



あけましておめでとうございます。筒井
Python in Excelは2024年10月に一般提供を開始しました[1]。Excelを持っている人であれば、特に設定を変更することなく使えます。本記事を参考にPython in Excelを使いこなしていただければ幸いです。
Python in Excelとは
Python in Excelとは、ExcelブックのセルにPythonコードを埋め込める機能です。筆者の経験上、VBAをPythonで書ける機能と誤解している人をときどき見かけたことがありますが、全く別物の機能なので注意してください。
Python in Excelの基本的な使い方については、2024年2月5日のPython Monthly Topicsで紹介しています。詳細は以下の記事を参照してください。
上記の記事はPython in Excelが一般提供される前に書かれたものですが、現在でも使い方に変わりはありません。ただし、導入方法は不要な手順になりました。
なお、Python in Excelは本記事執筆時点ではWindows版Excel
Python in Excelの実践プラクティス
ここでは、Python in Excelを使う際の実践プラクティスを紹介します。
元のデータはPython以外を使って加工しない
以下のExcelブックは、Pythonチュートリアルイベント
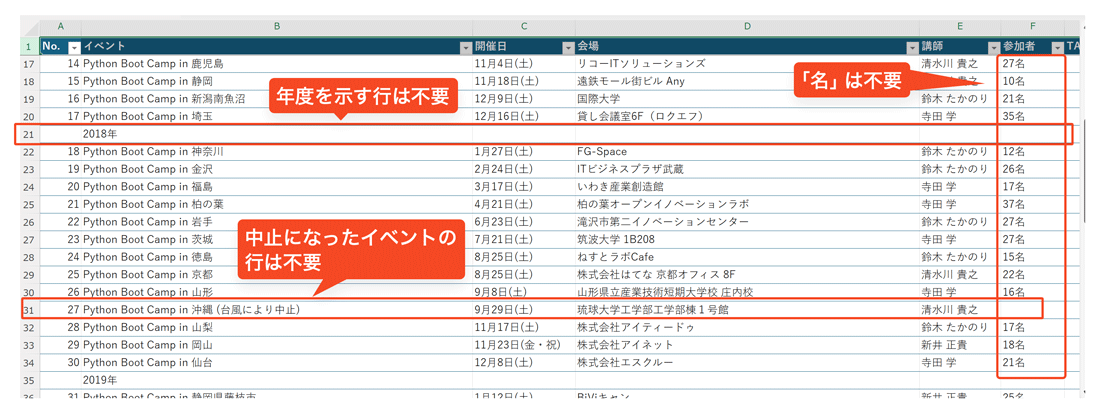
これをPython in Excelで扱う際、不要なデータがいくつか含まれています。たとえば、各イベントの参加者数の推移をグラフにする際は、以下のデータは不要です。
- 「2018年」、
「2019年」 など年度を示す行 - 中止になったイベントの行
- 「参加者」
の数字の末尾にある 「名」
これらを削除するために、Excelシートを直接編集することもできますが、それは極力避けたほうがよいです。なぜなら、直接編集することで、別の目的で統計処理を行うのが難しくなる場合があるからです。たとえば、年度を表す行を削除してしまうと、年度を軸にした統計処理ができなくなります。また、Power Queryで取り込んだデータの場合は、データを更新するたびに手作業で編集する必要があるため、非効率です。
