



前回は、LangChain4jを使ってAIチャットを作りました。ここまでは、与えたプロンプトだけからLLMが返答を生成していました。しかし、そうするとLLMがすでに持っている知識からしか返答を生成することができません。
LLMはリリースの数か月前までの知識で学習しているので、それ以降の情報について答えることができません。現在の天気や時刻を答えることができないわけです。また、公開されていない情報や個人のブログのような注目度の低い情報など、LLMが学習しにくい情報に関する返答もできません。
そこで、LLMが必要に応じて処理を呼び出したり検索を行ったり外部から情報を取り込んで、その情報を元に返答を生成することで、最新情報や天気など動的な情報を踏まえた返答ができるようになります。このように外部から取り込んだ情報を元に返答を生成することをRAG
処理を呼び出して動的な情報を取り込む場合には、Function CallingやTool useという仕組みを使います。どちらも同じ仕組みを指しますが、OpenAIやGoogleではFunction Calling、AnthoropicやAmazonではTool useと呼んでいます。この記事では以降Function Callingと呼びます。Function CallingもRAGの一種と言えますが、単にRAGと言った場合にはデータベースやファイルなど静的な情報を取り込むことを主に指します。
今回は、Function CallingとRAGを実装して外部情報を利用したチャットを作成します。
なお、この記事で取り扱ったコードはこちらからダウンロードできます。
AiServices
Function CallingやRAGでは、LLMの返答の解析やプロンプトの加工など、いろいろな処理が必要になります。また、前回のAIチャットでもChatMemoryの管理のコードが必要になっていました。
こういった定型処理をまとめる仕組みとしてLangChain4jでは、AiServicesを持っています。まずはAiServicesを使う基本的なコードを見てみましょう。
import dev.langchain4j.http.client.jdk.JdkHttpClient;
import dev.langchain4j.model.chat.ChatModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.service.AiServices;
import java.net.http.HttpClient;
public class AiServiceSample {
interface SimpleService {
String chat(String prompt);
}
static String MODEL =
"qwen/qwen3-1.7b";
public static void main(String[] args) {
ChatModel model = OpenAiChatModel.builder()
.baseUrl("http://localhost:1234/v1")
.modelName(MODEL)
.httpClientBuilder(JdkHttpClient.builder().httpClientBuilder(
HttpClient.newBuilder().version(HttpClient.Version.HTTP_1_1)))
.build();
SimpleService service = AiServices.builder(SimpleService.class)
.chatModel(model)
.build();
String message = """
/no_think
日本の首都は?""";
String response = service.chat(message);
System.out.println(response);
}
}
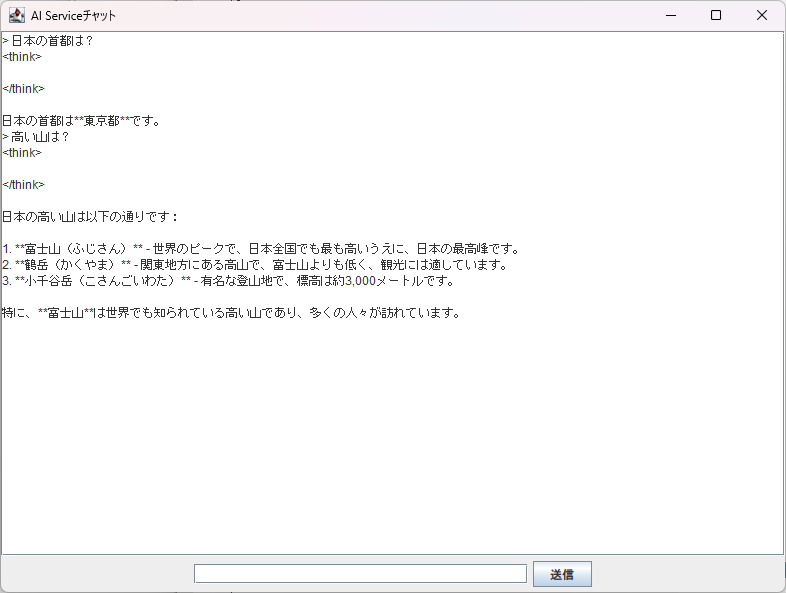
実行すると、今までと同様に日本の首都は東京という返答が出てきます。
<think> </think> 日本の首都は**東京(とうきょう)**です。東京は日本を代表する都市で、国務所や政府機関の所在地でもあります。
コードを見ていきましょう。
AiServicesでは、まずインタフェースを定義して処理の窓口になるメソッドの定義が必要です。
interface SimpleService {
String chat(String prompt);
}
AiServicesのbuilderに先ほどのインタフェースを渡して、chatModelを指定しbuildメソッドを呼び出すと、インタフェースを実装しAI処理が埋め込まれたオブジェクトが返ってきます。
SimpleService service = AiServices.builder(SimpleService.class)
.chatModel(model)
.build();
以降の処理では、このオブジェクトに対して処理を行います。インタフェースで定義したchatメソッドを呼び出すと、LLMにプロンプトが渡されて、返答が返ります。
String response = service.chat(message);
AiServicesでのストリーミング
AIServicesを使う処理をストリーミングに対応すると次のようになります。
import dev.langchain4j.http.client.jdk.JdkHttpClient;
