



杉田
従来のLLM
CrewAIとは
CrewAIは、複数のAIエージェントを役割ごとに編成し
- 公式ドキュメント
(CrewAI Documentation) -
URL:https://
docs. crewai. com
CrewsとFlows
CrewAIには中核となる2つの概念があります。
- Crews
(本記事のメイン) -
- 宣言的な記述で簡単に
「AIチーム」 を作成するための仕組み - 人間のチームのように、各エージェントが役割、目的、背景を持ち協力して問題を解決
- 宣言的な記述で簡単に
- Flows
-
- Crewsや個々のエージェントの実行を組み合わせ、処理の流れを制御するための仕組み
- 状態管理・
条件分岐・ イベント制御などを用いて、より複雑なワークフローを構築できる
Flowsの詳細には触れませんが、より高度な制御が可能です。興味のある方は、以下の公式ドキュメントをご参照ください。
本記事では、Crewsに焦点を当てて基本的な使い方を解説します。
Crewsの構成要素
CrewAIでAIチームを作る際の基本要素は以下の4つです。
- Agent:明確な役割と目的を持ち、Taskを遂行する自律的なAIエージェント
- Task:Agentに割り当てられる具体的な作業内容と期待される成果物を定義したもの
- Process:Taskの実行順序を制御
(順次プロセス、階層型プロセス) -
Process 実行方法 順次プロセス (Sequential) Task は定義した順番に実行される 階層型プロセス (Hierarchical) マネージャー役のLLMがAgentにTaskを動的に割り当てる
-
- Crew:複数のAgentとTaskをまとめ、指定されたProcessに従って実行をオーケストレーションする実行単位
CrewAIを動かしてみる
動作環境
- Python 3.
10以上 3. 14未満 (CrewAI の要件) - Python 3.
13 / CrewAI 1. 8.1 (本記事での動作確認環境)
それでは実際にCrewAIを使ってみましょう。
最小構成で動かす(順次プロセス)
まずは必要なライブラリをインストールして、最もシンプルなコードで動作を確認します。
pip install "crewai[google-genai]" python-dotenv
- crewai[google-genai]は、CrewAI本体とあわせてGoogleのGemini APIを利用するためのライブラリをインストールします。
- python-dotenvは、環境変数を.envファイルから読み込むために使用します。
CrewAIは、使用するLLMプロバイダのAPIキーなどを環境変数として参照します。後続の処理で複数のLLMを使い分けられるように、あらかじめOpenAI[1]とGoogle
OPENAI_API_KEY="your-api-key"
GOOGLE_API_KEY="your-api-key"
CrewAIは複数のLLMプロバイダに対応しており、必要な環境変数や設定内容は、使用するLLMプロバイダごとに異なります。対応している LLM の一覧および設定方法については、以下の公式ドキュメントを参照してください。
最もシンプルな構成で、Agent・
この例では、
from crewai import Agent, Crew, LLM, Process, Task
from dotenv import load_dotenv
# .envファイルから環境変数を読み込む
load_dotenv()
# 1. Agent定義
# 調査担当エージェント
researcher = Agent(
role="AI技術調査員",
goal="最新のAI技術動向を調査する",
backstory="あなたは技術トレンドに精通した調査の専門家です",
llm="gpt-4.1",
)
# 執筆担当エージェント
writer = Agent(
role="技術ライター",
goal="調査結果を分かりやすい記事にまとめる",
backstory="あなたは複雑な技術を平易な言葉で説明できるライターです",
llm=LLM(model="gemini/gemini-2.5-flash"),
)
# 2. Task定義
# 調査タスク
research_task = Task(
description="2025年のマルチエージェントAIの主要な進展を3つ挙げてください",
agent=researcher,
expected_output="主要な進展3つをそれぞれ1-2文で説明したリスト",
)
# 執筆タスク
writing_task = Task(
description="調査結果をもとに、200文字程度の技術ニュース記事を書いてください",
agent=writer,
expected_output="導入・本文・まとめの構成を持つ簡潔な記事",
context=[research_task], # 調査タスクの結果を受け取る
)
# 3. Crew定義(チーム編成)
my_crew = Crew(
agents=[researcher, writer],
tasks=[research_task, writing_task],
process=Process.sequential, # タスクを順番に実行
verbose=True, # 実行過程を表示
)
# 4. 実行
result = my_crew.kickoff()
print("\n=== 最終結果 ===")
print(result.raw)
- 1. Agentの定義
