



前回からの改善方針
前回、Vertex AI Agent Builder
しかし、前回の状態では以下のような機能における課題と、運用における課題があります。
- 社内コンテキストがないため、社内業務に対して向いていない
- 修正した際のロールバックなどができない
- Agent が想定外の動きをしているなどのときに、ログが参照できない
今回の記事ではこの課題をどう解消するかについて、前回作成したある企業の求人メール文章の作成と、送信を行うAgentを使い、解説しながら改善していきたいと思います。
社内コンテキストを利用する
RAGを使ったコンテキストの取得の意義
生成AIで利用されているLLM
そのため、LLMは学習されていない、持っていない情報についてはハルシネーション
AI Agentに社内情報を元に作業を行ってもらうためには、LLMに出力してくる前に社内情報
この方法をRetrieval Arguments Generation
DataStoresはAgent Builderから作成できますが、Searchで作成したアプリケーションから DataStore を利用する形になります。
今回のユースケースでRAGを使うメリットは、LLMがメール文章を考える際に社内のコンテキストに沿って作成してくれるという点になります。
たとえば、企業のエンジニア事業部で求めているスキルや経験は事業内容や会社文化によっても異なり、そのため、採用メールはその会社のコンテキストに沿って作成されることが求められます。
Agentの目的に細かく記載して対応することも可能ではありますが、要件の修正時にAgent Builderを修正する必要がある、また、他のエンジニアを抱える事業部で利用したい場合、別のAgent Builderのアプリケーションを作成する必要があります。
DataStoreの作成方法
今回は架空の会社における、どんなスタックでサービスを提供をしているかなどの情報をためているDataStoreを作成して、それを元にメールの文章を作成してもらうようにします。
DataStoreはToolsの一部です。そのため、Toolsから新しく作成します。
