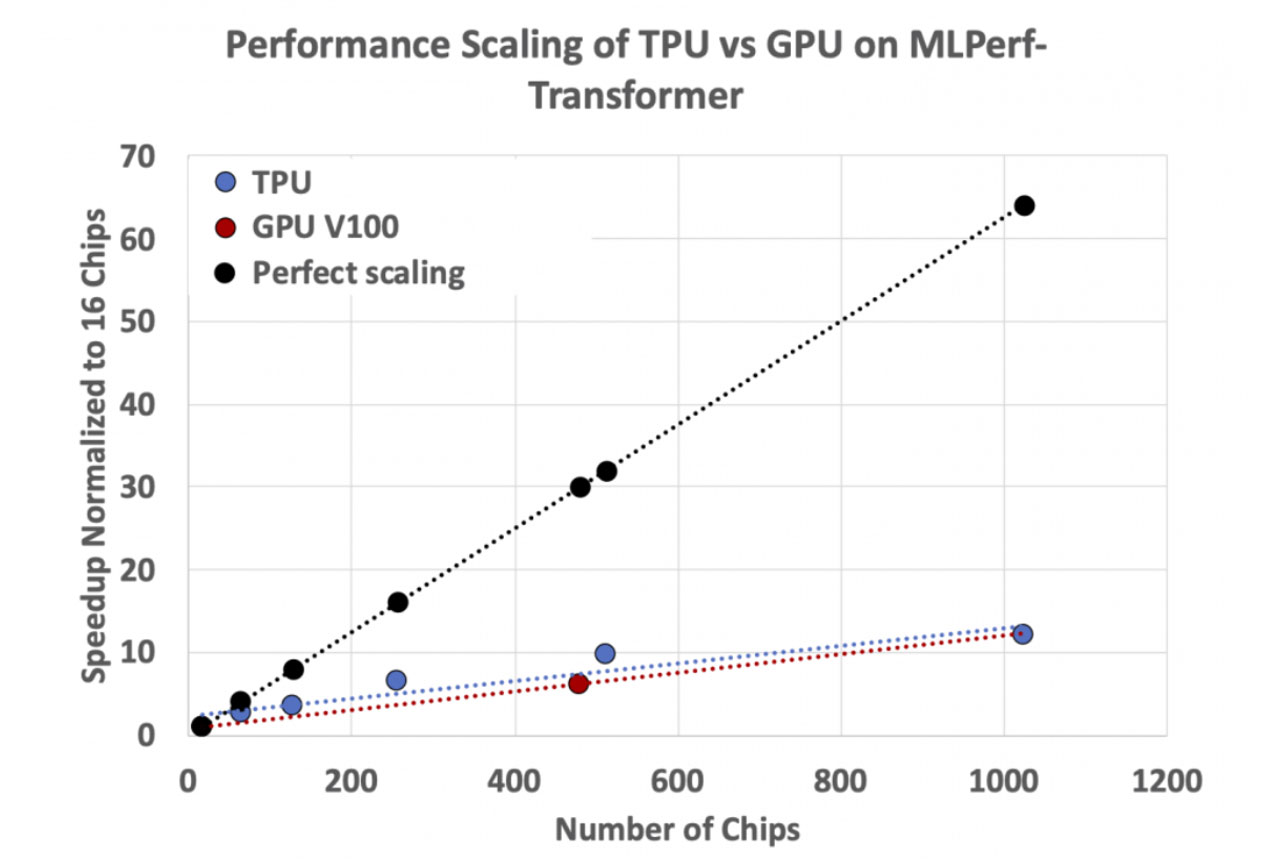
このスケーラビリティ
つまりスイッチに相当するSwarm Xはブロードキャスト
リダクションのようなアプリケーション寄りの処理をネットワーク機器の中で転送中に行うことを
多くの場合、CPUオフローディング手法の1つとして語られます。Memory Xとの組み合わせで、Swarm Xがブロードキャストとリダクションの処理をネットワーク機器中で階層的に実行するのは、シンプルですが効率の良い、まるでIn-Network Computingのお手本のような実装例です。
こうした仕組みはNVIDIAのNVSwitchチップにも実装されています。SHARPというワードで調べるといろいろ出てきます。元はMellanoxのInfiniband向け技術[4]でした。
- Yasu:最初
(2021年) にMemory XとSwarm Xの記事を読んだ時、ああこれはスケーラビリティの高い、良い方法だと思いました。Swarm Xでブロードキャストとリダクション処理をしていますからね。 - Andy:そうしたシンプルなアーキテクチャを使うことができた理由は、やはりウェハーだからです。ネットワーク中でのブロードキャストとリダクションが
(このように効率良く) 可能なのは、クラスタに接続したウェハーそれぞれで、同じモデルが丸ごと走っているからです。各システムでの違いは学習のために与えるデータだけです。 - つまり
(分散学習の手法としては) データ並列だけを行うのです。モデル並列は起きませんし、Tensor並列もありません。するとクラスタ内のウェハーは、他のウェハーと通信することがありません。このためネットワークに対する要求が大きくならないのです。 - たとえば2枚のウェハーがあったとして、あなたはただデータのサブセットをそれぞれに与えるだけなのです。両方のウェハーで完全なモデルが動き、スイッチはWeightをMemory Xから取りだし、ブロードキャストして、ウェハーがその計算を終えたら、その勾配情報をSwarm Xの経路でreduceするのです。ウェハーが互いに通信することはありません。
- Yasu:つまりニューロン間の通信を担うネットワークは変わらずウェハーの中にあるわけですね。良いアイディアです。
(シリコンの) 外のネットワークはそれに較べるととても貧弱です。この問題は誰も解決できませんからね。
現在のGPUチップには今どきのモデルは大きすぎ、データ並列だけでなく、モデル並列やTensor並列を導入せざるを得ません。するとGPU間での通信が
もちろんNVDIA自身もこの通信オーバヘッドの問題を強く認識しており、NVSwitchチップを開発し
対してCerebrasのシステムではモデル丸ごとが入ってしまうためにモデル分割が起きず、それに起因する通信がネットワークに出ることはなく、さらにWeightの配布と勾配情報の回収をIn-Network Computingで効率よく処理しています。この設計はウェハースケール・
(後編へ続く)