- CrewAI では、Agentを定義する際に次の3つのパラメータが必須です。
-
role:Agentの役割goal:達成すべき目的backstory:振る舞いを補強する背景設定
- この例では、調査担当と執筆担当の2つのAgentを定義し、それぞれに明確な役割を与えています。これにより、Agentごとに異なる専門性を持たせることができます。
- 2. Taskの定義と役割分担
- Taskには必須パラメータとして、以下を設定します。
-
description:Taskで実行する内容の説明expected_:期待される出力の形式や詳細output
-
agentは任意パラメータで、Taskを担当するAgentを指定します。ただし、CrewにProcess.sequentialを指定した場合、各Taskには agentの指定が必須となります。この例ではProcess.sequentialを使用しているため、すべてのTaskに agentを指定しています。 -
調査タスクでは
「2025年のマルチエージェントAIの進展を調べる」 ことを指示し、そのTaskを 調査担当エージェントに割り当てています。執筆タスクでは contextパラメータを使って調査タスクを指定しています。これにより、調査タスクの出力がそのまま次のTaskの入力として渡され、エージェント間で連携が可能になります。 - 3. Crew定義と実行戦略
(Process) -
Crewでは、AgentとTaskをまとめて
「チーム」 として定義します。Process. sequentialを指定すると、tasksに記載した順番どおりにTaskが実行されます。この例では、調査タスク→執筆タスクという流れが保証されます。 - 4. 実行と結果の取得
-
kickoff()メソッドを呼び出すことで、Crew全体の処理が開始されます。最終的な出力は、最後に実行されたTask(この例では執筆タスク) の結果であり、result. rawから取得できます。
このコードを実行してみましょう。
$ python sequential_example.py
このコードを実行するとCrewのverbose引数にTrueを指定しているため、CrewAIの実行過程がログとして表示されます。ログにはCrewの開始から各Task・
実行結果およびログ
実行ログには、主に以下の情報が表示されます。
- Crew実行の開始
(Crew名やID) - 各Taskの実行開始・
実行中・ 完了といったステータス - Taskを担当するAgentの起動
- Agentに割り当てられたTask内容
- Agentが生成した最終回答
(Final Answer) - すべてのTask完了後に出力されるCrew全体の最終結果
また、より詳細な実行ログを確認したい場合は、CrewAIが提供するトレース機能を利用できます。トレースでは、各TaskやAgentの内部的な処理状況をより細かく把握できます。具体的な使い方や確認方法については、以下を参照してください。
Agent / Task / Crewの主なパラメータ
Agent、Task、Crewには、それぞれの振る舞いや役割を定義するためのさまざまなパラメータがあります。以下に、主なパラメータを紹介します。
| パラメータ | 型 | 説明 |
|---|---|---|
role |
str |
(必須) |
goal |
str |
(必須) |
backstory |
str |
(必須) |
llm |
str | LLM | any |
Agentが使用する言語モデル。デフォルトはOPENAI_ |
tools |
list[BaseTool] [3] |
Agentが利用できるツール一覧 |
verbose |
bool |
詳細ログ出力の有無 |
allow_ |
bool |
Task委譲の許可フラグ |
| パラメータ | 型 | 説明 |
|---|---|---|
description |
str |
(必須) |
expected_ |
str |
(必須) |
agent |
BaseAgent |
このTaskを担当するAgent |
tools |
list[BaseTool] |
Task実行中に利用できるツール一覧 |
context |
list[Task] |
他Taskの出力を入力コンテキストとして利用 |
async_ |
bool |
非同期でTaskを実行するかどうか |
human_ |
bool |
人間の確認・ |
markdown |
bool |
出力をMarkdown形式にするかどうか |
output_ |
str |
Taskの出力を書き込むファイルパス |
output_ |
Type[BaseModel] |
JSON形式で出力するためのPydanticモデル |
output_ |
Type[BaseModel] |
Pydanticモデルとして構造化出力する指定 |
| パラメータ | 型 | 説明 |
|---|---|---|
tasks |
list[Task] |
(必須) |
agents |
list[Agent] |
(必須) |
process |
Enumsequential/hierarchical) |
Task実行のプロセスフロー |
verbose |
bool |
詳細ログを出すかどうか |
manager_ |
Any |
階層プロセスで使用するマネージャーAgentのLLM |
memory |
bool |
メモリ設定 |
上記で紹介したパラメータ以外にも細かな制御を行うためにさまざまな設定が可能です。詳細は以下を参照ください。
階層型プロセスとツール連携
前の例では Process.