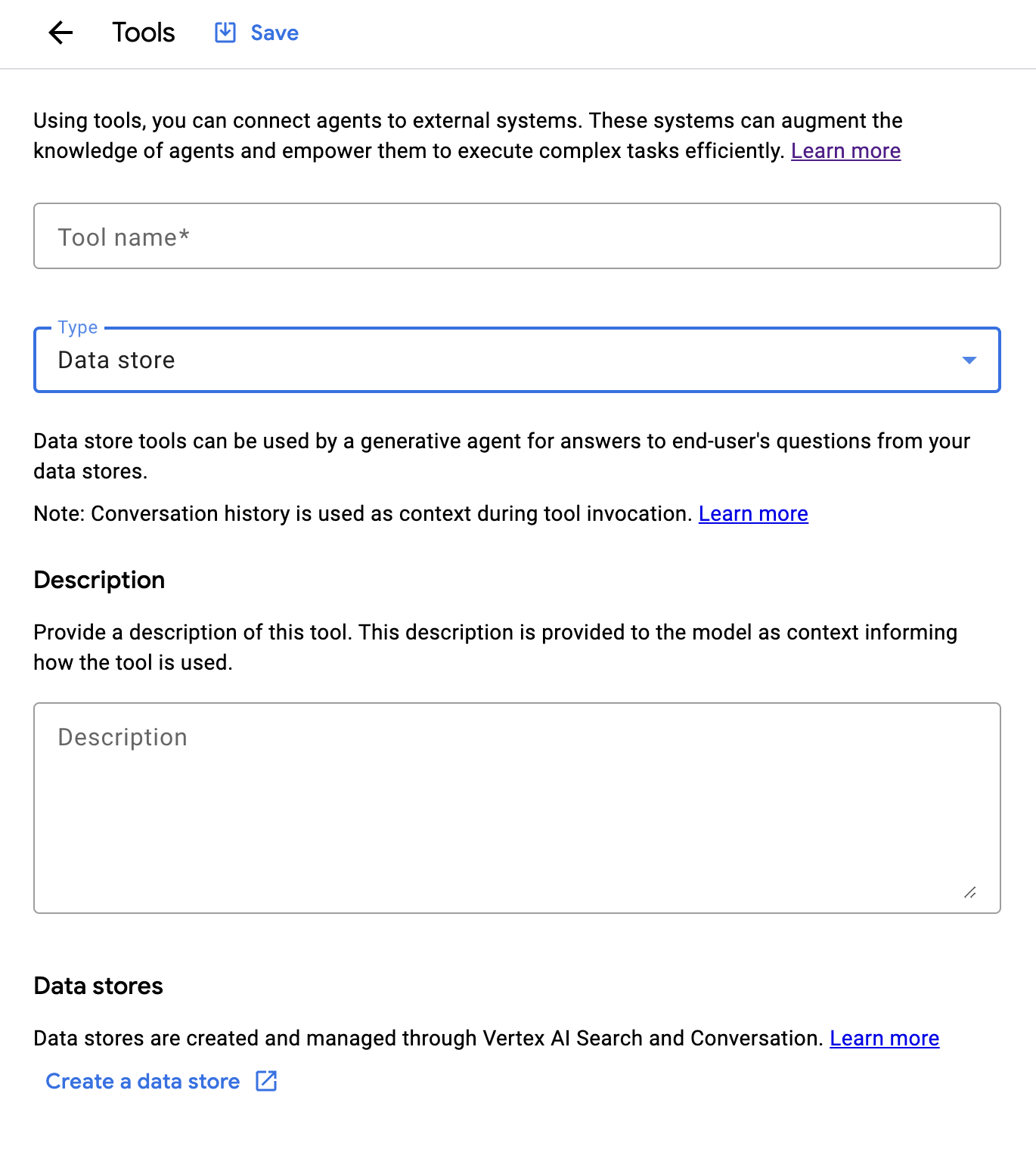
次に、別タブでDataStoreを作成していきます。そのため、Searchのアプリケーション作成画面に遷移しアプリケーションを作成します。
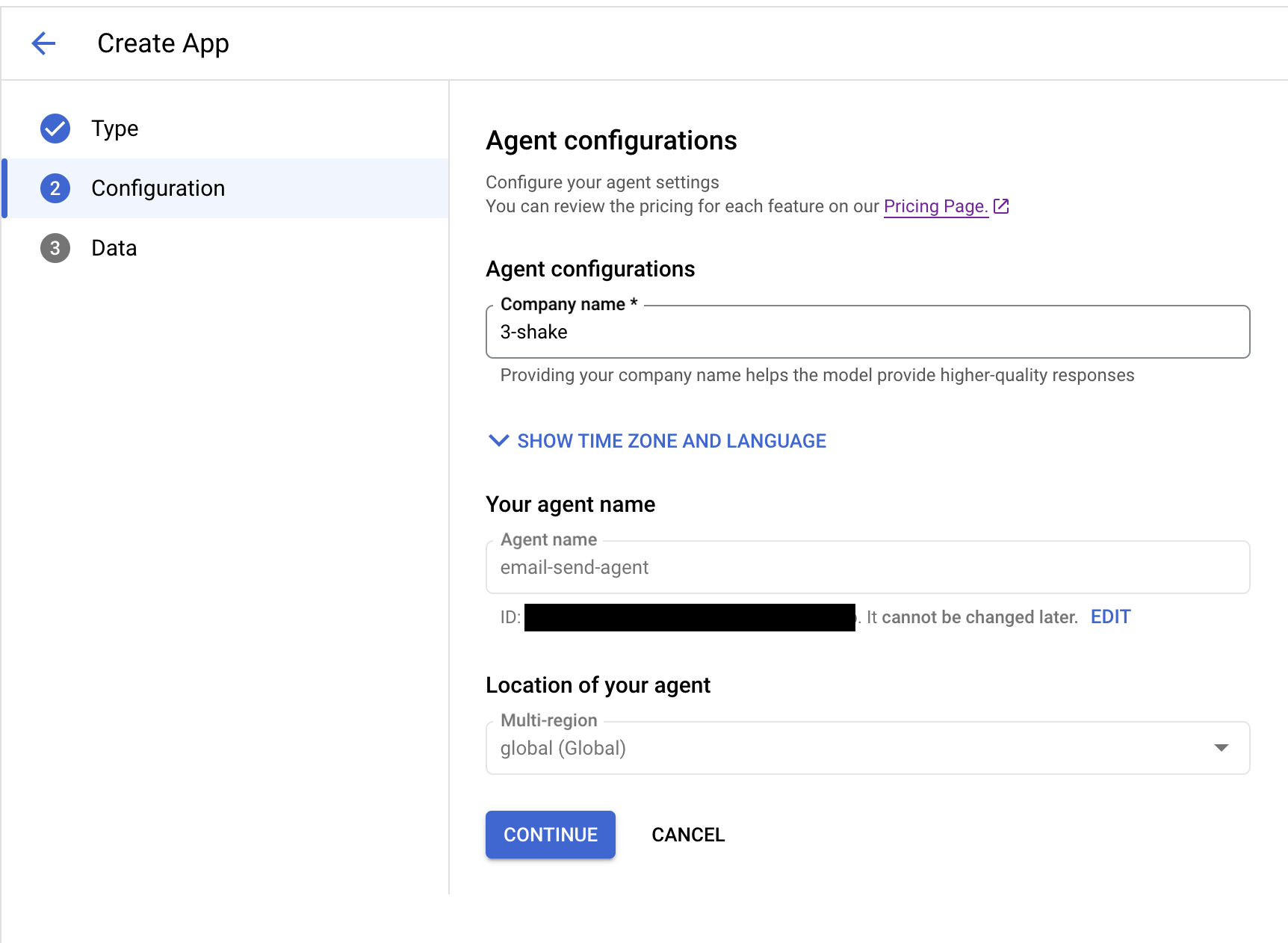
入力するCompany Nameですが、こちらがあるとLLMが会社の情報を使う際に参照されます。次にアプリケーションが参照するDataStoreを作成していきます。
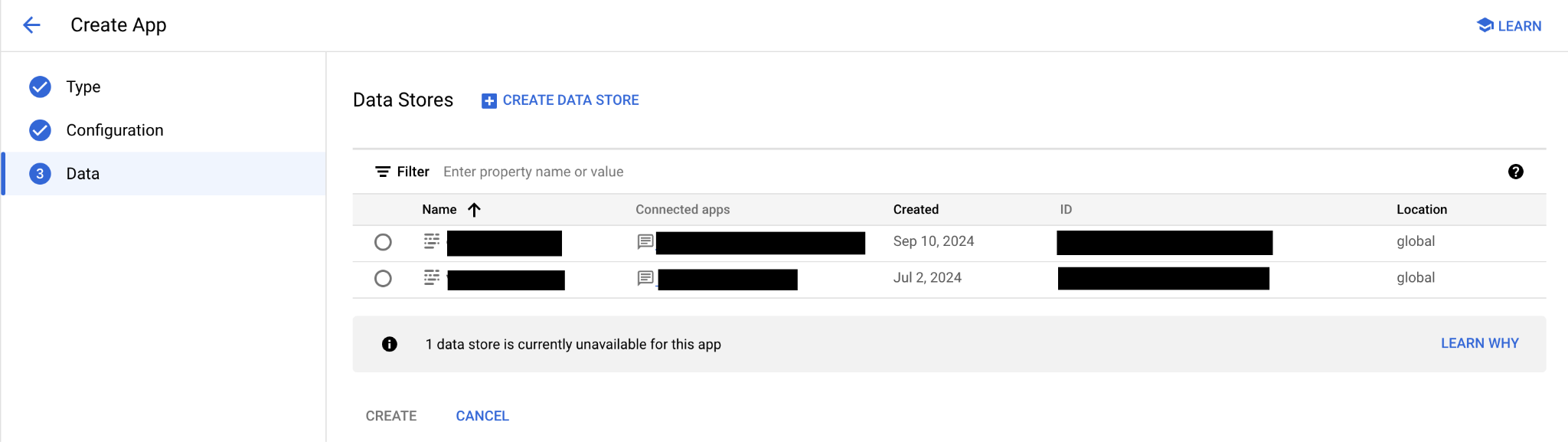
すでにSearchなどで作成しているDataStoreのうちAgentでも利用可能であればこちらに表示されます。データの置き場所としてはCloud Storageを使います。
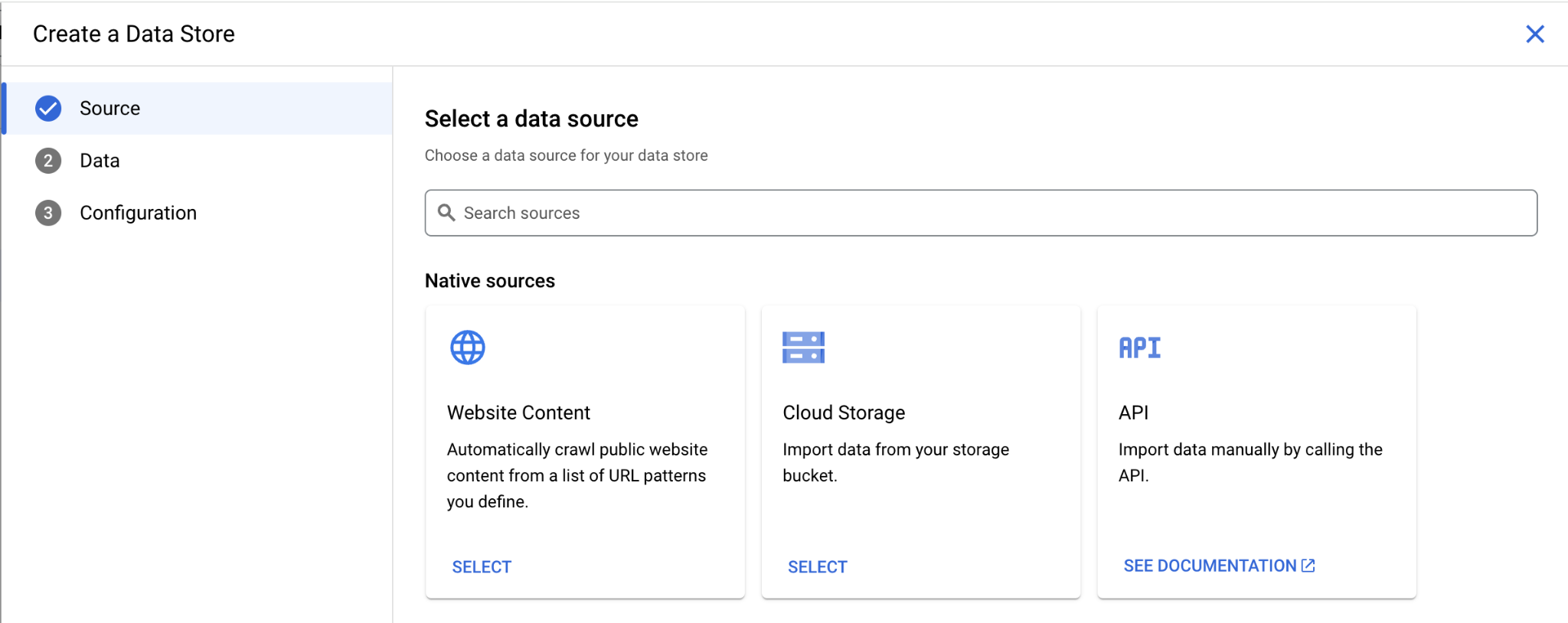
次に、どういう形式のデータを利用するかを選択します。今回はPDF、HTMLなどの非構造化データを取り込むようにしますので、Unstructured documentを選択します。
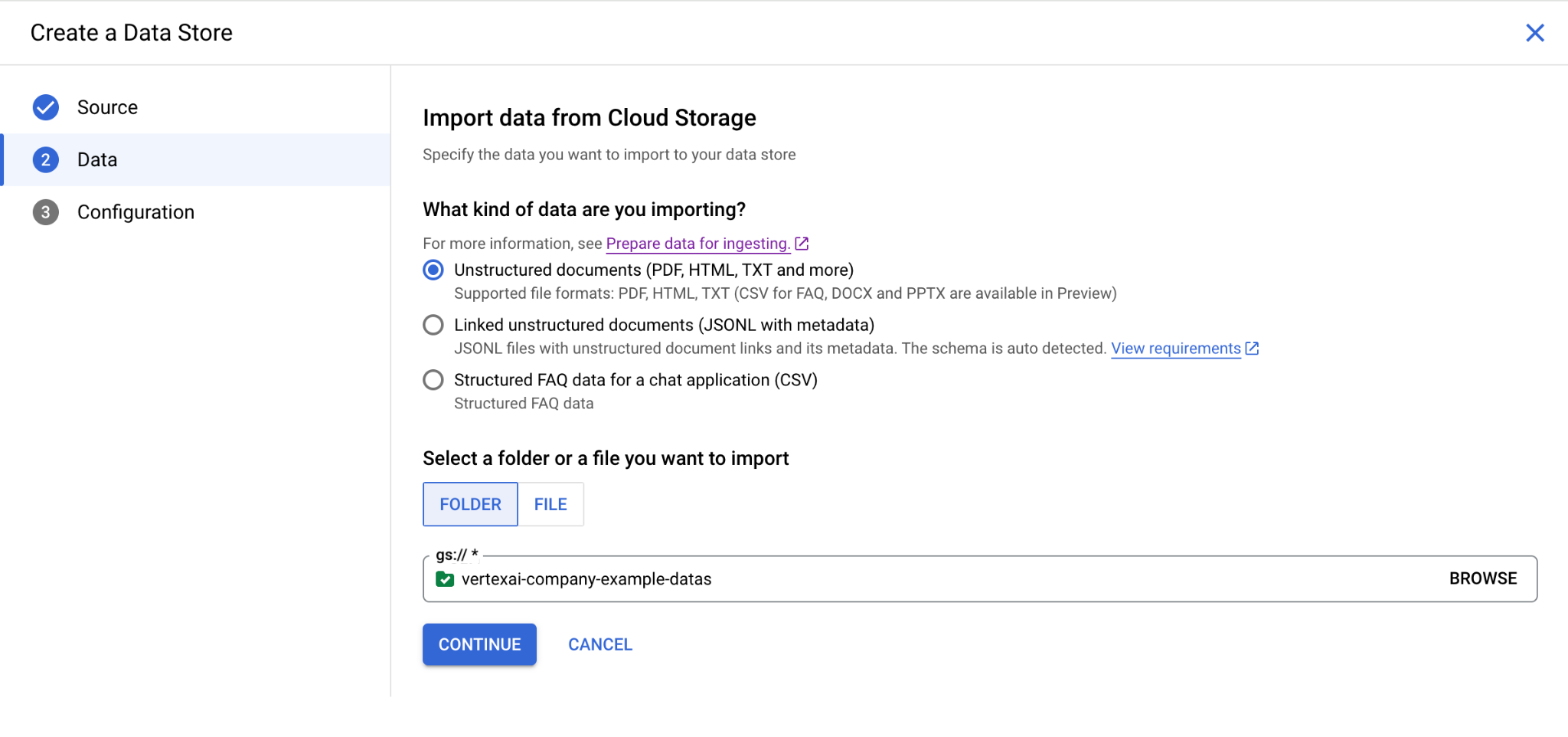
そして、データの置き場を作ります。今回は以下のようにGoogle Cloud Storageのバケットを作成します。今回はこちらのバケットに企業の情報、PDFなどが入る想定とします。
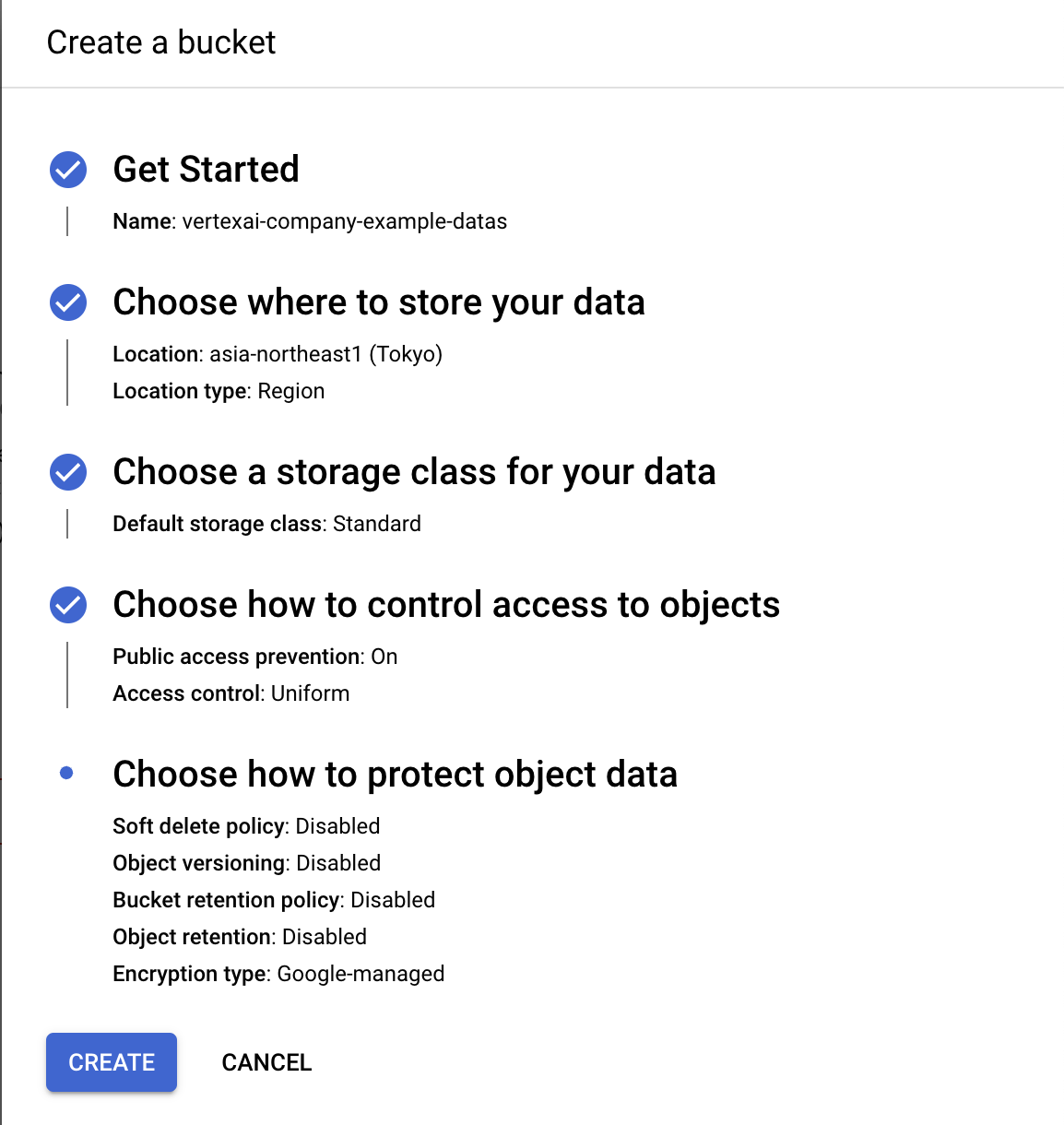
最後に、DataStore自体の名前を決め、ドキュメントのChunkの方法などを指定します。Chunk方法などはRAGのデータ取得精度のチューニングに使われます。これはとても奥が深い分野になるため今回は深く説明はしませんが、この値などを変更することで、精度の高いコンテキスト情報を取得できる可能性があります。
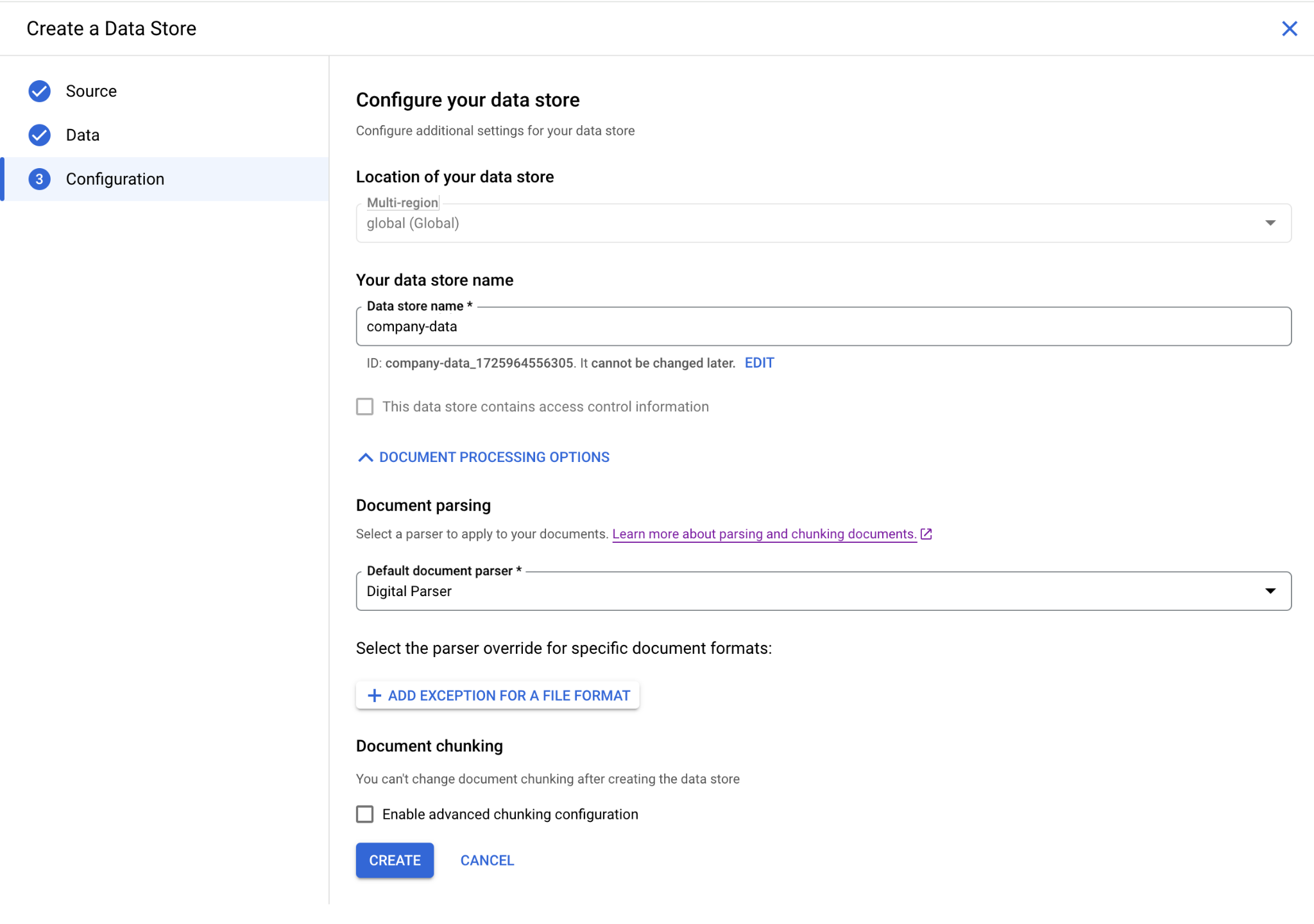
作成できると利用可能なDataStoreとして参照ができるようになります。
