



皆さんこんにちは。スリーシェイク代表の吉田です。
前回から少し間が空いてしまいましたが、今回は製造業で生成AIがすでにどう活用されているか、また課題や解決策について、前提となるルールや実現に必要なアーキテクチャを解説していきます。
個人的な感覚ですが、製造業における生成AIの活用は他業界よりも一歩進んでいる印象があります。慢性的な人手不足に対して生成AIがどんなアプローチを取れるのか、またそれはどういうアーキテクチャで実現できるのか、解説をしてみます。
製造業と生成AIの相性の良さ
生成AIはMLやDeep Learningに比べて自然言語処理能力とマルチモーダル処理、汎用性が非常に高い点が特徴です。製造の現場は必ずしも同じレベルの専門知識や経験を有する集団はないので、相手に合わせて的確な自然言語で情報を伝達することができるのはとても重要です。
また、精度/推論速度では既存手法には敵いませんが、製造現場の状況が変化するごとに、モデル再構築する手間を考えると、汎用的な生成AIをベースとしたアーキテクチャもコストパフォーマンスが良い構成だと言えます。
また非ITエンジニアである製造現場主導によるソフトウェア開発、
同様に工場内の制御装置に使われるPLC
実際に製造業では生成AIはどう活用されているか
生成AIを活用した社内エンジン
株式会社日本製鋼所はAmazon BedrockとAmazon Kendraを活用して、製品情報や過去の技術文書を効率的に検索し、生成AIが自然言語で回答を生成することで、技術サポートの質と効率を向上させました。
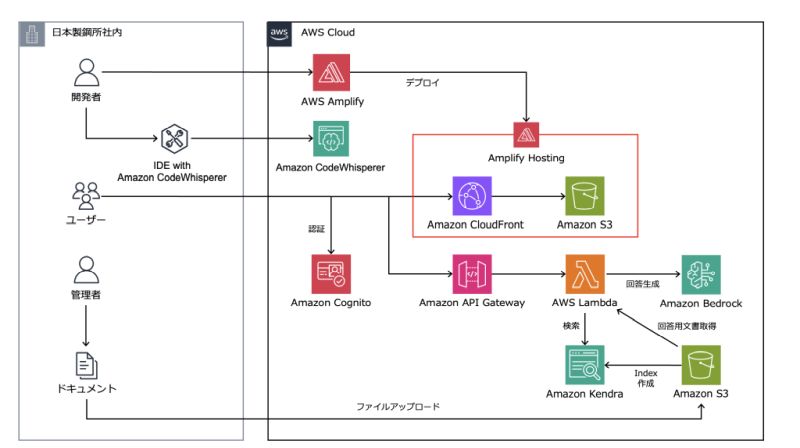
このアーキテクチャで特徴的なのは、Amazon Kendraで検索した情報を下にAmazon S3から元の文章ファイルを取り出してAmazon Bedrockに渡している点です。
Amazon KendraのQuery APIやRetrieve APIは、検索内容に関連するテキストの抜粋、もしくは関連性の高いパッセージを最大100個返すわけですが、必要な情報が散在している場合は、断片的な抜粋情報もしくは不完全なパッセージ郡をベースにAmazon Bedrockが回答を生成しなくてはいけませんので、回答精度が落ちる可能性があります。
そこで検索に連動して元文章ファイルを渡す工夫をすることで、膨大な文章があり、また製品固有の専門用語や略語などのドメイン知識が求められる中で回答精度を向上させています。
