



皆さんこんにちは。スリーシェイク代表の吉田です。
前回に続き、今回は医療業界で生成AIがすでにどう活用されているか、また課題や解決策について、前提となる法律や実現に必要なアーキテクチャを解説していきます。
「医療の世界とAI」
医療行為を生成AIが代替できるのか
MLやDeep Learningの進歩により自動運転が実現しつつある今、エンジニア視点だと
まず医師法第17条にて
生成AIであれ、MLやDeep Learningを用いた推論であれ、いずれにせよ医療行為
この法律自体は昭和23年に制定されたものですが、のちに厚生労働省は
つまり、生成AIの医療業界での活路は
- 院内業務の支援
- 医学教育
- 医学論文調査
- 医療記録や診断報告書などの事務作業
- 患者説明の支援
といった医療行為以外にまつわる膨大な業務の支援をゴールとして設計する必要があります
また開発するアプリケーションの内容によっては、
これは診断、治療、予防に使用され、そのアプリケーションによる副作用または機能障害によって生命や健康に影響を与えるものが該当します
つまり、生成AIアプリケーション自体が生命、及び健康にほとんど影響がないものは医療機器に該当しないことになります。
個人情報の取扱について
医療業界において個人情報の取り扱いは非常に重要です。
前述した医療行為や医療機器に該当しないAIアプリケーション開発や生成AIを活用するうえで、正しく個人情報関連の法律を意識してデータ設計をする必要があります。
改めて
| 氏名、生年月日 | ||
| 特定の個人を識別することができるもの |
||
| 個人識別符号 | 身体的特徴系符号 | ゲノムデータ |
| 顔データ | ||
| 虹彩模様データ | ||
| 声紋データ | ||
| 歩行態様データ | ||
| 手の静脈形状データ | ||
| 手の静脈形状データ | ||
| 指紋・ |
||
| 番号系符号 | パスポート番号 | |
| 基礎年金番号 | ||
| 運転免許証番号 | ||
| 住民票コード | ||
| マイナンバー | ||
| 健康保険証の記号・ |
||
このあたりは実際のアプリケーション開発現場でも意識されている領域だと思います。
さらに医療業界で意識しなければいけないのは、平成29年5月の改正個人情報保護法により定義された