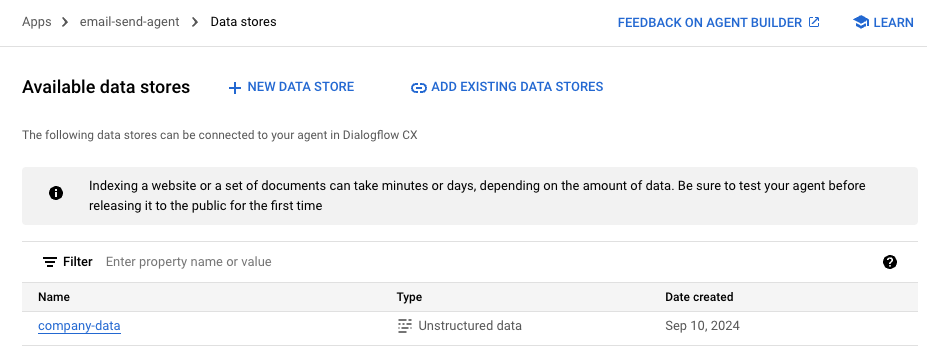
作成できると、ToolsにてDataStoreを作成編集する際に、項目が追加されます。
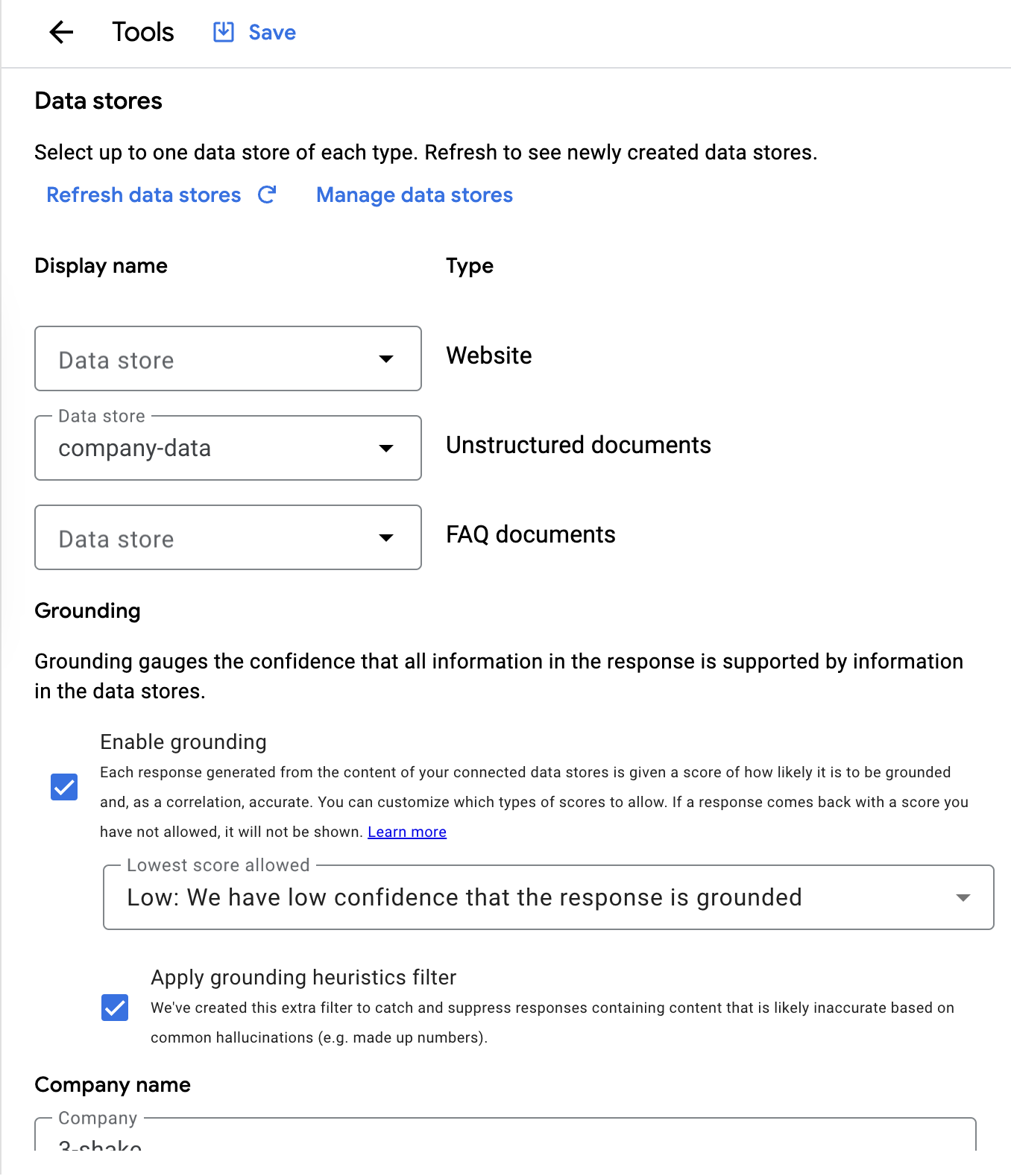
今回は以下のように設定をしていきます。
- unstructured documents
- 先ほど設定したアプリケーションを利用するようにします
- 他にwebsiteやFAQ documentを作成した場合はそれを指定します
- Enable Grounding
- 今回はLowに設定しておきます
- これは取得してきたデータが、今回の質問に対して、関係性があるのかの信頼度を持って利用するかを指定する値です
- 信頼度が低い場合そのデータは利用されません
- Company name
- こちらは基本精度を上げるために記載します
- 今回は3-shakeとしています
- Data store model selection
- gemini-1.
5-flash-002
- gemini-1.
- Summarization prompt
- ドキュメントの要約内容を変更することができますが、今回は不要なのでUse the default promptを選択します
- Payload settings
- Include snippets in response payload
(こちらはoffにして、回答に含まれないようにします)
- Include snippets in response payload
※参考:https://
実際に利用する際にはAgentのInstructionsに設定を記載していきます。前回、instructionsに対して以下を追加します。
本文は ${TOOL:company knowledge} を参考に作成してください
次に前回もやったようにExampleを追加します。今回は以下のように追加してみます。
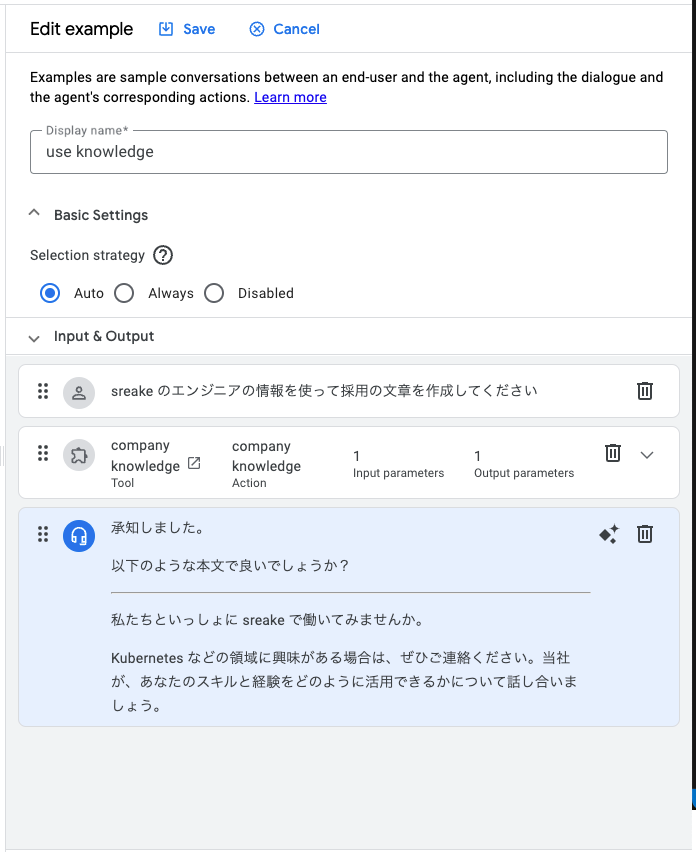