Python in Excelを使う場合は、元のデータをそのまま取り込み、Pythonで加工することをおすすめします。上記の例の場合は、以下のようなPythonコードを書くことで、不要なデータを削除できます。なお、以下のコードはExcelシート上のテーブルに
# データの読み込み
# xl()関数の第1引数でテーブル名を、第2引数でテーブルのヘッダーを除いて取得するかを指定
df = xl("PyCamp開催実績[#すべて]", headers=True)
# 採番されていない行(年度を表す行)を除去
# df["No."]は「No.」列の値を取得
filtered_df = df[pd.to_numeric(df["No."], errors="coerce").notnull()]
# イベントが中止になった行を除去
filtered_df = filtered_df[~filtered_df["イベント"].str.contains("中止")]
# 参加者の「名」を除去して数値に変換
filtered_df["参加者"] = filtered_df["参加者"].str.replace("名", "")
filtered_df["参加者"] = filtered_df["参加者"].astype(int)
filtered_変数はPandasのDataFrameオブジェクトです。これを使って、seabornなどを使ってグラフを作成することができます。具体的な方法については、2024年2月の記事の
コードは複数のセルに分割して書く
プログラミングをする際、コードを人間が読みやすい範囲に分割することはよく行われます。分割することで、コードを読む人は自分が知りたい部分だけにフォーカスできるようになります。Python in Excelでも同様に、コードを複数のセルに分割して書くことをおすすめします。
例として、横浜市のオープンデータから日常生活圏域等別データ
以下のコードを見てください。すべての処理を1つのセルにまとめて書いています。
