



はじめに
株式会社MIXIで
みてねの写真プリントサービスでは、ユーザが毎月アップロードした写真の中から、最適な11枚を自動的に選び出してプリント注文を提案しています。今回は、従来のルールベースの方式から、データ駆動型の機械学習アプローチへの移行を検証した経緯や技術的な選択について、この記事でご紹介します。
みてねの写真プリントサービスについて
みてねの写真プリントサービスは、大切な思い出の写真を高品質なプリントとして手元に残せる人気のサービスです。スマートフォンに保存されたままになっている写真を、実際に手に取って楽しむことができます。

このサービスの主な特長は以下のとおりです。
- 毎月11枚まで写真プリントが永続的に無料
- 月に3回まで送料のみで注文可能
- 家族全員がそれぞれ無料で注文可能
- アップロード済みの写真から自由に選択してプリント
- 毎月、前月アップロード分からおすすめの11枚を自動提案
とくに注目していただきたいのが、最後の
本記事では、このレコメンデーションシステムを従来のルールベース方式から機械学習
自動提案の制約
写真プリント自動提案は、2,500万ユーザ
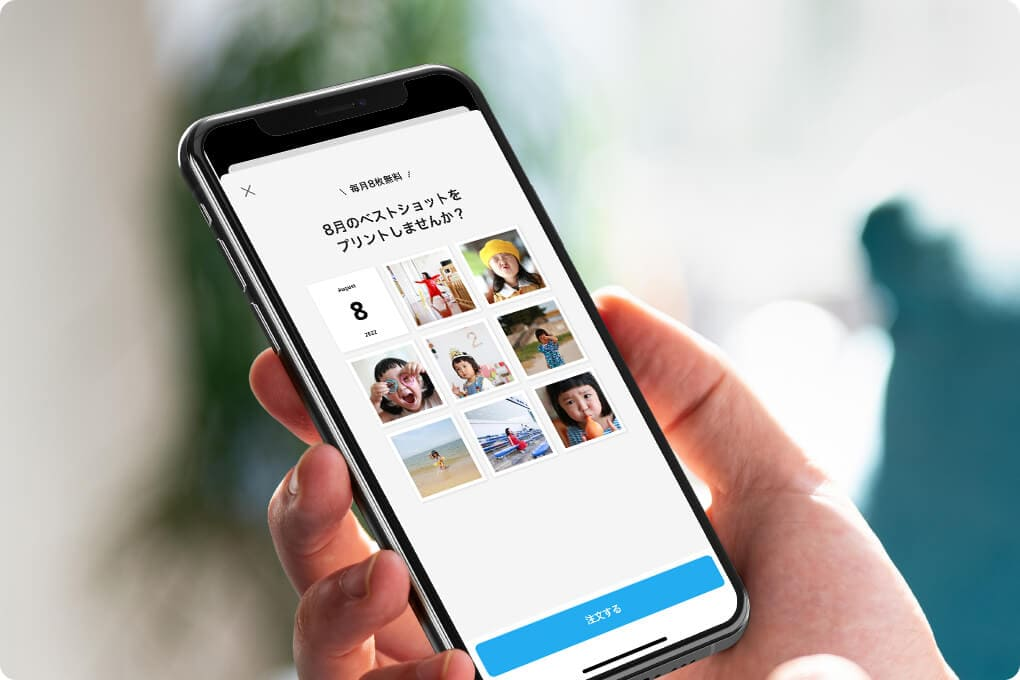
利用できる画像情報
自動提案に活用できる写真の特徴量は以下のとおりです。
- 画像メタデータ:解像度、撮影日など
- ユーザによって付けられた情報:お気に入り登録数、コメント数、公開範囲
- MLモデルによる画像解析:顔検出・
年齢推定・ 顔の向きなど
従来(ルールベース)の写真プリント自動提案システム
ルールベースの自動提案生成プロセス
本来は写真プリント専用のレコメンデーションシステムを構築することが理想的でしたが、設計・
そのため、既存のフォトブック自動提案システムから得られる23枚の写真を活用し、それをベースとして写真プリントの自動提案を生成する方法を採用しています。
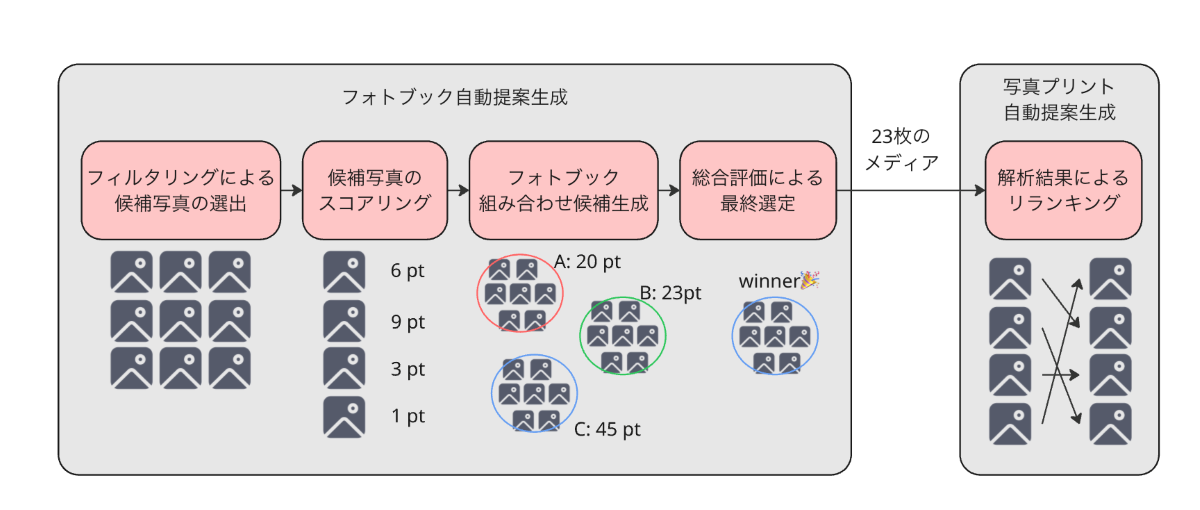
それぞれの処理の詳細は以下のとおりです
①フォトブック自動提案生成
詳細については、過去の記事
- 候補写真のフィルタリング:
「お気に入り」 「家族みんなに公開」 「ML評価スコア」 などの条件に基づき、フォトブックに適した候補写真を抽出します。 - 写真のスコアリング:抽出された候補写真それぞれに、メタデータと画像解析結果から算出したスコアを付与します。
- フォトブック候補の生成:高スコア写真を優先しつつ、撮影日時の分散も考慮して23枚
