


OpenAIは2025年12月16日、これまで同社が提供していた画像生成モデルから大幅に能力を向上させた新しい画像生成モデルとそのAPI
gpt-image-1.
今回のgpt-image-1.
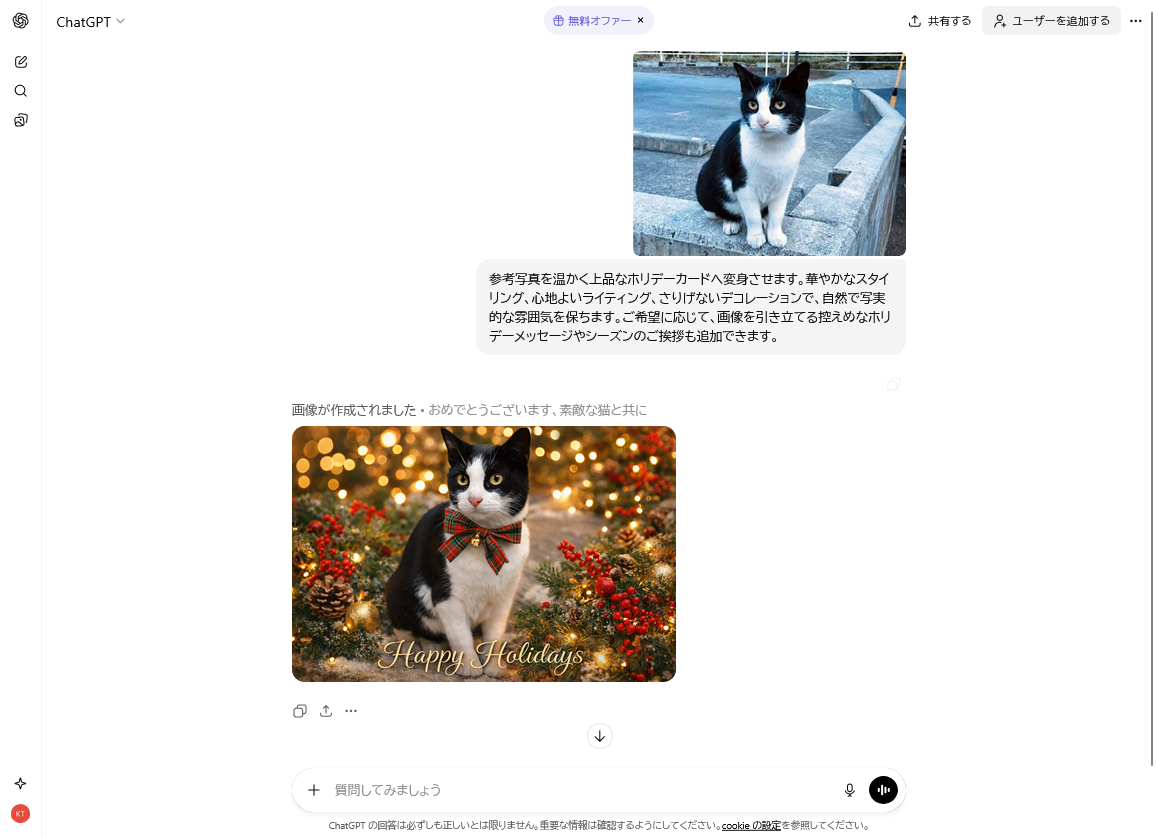
なお、日本語を含む多言語への対応も強化はされているが、日本語の文字列を明示していない大雑把なプロンプトで確認した限りでは、日本語テキストの描画品質がところどころの文字でまだ微妙な品質にみえた

- 構造+ゴール:背景→被写体→重要ディテール→制約という一貫した構造と画像の用途を明示し、長文ではなくラベル付き見出しや改行で整理することで、モデルに求めるモードと完成度を伝える。
- 具体性と品質:素材・
形状・ テクスチャ・ メディアやライティング条件を具体的に書き、必要な範囲でフィルムグレイン (微細な粒子状の質感) やタッチなどの品質を追加し、抽象的な形容詞よりもレンズや光条件を指定する。 - レイテンシと忠実度のバランス:大量生成やレイテンシ重視のユースケースではまず
quality="low"から試す(多くの場合、低品質設定でも、これまでよりも画質を保ちつつ生成速度を大幅に向上している)。 - 構図の明示:クローズアップかワイドか、俯瞰かアイレベルかといった視点やライティング、ムード、ロゴやテキストの配置を具体的に指定し、望むレイアウトをプロンプトで制御する。
- 変更点と保持要素の区別:
「Xだけ変更する」 「それ以外はすべてそのままにする」 といった表現で、変更する部分と維持すべき部分を明示する。 - テキストの扱い:画像内テキストは引用符や大文字で示し、フォントスタイルやサイズ、色、配置を具体的に記述する。難しい綴りは一文字ずつ明示する
(スペルアウトする) ことで文字精度を高める。 - 複数の画像入力:複数画像には
「Image 1: ...」 「Image 2: ...」 のように役割を与え、 「Image 1のスタイルをImage 2に適用する」 など変換関係を明示する。 - 過度の要求ではなく反復:最初から複雑な要求を一度に投げるのではなく、まずベース画像を生成し、その後
「光を暖かくする」 など小さな変更指示を段階的に与えるほうが安定した結果を得やすい。
gpt‑image‑1.
APIとしてのgpt-image 1.quality設定input_パラメータでhigh"を指定すると、入力画像トークン数が増加しコストにも影響するが、入力画像の細部をより忠実に保持しながら編集や合成を行うことができるとのこと