生成AIによるコード生成支援
日本特殊陶業株式会社は、Google BigQueryを中心とした統合データ基盤があり、SQLを用いて分析業務を行っていました。ここで、Data Catalogに保存されたメタデータをベースに生成AIを用いることで適切なSQLを自動で生成することが可能になり、高度な分析業務を幅広いチームで行うことが可能になりました。
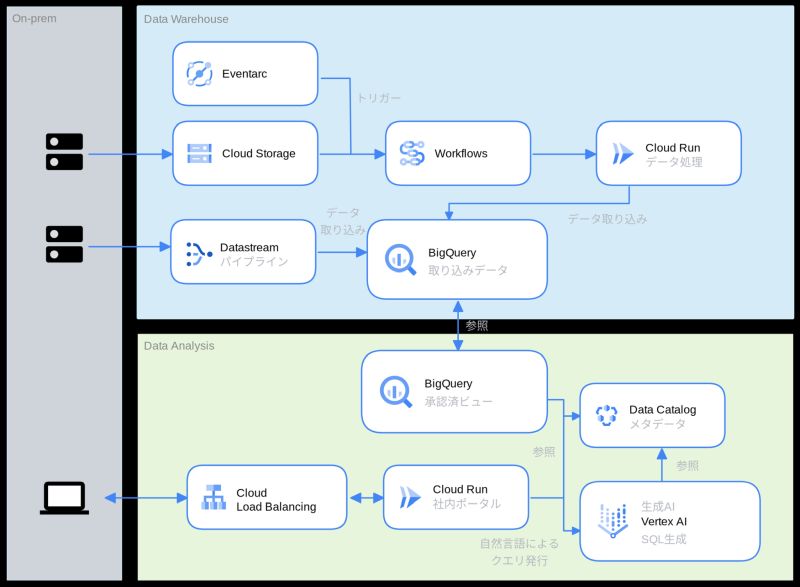
このアーキテクチャの特徴的なのは、分析のベースとして
そこで、Data Catalogでメタデータを管理しながら、生成AIを用いることでより精度の高いSQLを生成し、エンジニアの育成にもつながる仕組みになっています。
これからの可能性
まだ事例はないですが、これから近い将来事例が出てきそうな内容をいくつか挙げます。
予知保全
製造現場での機械故障予知は昔からニーズのある領域です。
既存のIoT製品向け機械学習モデルやアプリケーションでは以下の課題をよく耳にします
- 対象機器に対して学習するデータが足りず精度が出せない
(作れない) - 故障予知や部品交換の通知が来ても、そこからは人を介することになる。つまり通知を受け取っても、受け取る人の能力によってはどうしたらいいかわからず、結局熟練者に頼り切りになってしまう
とくに2に関して、生成AIを間に入れて、分析結果や通知を元にどうしたらいいのか?
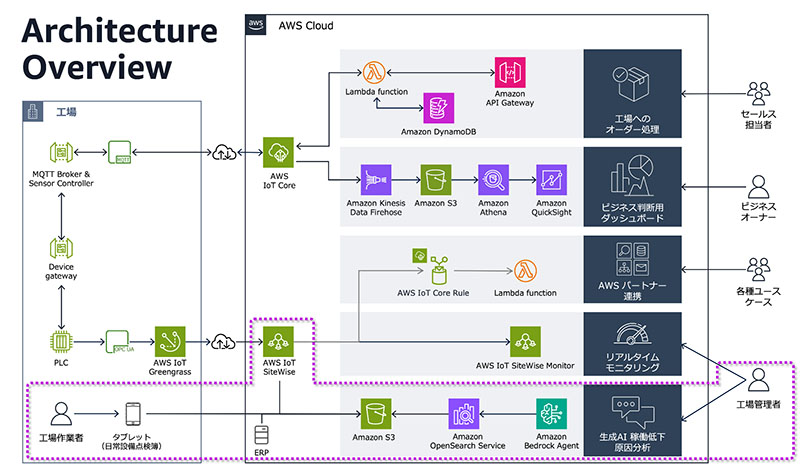
PLCを経由して取得したデータをAWS IoT SiteWiseを用いて簡易解析し、それをベースにAmazon Bedrock経由でより工場管理者や作業者が理解しやすい言葉で解説、指示書の作成をする内容です。記事では工場の稼働率低下の原因分析をメインとしていますが、プロンプト次第で、予知保全に流用は可能です。
また前段でご紹介したAmazon Kendra
技能継承
前段でご紹介したアーキテクチャは、前提として過去の対応マニュアルや文章が十分にある状況ですと有用ですが、そもそも熟練者が暗黙知として保有している対応を言語化するところから始めないといけない現場は数多くあります。
そこで、Amazon Bedrock が過去のデータや膨大な資料から効率的に解決策を推測しつつも、熟練者がリモートから映像や音声を通じて若手対応者を支援し、その内容を更に次の知見として、保存していくアーキテクチャが以下となります。
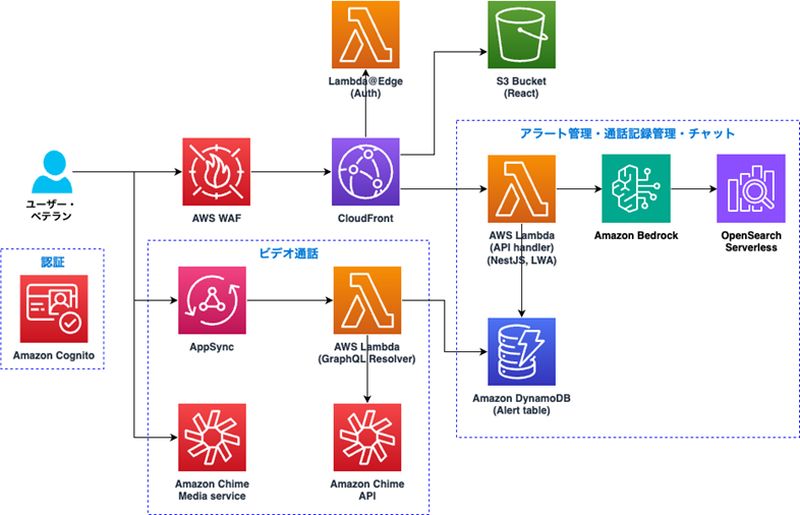