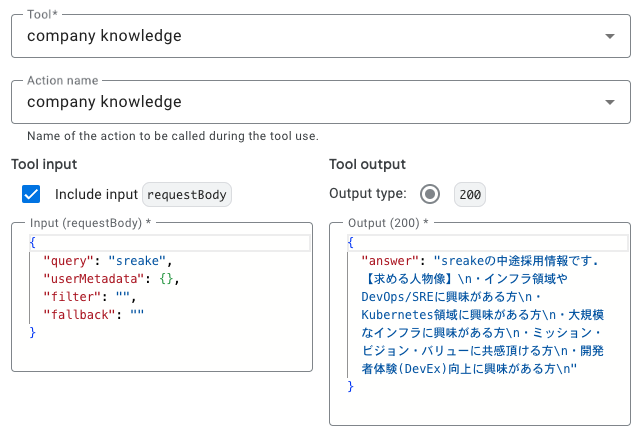
このようにExampleを入れて試すと動かすことができます。
Exampleと同じ解答ではありませんが、Datastoresを使って取得しているのが確認できると思います。
ここまでで RAG 機能を持ったアプリケーションは作成できました。
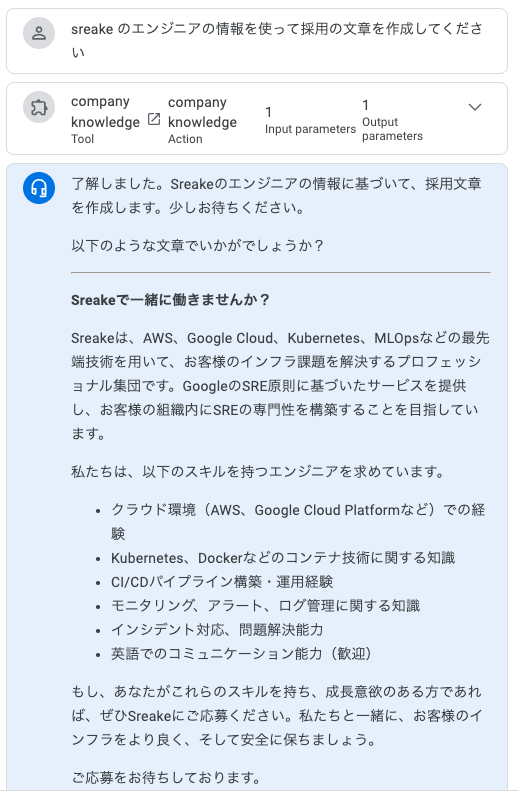
しかし、実行してみると2回に1度でエラーが起きてしまうことがわかります。
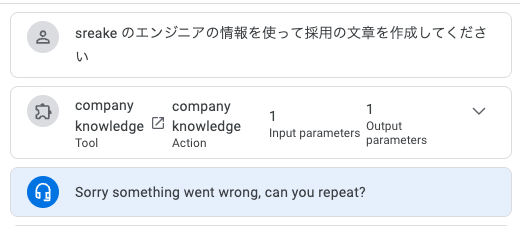
エラーの内容を見るには、後に説明するCloud LoggingとDebug Traceを使うことができます。Debug Traceは現在のプレビューの内容が見れるのでデバッグ時に、各ステップでどのような出力が行われたのか? そして、input token数などを確認する際に有用です。
今回Debug Traceを使い内容を見てみると、今回のエラーはDataStoresがsnippetsを返してエラーと言っています。とはいえ、今回ExampleやDebugで返っている値をみる限りanswerしか返していないように見えるので、 何かしらのバグがあるのかと考えられます。このあたりもどこかで修正されるのを待ちましょう。

アプリケーションのバージョン管理をする
この状態のアプリケーションをバージョンで管理してみます。
バージョン管理には現状2つ方法があります。
- Agentに対して管理する
- アプリケーション全体をGit管理する
- Exportしてローカルにファイルを管理する
1. Agent に対して管理する
以下のように、Agentに対してVersion Historyがあるので、それを使います。
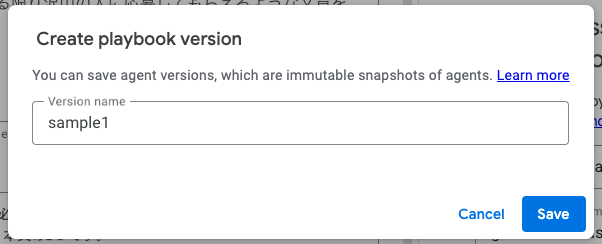
最初は何もないのでバージョンとなる名前を設定します。
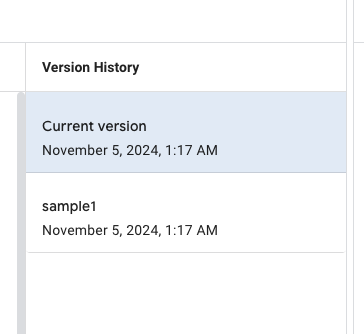
保存されると、以下のようにリストにバージョンが見えます。
