



筆者のキャリアは日本IBMのエンジニアとして始まった。特許も取った経験もあり、IBMの研究開発はクローズドな環境で守り抜く姿勢があたりまえのことだった。2024年2月、IBMは日本語版基盤モデル
AI技術や普及が急速に進む中、IBMは囲い込みではなく、オープン化へ舵を切り始めている。IBM のInstructLabというオープンソースプロジェクトは、すでにGitHubに上がっている
そこで、この対談が実現した。IBM Graniteの日本語開発に携わる日本IBMの東京基礎研究所で技術理事を務める 倉田岳人氏とCode for Japanの川邊悠紀氏という2人のキーパーソンを迎え、オープンソースLLMの可能性と、それが企業や社会にどのような変革をもたらすのかを議論する場だ。
この対談を通じて、IBMがオープンソースにコミットすることで描かれる未来、そしてCode for Japanのようなエンジニアコミュニティとの協力がどのような力を生むのか、その核心に迫った。
Code for Japanの最新動向とIBMのLLM
まずはCode for Japan川邊氏にCode for Japanのオープンソースを中心とした活動を紹介してもらった。
Code for Japanが提供するオープンソース開発環境
Code for Japan
注目すべきは、オープンソース技術を地域や地方自治体に実装し、具体的な成果を生み出している点だ。たとえば、
さらに、スマートシティのデータ連携基盤として
Code for Japanのオープンソースプロジェクトは、GitHub上に100近く公開されており、能登半島地震での復興支援やコロナウイルス対策ダッシュボードの構築など、多岐にわたる活動を展開している。とくに川邊氏は、web3技術を応用した新しい仕組み
彼はIBMのLLMオープンソースをどのように見るのか?
IBMが目指すオープンソースAIの未来:倉田氏が語るLLM開発の挑戦
次に倉田氏およびIBMが開発するLLMの最新動向について紹介する。
倉田氏はおよそ20年間、IBM Researchの東京基礎研究所で音声認識や自然言語処理の研究に携わっている。直近のプロジェクトはIBM Graniteの日本語LLMの研究をリードし、オープンソースプロジェクトにも寄与している。

- 倉田:
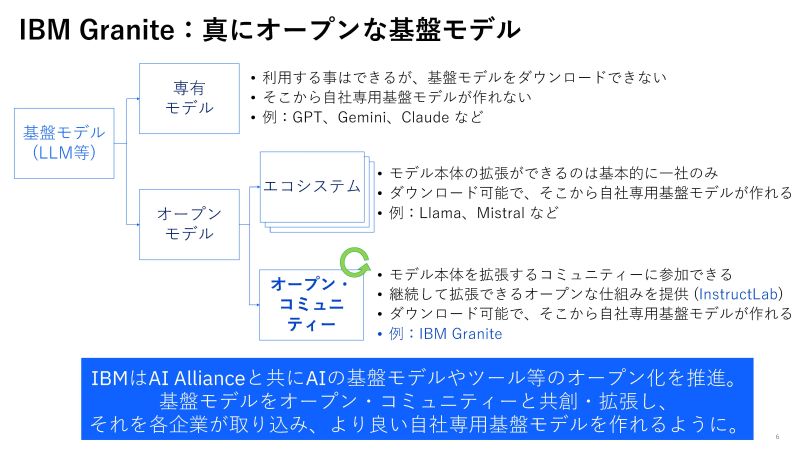
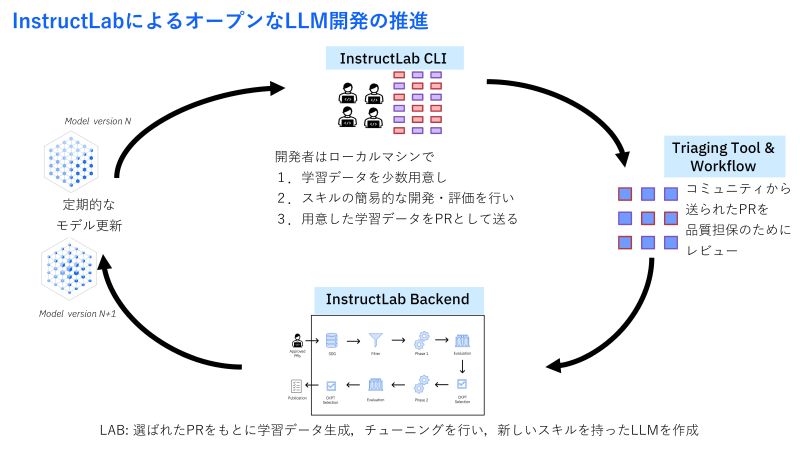
「IBMは、クローズドなAIではなく、オープンなAIを目指しています。現在、IBMはオープンソース、オープンコミュニティに力を入れており、LLMの開発の共創を進めています。InstructLabというオープンソースをGitHubに公開し、コミュニティの力を借りてLLMの改良を進めてようとしています。開発者がLLMに機能を追加した場合、プルリクエスト (PR) を通じて、プロジェクトに参加できる仕組みを提供しています。 - LLMの開発には大量の計算リソースが必要ですが、IBMとRed Hatはそのインフラを提供します。図3のInstructLab Backendにあたる部分です。開発されたものはGitHubにアップされ、コミュニティ全体で改良を加えることができます。