この例では、ブログ記事作成を題材に、
また、Agentが外部情報を取得できるように、ツール
SerperDevToolを使用するには、事前にSerper.
まず、実行に必要なライブラリをインストールします。
pip install "crewai[google-genai,tools]" python-dotenv
crewai[tools]は、CrewAI で利用可能な各種ツールを提供するライブラリです。
OPENAI_API_KEY="your-api-key"
GOOGLE_API_KEY="your-api-key"
SERPER_API_KEY="your-serper-api-key" # SerperDevTool で使用する
以下が、サンプルコード全体です。
from crewai import Agent, Crew, LLM, Process, Task
from crewai_tools import SerperDevTool
from dotenv import load_dotenv
# .envファイルから環境変数を読み込む
load_dotenv()
# Google Web検索機能を表すツールオブジェクトを生成
# このインスタンスを Agent の tools に渡すだけで、検索ツールとして利用できる
search_tool = SerperDevTool()
# 1. エージェント定義
# データ収集
data_collector = Agent(
role="データ収集専門家",
goal="最新の統計データと数値情報を収集する",
backstory=(
"あなたはデータ収集の専門家です。"
"統計データ、数値、グラフなどの定量的な情報を見つけることが得意です。"
),
llm=LLM(model="gpt-4"),
tools=[search_tool],
verbose=True,
)
# トレンド分析
trend_analyst = Agent(
role="トレンド分析専門家",
goal="最新のトレンドや動向を分析する",
backstory=(
"あなたはトレンド分析の専門家です。"
"業界の最新動向、専門家の意見、将来予測などを調査します。"
),
llm=LLM(model="gpt-4"),
tools=[search_tool],
verbose=True,
)
# コンテンツライター
writer = Agent(
role="コンテンツライター",
goal="魅力的で分かりやすい記事を書く",
backstory=(
"あなたは経験豊富なライターです。収集された情報をもとに、読みやすい記事にまとめます。"
),
llm=LLM(model="gemini/gemini-2.5-flash"),
verbose=True,
)
# 2. タスク定義
task = Task(
description=(
"「{topic}」をテーマに読者に価値のあるブログ記事を作成してください。"