これは他の方が作成したバージョンも見れるので、多人数で作成する場合は何かしら命名規則を付けることをおすすめします。
この履歴のバージョンを復元、削除するという機能はないので、できるとしたら昔の目的のプロンプトやExampleを参考にするなどのケースが考えられます。
2. アプリケーション全体をGit管理する
Agent BuilderはGitでの管理ができます。そのため、機能のロールバック、また、修正に対してPRにおけるレビューを行い、それを取り込むことができます。
この機能を使うにはGithubのレポジトリと、アクセストークンが必要になるので、まず作成する必要があります。
レポジトリは社内情報が入らないのであればpublicでもかまいませんが、基本privateで作るほうが良いでしょう。作成した後、Readme ファイルなどでも良いので、1コミットをデフォルトブランチにpushします。これをしないとAgent Builderがpushする先が見つからないというエラーを出します。
次に、アクセストークンは、GitHubのこちらの指示に従い、
- Only select repositories
- 先ほど作成したレポジトリ
- Repository permissions
- Contents: read and write
- Metadata: read
作成した後にGitの設定を行います。
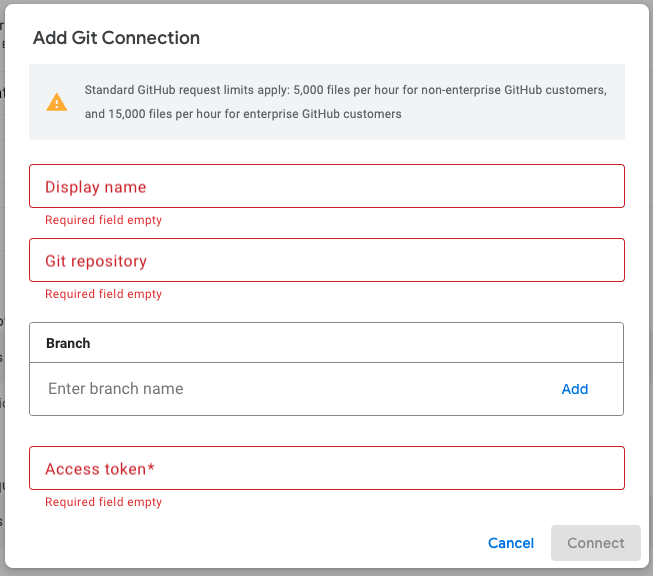
- 名前は適当な名前を付けます
- Git Repositoryのurlは https://
api. github. com/ repos/{Org}/{RepositoryName} となります - Branchはデフォルトブランチを設定しましょう。基本はmainブランチになります
- 先ほど作成したAccess tokenを設定します
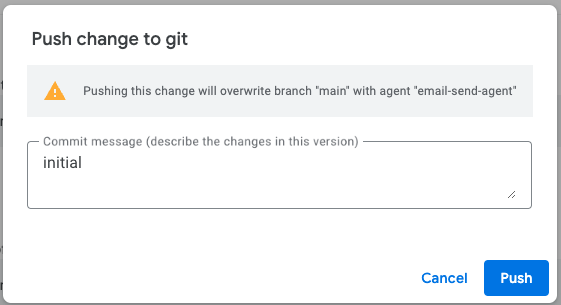
設定ができると以下のように、現状の状態のpushができるようになっています。

コミットの説明を記載して、pushを行います。