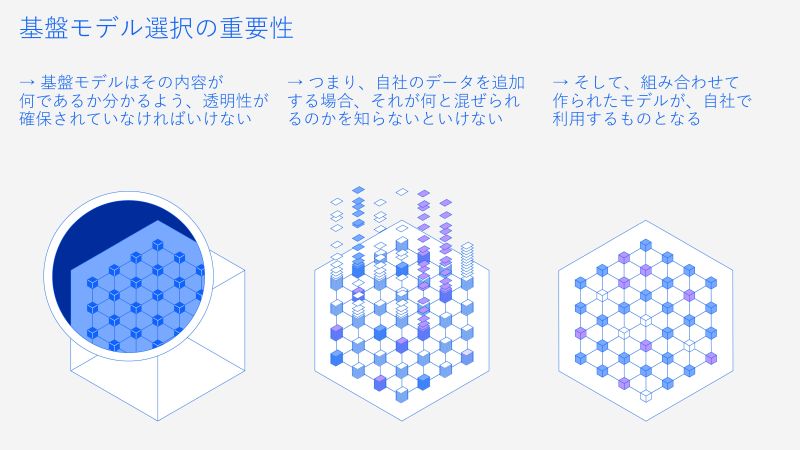
- IBMの透明性あるLLMは、個人や企業がフォークして使えるようにもなっており、真にオープンな基盤モデルを提供しています。企業内でのLLMの運用においても、コミュニティで育てられたものを基盤として、企業内でさらに改良を加えていくことができるようになっています。
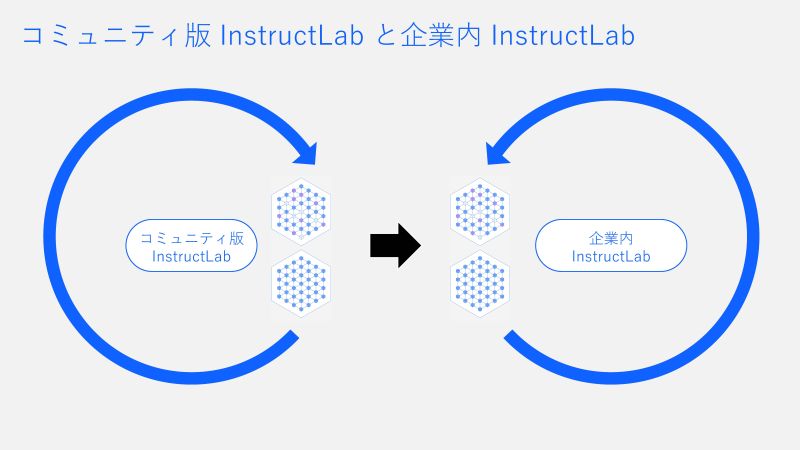
- 企業の皆さまに安心していただきたいのは、コミュニティ版から企業版への矢印が一方通行である点です。コミュニティで開発した透明性が担保されたモデルを企業はご利用いただけ、さらにその後の企業内での改良は企業内に閉じているので漏洩などの心配なく安心してお使いいただけます。」
- 倉田:
「IBMはテクノロジーの活用により、より良い社会の実現に貢献することを重視しており、AIのオープン化に踏み切りました。ただ、オープンソース化するだけではなく、Red Hatとの協力により、実績あるLinuxで培ったオープンソースプロジェクトの考え方を活用しています。さらに、テクニカルレポートも公開しており、LLMの学習データの詳細や学習パラメータまで記載するなど、これまでにないオープンさを追求しています。私もテクニカルレポート公開に参加してますが、今までのIBMでは考えられないほど詳細に公開しているので、ここからもIBMのオープンへの真剣さを受け取ってもらえると思います。 - LLMの開発において、データは厳密に管理されており、IBMモデルは適切なライセンスと透明性を持っています。データのレビューは非常に大変ですが、法務、知財、購買部などさまざまな角度からIBMの厳しい基準に従って行われています。
- IBMは、ビジネスに対応するAIおよびデータ・
プラットフォームであるIBM watsonxを活用して、適材適所の基盤モデルをお客様にデプロイしていただき、エージェントやアシスタントなどを作る仕組みまでをご提供することを目指しています。今後、さらにコミュニティの力を活かして、LLMの開発を進めていく予定です」。
オープンソースLLMの可能性を探る対談

お互いの取り組みと理念を理解した上で、Code for Japanの川邊氏とIBMの倉田氏のディスカッションが本格的に始まる。川邊氏が持つ地域や市民と密接に結びついたオープンソースの経験と、倉田氏がIBMというグローバルな舞台で培ったAI技術、オープン化の流れへの洞察が、ここで交差する。果たして、企業のために作られるLLMにオープンソースエンジニアが参加する際に気をつけるべきこと、そして、可能性とはどのようなものなのか?
