


Googleは2026年3月10日、Geminiアーキテクチャを基盤とする同社初のマルチモーダル埋め込みモデル
Start building with Gemini Embedding 2, our most capable and first fully multimodal embedding model built on the Gemini architecture. Now available in preview via the Gemini API and in Vertex AI. pic.
— Google AI Developers (@googleaidevs) March 10, 2026twitter. com/ jPE8KpN7Rf
埋め込みモデルは、テキストなど人間が理解しやすいデータを数値
パフォーマンスも上がっており、テキスト処理のベンチマークで前モデルを大きく上回るほか、マルチモードでもAmazon Nova 2 Multimodal Embeddingsなどの他社モデルを凌駕するベンチマークを記録したという。
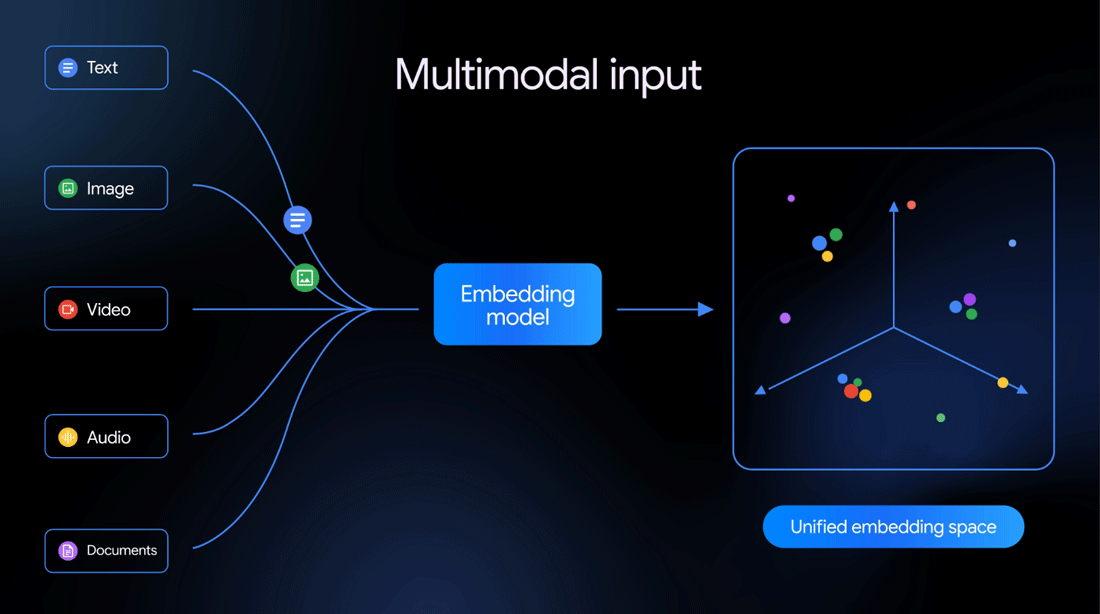
各モードが扱えるデータは以下の通り。
- テキスト:最大8192個の入力トークンを含むコンテキストをサポート
- 画像:リクエストごとに最大6枚の画像を処理可能。PNGおよびJPEG形式をサポート
- 動画:MP4およびMOV形式で最大120秒の動画入力をサポート
- 音声:テキスト書き起こしなしで音声データをネイティブに取り込み埋め込み可能
- ドキュメント:最大6ページのPDFを直接埋め込み
またGemini Embedding 2は、1つのリクエストで複数のモード
前モデル同様、Gemini Embedding 2には出力データの次元を動的にスケールダウンすることで情報をネストする手法であるMatryoshka Representation Learning
Gemini Embedding 2パブリックプレビュー版は、Gemini APIおよびVertex AI経由で利用できる。