# データの読み込み
df = xl("日常生活圏域等別データ[#すべて]", headers=True)
# 鶴見区のデータのみ抽出
tsurumi_df = df[df["区名称"] == "鶴見区"]
# 年齢の内訳を取得
age_groups = {
"14歳以下": tsurumi_df["人口_14歳以下"].sum(),
"15-64歳": tsurumi_df["人口_15_64歳"].sum(),
"65歳以上": tsurumi_df["人口_65歳以上"].sum(),
}
# 円グラフの描画
# 日本語フォントを指定(これが必要な理由は後述)
plt.rcParams["font.family"] = "Meiryo"
plt.figure(figsize=(8, 8))
plt.pie(
age_groups.values(),
labels=age_groups.keys(),
autopct="%1.1f%%",
startangle=90,
counterclock=False,
)
plt.title("鶴見区の年齢内訳(人口割合)")
plt.show()
上記のコードを=PY()Excel関数で実行し、セルを右クリックしてメニューの
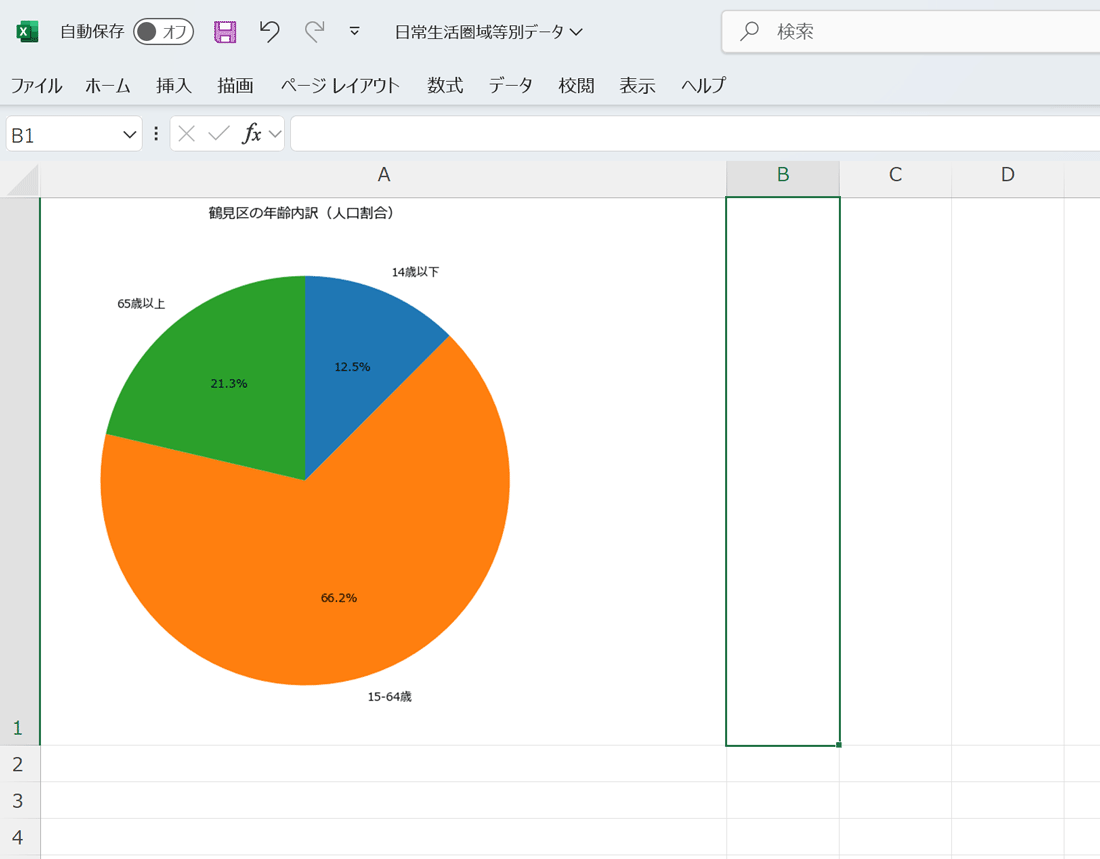
これでも意図通りのグラフは表示されていますが、すべての処理を1つのセルにまとめる書き方には、以下の問題があります。
- 長いコードだと自分が読みたいコードだけにフォーカスしにくい
(毎回先頭から読む必要がある) - 共通のロジックを再利用しにくい
(他の区の年齢内訳を取得する場合、ほぼ同じコードを書く必要がある) - コードの途中の変数の内容を確認しにくい
(Python in Excelでは breakpoint()関数を使ったデバッグはできない)
次に、上記の改善例をお見せします。以下では、前述のコードを複数のセルに分割して書いています。

この書き方により、前述の問題1~3を解決できます。以下で詳しく説明します。
問題1.「長いコードだと自分が読みたいコードだけにフォーカスしにくい」をどう解決するか