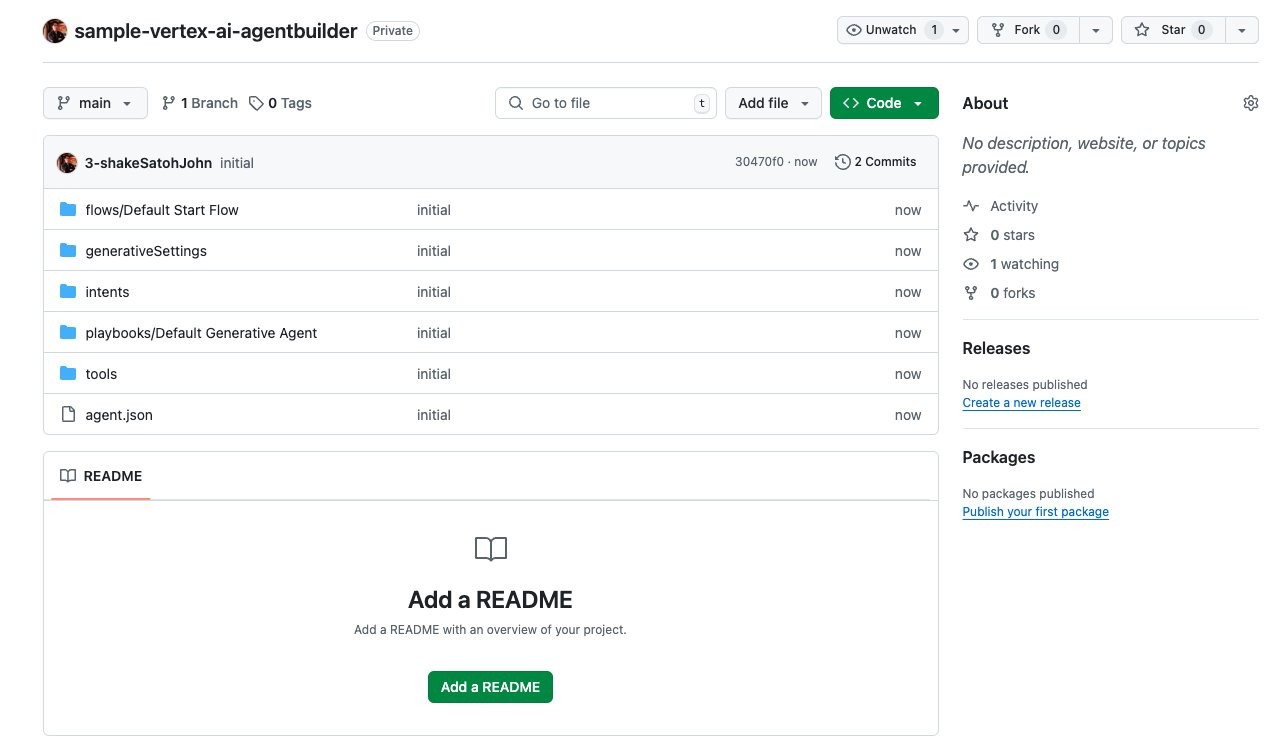
すると対象のレポジトリに push されているのが確認できると思います。
ブランチの状態を反映するにはrestoreを行います。
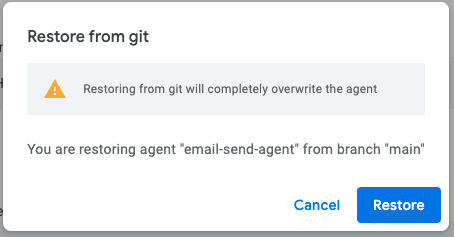
Gitを使ったAgent Builderの開発では、以下の流れが考えられると思います。
- 開発環境のAgent Builderと本番環境のAgent Builderを用意する
- 開発環境にて機能開発を行い、開発ブランチに push
- PRレビューを行いマージしたmainブランチを開発環境のAgent Builderにてrestoreし動作確認
- 問題がなければ本番環境のAgent Builderにてrestoreを行いリリース
3. Exportしてローカルにファイルを管理する
Git管理ができない場合、アプリケーションをzipでExportすることができます。
これにより、ローカルPCでバージョンを管理します。
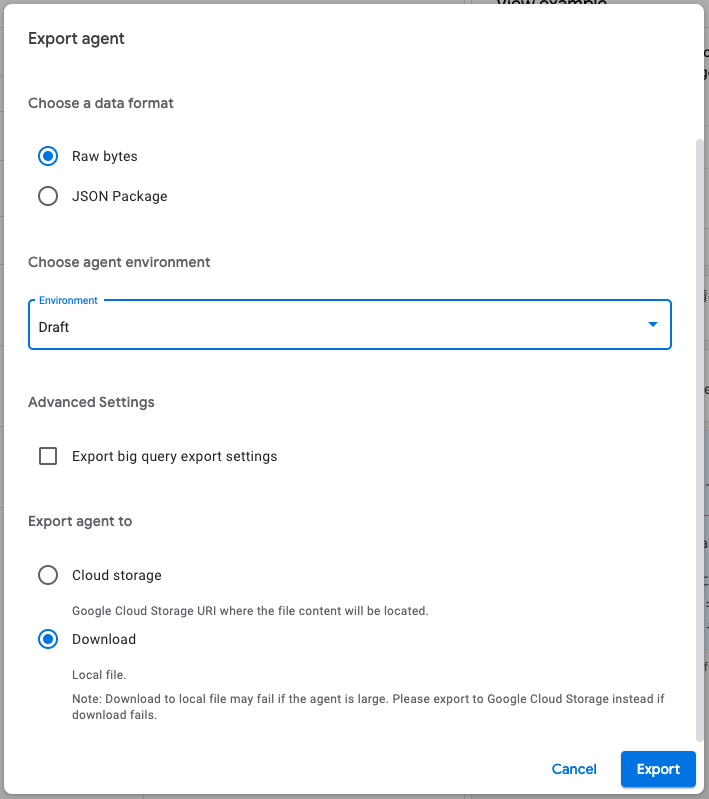
ファイルの保存先はGCSにすることも可能です。また、Restoreも可能です。
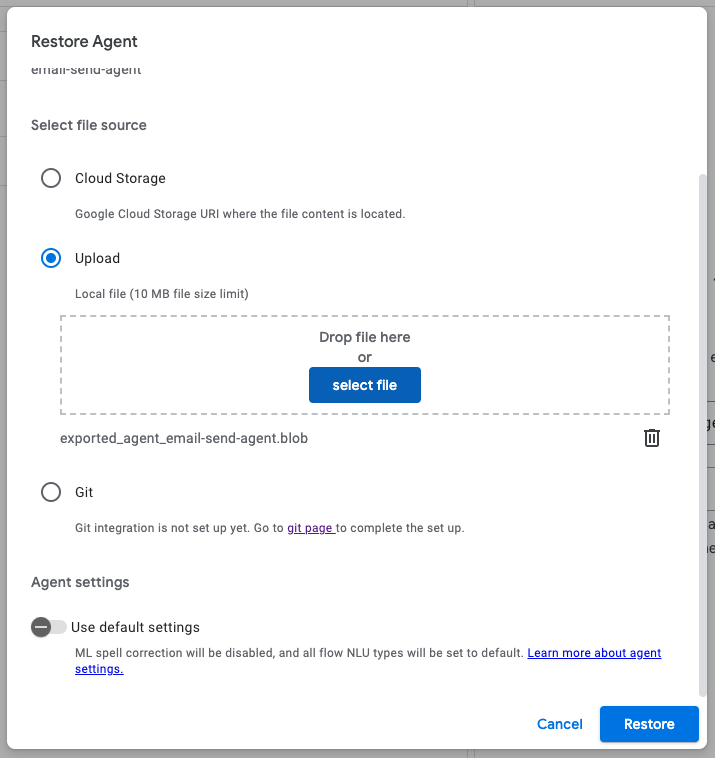
別のプロジェクトをコピーするのではなく、元バージョンに戻すなどの機能になります。2のGithubが使えない場合はこの方法を活用するのが良いかもしれません。
ログを確認する
Cloud Loggingとの連携
Cloud LoggingはGoogle Cloud上でおきたイベントや、送られてきたログを見ることができるサービスになります。
先ほど説明したものは、自身のテストにおけるデバッグ情報を確認できましたが、こちらは実際にリリースした際に、他のユーザがどのようなクエリを投げているかを確認ができます。
設定自体は、setting 上にて、Enable Cloud Loggingの設定をonにするだけです。