import dev.langchain4j.model.chat.StreamingChatModel;
import dev.langchain4j.model.openai.OpenAiStreamingChatModel;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.TokenStream;
import java.net.http.HttpClient;
public class AiServiceStreamSample {
interface SimpleService {
TokenStream chat(String prompt);
}
static String MODEL =
"qwen/qwen3-1.7b";
public static void main(String[] args) throws InterruptedException {
StreamingChatModel model = OpenAiStreamingChatModel.builder()
.baseUrl("http://localhost:1234/v1")
.modelName(MODEL)
.httpClientBuilder(JdkHttpClient.builder().httpClientBuilder(
HttpClient.newBuilder().version(HttpClient.Version.HTTP_1_1)))
.build();
SimpleService service = AiServices.builder(SimpleService.class)
.streamingChatModel(model)
.build();
String message = """
/no_think
日本の首都は?""";
TokenStream response = service.chat(message);
Object sync = new Object();
response.onPartialResponse(s -> System.out.print(s))
.ignoreErrors()
.onCompleteResponse(res -> {
synchronized (sync) {
sync.notify();
}
})
.start();
synchronized(sync) {
sync.wait();
}
}
}
変更点を見ていきます。
インタフェースでのメソッド定義で、戻り値をTokenStreamにします。
TokenStream chat(String prompt);
用意するモデルをStreamingChatModelに変更します。
StreamingChatModel model = OpenAiStreamingChatModel.builder()
AiServicesへのモデルの設定も、chatModelではなくstreamingChatModelになります。
SimpleService service = AiServices.builder(SimpleService.class)
.streamingChatModel(model)
.build();
LLMにメッセージを送るとTokenStreamが返ってくることになります。
TokenStream response = service.chat(message);
onPartialResponseで部分的なレスポンス処理を行います。ここでは標準出力に表示しています。
response.onPartialResponse(s -> System.out.print(s))
今回はignoreErrorsとすることでエラーを無視するようにします。
.ignoreErrors()
エラー処理をする場合はonErrorで例外に対処します。ignoreErrorsかonErrorのどちらかは必要です。
startで処理を開始します。
.start();
ただし、これではLLMから返答が返ってくる前にmainメソッドを抜けてしまってプロセスが終わってしまうので、返答が終わるまで待つ必要があります。そこで、終了待ちのモニタになるオブジェクトを用意します。
Object sync = new Object();
そして、waitメソッドで実行を停止しnotifyメソッドが呼び出されるまで待機します。waitメソッドは、モニタになるオブジェクトを渡したsynchronizedブロックで囲う必要があります。
synchronized(sync) {
sync.wait();
}
TokenStreamのonCompleteResponseで返答終了時に呼び出される処理を設定します。
.onCompleteResponse(res -> {
synchronized (sync) {
sync.notify();
}
})
ここでnotifyメソッドを呼び出すと、waitメソッドで待機していた処理が再開され、mainメソッドの最後に到達してプログラムが終了します。notifyメソッドもsynchronizedブロックで囲う必要があります。
AI Serviceを使ったチャット
それでは、前回の最後に作ったストリーム版AIチャットアプリをAiServicesに対応してみましょう。
コードは次のようになります。
package examples.ai03;