(表紙1枚+本文22枚) の写真を選出し、複数パターンの候補を生成します。 - 最適候補の選定:生成された候補から、写真の分散度などの総合評価に基づき、最高スコアの候補をフォトブックとして採用します。
②写真プリント提案生成プロセス
- フォトブック自動提案で選出された23枚の写真から、お気に入り状態、撮影日の重複、公開範囲、顔検出結果などの複合評価に基づき、写真プリントに最適な11枚を選出します。
ルールベース方式の自動提案技術的課題
従来のルールベースアプローチには、以下の技術的な課題がありました:
- パーソナライゼーションの限界:個々のユーザ嗜好に適応した提案が困難
- サービス最適化の制約:フォトブック自動提案システムへの依存により、写真プリント特有のユーザ行動パターンに対応できない
- 計算効率の問題:複数段階処理による高い計算コストとリソース消費
- 自動提案のメンテナンス性の限界:
- 新規特徴量追加による効果が限定的
- データドリフト
(ユーザ行動変化) への対応力不足 - 複雑なルール構造によるメンテナンス困難性
ML自動提案モデル構築
機械学習
- パーソナライゼーションの強化:ユーザ個々の特性や嗜好を学習し、最適な写真を提案
- 独立した自動提案システム:フォトブック提案に依存せず、写真プリント専用のロジックを実現
- 処理効率の向上:木構造のMLモデルを採用し、複雑な組み合わせ計算を効率化
- 拡張性と保守性の改善:特徴量の追加や改良が容易な柔軟なアーキテクチャを構築
これらの改善により、システムコストを抑えながらも、ユーザ満足度と購買数の向上を実現できるか検証しました。
評価指標の策定
従来のルールベースの自動提案システムは人手によるチューニングのみに頼っており、十分な指標の決定がされていない状況でした。
そこで、施策を始める前に、自動提案システムの精度指標やKPI
-
自動提案モデルの目的関数
- Binary Cross Entropy:過去の情報を参照し、売れたメディアを1、売れなかったメディアを0としてラベル付けして学習しました。
- 他にもLambdaRankなどのランキング学習手法も試しましたが、我々の実験では精度向上につながりませんでした。
- Binary Cross Entropy:過去の情報を参照し、売れたメディアを1、売れなかったメディアを0としてラベル付けして学習しました。
-
自動提案結果の精度指標
- Recall@11:自動提案された11枚の写真のうち、実際にユーザが購入した写真の割合を測定する指標です。この値が高いほど、ユーザの好みに合った写真を提案できていることを意味します。mAP