1.については、コードを意味がある単位に分割することで、自分が読みたいコードを他と切り離して読むことができます。前述の改善例では、コードを以下に分割しています。
- データの読み込み
- 鶴見区のデータのみ抽出
- 年齢の内訳を取得
- 円グラフの描画
コードを読む人は、上記の中から自分が知りたい部分の処理内容を見つければ、他の部分を読む必要がありません。
なお、この例ではExcelブックを開いたときに全体の処理内容を把握しにくいという問題がありますが、後述の
問題2.「共通のロジックを再利用しにくい」をどう解決するか
2.について具体例を挙げます。コード例
以下の部分を関数化することで、ロジックを再利用できそうです。
# データの読み込み
df = xl("日常生活圏域等別データ[#すべて]", headers=True)
# 鶴見区のデータのみ抽出
tsurumi_df = df[df["区名称"] == "鶴見区"]
# 年齢の内訳を取得
age_groups = {
"14歳以下": tsurumi_df["人口_14歳以下"].sum(),
"15-64歳": tsurumi_df["人口_15_64歳"].sum(),
"65歳以上": tsurumi_df["人口_65歳以上"].sum(),
}
# 円グラフの描画
# 日本語フォントを指定(これが必要な理由は後述)
plt.rcParams["font.family"] = "Meiryo"
plt.figure(figsize=(8, 8))
plt.pie(
age_groups.values(),
labels=age_groups.keys(),
autopct="%1.1f%%",
startangle=90,
counterclock=False,
)
plt.title("鶴見区の年齢内訳(人口割合)")
plt.show()
以下では、上記のコードを関数化しています。
def get_age_groups(df, ward_name):
"""ある区の年齢の内訳を取得する"""
ward_df = df[df["区名称"] == ward_name]
return {
"14歳以下": ward_df["人口_14歳以下"].sum(),