- 診療記録
- 病歴
- 医療従事者が知り得た診療情報や調剤情報
(調剤録、薬剤服用歴、お薬手帳に記載された情報) - 健康診断の結果及び保健指導の内容
- 障害の事実
- 犯罪により害を被った事実
などが挙げられます。つまり、その情報を第三者が知ることで不当な差別や偏見、不利益が生じてしまう可能性があるものが対象です。
これら個人情報及び要配慮個人情報については、
- 本人の同意なしの個人情報の目的外利用禁止
- 本人の同意なしの要配慮個人情報の取得禁止
- 本人の同意なしの個人情報の第三者提供禁止
と定義されており、たとえば個人情報や要配慮個人情報を社外のクラウドサービスが提供するストレージやデータベースに格納することは違反なのか?
一方で
これは実際の現場でどうするかというと、クラウドサービスを選定するときに、事業者が保存したデータに対してアクセスしない旨が明記された利用規約を確認することをオススメします
以下、各クラウドサービスに関してのポリシーや規約です。
全般的なプライバシーポリシーについて(PDF)
生成AIについて
ここで重要なのが、医療機関で取得したデータに基づいて構築した生成AI、もしくはDeep Learningアプリケーションなどを
取得した医療機関において活用されるのであれば第三者提供には該当しませんが、たとえば別の医療機関や研究機関、もしくは汎用的なサービスとして一般公開される場合は該当します。
つまり、日本中のあらゆる診療機関からデータを統合して、汎用的な医療LLM
情報:令和6年4月に施行された次世代医療基盤法により、氏名など単体で個人を識別できる情報を削除
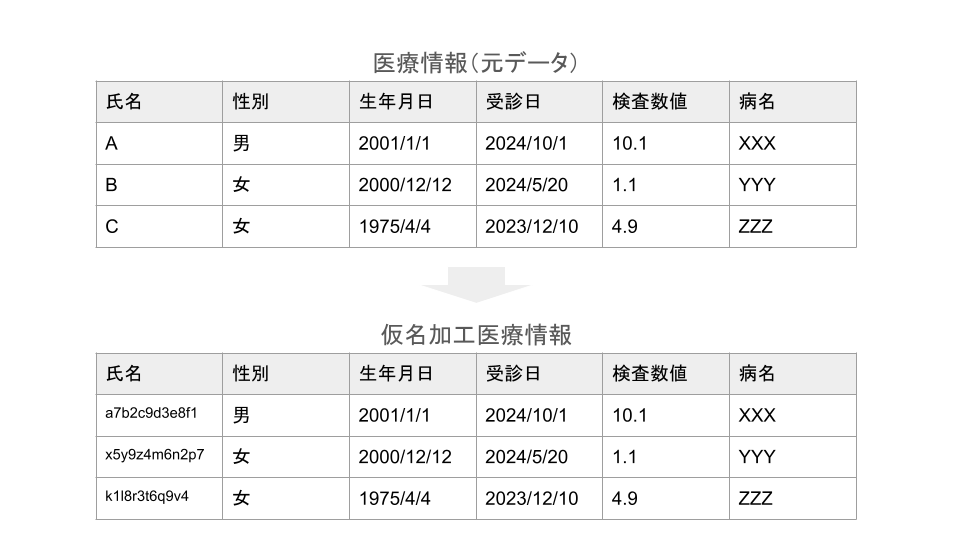
さて、医療業界における前置きが長くなりましたが、前向きに捉えると、上記を踏まえたうえで、医療機関内で取得したデータを基に、正しくアプリケーションを構築、運用していけば、生成AIやDeep LearningなどのAIの恩恵をパブリッククラウド上で受けられるということです。
医療特化型のLLMについて
オープンLLM
このようなオープンなモデルを用いて国内利用も今後広まると考えられます。