"2026年の予測データ、市場規模、成長率、導入率などの数値を盛り込んでください。"
"必要に応じて調査・分析・再調査・構成変更を行ってください。"
),
expected_output="完成したブログ記事(日本語で600文字程度)",
)
# 3. Crew定義(Hierarchical Process)
crew = Crew(
agents=[data_collector, trend_analyst, writer],
tasks=[task],
process=Process.hierarchical, # 階層的プロセス
manager_llm="gpt-4.1", # マネージャー用のLLMを指定。階層型プロセスでは必須のパラメータ。
planning=True,
verbose=True,
)
# 4. 実行
if __name__ == "__main__":
result = crew.kickoff(inputs={"topic": "マルチエージェントAIシステムの2026年の展望"})
print("\n=== 最終結果 ===")
print(result.raw)
python hierarchical_example.py
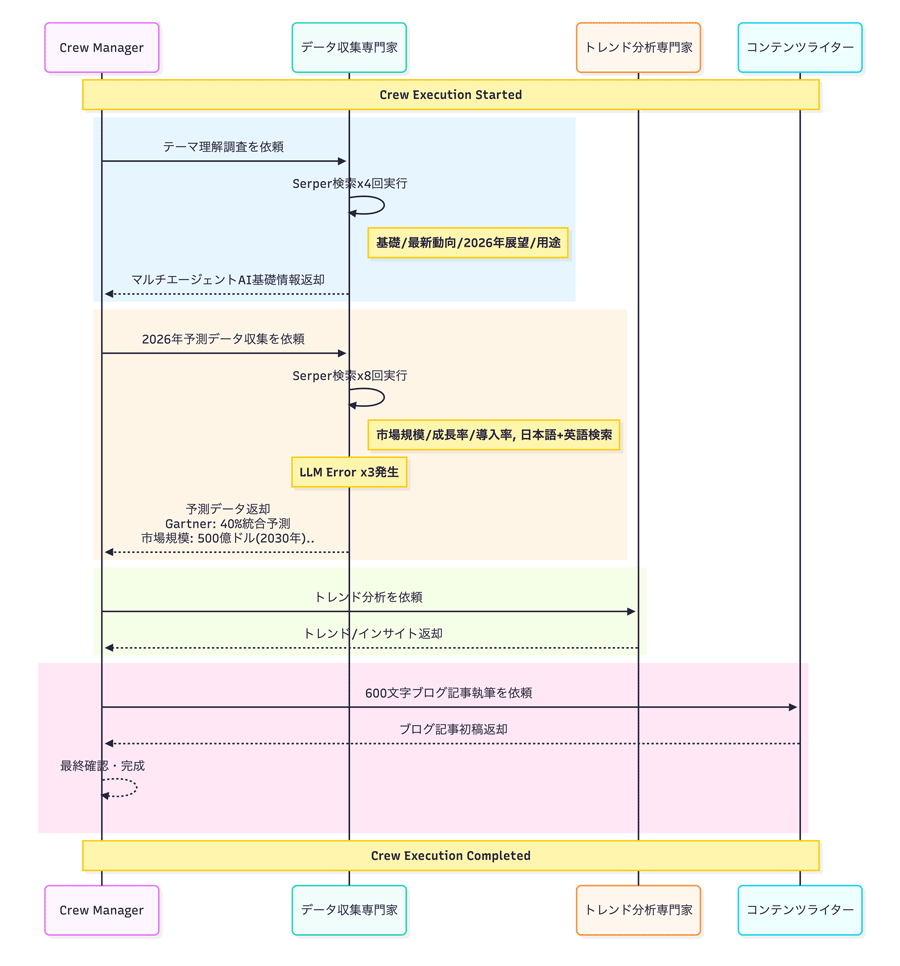
このコードを実行すると、階層型プロセスに基づいて、マネージャーLLMが全体を統括しながら処理が進行します。以下のシーケンス図は、実際の実行ログをもとに、Agent 間のやり取りを可視化したものです。実行時のおおまかな流れは以下のとおりです。
- マネージャーLLMはTaskの内容を把握し、全体の実行計画を立案する。実行計画には、次のような工程が含まれる。
- テーマの理解
(基礎知識・ 文脈の把握) - 必要なデータの収集
(市場規模・ 成長率・ 導入率などの収集) - データの分析(収集データから重要なトレンドやインサイトを抽出)
- 記事構成の決定
- 初稿の作成
- 再調査
(不足情報の補完)、校正、最終確認、発表
- テーマの理解
- マネージャーLLMは、各Agentの役割や能力を踏まえ、実行計画の一部を各Agentに割り当てる。
-
作業内容 担当Agent テーマの理解、必要なデータの収集 データ収集専門家 データの分析 トレンド分析専門家 初稿の作成 コンテンツライター - なお、実行計画の工程
「4. 記事構成の決定」 および 「6. 再調査・ 校正・ 最終確認・ 発表」 については、独立した作業として各Agentに割り当てられていることは確認できませんでした。
- マネージャーLLMの指示のもと、以下の流れで処理が進行する。
- データ収集専門家が
「マルチエージェントAIの基礎」 「最新動向」 「2026年展望」 「市場規模・ 成長率」 についてWeb検索を実施 - トレンド分析専門家が収集データをもとに、2026年のトレンド・