(Mean Average Precision) も検討しましたが、自動提案結果を日付順で表示するというUI上の制約があり、ランキング順での表示ではないため、評価指標としては採用しませんでした。
- Recall@11:自動提案された11枚の写真のうち、実際にユーザが購入した写真の割合を測定する指標です。この値が高いほど、ユーザの好みに合った写真を提案できていることを意味します。mAP
-
KPI
- 自動提案経由での写真プリント離脱率:ユーザが自動提案を閲覧した後、注文完了せずに離脱してしまう割合です。この値が低いほど、提案内容がユーザの期待に沿っていると判断できます。
- 自動提案経由での写真プリント選択時間:ユーザが自動提案を確認してから注文を確定するまでの時間です。この時間が短いほど、ユーザにとって魅力的な提案であったと解釈できます。
- 自動提案メディア購買数:実際に自動提案を通じて購入された写真の枚数です。この数値が多いほど、ビジネス面での成功を示します。
データセット構築
大量の購入履歴によるデータセット構築
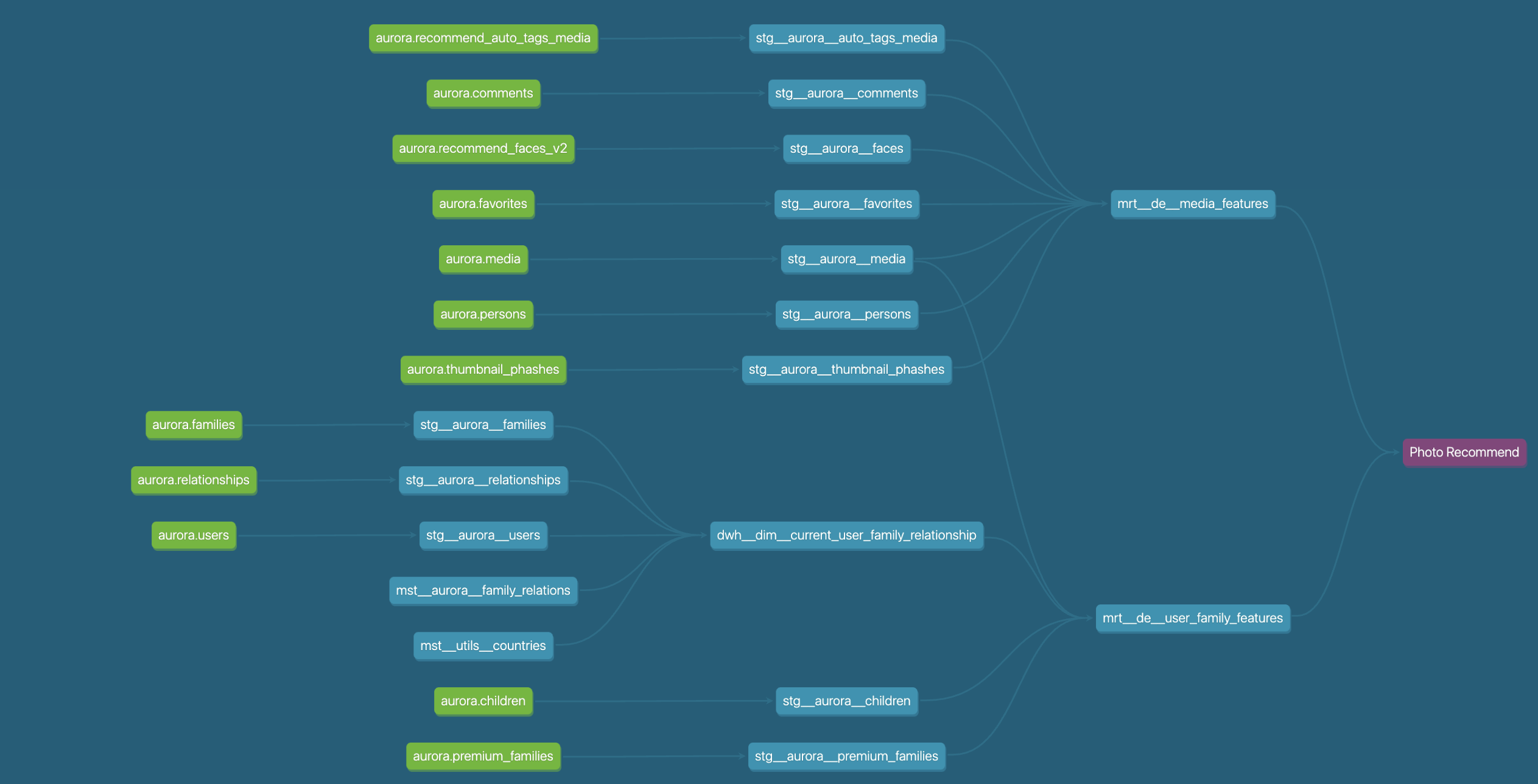
MLモデルの学習や推論に必要なデータは、みてねのRDBやFirebaseのEventLogなど複数のソースから取得します。そこでデータ参照先としてBigQueryを採用しました。みてねではBIや分析だけでなく、アプリケーション開発にも広く活用しています。とくに自動提案処理ではRDBへの負荷が高いため、BigQueryへのオフロードが効果的です。
BigQuery上の複数データの整形にはDBTを使用しました。DBTはSQLでデータ変換処理を記述し、データパイプラインの構築・
以下はDBT上で構築したデータパイプラインの図です。これにより、メディアのメタデータやいいねの数、コメント数など、さまざまな特徴量を抽出し、モデルの入力として利用しています。
Training/Validationデータセット
データセットには過去の写真プリント購入履歴を使用し、購入されたメディアを1、購入されなかったメディアを0としてラベル付けしました。Training データとValidationセットは 家族IDで分割し、1割の家族をValidationセットとして分割して利用しました。
課題として、購入されたメディアよりも購入されなかったメディアが圧倒的に多いという、クラス不均衡の問題がありました。この状態では、モデルが適切に学習できません。
解決策として、Training セットのみ、購入されなかったメディア
この手法により、我々の実験ではモデルの予測精度が大幅に向上することを確認できました。
評価セット
