


Alibabaは2025年7月23日、同社が開発するLLM
🚀 We’re excited to introduce Qwen3-235B-A22B-Thinking-2507 — our most advanced reasoning model yet!
— Qwen (@Alibaba_Qwen) July 25, 2025
Over the past 3 months, we’ve significantly scaled and enhanced the thinking capability of Qwen3, achieving:
✅ Improved performance in logical reasoning, math, science & coding… pic.twitter. com/ vO6UHlW7pf
Qwen3-235B-A22B-Thinking-2507は、同社が3ヵ月間にわたってQwen3-235B-A22Bの思考能力を大幅に拡張し、推論の質と深さの両方を向上させたモデル。256KBのネイティブコンテキスト長により、深く長い形式の理解が可能となり、論理的推論、数学、科学、コーディング、そして通常は人間の専門知識を必要とする学術ベンチマークを含む推論タスクにおいて、パフォーマンスが大幅に向上した。
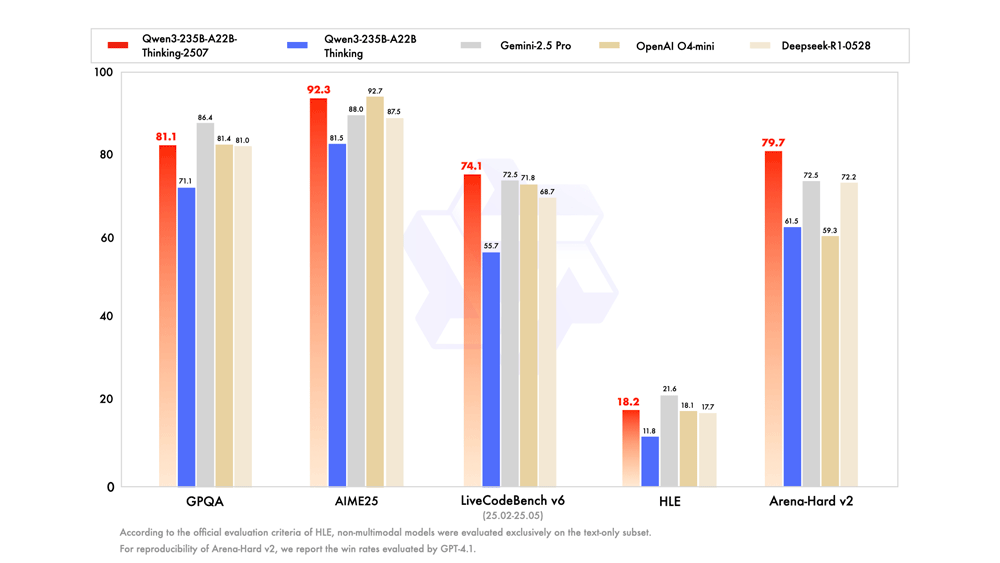
なお、このモデルは
Qwen3-235B-A22B-Thinking-2507では、新たな強化学習アルゴリズムとして
Qwen3-235B-A22B-Thinking-2507はHuggeing Face等で公開されているほか、APIドキュメントも同社のドキュメントページで公開されている。