ちなみに弊社ではR&Dの一環として、Meditron-7BとELYZA-japanese-Llama-2-7bをモデルマージして日本語用LLMの開発に着手したことがありますが、Google Cloud上の環境でa2-highgpu-1g
またGoogle Cloudではクローズドモデルとして、医療に特化したMedLMモデルが提供されています。事例は少ないですが、今後パブリッククラウド事業者側が提供する業界特化型のモデルを活用したアーキテクチャも進むことでしょう。
以上から、現段階ではあくまで汎用的なLLMに対してRAGを構築するアーキテクチャを採用するのがベターと考えられます。
なぜ医療業界において生成AIが普及しないのか
私自身この数ヵ月間、医療システムについて実際の現場を見せていただく機会がありましたが、前段の法的な制約以外に、以下の課題があると認識しました。
- 医療システムは用途に応じてメーカーが異なる医療機器、システムが複雑に密結合している集合体であり、生成AIを活用には既存システム連携が必要
(= システム連携コストが高い) - 生成AIの生成物について、品質保証が難しい
- 現場
(医師、看護師など) におけるITリテラシー - そもそも大規模なシステム投資は他業界と比べて難しい
2については、Nature Medicineの論文が提唱する
たとえば、生成AIが出力した内容に従って医療文章を確認せずに作成し、その内容が間違っていた場合、その結果責任は生成AIの利用者が負うことになります。そういう意味で、医療現場が生成AIについて責任を持って利用する必要があり、開発するエンジニアは導入時に医療現場に対してシステムの内容
3については、医療現場は当然ですがITリテラシーの高い業界ではありません。すでに導入されているシステムに最適化されたオペレーションを日々回している現場にとって、新しいUXを導入することは学習コストや業務フロー変更の負担が高く、それを受け入れられる状況にありません。
4については、医療は基本的に診療報酬と研究費に依存したビジネスモデルであり、半数以上が赤字運営という厳しい病院経営の中で、大規模なシステム投資に踏み切るのは容易ではありません。
つまり、日本の医療業界において生成AIを活躍させるポイントは、
- いかに学習コストを下げられるか
- いかに低コストで始められるか
- いかに品質面をトレースできるか
- いかに個人情報を守るか