"15-64歳": ward_df["人口_15_64歳"].sum(),
"65歳以上": ward_df["人口_65歳以上"].sum(),
}
上記の関数を独立したセルに書いておいて、別のセルでage_と書けば、鶴見区の年齢内訳を取得できます。"鶴見区"の部分を変えるだけで、他の区の年齢内訳も取得できます。
問題3.「コードの途中の変数の内容を確認しにくい」をどう解決するか
3.に挙げたデバッグのやり方について説明します。Python in Excelでは最後の行に書いた値がセルに表示されます。そのため、内容を確認したい変数を最後の行に書いておくと、値の確認ができます。
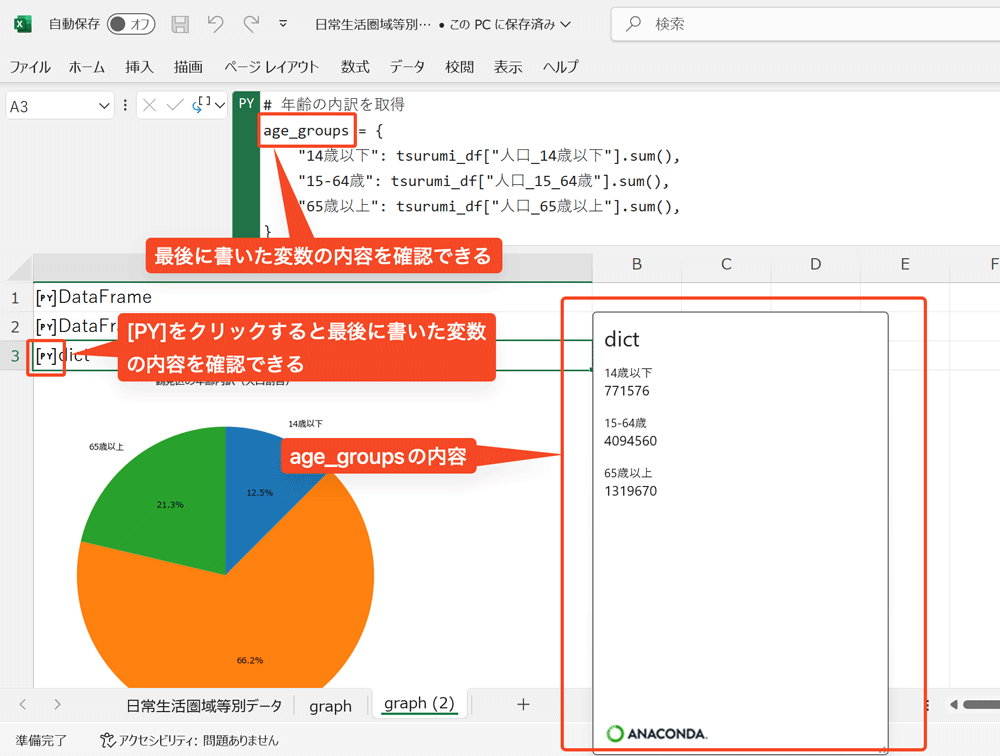
Jupyter Notebookを使っている人であれば、セルごとに実行結果を確認することがよくあるかと思いますが、それに近いやり方といえばイメージしやすいかもしれません。
セルの実行順序を把握する
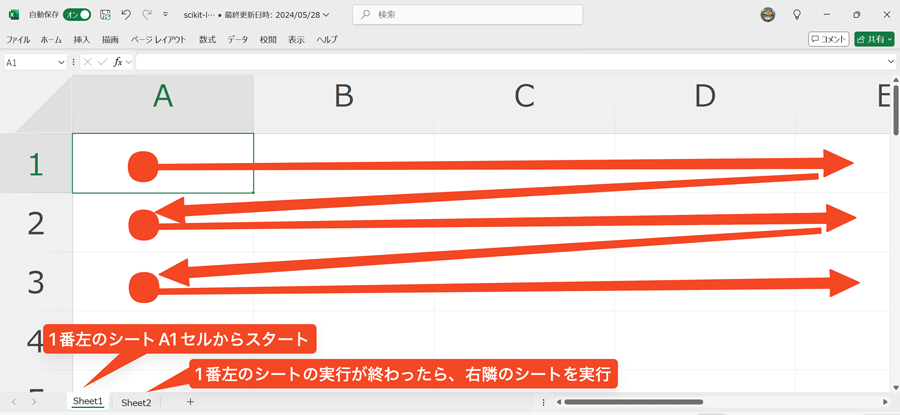
コードを複数のセルに分割して書く際に覚えておいてほしいのは、セルの実行順序です。Python in Excelで定義された変数や関数は、Excelブック全体でグローバルなスコープです。そのため、どの順番でコードが実行されるかを把握しておかないと、未定義の変数や関数を呼び出してしまい、NameErrorが発生することがあります。
Python in Excelでは、以下の順序でコードが実行されます。
- 1番左のシートのA1セル
(一番左上のセル) から右方向に1番右端まで実行 - 1番下の行まで上記と同様に実行
- 右隣のシートから最後のシートまで1.〜2.と同様に実行
図にすると、以下の順番でコードが実行されます。
各セルに「文字列リテラルのコメント」を書く
Python in Excelでも通常のPythonと同様にコメントを書くことができますが、より読みやすくするためには独特のテクニックがあります。
以下の例を見てください。複数のセルにコードを書き、それぞれのセルの内容を#でコメントしています。