import dev.langchain4j.http.client.jdk.JdkHttpClient;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.openai.OpenAiStreamingChatModel;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.TokenStream;
import java.net.http.HttpClient;
import java.awt.BorderLayout;
import javax.swing.*;
public class AiServiceChat {
interface SimpleService {
@SystemMessage("""
/no_think
あなたはユーザーの役にたつアシスタントです。""")
TokenStream chat(String prompt);
}
static String MODEL =
"qwen/qwen3-1.7b";
public static void main(String[] args) {
JFrame f = new JFrame("チャット");
f.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
f.setSize(800, 600);
JTextArea output = new JTextArea();
output.setFocusable(false);
output.setLineWrap(true);
f.add(new JScrollPane(output,
JScrollPane.VERTICAL_SCROLLBAR_AS_NEEDED,
JScrollPane.HORIZONTAL_SCROLLBAR_NEVER));
JPanel p = new JPanel();
JTextField tf = new JTextField(30);
JButton b = new JButton("送信");
p.add(tf);
p.add(b);
f.add(BorderLayout.SOUTH, p);
f.setVisible(true);
var model = OpenAiStreamingChatModel.builder()
.baseUrl("http://localhost:1234/v1")
.modelName(MODEL)
.httpClientBuilder(JdkHttpClient.builder().httpClientBuilder(
HttpClient.newBuilder().version(HttpClient.Version.HTTP_1_1)))
.build();
SimpleService service = AiServices.builder(SimpleService.class)
.streamingChatModel(model)
.chatMemory(MessageWindowChatMemory.withMaxMessages(50))
.build();
b.addActionListener(ae -> {
String text = tf.getText();
if (text.isBlank()) return;
tf.setText("");
output.append("> %s\n".formatted(text));
TokenStream response = service.chat(text);
response.onPartialResponse(str -> {
output.append(str);
output.setCaretPosition(output.getText().length());
})
.onCompleteResponse(res -> output.append("\n"))
.ignoreErrors()
.start();
});
tf.addActionListener(b.getActionListeners()[0]);
}
}
前回のサンプルではシステムメッセージをChatMemoryに追加していましたが、今回はサービスインタフェースのメソッドに@SystemMessageアノテーションを付けて記述しています。
interface SimpleService {
@SystemMessage("""
/no_think
あなたはユーザーの役にたつアシスタントです。""")
TokenStream chat(String prompt);
}
ただ、前回システムメッセージのクラスはdev.でしたが、今回のアノテーションはdev.でパッケージが違うのでimportに気を付けてください。
StreamingChatModelを用意したあとで、AiServicesを用意します。このとき、ChatMemoryも設定します。
SimpleService service = AiServices.builder(SimpleService.class)
.streamingChatModel(model)
.chatMemory(MessageWindowChatMemory.withMaxMessages(50))
.build();
前回のサンプルでchatメソッドを呼び出していた部分を書き換えます。
memory.add(new UserMessage(text));
model.chat(memory.messages(), new StreamingChatResponseHandler(){
...