このアーキテクチャはAmazon Bedrockを介したチャット形式のコミュニケーションだけでなく、Amazon Chimeを通じてリアルタイムでビデオ通話をしつつ、通話後、内容をAmazon Transcribeが文字起こしし、それをAmazon Bedrockが要約し、DynamoDBやS3に保存する内容になっています。
Amazon Chimeは2026年2月に廃止されますので、Amazon Wickrに置き換える必要があります。またGoogle MeetもアーティファクトAPIを利用すれば、同様のことは可能ですので、普段Google Workspaceを利用するユーザも熟練者の知見を生成AIで言語化していくことは可能ではないでしょうか。
機械学習ベースの画像認識精度の向上
少し毛色が異なりますが、BMW GroupのSORDI.
生成AI自身が、既存の機械学習のモデル開発を大幅に効率化し、少ないデータセットでも生AIを用いて精度向上していこうという取組は、今後流行りそうな気がします。いわゆる、デジタルツインですかね。
生産ラインの最適化
多くの製造業において、製品のライフサイクル管理
以下はデジタルスレッドをAWSで構築するアーキテクチャの例となります。
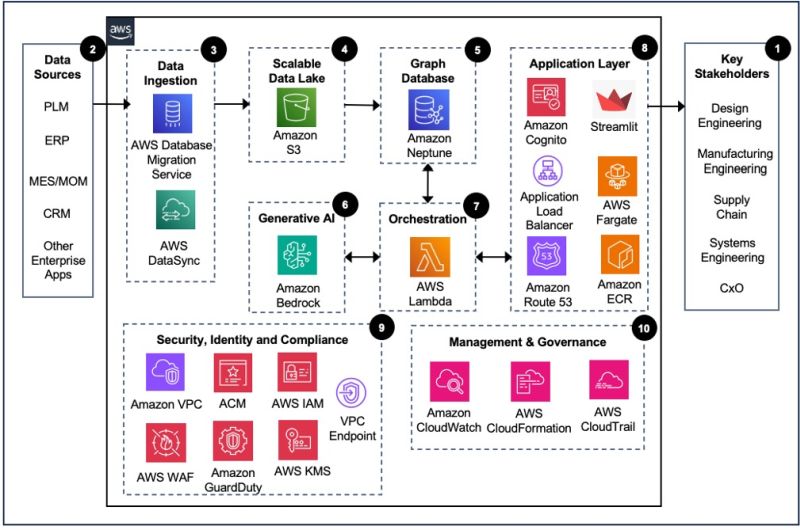
このアーキテクチャで重要なのは、各システムから取れるデータはそもそも目的も利用ユーザも異なるものなので、それらの関連をAmazon Neptuneでグラフデータベースをつくり、それをGraphRAGとしてAmazon Bedrockが利用する点です。コンテキストもデータ形式も全く異なるシステムからデータを収集していくなかで、ナレッジグラフを生成することで、より多面的な観点で文章を生成することが可能になります
最後にいかがでしょうか。製造業における生成AIの活用例は他業界に比べても一歩進んでおり、中でもAWSでの事例やリファレンスアーキテクチャは豊富だなという印象です。このあたりはGoogle CloudやAzureでの事例も今後増えていくといいですね。
また国内事例はどちらかというと、人手不足に起因する実用的な課題解決に焦点があたっていますが、海外はデジタルツインや工場のレイアウト最適化など、スマートファクトリーに向けた内容が比較的多いですね。
ぜひ本記事で紹介した事例やアーキテクチャを参考に、自社の課題に合わせた生成AI活用の検討を進めてみてください。