Cloud Logging上にて、いろいろな情報が流れますので、以下にとくに使うと思われる項目をまとめます。
| 項目名 | 説明 |
|---|---|
| jsonPayload. |
ユーザが入力した内容 |
| jsonPayload. |
Agentが返却した内容 |
| jsonPayload. |
InputのtokenやAgentの利用したtoken数などの情報。Cloud Monitoringと連携してtoken数などを図るのもよいでしょう |
| jsonPayload. |
Agent 内でどう動きが行われたのかのトレース情報。デバッグのトレース情報がこちらにでてきます |
BigQuery Export
この機能を利用するには現在Enable conversation historyをオンにしている必要があります。
こちらは基本的に先ほどの情報をBigQueryにinsertができるというものになります。Cloud Loggingに流すのが難しい場合は利用が考えられるかと思います。
ただし、Enable conversation historyをオンにする場合、Googleが収集し保存することに同意することが必要になるため、商用、社内機密情報を扱う場合などでの利用パターンでは使いにくいでしょう。
BigQueryで集計したい場合は、一例として、Cloud LoggingのデータをBigQueryへ移すのが良いかと思われます。
運用改善
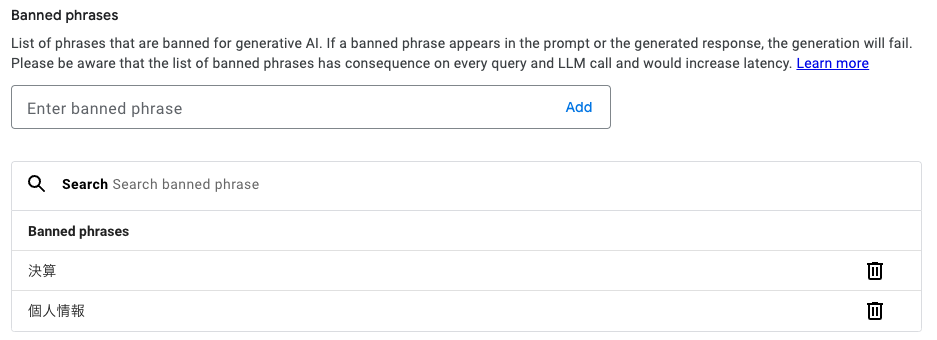
Banned phrases
ユースケース上検索、出力してほしくない文言において無効にすることができます。Banned phrasesを使うと指定したワードが生成されたテキストにある場合、生成が失敗と処理されて代わりに通常の所定のレスポンス
しかし、このリストが多すぎる場合は、LLMの呼び出しに遅延が生じる可能性があります。現状、日本語を入れて利用している限り、あまり機能はしていないように見えます。後に改善されると思われます。
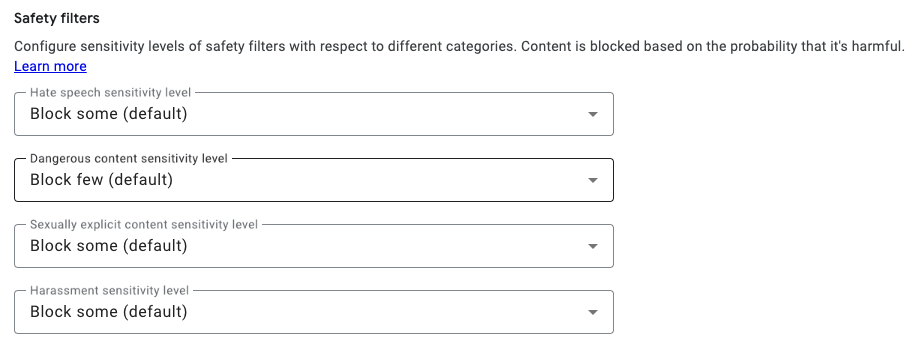