});
次のようになります。
TokenStream response = service.chat(text);
response.onPartialResponse(str -> {
output.append(str);
output.setCaretPosition(output.getText().length());
})
.onCompleteResponse(res -> output.append("\n"))
.ignoreErrors()
.start();
ここで、ChatMemoryにユーザー入力やシステム返答を登録する必要がないことに注意してください。AiServicesを使うと、ChatMemoryの管理も自動的に行われます。また、SwingプログラムはUIプロセスが動く間はアプリケーションが止まらないので、waitやnotifyでの終了制御は不要です。
実行すると前回のサンプルと同じように動くはずです[1]。
Function Calling
それでは、Function Callingを実装しましょう。
LLMから呼び出してもらうメソッドを定義したクラスを用意します。
static class WeatherService {
private final Random random = new Random();
@Tool("与えられた場所の天気の情報を取得します。")
public String getWeather(String place) {
var wethers = List.of("晴れ","晴れ", "雨", "曇り","曇り", "雪");
return wethers.get(random.nextInt(wethers.size()));
}
@Tool("現在時刻を返します")
public String getTime() {
return LocalDateTime.now().toString();
}
}
呼び出されるメソッドには@Toolアノテーションを付けます。パッケージまで含めるとdev.です。 ここにメソッドの説明を書いておくとLLMに渡されます。LLMはこの説明を参考にしてメソッド呼び出しを決めます。
今回は、天気を返すgetWeatherメソッドと、現在時刻を返すgetTimeメソッドを用意しました。ただし、天気はランダムに決めています。
toolsとしてメソッド定義クラスのオブジェクトをAiServicesに渡します。
SimpleService service = AiServices.builder(SimpleService.class)
.streamingChatModel(model)
.chatMemory(MessageWindowChatMemory.withMaxMessages(50))
.tools(new WeatherService())
.build();
実行すると次のようにgetWatherメソッドやgetTimeメソッドを呼び出した結果を返答に含めていることがわかります。
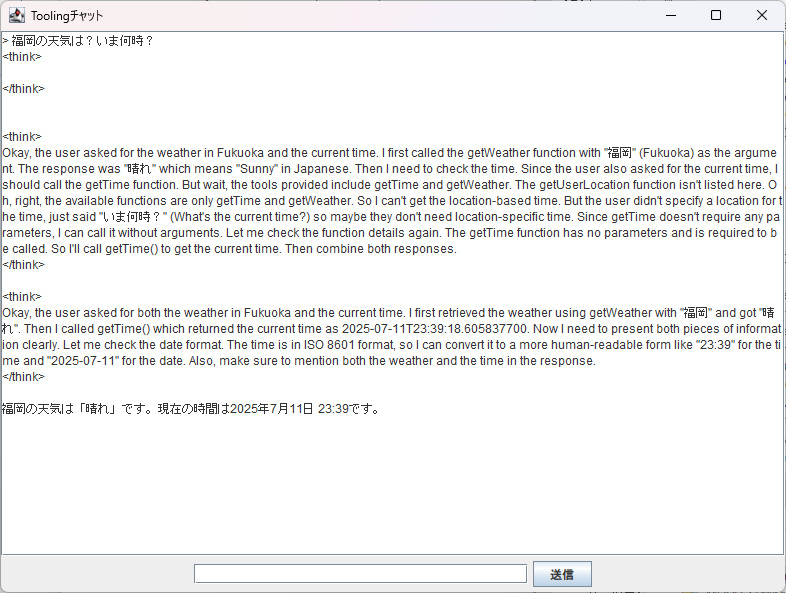
Qwen3 1./no_が効かなくなります。Function Callingではメソッドの定義がシステムプロンプトで渡されるため、プロンプトが長くなります。そのため、今回の例では<think>でメソッド呼び出しの検討を行うところが見えています。
2番目の<think>はgetWeatherを呼び出したあとでgetTimeの呼び出し方を検討し、3番目の<think>でgetTimeの結果を統合して返答を生成しています。このThink部分を見てわかるように、Function CallingではLLMが必要なメソッドを判断して呼び出します。
RAG
最後にRAGを実装してみます。RAGは広義では外部の情報をLLMに投入する手法全体を指しFunction Callingも含みますが、通常はプロンプトからデータベースを検索した結果を含めてLLMに渡す仕組みを指します。特に、プロンプトから計算したエンベディングベクトルと、文書のエンベディングベクトルを比較して検索する手法を指すことが多いです。
エンベディングベクトルとは、文章の特徴を表すベクトルで、同じような内容の文章であれば同じような方向のベクトルになります。この性質を利用して、入力したプロンプトに近い文書を探してLLMへの問い合わせに含めて返答を生成する仕組みが、今回実装するRAGです。
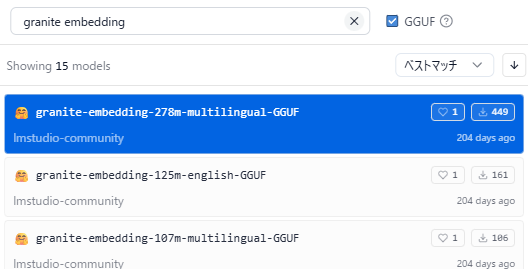
まずはエンベディングベクトルを計算するエンベディングモデルが必要です。日本語に対応するために、日本語に対応したエンベディングモデルが必要になります。今回はIBMが作成した多言語対応エンベディングモデルのGranite Embedding 278Mを使います。Qwen3 1.granite-embedding-278m-multilingual-GGUFをダウンロードします。元々のサイズが小さいのでQ8_を使います。