の4点を押さえていく必要があります
海外の医療業界では生成AIはどう活用されているか
HCA Healthcare社は、ハンズフリーデバイスを用いて、医師と患者の会話から生成AIを用いて医療メモを作成し、自動的に電子カルテに転送する仕組みを提供することで、看護師間の引き継ぎ負荷を減らしました。音声と生成AIとの相性は良いですから、良い事例だと思います。

日本の医療業界では生成AIはどう活用されているか
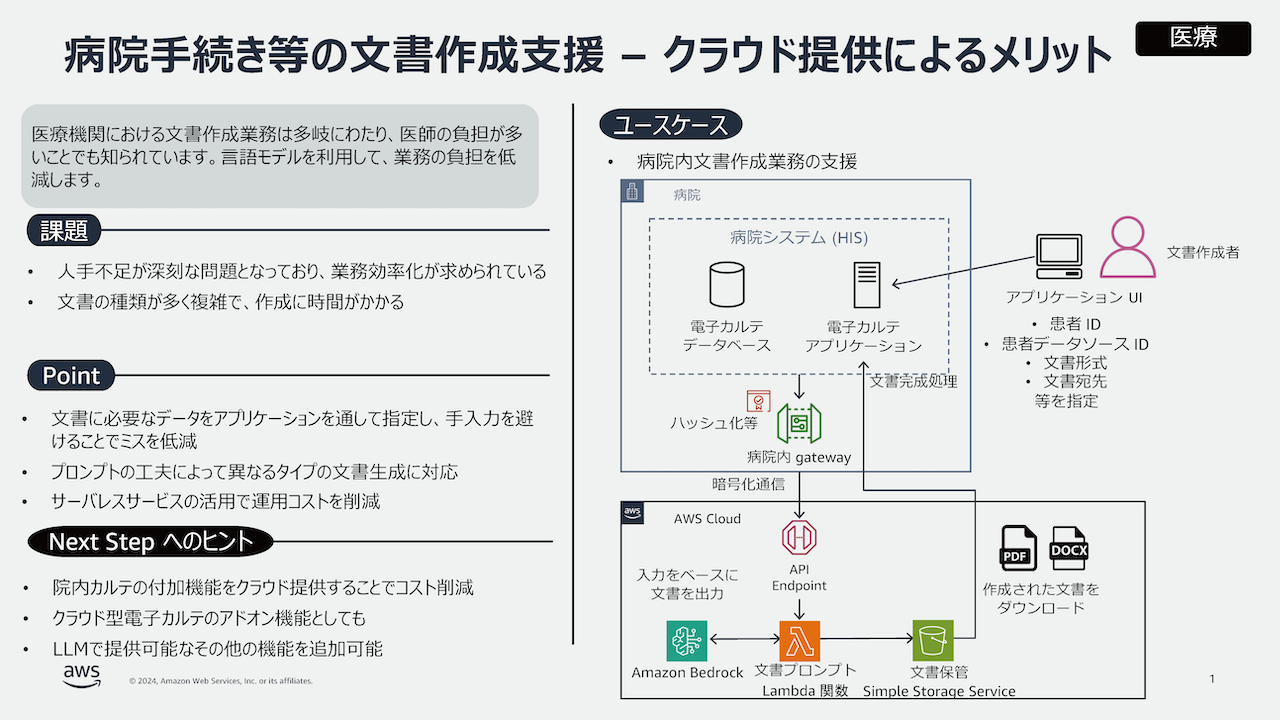
まだまだ日本においては事例が少ないですが、音声や画像よりも電子カルテから医療文章
図3のようにAWSからユースケースが提示されています。オンプレミス環境にある電子カルテシステムからDirect Connectを通じて、生成AIを呼び出すアーキテクチャとなり構造としては比較的シンプルです。
医療業界においてクラウド上で生成AIを活用したアプリケーションを構築するには
前段が長くなりましたが、個人情報や品質面をクリアしつつ、低コストなアーキテクチャをどう作っていくかについて解説します。ここでは何をデータとして取り扱うのかに合わせて大きく2パターンで考えていくことを推奨します
個人情報(要配慮個人情報を含む)を扱わないアプリケーションの場合
各パブリッククラウドにおいて生成AIアプリケーションを構築する際の基本的なアーキテクチャは、前回の記事を参考にしていただくと良いと思います。
ここで重要となるのが、
つまり
- RAGとして誤って個人データが含まれてないか
- プロンプトとして誤って個人データが含まれていないか
(防げないか)
という2点です。そこでAWSとGoogle Cloud上の生成AIアプリケーションについて、以下の対策を提案します。
AWSの場合
- AWS Macieを使ってS3上に保管されているRAGのRAWデータに個人情報がないか検知する
- Amazon Bedrock Guardrailsを利用して、個人情報がプロンプトされた場合にフィルタリングする
AWS MacieはS3に保存しているデータ
Google Cloudの場合
- Cloud DLPを用いて、Cloud Storage上に保管されているRAGのRAWデータに個人情報がないか検知する