モデル評価では、バイアスのないデータを使用することが重要です。みてねの写真プリントには2つの購入パターンがあります。
- 自動提案UI経由:システムが選んだ写真をユーザが購入
- 特徴:提案されたメディアが購入されやすいというバイアスが存在
- 選択画面UI経由:ユーザが自ら写真を選んで購入
- 特徴:ユーザの真の嗜好がより反映されている
今回の検証では、できるだけバイアスを避けるため、
また、データリークを防止するため、Training/
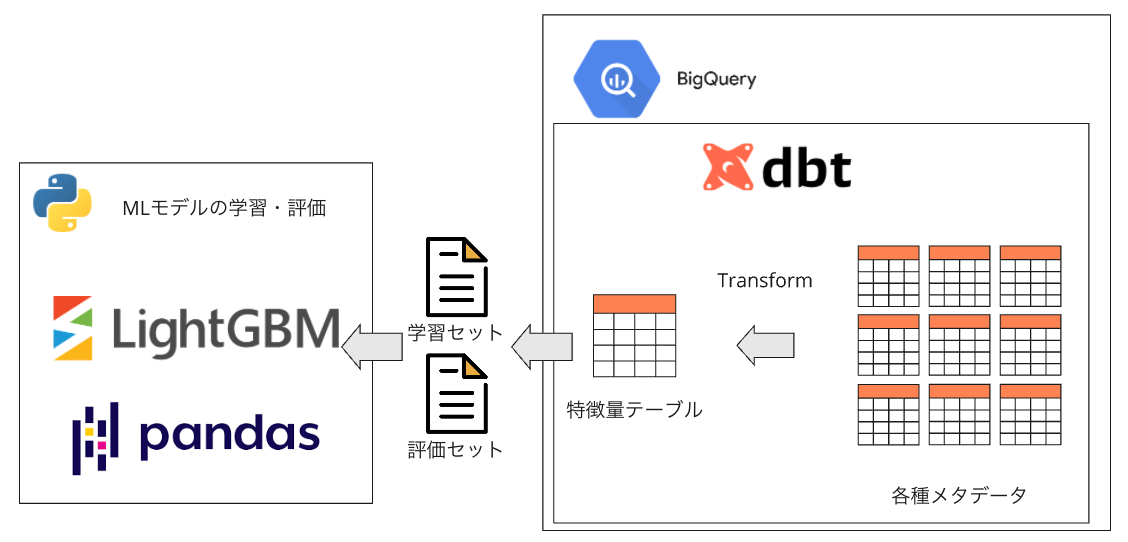
MLモデルの選定
写真プリント自動提案のMLモデル選定においては、計算コストの効率性と実績のあるモデルを重視しました。特に検討したのは以下のモデルカテゴリーです。最終的に計算リソースの制約、過去の実績、予測精度、そして実装の容易さなどから、1st stepとしては、LightGBMを採用しました。
-
木構造系モデル
- LightGBM:勾配ブースティング決定木の一種で、メモリ効率と計算速度に優れています。とくに、レコメンデーション系のKaggleコンペティションで多く採用されています。
- XGBoost:高い予測精度と過学習に強い特性を持ちますが、LightGBMと比較検討した結果、計算効率が劣るため、今回のユースケースでは見送りました。
-
Deep Learning系モデル
- DNNベースのモデル:画像特徴量を用いた、より複雑で精度の高いモデルを構築できる可能性がありましたが、モデルの解釈性やハイパーパラメータチューニングの難しさなどを考慮して今回のユースケースでは見送りました。
MLモデルの学習
学習にはLightGBMを使用し、ハイパーパラメータを調整しながら最適化を行い、ローカル検証結果が最も良かったモデルを採用しています。
オフライン精度検証
検証方法
データセット構築で作成した評価セットをもとに、モデルの評価指標としてあらかじめ決めておいたRecall@11を用いて自動提案精度を検証しました。
検証プロセスでは、以下のステップで精度評価を行いました。
- 評価セットの各ユーザに対して、モデルが予測スコアの高い順に写真を11枚選定
- その11枚の中に、実際にユーザが購入した写真が何枚含まれているかをカウント
- 全ユーザの平均Recall@11を算出し、ベースラインモデル
(ルールベース) と比較
検証結果
検証の結果、従来のルールベース方式と比較して、ML自動提案方式では選択画面UI経由での提案精度が有意に向上しました。特に、ユーザの購入傾向を学習したモデルによって、個々のユーザの嗜好に合わせたパーソナライズされた写真提案が実現できました。