エンベディングモデルはEmbeddingModelとして読み込みます。ここでもOpenAI互換のプロトコルで利用するのでOpenAiEmbeddingModelを使います。
String EMBEDDING =
"text-embedding-granite-embedding-278m-multilingual";
EmbeddingModel embedding = OpenAiEmbeddingModel.builder()
.baseUrl("http://localhost:1234/v1")
.modelName(EMBEDDING)
.httpClientBuilder(JdkHttpClient.builder().httpClientBuilder(
HttpClient.newBuilder().version(HttpClient.Version.HTTP_1_1)))
.maxSegmentsPerBatch(5)
.build();
ChatModelとほとんど同じですが、今回はmaxSegmentsPerBatchで同時に渡すデータを5つに指定しています。
RAGの検索対象になるドキュメントを読み込みます。ここではdocumentsフォルダにある拡張子.mdのファイルを読み込むようにします。適当な文書やWeb記事のコピーなどを保存して試してみるといいでしょう。
List<Document> documents = FileSystemDocumentLoader.loadDocuments(
Path.of("documents"),
FileSystems.getDefault().getPathMatcher("glob:*.md"));
エンベディングベクトルを保存するデータストアを用意します。今回は手軽にインメモリで使えるInMemoryEmbedingStoreを使います。
var store = new InMemoryEmbeddingStore<TextSegment>();
エンベディングベクトルを先ほどのエンベディングモデルで取得して、データストアに保存するEmbeddingStoreIngestorを用意して、ingestメソッドでドキュメントに対する処理を行います。
EmbeddingStoreIngestor.builder()
.embeddingModel(embedding)
.embeddingStore(store)
.documentSplitter(DocumentSplitters.recursive(1500, 30))
.build()
.ingest(documents);
System.out.println("ingest完了");
あまり大きいドキュメントを使うと、エンベディングベクトルの比較が行いにくくなり、また今回のGranite Embeddingがあまり長い文章に対応していないこともあり、ここでは1500文字で文章を区切るようDocumentSplitters.を使っています。30文字が重複するようにします。また、この処理には時間がかかるので、終了時に標準出力にメッセージを出すようにしています。
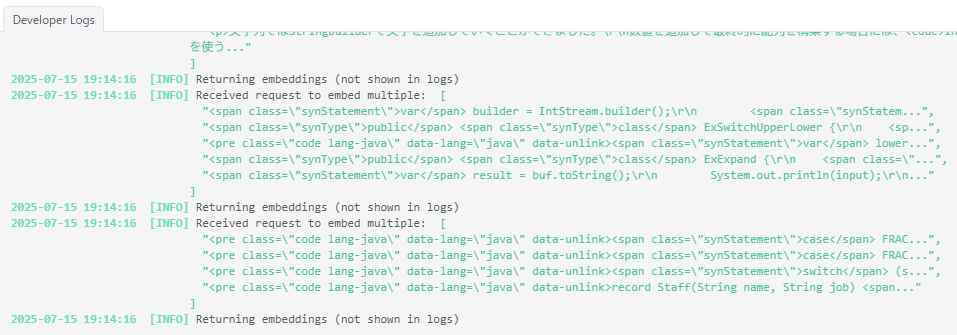
ingestメソッドの処理が行われる間、エンベディングモデルが呼び出されるので、LM Studioのログに次のように出力されます。今回はバッチサイズを5に設定しているので、5件ごとに呼び出されていることがわかります。
ここまでがRAGでの検索のためのデータの準備です。
LLMとのやりとりでRAGを実現するために、エンベディングデータストアから検索してLLMにデータを渡すためのEmbeddingStoreContentRetrieverを用意します。
ContentRetriever retriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)
.embeddingModel(embedding)
.build();
最後に、contentRetrieverでAiServicesに設定します。
SimpleService service = AiServices.builder(SimpleService.class)
.streamingChatModel(model)
.chatMemory(MessageWindowChatMemory.withMaxMessages(50))
.contentRetriever(retriever)
.build();
今回は筆者のブログのデータを用意して
次のブログエントリの内容を反映した返答が返ってきました。
1.
次回は、MCPのサーバーとクライアントを実装します。