ビジネスインパクト・ 今後の展望を分析・ 要約 - コンテンツライターが分析結果を踏まえ、600文字程度の日本語ブログ記事初稿を作成
- マネージャーLLMがコンテンツライターの出力を受け取り、表現の簡略化・
出典の明確化・ 文体の統一などの修正を加えて最終成果物として出力
- データ収集専門家が
このように、階層型プロセスではマネージャーLLMが各Agentにタスクを割り当て、その出力を受け取りながらワークフロー全体を統括します。
ツール連携
CrewAIは多様なツール連携に対応しており、SerperDevToolの他にも、ファイル操作・
CLIによるプロジェクト管理
ここまでの例では、AgentやTask、CrewをすべてPythonコード上で定義してきましたが、CrewAIでは、AgentやTaskの定義は、YAMLによる管理を推奨しています。YAML形式によるプロジェクト管理には次のような利点があります。
- 設定
(Agent/ Task) とロジック (Crew) が分離され、保守性が向上する - YAMLを変更するだけで挙動を調整できる
- チーム開発時に差分レビューやバージョン管理がしやすい
特に、AgentやTaskの数が増えるケースでは、コード管理よりも YAML 管理の方が見通しが良くなります。また、CrewAIのCLIコマンドを利用することで、YAML定義を含んだプロジェクトの雛形作成や実行を効率よく行うことができます。ここでは、その基本的な使い方を簡単に紹介します。
CrewAI CLIでプロジェクトを作成する
まずはCLIツールを使って、CrewAIプロジェクトの雛形を作成します。以下のコマンドを実行すると、CrewAI用の標準的なプロジェクト構成が自動生成されます。
# インストール pip install crewai # プロジェクト作成 crewai create crew my_crew cd my_crew
作成されるプロジェクト構造は次のとおりです。
.
├── README.md
├── knowledge # Agentが参照する補助的な知識や前提情報を配置する
│ └── user_preference.txt
├── pyproject.toml
├── src
│ └── my_crew
│ ├── __init__.py
│ ├── config
│ │ ├── agents.yaml # Agent定義
│ │ └── tasks.yaml # Task定義
│ ├── crew.py # Crew定義(メイン)
│ ├── main.py
│ └── tools # エージェントが利用する独自ツールを定義するためのファイル
│ ├── __init__.py
│ └── custom_tool.py
├── .env # 環境変数の設定
└── tests
作成されたプロジェクトでは、AgentやTaskの設定をYAMLファイルとして切り出し、Python側では実行ロジックに集中できる構成になっています。agents.