#でコメントを書いた例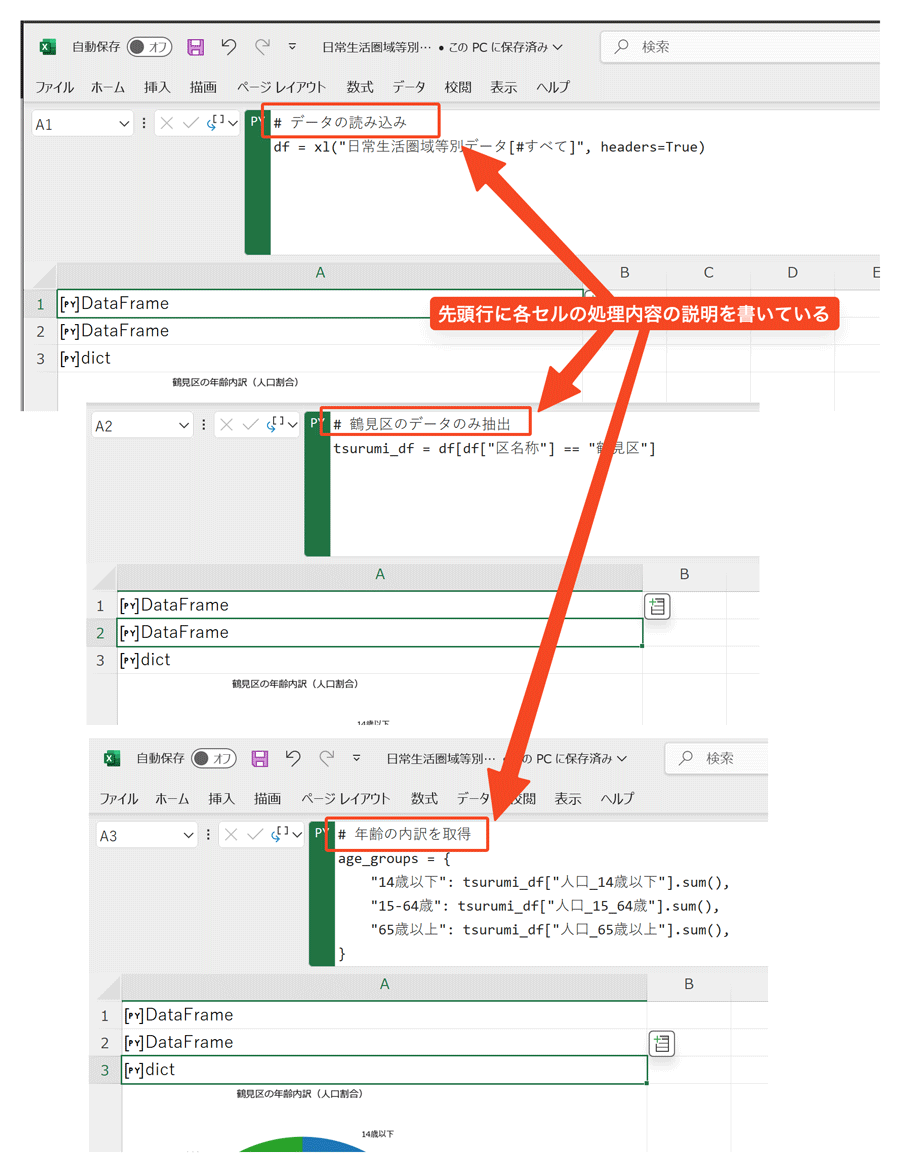
#でコメントを書くのはPythonの文法的には正しいのですが、Excelブックを開いたときにコメントが表示されず、[PY]DataFrameのようにPythonのオブジェクト名が表示されています。これでは、全体の処理の概要を把握するには、各セルをクリックしてコードの内容を確認する必要があり、少々手間がかかります。
#でコメントを書いた場合の表示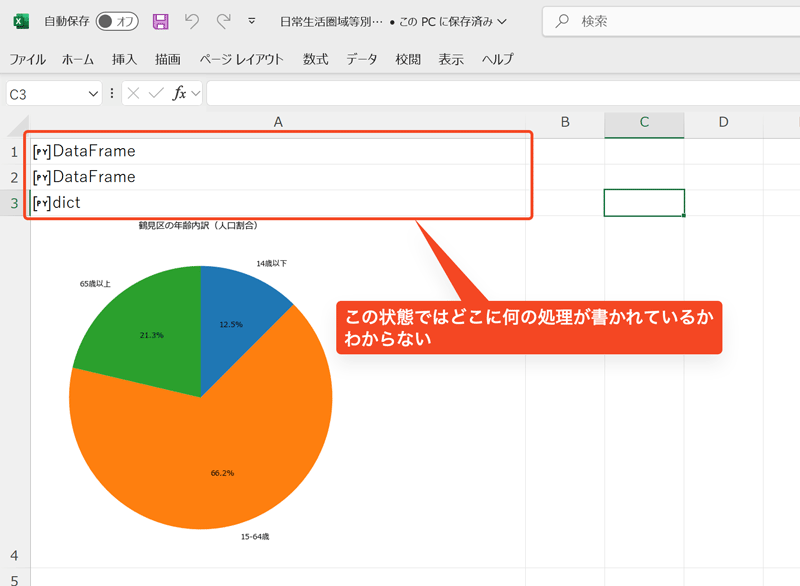
こんなときは、
df = xl("日常生活圏域等別データ[#すべて]", headers=True)
"データの読み込み"
「コードを複数のセルに分割して書く」
以下の例を見てください。各セルに
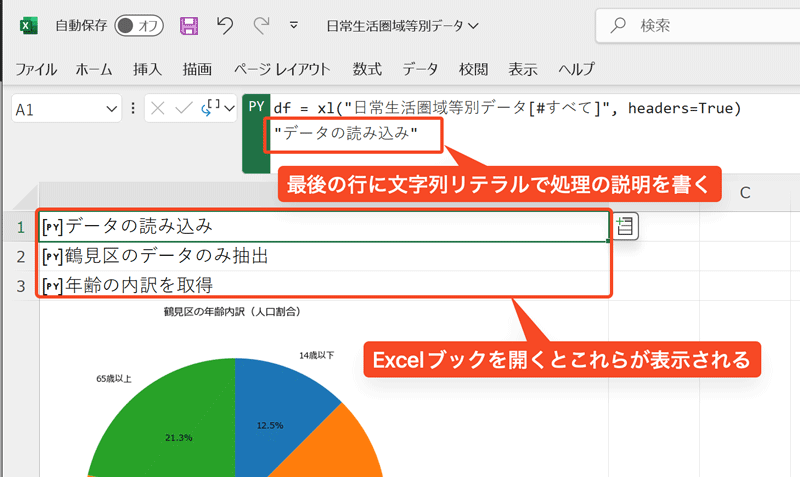
ただし、この方法を採用すると、最後の行に書いた変数の内容を確認することができなくなるため、デバッグの際は#でコメントアウトするなどの工夫が必要です。デバッグのしやすさと比較して、
グラフの描画時に日本語フォントを指定する
Python in Excelでグラフを描画する際、表示する文言が日本語だと文字化けが起こります。これを防ぐため、日本語フォントを指定するコードを書く必要があります。
フォントの指定方法は使うコアライブラリによって異なりますが、よく使われるものをいくつか紹介します。seabornを使う場合は以下のように書きます。
sns.set(font="Meiryo") # 日本語フォントを指定
matplotlibを使う場合は以下のように書きます。
plt.rcParams["font.family"] = "Meiryo" # 日本語フォントを指定
参考資料
Python in Excelを学ぶ上で役立つ参考資料を以下に挙げます。
最後に
今回はPython in Excelを使う際に便利なプラクティスを紹介しました。Python in Excelは一般提供されたため、より気軽に使えるようになりました。ぜひこの機会に、Python in Excelを使いこなしてください。