- 川邊:
「LLMのオープンソースと言いつつ、計算部分のパワーはIBMのハードウェアパワーが使えるのと、データの法務・ 購買部などの多面的レビューが行われることに感動しました。1つ気になったのは、 「プルリクエスト (図3、PR) をどのように選ぶのか?」 という点です。 - IBMの中では、ビジネスとして一定の評価基準を設けて、それを通過したものが選ばれると理解しています。ただ、そこに対しての透明性はどのように担保されているのでしょうか。
- たとえば、リジェクト
(却下) された理由については、どれほど明示されているのか。実際にオープンソースのプロジェクトでは、たまにリクエストの採用について議論が起こることがあります。実例として、コロナ対策サイトを作った際に、いくつかのリクエストが却下されたときに 「なぜそれを却下したのか、理由を教えてほしい」 といった意見が噴出しました。緊急時には素早く意思決定しなければならない場面もあり、リソースを重要な部分に振り向けるために、リジェクトが必要になることもあります。ただ、リジェクトする際に、納得感のあるプロセスが重要です」。 - 倉田:
「IBMではモデルやテクニカルレポートをオープンソース化しています。これには私も関わっています。IBMは知財の扱い方を重視する会社であり、これまでは公開する内容にも慎重でしたが、最近はその方針が変わり、よりオープンに進めるようになっています。
- 具体的には、LLMの学習パラメータや使用しているデータの詳細まで公開しています。これにより、透明性を確保しながらも、データのライセンスや知的財産に対する懸念を排除しています。また、社内でもリーガルや購買部を通じて徹底したレビューを行っていますので、安心して使っていただける体制を整えています。
- IBMの研究所に20年間おりますが、かつてはIBMの知財は厳守するものだったので、ここまでオープンにしていいのか? と、最初は戸惑いましたが、今はオープンソースが社会やお客様の未来のために貢献するプロセスと考え、透明性を徹底しています。PRの選択基準についても同様に、ガイド・
ワークフローを公開し、透明性を担保しています」。 - 川邊:
「Code for Japanのように、市民や自治体との協力を通じて透明性を高めているプロジェクトが参画することで、LLMの信頼性がさらに向上するのではないかと考えます。Code for Japanは、既存のオープンソース技術を地域や住民に適応させることで信頼を築いていますし、国際的なプロジェクトとも連携する力があります。コミュニティをどのように運営し、ローカルな知見をどのように取り入れていくかが、これからの課題だと感じます」。 - 倉田:
「そのとおりです。LLMのような技術は、幅広い知見とコミュニティの力を借りることで進化していくと考えています。Code for Japanのようなすでに多くのエンジニアや自治体と繋がっているコミュニティと一緒に盛り上げ、企業や自治体も安心して技術を取り入れられる仕組みができていくでしょう。コミュニティ版で開発されたモデルを企業に導入し、その後さらに進化させるという流れを作りたいと考えています (図4参照)」。 - 川邊:
「オープンソースのプロジェクトでは、出口が明確であることが重要です。作ったものが他の人に使われたり、フィードバックをもらうことで、開発者にとっても大きなモチベーションになります。今回のIBMのオープンソースのプロジェクトは、コミュニティで育てられた技術が企業で使われるという出口が魅力的です。エンジニアがコミュニティとして貢献したものが、企業でも採用されるという貢献実感を得られることは、開発者にとっても誇りになると思います」。 - 倉田:
「Linuxでも同様の流れがありましたが、貢献したいという人々が集まるコミュニティによって技術が育てられると信じています。また、我々の戦略としては、オープンソースのモデルを企業に導入し、さらにはエージェントやアシスタントを作る仕組みまで一気通貫で提供することを目指しています。 - その先には業界ごとのコミュニティを形成することも視野に入れています。同じ業界内の企業が共通の問題に取り組むために、コミュニティを通じてLLMを作り上げることができれば、さらに多くの価値を提供できると思います。製造業や金融業など、業界ごとにコミュニティを形成して技術を共有することで、効率的な導入が可能になるでしょう」。
AIへの期待と技術の民主化に向けて
今回の対談を通して、IBMがオープンソースLLMの開発に本格的に取り組む背景には、AI技術がもたらす未来への強い責任感と、技術の民主化への明確なビジョンがあることを強く感じた。倉田氏が伝えるIBM Researchの姿勢である
Code for Japanの川邊氏とIBMの倉田氏が語る未来像は、単に技術革新に留まらず、エンジニアやコミュニティが連携し、業界全体を巻き込んだ共創の時代を見据えている。オープンソースの力を最大限に活かし、地域や社会に深く根ざした課題解決に挑む姿勢は、現代の企業に求められる新しい価値観を体現しているといえるだろう。
AI開発の未来は、もはや一部のプレイヤーだけが握るものではないのかもしれない。オープンソースの力で、すべての企業、エンジニア、そして社会全体が新たなステージへと歩み出すその時代は、今まさに始まろうとしている。