また、tools/
knowledge ディレクトリは、Agentが参照する補助的な知識や前提情報を配置するための場所です。詳細は、後述しています。
プロジェクトの実行は、プロジェクトのルートディレクトリで次のコマンドを実行します。
$ crewai run
参考までに、前述の
その他の機能
ここでは、知っておくとさらに便利な機能をいくつか紹介します。
Memory(記憶機能)
memory=TrueをCrewに設定すると、Agentは 過去のやり取りや情報を記憶し、複数のTaskや実行セッションをまたいで活用できるようになります。
crew = Crew(
agents=[researcher, analyst],
tasks=[research_task, analysis_task],
memory=True # メモリを有効化
)
Memoryの種類
CrewAIでは、用途に応じて複数の種類のメモリが内部的に使い分けられています。
- 短期記憶
(Short-term Memory) - 実行中の現在のTaskや直近の結果を一時的に保存し、文脈を維持するために利用されます。
- 長期記憶
(Long-term Memory) - 過去のセッションや実行から得られた情報を蓄積し、次回以降のセッションで再利用できます。
- エンティティ記憶
(Entity) - 人名・
組織名・ 固有概念などの重要なエンティティ情報を整理して記憶し、より深い理解や関係性の保持に役立てます。
- 人名・
- コンテキストメモリ
(Contextual) - 短期・
長期・ エンティティなど複数のメモリを統合し、総合的な文脈を維持して応答に反映させるための仕組みです。
- 短期・
デフォルトでは、MemoryのデータはCrewAIの内部ストレージに保存されます。短期記憶・CREWAI_を設定してください。
Knowledge(外部ナレッジの参照)
CrewAIでは、RAG
以下は、記事執筆時のルールをナレッジとして与える簡単な例です。
記事は必ず日本語で書く
専門用語には簡単な補足を入れる
結論を最初に書く
このようなテキストファイルをknowledgeディレクトリに配置し、Crew定義時にKnowledge Sourceとして登録することで、AgentはTask実行時にこれらのルールを参照しながら文章を生成します。
from crewai import Agent, Crew, Task
from crewai.knowledge.source.text_file_knowledge_source import TextFileKnowledgeSource
# 執筆ルールを記載したテキストファイルを Knowledge Source として読み込む
rules = TextFileKnowledgeSource(file_path="writing_rules.txt")
writer = Agent(
role="テクニカルライター",
goal="社内のルールに従って記事を書く",
backstory="経験豊富で、社内の執筆基準に従うテクニカルライター。",
verbose=True
)
task = Task(
description="CrewAIのMemory機能について記事を書く",
expected_output="ルールに沿った日本語記事",
agent=writer,
)
crew = Crew(
agents=[writer],
tasks=[task],
knowledge_sources=[rules]
)
crew.kickoff()
この例では、Taskのdescriptionにルールを直接書かなくても、AgentがKnowledgeを検索・
Knowledgeとして利用できるのはテキストファイルだけでなく、Markdown、PDF、CSVなどのファイル形式にも対応しており、仕様書やガイドライン、FAQ などをそのまま知識として扱うことが可能です。
本番利用を見据えた運用
CrewAIは外部サービスとの統合や高度なワークフロー構築を想定した設計になっています。特にAWSとの統合として、CrewAIの公式統合ツールのひとつにBedrock Invoke Agent Toolがあり、これを使うことでCrewAIのワークフロー内からAmazon Bedrock上のエージェントを呼び出し、活用できます。
Amazon BedrockはAWSが提供する フルマネージドの生成AI基盤サービスです。CrewAIとBedrockを組み合わせることで、次のような利点が期待できます。
- BedrockによってAgent実行や基盤構築の多くをAWSに委ねられる
- Anthropic、Amazon TitanなどBedrockが提供するモデルを統一的に扱える
- BedrockやAWSのIAM、ネットワーク管理を活用したアクセス制御とポリシー適用が可能
本番運用では、アクセス制御・
まとめ
本記事では、CrewAIを使ったマルチエージェントシステムの構築方法について、Agent・
筆者自身、複数の視点から株価分析を行う
一方で、パラメータの組み合わせによっては期待どおりの出力が得られなかったり、回答を安定させるために、本記事では紹介しきれなかった項目の調整が必要になる場面があることも実感しました。トレースやモニタリングを活用しながら、挙動を確認しつつ試行錯誤していくことが重要だと感じています。
CrewAIは豊富な設定パラメータにより細かな動作制御が可能で、本記事で紹介した内容はその一部にすぎません。監視・
まずは最小構成から試し、少しずつ機能を追加しながら、自身のユースケースに合わせて発展させてみてください。本記事が、AI活用の可能性を広げるきっかけになれば幸いです。