※ 具体的な数値については今回は控えさせていただきます。
ML自動提案とルールベース自動提案の精度比較
この結果を受けて、チームはプロダクション環境での検証フェーズへ移行し、実際のユーザ行動データに基づく検証を通じて、MLモデルの実用性と効果を確認することになりました。
本番環境でのA/Bテスト
ML自動提案システムの効果を定量的に評価するため、従来のルールベース方式と比較するA/
-
ユーザ体験の向上:ML自動提案の導入により、提案画面から購入完了までの導線においてユーザの離脱率が若干減少しました。これはより適切な写真提案がユーザの関心を引き付けた結果と考えられます。
-
購入枚数の微増:ユーザあたりの写真プリント購入枚数に若干の増加が見られ、パーソナライズされたレコメンデーションが一定の効果をもたらしたことが示唆されました。
しかしながら、これらの改善効果は当初の期待値を下回る限定的なものでした。そのため、現時点では全面的な展開を見送り、一時的にルールベース方式に戻しながら、MLモデルの改良を続けています。
まとめと今後の展望
みてね写真プリントサービスでは、従来のルールベース方式から機械学習モデルを活用した自動提案システムへの移行に取り組みました。特徴量エンジニアリングからモデル選定、実証検証まで一連のプロセスを実施し、実用化を目指しました。
改善したポイント
今回ML自動提案手法を検討したことで、従来手法から比べて、以下の点が改善でき、システムコストを抑えながらも、ユーザ満足度と購買数の向上を実現できそうということがわかりました
- パーソナライゼーションの強化:ユーザ個々の特性や嗜好を学習し、最適な写真を提案
- 独立した自動提案システム:フォトブック提案に依存せず、写真プリント専用のロジックを実現
- 処理効率の向上:木構造のMLモデルを採用し、複雑な組み合わせ計算を効率化
- 拡張性と保守性の改善:特徴量の追加や改良が容易な柔軟なアーキテクチャを構築
今後の課題
より効果的なシステムの実現に向けて、以下の2つの課題に取り組みます。
- 特徴量の強化による精度向上
- 閲覧履歴や詳細な画像特徴量の活用による予測精度の向上
- ユーザ行動の詳細分析に基づくパーソナライズ提案の質的向上
- MLOps基盤の構築
- 継続的なモデル更新パイプラインの実装
- データドリフト検出と自動対応の仕組み化
- 効率的なモデル管理とモニタリング体制の確立
さいごに
今後もML技術を活用して、一人ひとりの好みや思い出の文脈を深く理解した、より価値の高い自動提案の実現を目指します。技術の進化とともに、ユーザ体験の向上に継続的に取り組んでいきます。