- Guardrails for Amazon Bedrockに類似する機能はないため、アプリケーション側でプロンプト入力時にバリデーションを行うか、LLMが出力した内容に対して個人情報をマスキングして出力する機能をいれる
Google Cloudの場合は、Gemini API側で個人情報をフィルターする機能を提供しているので、それ以前にフィルタリングする機構はいらないよね、という発想に基づいているところが特徴です。
以上に加えて、各クラウドベンダが提供する次のセキュリティ原則を参考にするとよりベターです。
個人情報(要配慮個人情報を含む)を扱うアプリケーションの場合
個人情報を含んだアプリケーションを構築する場合は、上記セキュリティ原則に加えて厚生労働省などがまとめた
さらに万が一の漏洩リスクを鑑みて、個人情報を仮名加工
AWSの場合
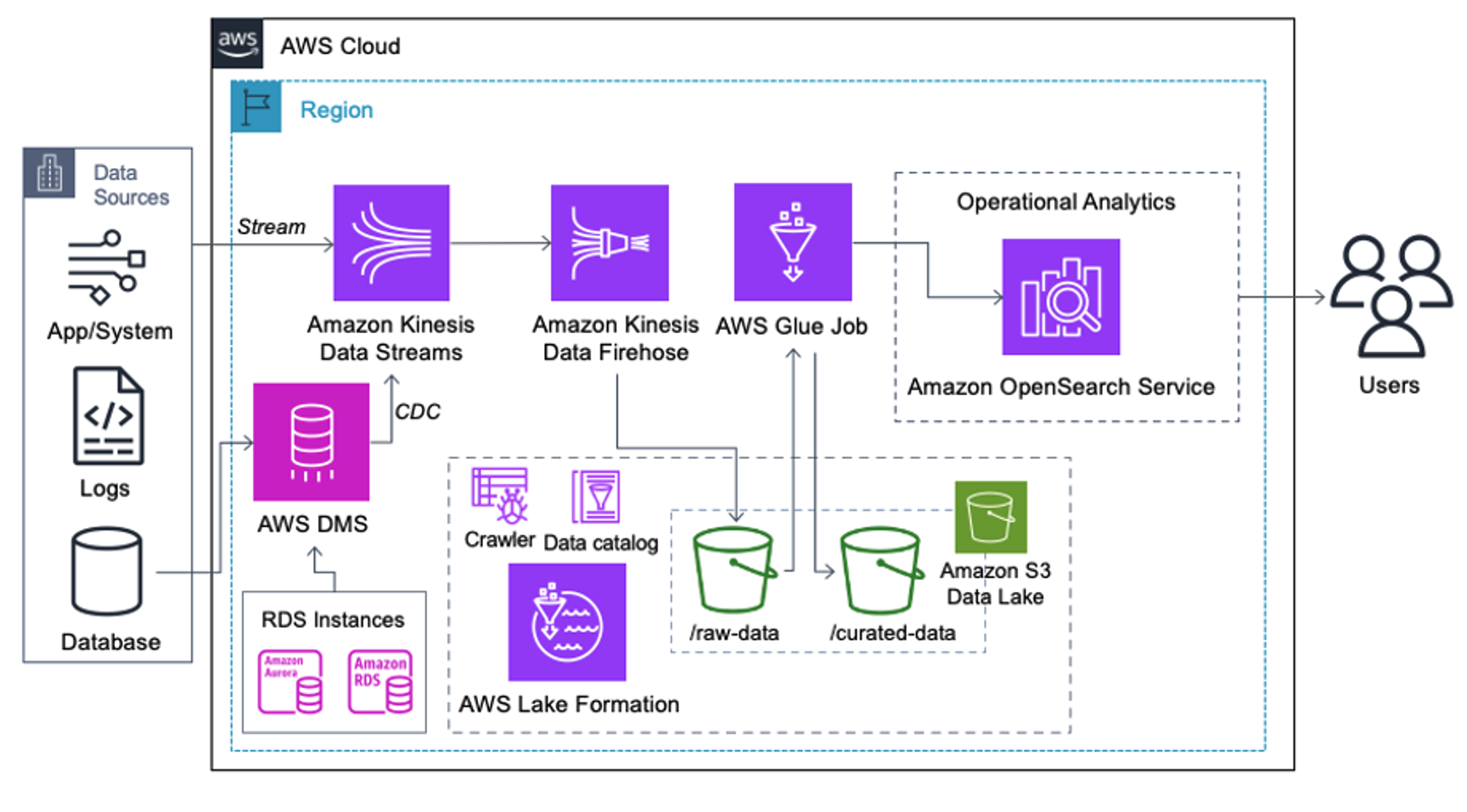
Glue DataBrewの活用
RAGとしてS3に保存されたRAWデータに対して、図4のようにGlue DataBrewを用いて仮名加工したデータをRAGとして取り込みます。図ではRAWデータをGlueで加工してOpenSearchに取り込む
Google Cloudの場合
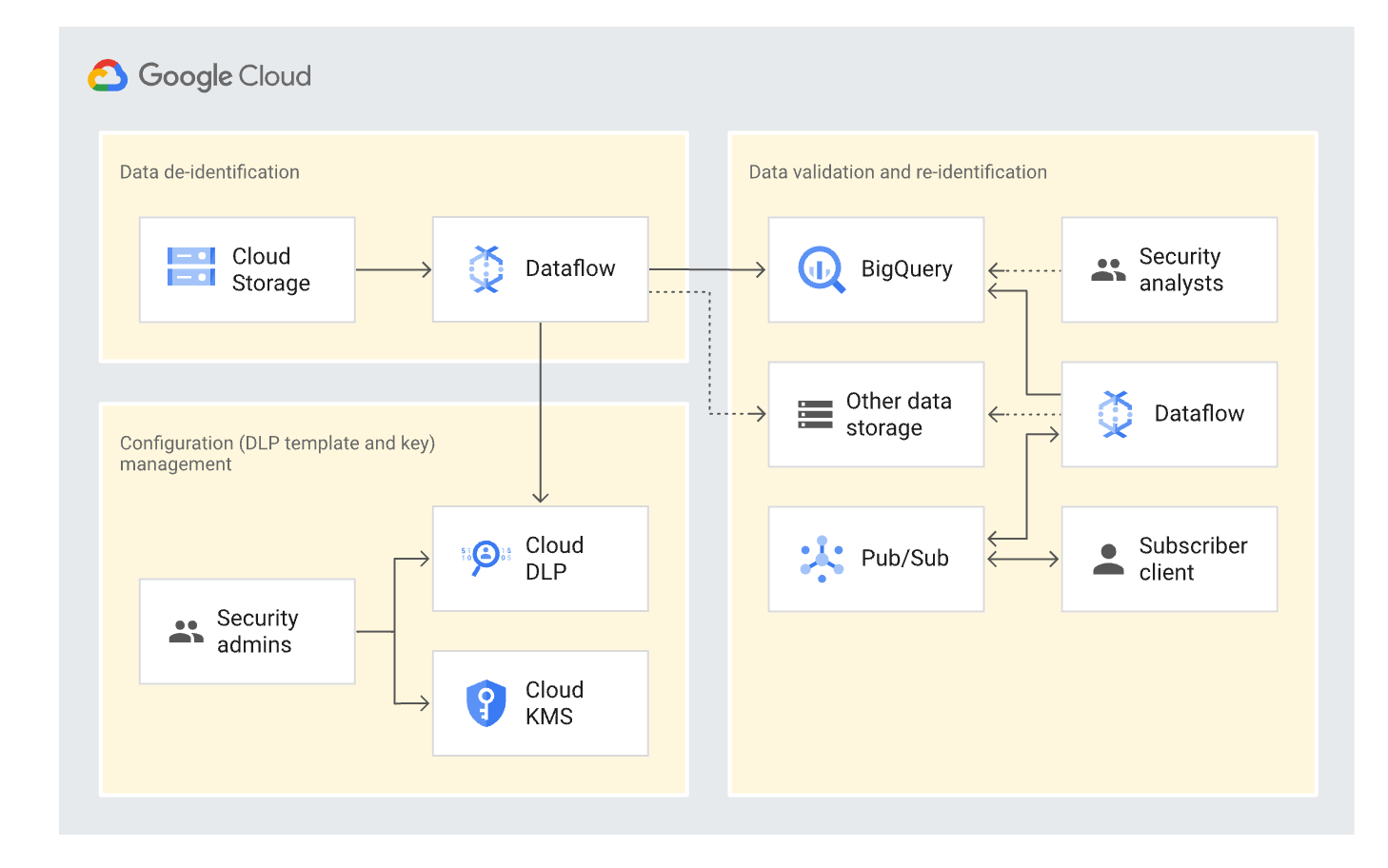
Cloud DLPの活用
RAGとしてCloud Storageに保存されたRAWデータに対して、Cloud DLPを用いて仮名加工し、Cloud StorageもしくはBigQueryを経由してRAGとして利用します。図5ではCloud Storageに逐次保存されたデータに対して、Dataflowを用いてリアルタイム且つ大規模な個人情報の検知及びマスキング処理を行い、BigQueryやストレージに保存するアーキテクチャです。しかし、生成AIアプリケーションの特性上
上記はいずれも一時的には
ここは実際の現場で、どこまで情報漏洩のリスクを考えるかを議論して選定すると良いと思います。
最後に
医療業界における生成AIの活用はインパクトは大きくても非常に多くの制約条件があります。
エンジニアとしてこれらを把握しながら、アーキテクチャを考えていくことでtoo muchなシステムにならず、医療業界にとっても挑戦する敷居が下がるのではないでしょうか。