Safety filters
生成AIに以下のような項目を話させようとした場合に、レスポンスの生成に失敗させることができます。これは、Google の責任ある AI としての標準設定になります。
| Category | 説明 |
|---|---|
| ヘイトスピーチ | アイデンティティや保護された属性を標的とした、否定的または有害なコメント |
| 嫌がらせな文章 | 他の個人を標的とした脅迫、威嚇、いじめ、または虐待的なコメント |
| 露骨に性的な文章 | 性行為やその他のわいせつな内容のコメント |
| 危険なコンテンツ | 有害な商品、サービス、活動を促進したり、それらへのアクセスを可能するコメント |
Prompt Security
Agent Builderに対してジェイルブレイクなどのセキュリティ面をある程度防ぐことができます。
ジュエルブレイクとは、生成AIにユースケース以外のことを話させるようなこと、また、プロンプトで制御している制約やルールを回避する手法のことです。この設定をしておくと、意図しない使い方をある程度抑えることができます。

まとめ
ここまでで、Agent Builderを実際に運用にまでするまでの機能についてまとめました。
2024年12月23日現在、まだPreviewなサービスでもあるので不安定な動きをすることもありますが、GUI上で社内コンテキストを利用したRAGアプリケーションの作成について説明をさせていただきました。こちらにより、非エンジニアであっても、社内アプリケーション作ることができるのが見えてきたかと思います。
そして、そのアプリケーションの運用におけるバージョン管理、ログの確認方法、プロンプトセキュリティについて説明をさせていただきました。これらの機能を利用することで、Agent Builderの開発時におけるDebugを楽にしつつ、アプリケーションの品質を高めることができます。
何度も説明をさせていただいておりますがPreviewであり、ご利用時期にはガラッとUIが変わっている可能性があります。その点にだけ気をつけてAgent Builderを使ってみてください。